궁금했던 것
과거의 프로젝트에서 검색을 개발할 때 mysql 의 Like 키워드를 사용했었다.
하지만 더 성능이 좋은 검색 방법도 같이 검색이 되었었는데
그 방법은 바로 Elastic Search 를 이용하는 방법이었다.
그때는 그렇구나 하고 넘어갔는데
정확히 얼마나 성능이 향상 되는지 궁금하였다.
그래서 100만건의 데이터를 넣고 이에 대한 검색 속도를 측정해 보겠다.
프로젝트 세팅
주의점
elastic search 를 이용할 때 제일 힘든 부분이였다.
스프링 부트와 그와 연계되는 elastic search 버전 그리고 또 그와 연계되는 키바나까지 버전을 정확히 맞춰줘야 했다 .
나의 경우 윈도우 환경에서 Elastic Search 버전 7.12 , 키바나는 7.8 , 스프링 부트는 2.7.6 버전을 이용하였고
build.gradle 에는
implementation 'org.springframework.data:spring-data-elasticsearch'를 넣었다.
이에 대한 정확한 spring data elastic search 의 버전은
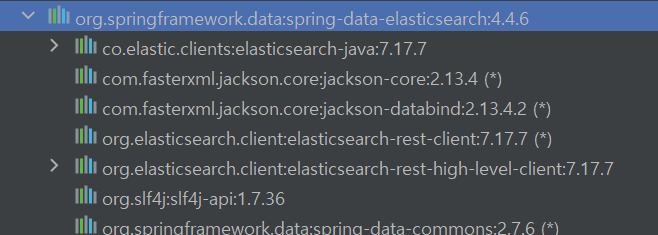
위 사진과 같이 4.4.6이였다.
아래 글에 대한 설명
아래 글에 부연설명은 최대한 안하겠다.
확실하게 모르는 부분이기도 하고
이 글의 목적은 일반 like 검색에 비해 elastic search 의 검색이 얼마나 빠른지 알아보는 것이 전부이기 때문이다.
build.gradle
위와 같이 build.gradle 을 세팅한다.
application.properties
spring.data.elasticsearch.repositories.enabled= true
spring.data.elasticsearch.url= localhost:9200위 두 조건을 추가해줬다.
ElasticSearchConfig
@Configuration
@EnableElasticsearchRepositories(basePackageClasses = {MemberSearchRepository.class})
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.data.elasticsearch.url}")
String url;
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}사실 위 connectedTo 부분에 url 을 넣어줘야 하는데 내가 그냥 localhost:9200 을 넣은 부분이다. 실험환경이니 딱히 고치지는 않았다.
Member , MemberDocument
데이터 베이스에 저장하기 위해서는 Member Entity 가 필요하고
Elastic Search에 저장하기 위해서는 MemberDocument 가 필요하다.
Member
@Entity
@Getter
@Setter
@NoArgsConstructor
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "member_id")
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private int age;
@Builder
public Member(String name,int age,Team team){
this.name=name;
this.team=team;
this.age =age;
}
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
}MemberDocument
@Builder
@Getter
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "members")
public class MemberDocument {
@Id
private Long id;
private String name;
private int age;
private Long teamId;
public static MemberDocument from(Member member){
return MemberDocument.builder()
.id(member.getId())
.name(member.getName())
.age(member.getAge())
.teamId(member.getTeam().getId())
.build();
}
}최대한 검색하고 싶은 Member 의 내용만 넣었다.
MemberSearchRepository
JPA 를 이용하여 데이터를 넣는 부분은 생략하고
elastic search 의 데이터를 저장하는 코드를 보겠다.
@Repository
public interface MemberSearchRepository extends ElasticsearchRepository<MemberDocument,Long>{
Optional<MemberDocument> findById(Long id);
List<MemberDocument> findByName(String nickName);
List<MemberDocument> findByNameLike(String name);
List<MemberDocument> findByNameContains(String name);
}스프링 data jpa 와 유사하게 처리해주면 된다 .
단 extends 를 ElasticSearchRepository로 하였을 뿐 !
