grokking deep learning pdf 책
논문 읽기
도표부터 -> study -> appendix -> abstract
nlp
zero-shot : 이미 안에 들어있는 성능으로도 가능
5-shot
10-shot
training dataset의 양에 따라
Bert(transformer) ->분류를 잘함
mlm 사용
gpt(transformer)는 lm ->분류를 잘 못함
- vectorizer(real-world를 컴퓨터가 알아들을 수 있는 숫자로)
-
맥락

embedding 덕에 맥락을 이해할 수 있음 (one-hot 아님) -
tokenizer
딕셔너리(key : vocab, value : number-input id-)

쪼개는 기준은 tokenizer의 종류에 따라 다름(형태소, 의미단어 등..)
-embedding
input id에 붙어있는 n-dimension 벡터(리스트) - 수는 처음엔 랜덤 or pretrained로
similar vectors, then similar meanings

소수로 된 matrix

22-> 단어 개수
12-> ?
768-> 벡터 디멘션의 개수
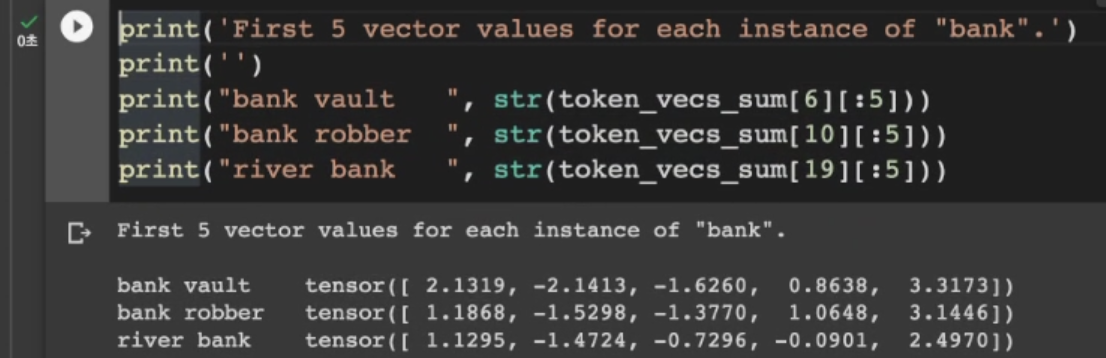
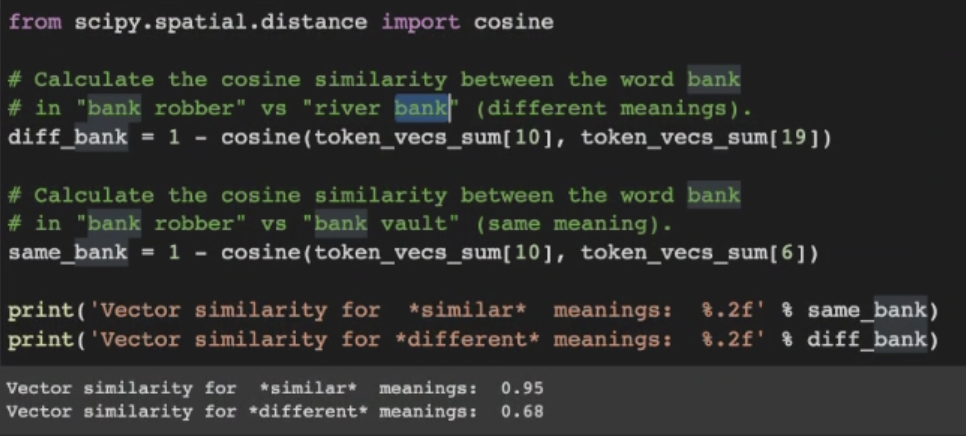
-> cosin similarity(벡터와 벡터간의 유사도) .. 맥락이 비슷하면 벡터간 유사도가 1에 가깝게 나옴 (사용하는 이유 : tensor를 인간이 일일이 확인하기 어려우므로. 만약 2차원이면 벡터 각도, 방향을 비교할 수 있지만 768차원은 인간이 비교하기 힘들 것임)
vars(tokenizer) #
dir(tokenizer) #tokenizer 종류
list(tokenizer.vocab.keys())[5000:5020]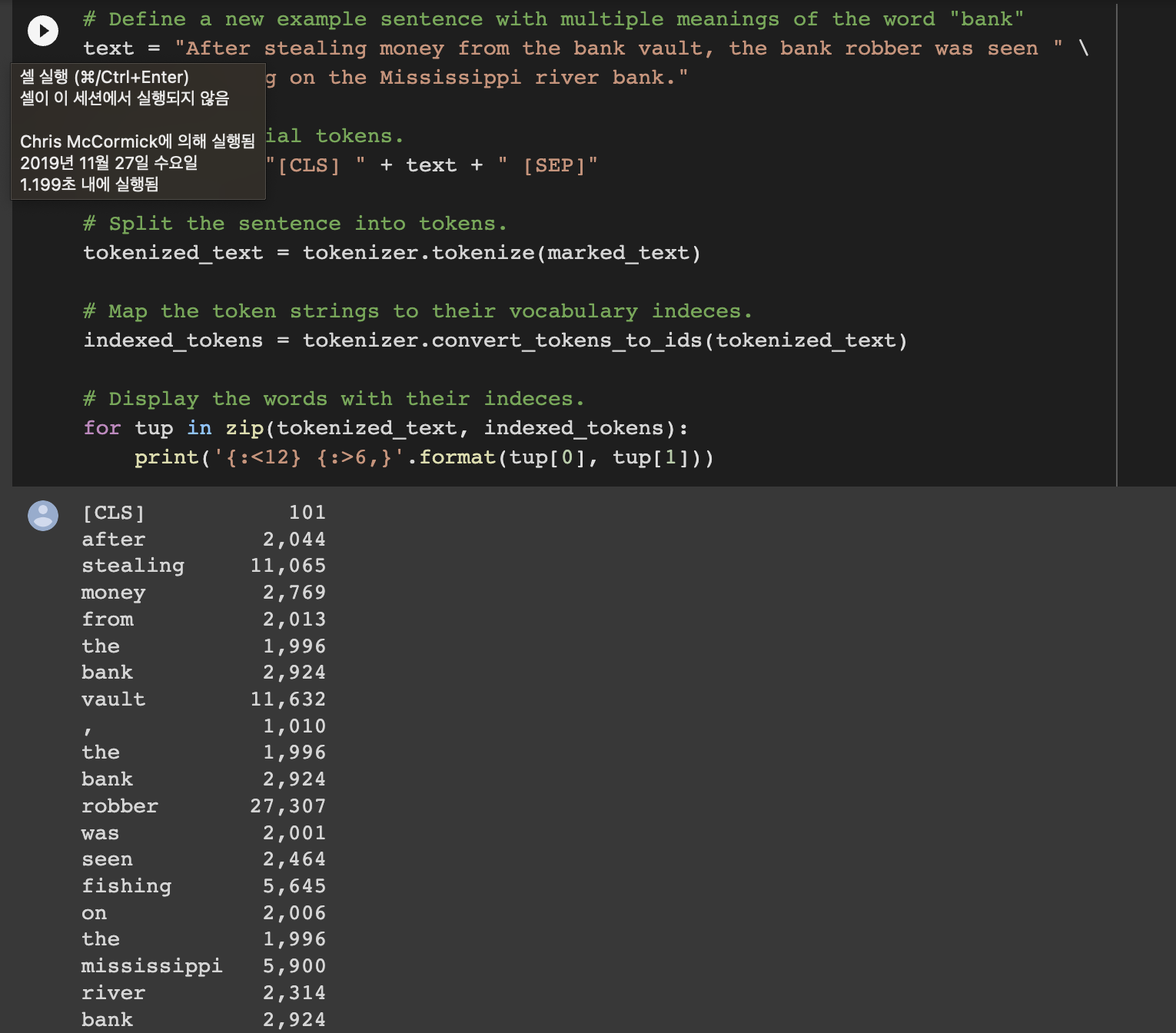
->embedding이 필요한 이유(두 뱅크가 다른 걸 구분하지 못함. 빈도수가 동일)
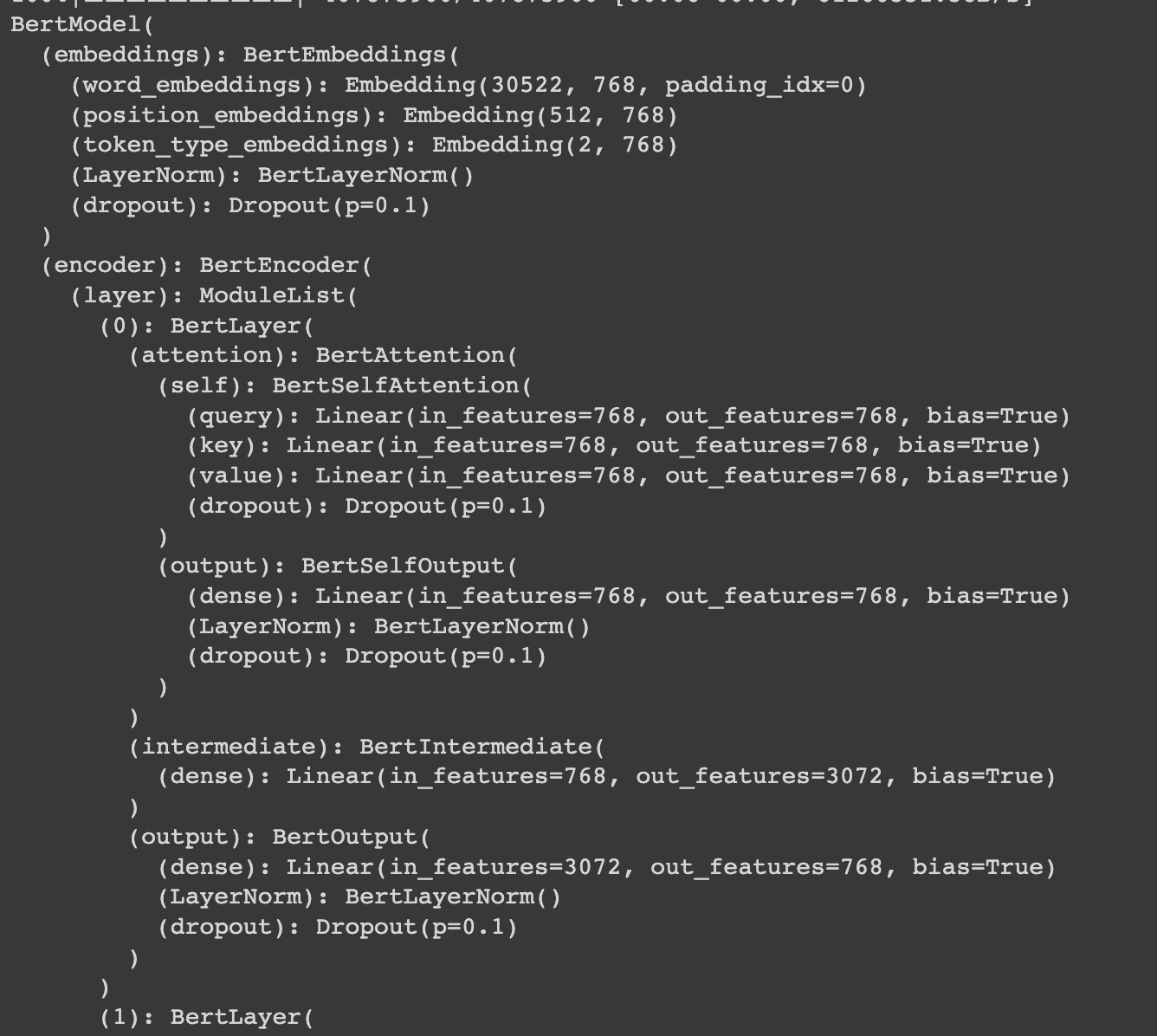
encoder, embedding, bertlayer12개, attention(transformer의 특징)
