JPA
Java Persistence API/Jakarta Persistence
ORM(객체 중심의 데이터 액세스 기술)의 Java 표준사양(명세)
Java 인터페이스로 정의되어 있으며 이를 구현한 것이
Hibernate ORM, EclipseLink, DataNucleus 이다
뭐가 영속성(Persistence)인가?
테이블과 매핑되는 엔티티 객체를 영속성 컨텍스트에 보관한다
부트스트랩
웹사이트를 쉽게 만들 수 있게 도와주는 HTML, CSS, JS 프레임워크
Persistence API
의존 라이브러리 추가, application.yml 설정
hibernate: ddl-auto: create : 엔티티 스키마(테이블) 자동 생성
show-sql: true SQL 쿼리 출력
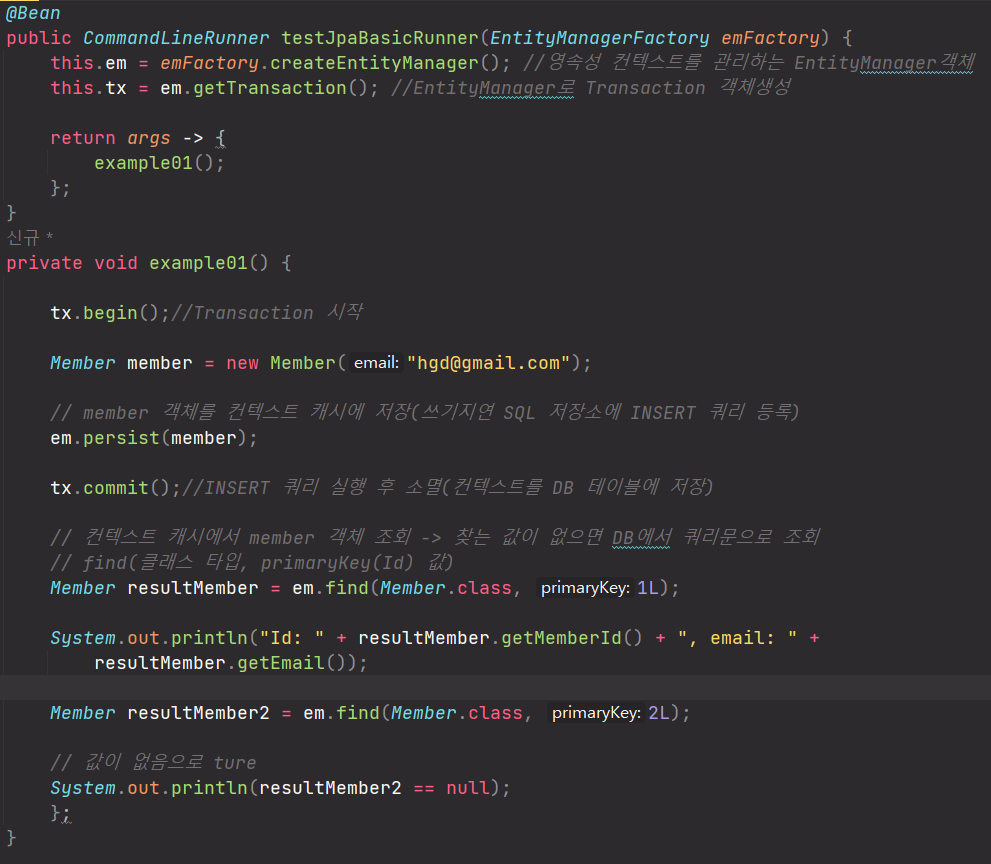
tx.begin()트랜잭션 시작em.persist()컨텍스트 객체 , 쿼리문 저장tx.commit()쿼리 실행, 객체 DB저장em.find()컨텍스트 선 검색, 없으면 쿼리로 DB검색
저장 :
em.persist()
조회 :em.find()
수정 :em.find()->setter
삭제 :em.find()->em.remove()
tx.commit()을 호출하면 내부적으로 em.flush()가 호출된다.