MemberSearchService
@Service
@RequiredArgsConstructor
public class MemberSearchService {
private final MemberSearchRepository memberSearchRepository;
private final RestHighLevelClient restHighLevelClient;
private final ObjectMapper objectMapper;
//단건을 저장 가능!
public void save(Member member){
memberSearchRepository.save(MemberDocument.from(member));
}
// batch 를 이용해서 한번에 저장이 가능하다.
public void saveAllMemberDocument(List<MemberDocument> memberDocumentListList){
memberSearchRepository.saveAll(memberDocumentListList);
}
// 특정 이름을 가진 Member를 찾는데 사용한다.
public List<MemberResponseDto> findMembersByName(String keyword){
return memberSearchRepository.findByName(keyword).stream().map(memberDocument -> {
return new MemberResponseDto(memberDocument.getId(),memberDocument.getName());
}).collect(Collectors.toList());
}
// 이 부분은 무시해 주기를 바란다. 조금 더 공부를 해야 한다 .ㅜ
public List<MemberResponseDto> findMemberContainsName(String keyword) throws IOException {
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.wildcardQuery("name","*"+keyword+"*"));
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
SearchRequest searchRequest = new SearchRequest("members");
searchRequest.source(searchSourceBuilder);
SearchHits hits = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT).getHits();
return Arrays.stream(hits.getHits())
.map(hit-> objectMapper.convertValue(hit.getSourceAsMap(),MemberResponseDto.class))
.collect(Collectors.toList());
}
// repository 의 Like 를 호출한다. Member 의 이름이 매개변수로 들어온 name 으로 시작하는 것을 골라준다.
public List<MemberResponseDto> findMemberNameLike(String name){
return memberSearchRepository.findByNameLike(name).stream().map(memberDocument -> {
return new MemberResponseDto(memberDocument.getId(),memberDocument.getName());
}).collect(Collectors.toList());
}
// repository 의 Like 를 호출한다. Member 의 이름이 매개변수로 들어온 name 을 포함하는 것을 골라준다.
public List<MemberResponseDto> findMemberNameContains(String name){
return memberSearchRepository.findByNameContains(name).stream().map(memberDocument -> {
return new MemberResponseDto(memberDocument.getId(), memberDocument.getName());
}).collect(Collectors.toList());
}
}각 메서드 별로 주석을 달았다.
MemberController
@RestController
@RequiredArgsConstructor
public class MemberController {
private final MemberService memberService;
private final MemberSearchService memberSearchService;
private final MemberRepository memberRepository;
//mysql 에서 특정 이름을 가진 member 를 찾아 반환
@GetMapping("/search/member/api")
public List<MemberResponseDto> showMemberByNameByApi(@RequestParam("name")String name){
return memberRepository.findByName(name).stream().map(member -> {
return new MemberResponseDto(member.getId(),member.getName());
}).collect(Collectors.toList());
}
// elastic search 에서 특정 이름을 가진 member 를 찾아 반환
@GetMapping("/search/member/es")
public List<MemberResponseDto> showMemberByNameByEs(@RequestParam("name")String name){
return memberSearchService.findMembersByName(name);
}
@GetMapping("/search/member/es/like2")
public List<MemberResponseDto> showMemberByLikeNameByEs2(@RequestParam("name")String name)
throws IOException {
return memberSearchService.findMemberNameLike(name);
}
// 이 api를 호출하면 elastic search 에서 name을 포함하는 이름을 가진 모든 member 의 정보가 나온다.
@GetMapping("/search/member/es/like3")
public List<MemberResponseDto> showMemberByLikeNameByEs3(@RequestParam("name")String name)
throws IOException {
return memberSearchService.findMemberNameContains(name);
}
//이 api 를 호출하면 mysql db 에서 name을 포함하는 이름을 가진 모든 member의 정보가 나온다.
@GetMapping("/search/member/api3/like")
public List<MemberResponseDto> showMemberByLikeNameByAPI3(@RequestParam("name")String name)
throws IOException {
return memberRepository.findMemberByNameContaining(name).stream().map(member -> {
return new MemberResponseDto(member.getId(),member.getName());
}).collect(Collectors.toList());
}
}마찬가지로 주석을 달았다.
각 함수 메서드의 이름과 이런 부분을 좀더 신경썼어야 했지만
실험적인 부분이 강한 내용이므로 .... 자중하겠다 ㅜ
데이터 100만건 저장하기 -MemberInitializer
스프링에서 repository.save 를 이용해서 단건으로 저장하는 것은 elastic search 로도 , mysql 에도 쉽지 않다.