pretrained ai's embedding layer vs random
*visual

Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels, without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels, we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0% top-1 accuracy on a linear probe of our features.

보라색 - attention 0 (관계 x) ->학습 x ???
attention map이 활성화 - 관계가 있다
->연관성을 찾아내 selective하게 학습
영어단어, 스페인단어의 각 matrix를 비교 (순서 없음, 한 번에 mapping)
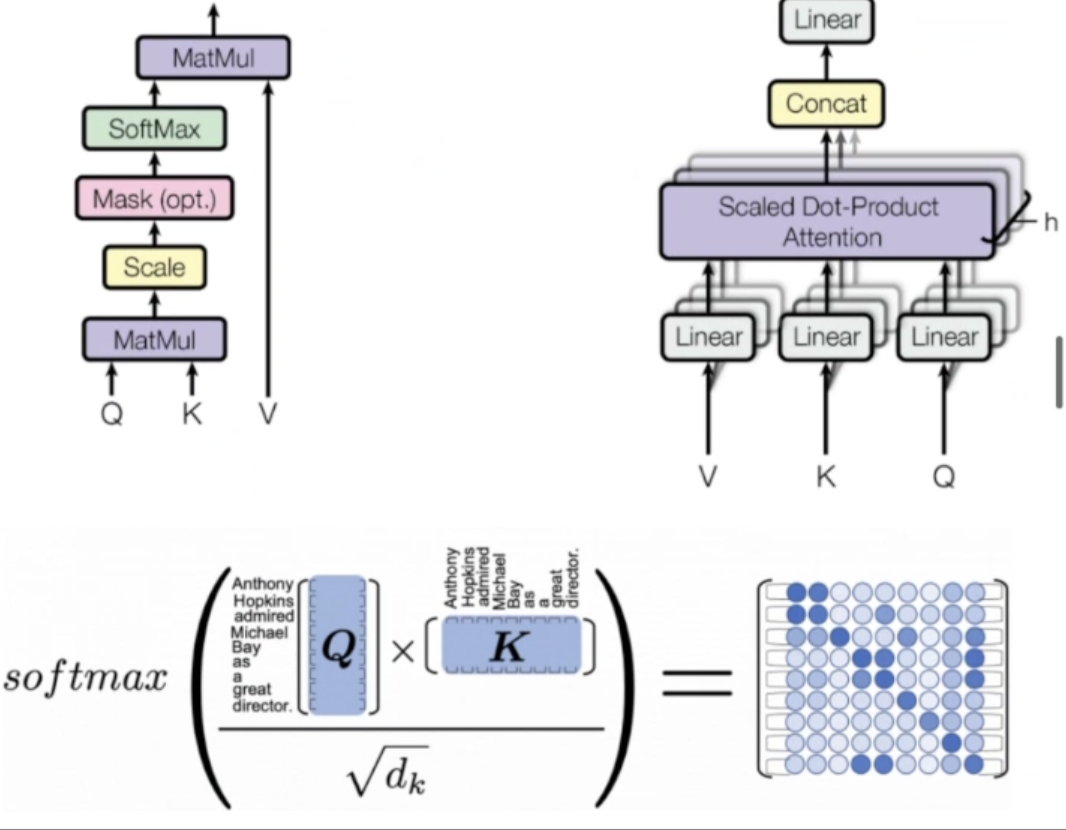
->attention mapping을 스스로 하게 함
key와 query가 같음 (행렬은 처음엔 랜덤 - 행렬곱을 하면 둘 간의 관계가 나올 것이다!)