엔티티 매핑
@Entity/@Table
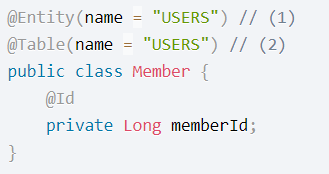 `@Entity(name="")` 설정하지 않으면 클래스명이 기본값, @Entity와 @Id는 필수
`@Table(name="")` 설정하지 않으면 클래스명이 기본값
`@Id` 설정 필드는 기본키가 됨
`@Entity(name="")` 설정하지 않으면 클래스명이 기본값, @Entity와 @Id는 필수
`@Table(name="")` 설정하지 않으면 클래스명이 기본값
`@Id` 설정 필드는 기본키가 됨
@Id
직접 할당
@Id지정시 직접 할당이 defalt
em.persist(new Member(1L));
IDENTITY(AUTO_INCREMENT)
데이터베이스에서 자동 증가
@Id필드에@GeneratedValue(strategy = GenerationType.IDENTITY)설정
SEQUENCE
시퀸스 값을 따로 설정
@Id필드에@GeneratedValue(strategy = GenerationType.SEQUENCE)설정
AUTO
JPA가 데이터베이스의 Dialect에 따라 적절한 전략 자동 선택
@Id필드에@GeneratedValue(strategy = GenerationType.AUTO)설정
Key TABLE
@Column
미설정시 자동으로 검색해 추가, defalt값 적용
defalt: @Column( nullable = true, updatable = true, unique = false, length = 255, name = "" )
기본타입은 @Column 미 설정시 nullable = false 적용되나
@Column적용 후 값을 넣지 않으면 nullable = ture 가 됨으로 주의[false설정을 권장]
LocalDateTime.now()
등록되는 시간을 매핑하는 필드에 적용하는 메서드, TIMESTAMP 와 매핑
private LocalDateTime createdAt = LocalDateTime.now();
@Transient 해당 필드는 열과 매핑하지 않음
@Enumerated enum 타입을 매핑
@Enumerated(EnumType.ORDINAL) 순서(숫자)를 테이블에 저장
@Enumerated(EnumType.STRING) 이름을 테이블레 저장[권장]
연관관계 매핑
1:1
@OneToOne을 사용하며
@JoinColumn(name = "연결 대상의 열명")
반대쪽에도
@OneToOne(mappedBy = "연결주체 변수명")
한 쪽 지정 시 단방향, 양 쪽 지정 시 양방향이 된다.
N:1
@ManyToOne를 사용한다.
'N' 쪽에@JoinColumn(name = "연결 열명")을 추가하여
연결 매개가 되는 외래 클래스 필드명(보통ID)을 설정한다
1:N
일반적으로 1:N 단방향 매핑은 사용하지 않는다.
연결된 N:1을 양방향으로 추가 연결하고 싶을 때 사용한다'1'쪽에
@OneToMany(mappedBy = "[연결 열명]을 가진 변수명")을 추가한다
연결 매개가 된 필드의 변수명을 설정 해 준다
N:N
@ManyToMany의 사용보다@ManyToOne,@OneToMany의 연결을 통한
중개 클래스의 N:1 매핑 연결을 권장한다
필요시mappedBy로 양방향 추가 연결한다
영속성 전이
cascade = CascadeType.PERSIST
mappedBy의 추가 속성으로 붙어
하위 필드(기본키로 매핑하는 쪽)의 행위를 강제한다
PERSIST는 같이 영속성 컨텍스트에 보관한다는 뜻
Fetch 전략
Eager
데이터를 즉시 호출
연관관계 매핑된 엔티티의 데이터까지 즉시 호출
@ManyToOne,@OneToOne의 기본값
연관 엔티티가 하나일 경우
Lazy
필요한 시점에 데이터 호출
연관관계 매핑된 엔티티를 가져오는 메서드를 사용하는 시점에 호출
@OneToMany의 기본값, 또는 연관 엔티티가 컬렉션인 경우
연결된 맴버를 통한 오더Id 그래프 탐색
Member findMember = em.find(Member.class, 1L);
findMember.getOrders().stream().forEach(findOrder -> findOrder.getOrderId())
레포지토리
- JpaRepository 인터페이스 사용
- JPQL을 통한 객체 지향 쿼리
객체를 대상으로 객체 조회, 내부적으로 SQL을 만들어줌
@Query(value = "SELECT c FROM 클래스명 c WHERE c.필드명 = :coffeeId") - JDBC 는 테이블명과 컬럼명을 넣은 것과 달리 JPA는 클래스와 필드를 지정
c는 클래스의 별칭, 즉 조건에 맞는 클래스 전체(*)를 조회한다는 뜻
@Query에nativeQuery = true값을 넣어 실행 여부를 설정