실제로 직접 해보면 진짜 엄~~청 오래 걸리기 때문에 insert 쿼리 한번에 여러 개의 데이터를 넣는 batch 를 이용하겠다.
맛만 살짝 보여주면
INSERT INTO member (age,name,team_id) VALUES
(22,'P50dW',2),(33,'XFdoD',2),(14,'ZoYi1',5),
(36,'GgM5y',5),(59,'cDC5D',1),
(15,'rGsnh',3),(45,'gY02P',1),(64,'dUksN',2),(82,'J9hKB',5),(9,'qqgUN',4),(63,'S8ecC',3),
(57,'clI8n',2),(26,'LkW3w',4),(71,'bQmuY',1),.....이런식으로 데이터를 넣는 수밖에 없다.
이런 식으로 데이터를 저장하려면 mysql 의 id 를 GenereationType.Identity 로 하는 나로써는 JDBC 를 이용해서 배치로 데이터를 저장하는 수밖에 없었다.
@Component
@RequiredArgsConstructor
public class MemberInitializer implements ApplicationRunner {
private final MemberRepository memberRepository;
private final TeamRepository teamRepository;
private final JdbcTemplate jdbcTemplate;
private final MemberSearchService memberSearchService;
@Override
public void run(ApplicationArguments args) throws Exception {
//처음에는 team 의Quality 를 설정하려고 하고 이를 기준으로
//정렬하려 했으나 이는 보류 되었다. ㅎ 따라서 무시해주면 된다.
Team teamA = Team.builder().name("teamA").quality(5).build();
Team teamB = Team.builder().name("teamB").quality(3).build();
Team teamC = Team.builder().name("teamC").quality(2).build();
Team teamD = Team.builder().name("teamD").quality(1).build();
Team teamE = Team.builder().name("teamE").quality(4).build();
teamRepository.save(teamA);
teamRepository.save(teamB);
teamRepository.save(teamC);
teamRepository.save(teamD);
teamRepository.save(teamE);
List<Member> memberList = new ArrayList<>();
//100만건의 Member 데이터를 저장한다.
for(int i=0;i<1000000;i++){
Random random = new Random();
int randomNumber = random.nextInt(100)+1;
int teamNumber = random.nextInt(5);
// 나이는 random 데이터로 , 이름도 random 으로
Member.MemberBuilder memberTmp = Member.builder()
.age(randomNumber)
.name(generateRandomString(5));
Member member = null;
//team 도 random 이지만 team 은 이제 안쓰이므로 알아서 써주거나 하면된다.
if(teamNumber%5==0){
member = memberTmp.team(teamA).build();
}
else if(teamNumber%5==1){
member = memberTmp.team(teamB).build();
}
else if(teamNumber%5==2){
member = memberTmp.team(teamC).build();
}
else if(teamNumber%5==3){
member = memberTmp.team(teamD).build();
}
else if(teamNumber%5==4){
member = memberTmp.team(teamE).build();
}
memberList.add(member);
}
String sql = "INSERT INTO member (age,name,team_id) " +"VALUES (?,?,?)";
// jdbc 의 batch 를 이용해서 직접 대용량의 데이터를 저장한다. (GenerationType.Identity이므로)
jdbcTemplate.batchUpdate(sql,
memberList,memberList.size(),
(PreparedStatement ps, Member member )->{
ps.setInt(1,member.getAge());
ps.setString(2,member.getName());
ps.setLong(3,member.getTeam().getId());
});
//ElasticSearch 에도 데이터를 저장한다. 한번에 저장할 수있는 크기의 한계가 있으므로
//10000으로 쪼갰다
List<MemberDocument> memberDocumentList = new ArrayList<>();
memberRepository.findAll().forEach(member -> {
//memberSearchService.save(member);
if(memberDocumentList.size()==10000){
memberSearchService.saveAllMemberDocument(memberDocumentList);
memberDocumentList.clear();
}
memberDocumentList.add(MemberDocument.from(member));
});
memberSearchService.saveAllMemberDocument(memberDocumentList);
}
//이름을 만들때 랜덤하게 만들기 위한 메서드
public static String generateRandomString(int length) {
// 생성할 문자열에 포함될 문자들
String characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
// SecureRandom 객체 생성
SecureRandom random = new SecureRandom();
// 랜덤 문자열 생성
StringBuilder sb = new StringBuilder(length);
for (int i = 0; i < length; i++) {
int randomIndex = random.nextInt(characters.length());
sb.append(characters.charAt(randomIndex));
}
return sb.toString();
}
}
실험 화면 및 결과
초기에는...