softmax (확률값으로 normalization 0.0~1.0)
-> wei를 만듦
-> 한 번 더 곱함
-> 이를 다음 layer에 넘김
training objective : loss criteria의 정식 용어
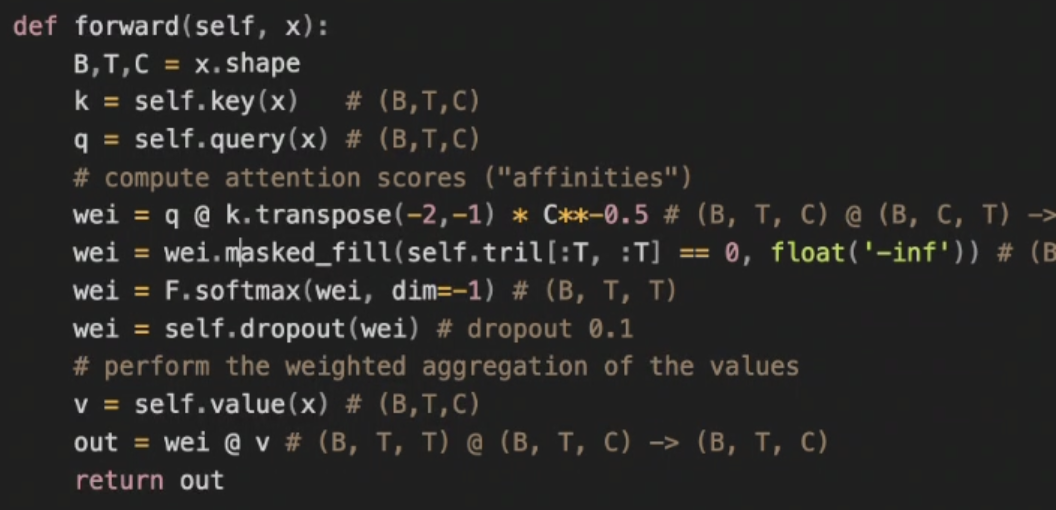
- LM(gpt or auto regressive) : 다음 단어를 예측하는 학습 (context를 기반으로, 3만 개의 단어 중에서 어떤 것이 다음 단어로서 확률이 제일 높은지) ->단방향 (앞만 주어지니까)
- MLM(bert) : 제일 어려운 masking으로 학습시킴(랜덤으로 mask하고 3만 개의 단어 중에서 확률로 찾아 채우게 함. epoch마다 같은 텍스트인데 mask하는 부분만 다름. 만약 이전 epoch에서 잘 학습을 했다면 그 epoch에서 잘 맞힐 것) -> bi directional (앞뒤를 모두 보니까) ->물론 데이터셋이 작으면 overfitting될 수 있음
MRC machine reading comprehension
Benchmark
*chat GPT
*prompt - tuning vs fine tuning
fine tuning : input, output을 가지고 transformer weight를 전부 업데이트
prompt tuning : 어떤 텍스트를 주고 업데이트를 시킴
- weight
float로 구성된 matrix
모델 배포(파랑) -> B(유저들의 모델이 됨) -> cloud에서 더함 -> c라는 모델 탄생 -> c를 배포
->federative 방식의 업데이트
- task-specific heads : 태스크에 맞게 짜는 것
- classification head : gournd truth vs probability -> loss
왜 확률? -> real world의 sub sample이므로 확률이 확정값보다 좋음 - token classification head
..등 종류가 아주 많음 (huggingface에서 확인 가능!)
