🌼 Problem
🍔 Solution 1 - replaceAll() 사용
import java.util.Locale;
import java.util.Scanner;
public class Main {
public static String Solution(String str){
String answer = "YES";
String special = "[^\\uAC00-\\uD7A3xfe0-9a-zA-Z\\\\s]";
// 특수문자 제거
String removespecial = str.toLowerCase(Locale.ROOT).replaceAll(special,"");
// 숫자 제거
String removenum = removespecial.replaceAll("[0-9]","");
char[] charArr = removenum.toCharArray();
int lt = 0;
int rt = removenum.length()-1;
while(lt < rt){
if(charArr[lt]!=charArr[rt]){
answer = "NO";
break;
}
lt++; rt--;
}
return answer;
}
public static void main(String[] args){
Scanner in=new Scanner(System.in);
String input = in.nextLine();
System.out.println(Solution(input));
}
}
replaceAll() 추가 노트
String replaceAll(String regex, String replacement)
replaceAll( ) : 자바의 문자열에서 정규식을 자주 사용하는 메소드 중 하나이다.
문자열 내에 있는 정규식 regex와 매치되는 모든 문자열을 replacement 문자열로 반환한다.
| 정규 표현식 | 의미 |
|---|---|
^[0-9]*$ == \\d | 숫자 |
^[a-zA-Z]*$ | 알파벳 |
^[가-힣]*$ | 한글 |
^[a-zA-Z0-9] | 알파벳이나 숫자 |
^[a-zA-Z0-9]+@[a-zA-Z0-9]+\\.[a-z]+$ | 이메일(Email) |
\w+@\w+\.\w+(\\.\\w+)? | 이메일(Email) |

replace 예제
public class PatternExample {
public static void main(String[] args){
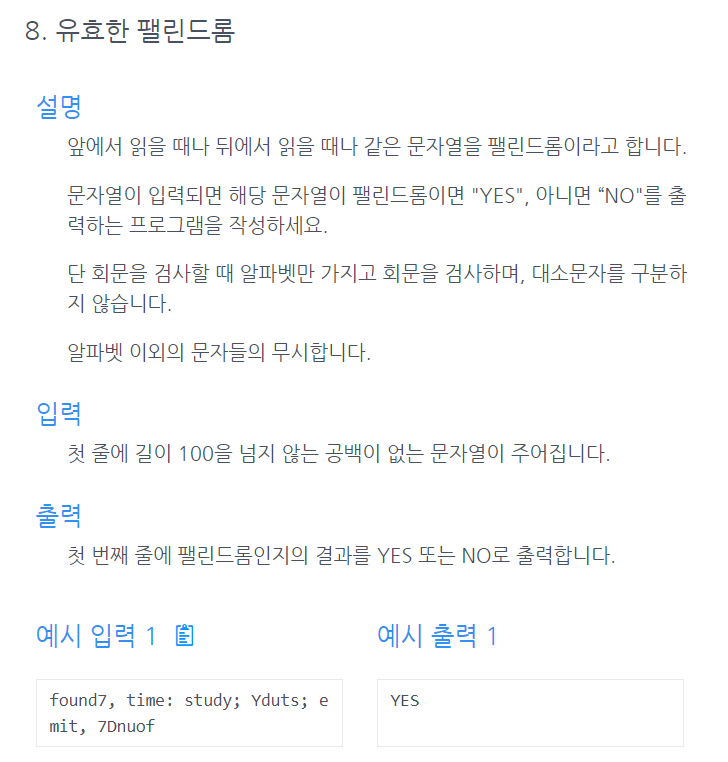
String before = "ABC1234DEFG!^/";
String regex = "[0-9]";
System.out.println("replaceAll() 사용 전 :" + before);
String after = before.replaceAll(regex,"");
System.out.println("replaceAll() 사용 전 :" + after);
}
}
[결과]
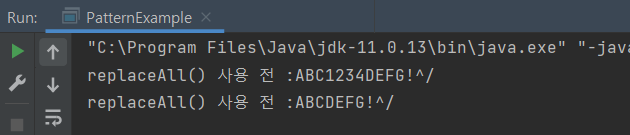
🍪 강사 Solution - replaceAll(), StringBuilder reverse() 사용
import java.util.Locale;
import java.util.Scanner;
public class Main {
// 강사 : replaceAll 사용
public static String Solution(String str){
String answer = "NO";
str = str.toLowerCase(Locale.ROOT).replaceAll("[^a-z]","");
String tmp = new StringBuilder(str).reverse().toString();
if(str.equals(tmp)) {
answer = "YES";
}
return answer;
}
public static void main(String[] args){
Scanner in=new Scanner(System.in);
String input = in.nextLine();
System.out.println(Solution(input));
}
}[결과]
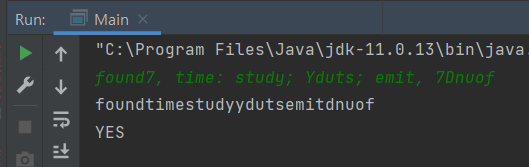
😂 부족했던 점 1
replaceAll("[^a-z]","") 으로 사용하면 소문자 a-z 에 해당하지 않으면(^) 모두 제거 할 수 있었다.
// 특수문자 제거
String removespecial = str.toLowerCase(Locale.ROOT).replaceAll(special,"");
// 숫자 제거
String removenum = removespecial.replaceAll("[0-9]","");불필요하게 특수문자 제거 후, 숫자 제거했었음
😂 부족했던 점 2
StringBuilder를 통해 다시 비교할 수 있다는걸 생각하지 못했다 !
while문에서 char[]의 index에 접근해서 하나하나 문자를 비교한 방법은 비효율적인 것 같다.
🍄 issue 🍄
import java.util.Locale;
import java.util.Scanner;
public class Main {
public static String Solution(String str){
String answer = "YES";
char[] charArr = str.toLowerCase(Locale.ROOT).toCharArray();
int lt = 0;
int rt = str.length()-1;
while(lt < rt){
if(String.valueOf(charArr[lt]).matches("^[a-zA-Z]*$")){
// 알파벳인 경우만 비교
if(charArr[lt]!=charArr[rt]){
answer = "NO";
break;
}
}
lt++; rt--;
}
return answer;
}
public static void main(String[] args){
Scanner in=new Scanner(System.in);
String input = in.nextLine();
System.out.println(Solution(input));
}
}[결과]
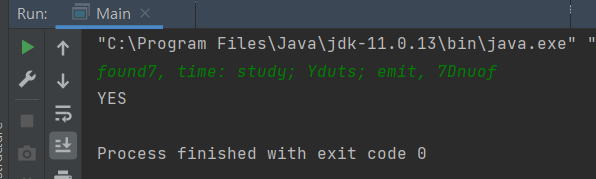
결과는 YES 인데 어디가 틀린건지 모르겄다 ㅠㅠ

진주의 코딩일기