ElasticSearch 에도 데이터가 없고 당연히 mysql 에도 데이터가 없다.
아래는 키바나 환경에서 데이터가 없음을 보여주는 것이다.
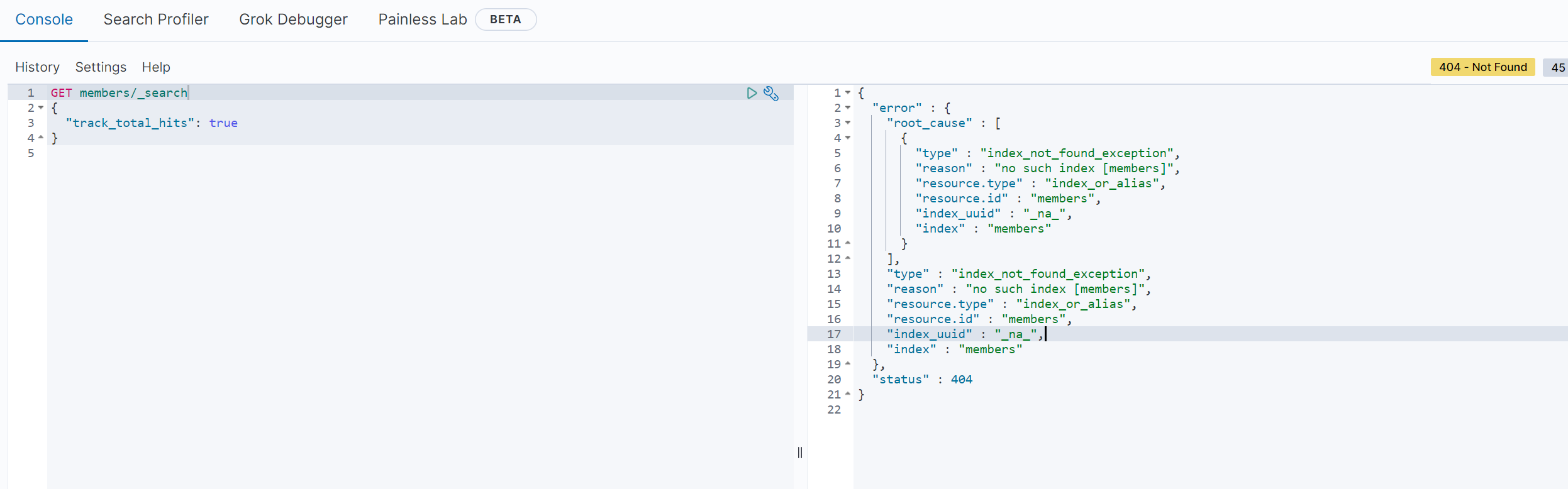
스프링 실행
스프링이 실행되면 MemberInitializer 의 run 이 동작한다.
데이터가 잘 들어가는 모습!~
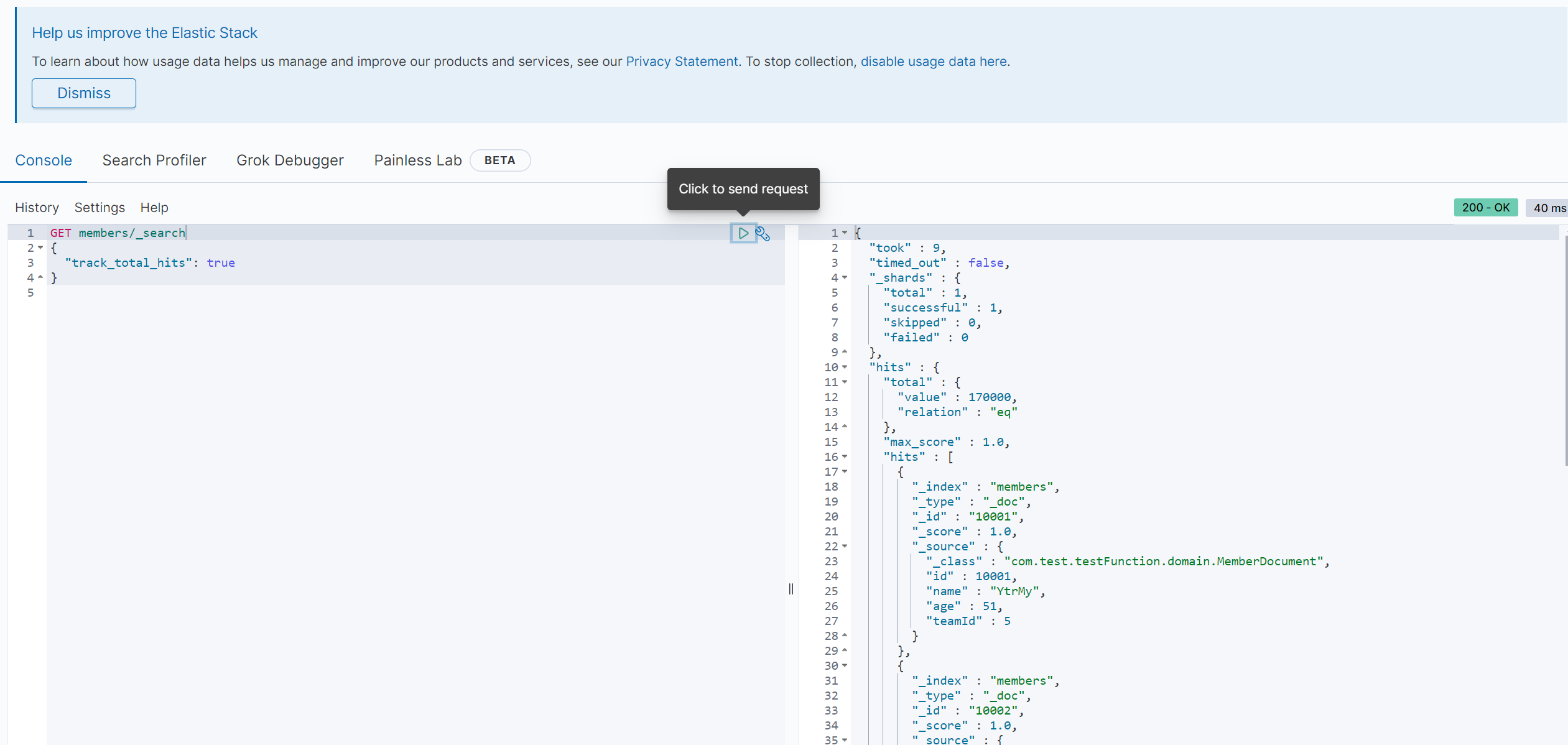
mysql 에 100만건의 데이터가 잘 들어간 모습을 볼 수 있고
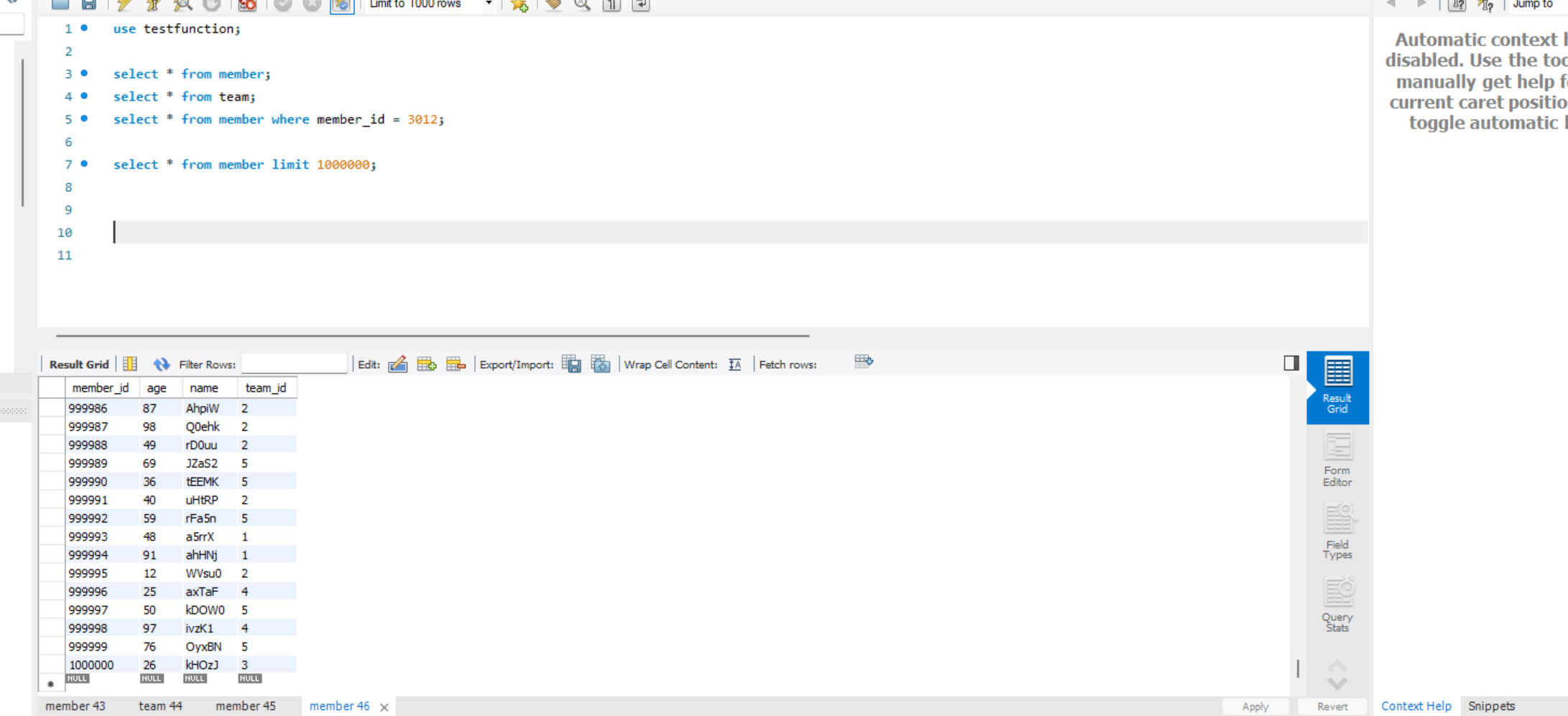
Elastic Search 에도 데이터가 잘 들어간 모습을 볼 수 있다.
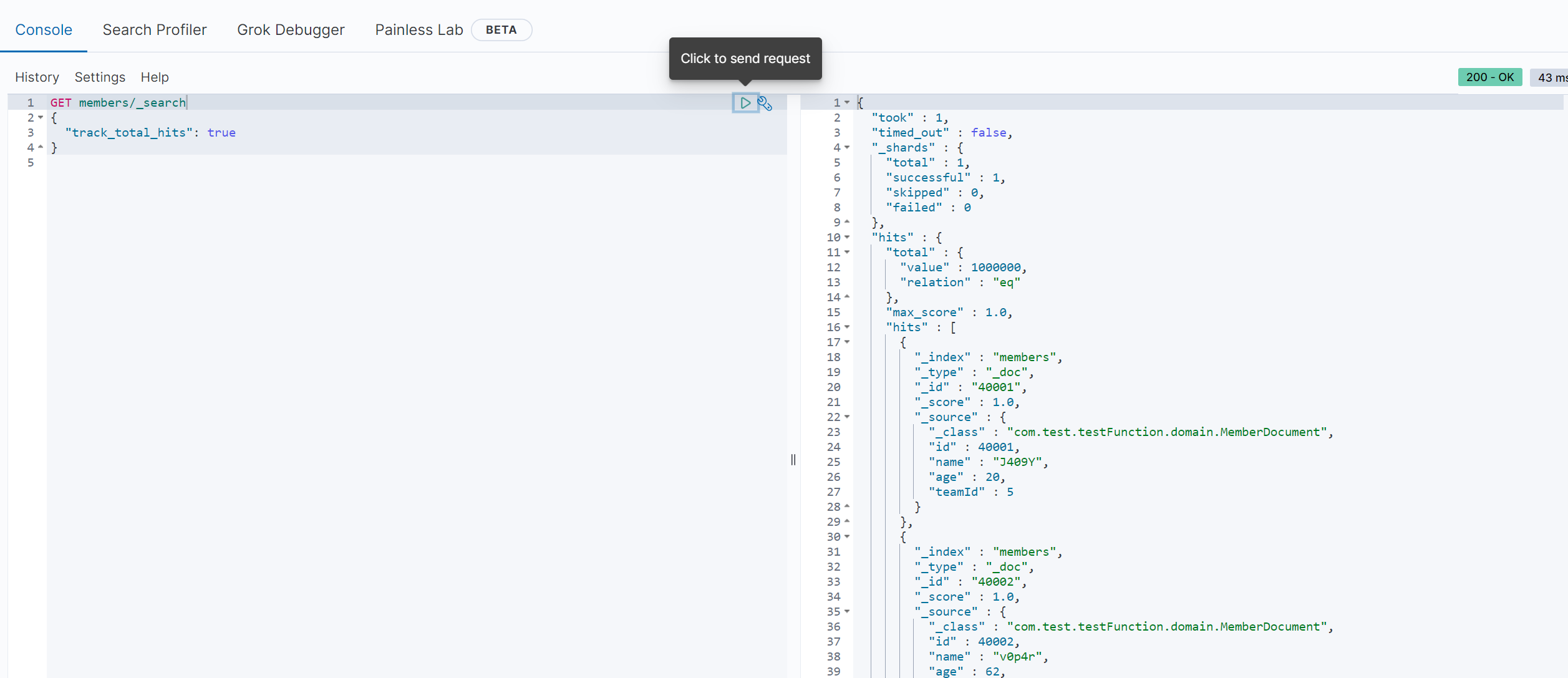
진짜 데이터를 검색해보자
직접 검색

rdbms 를 이용한 직접검색
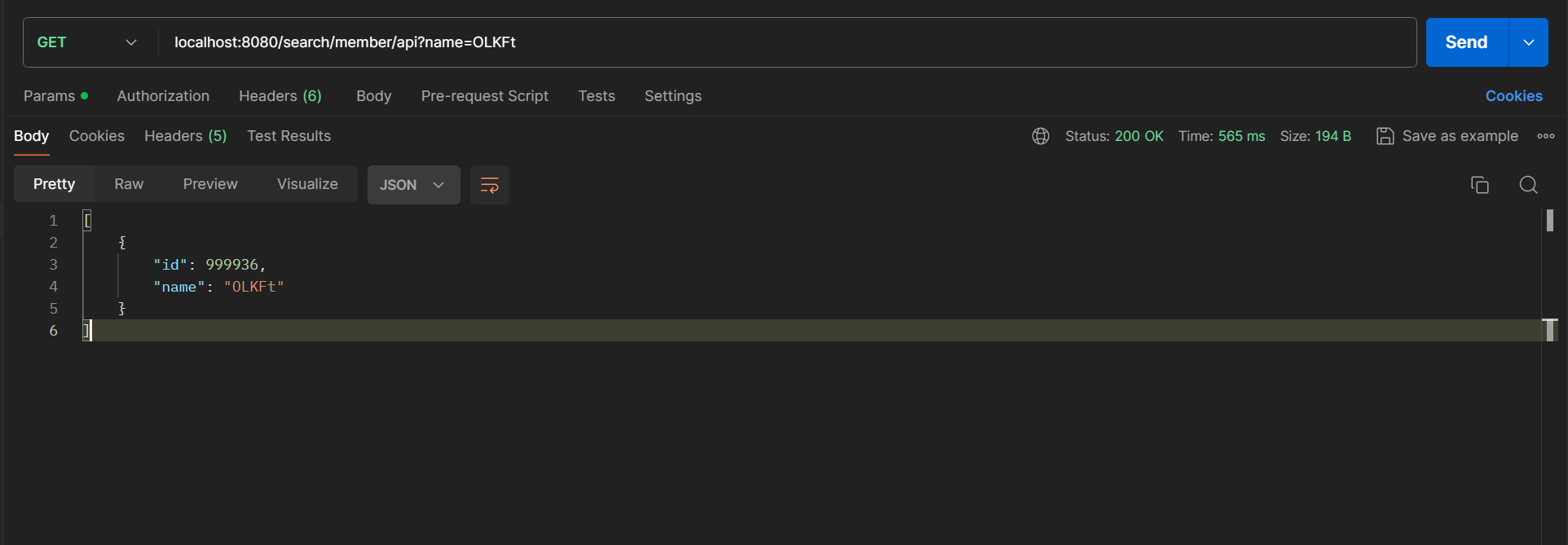
검색이 잘 수행이 되고 시간은 0.5초 언저리가 걸린다.
elastic search 를 이용한 직접 검색
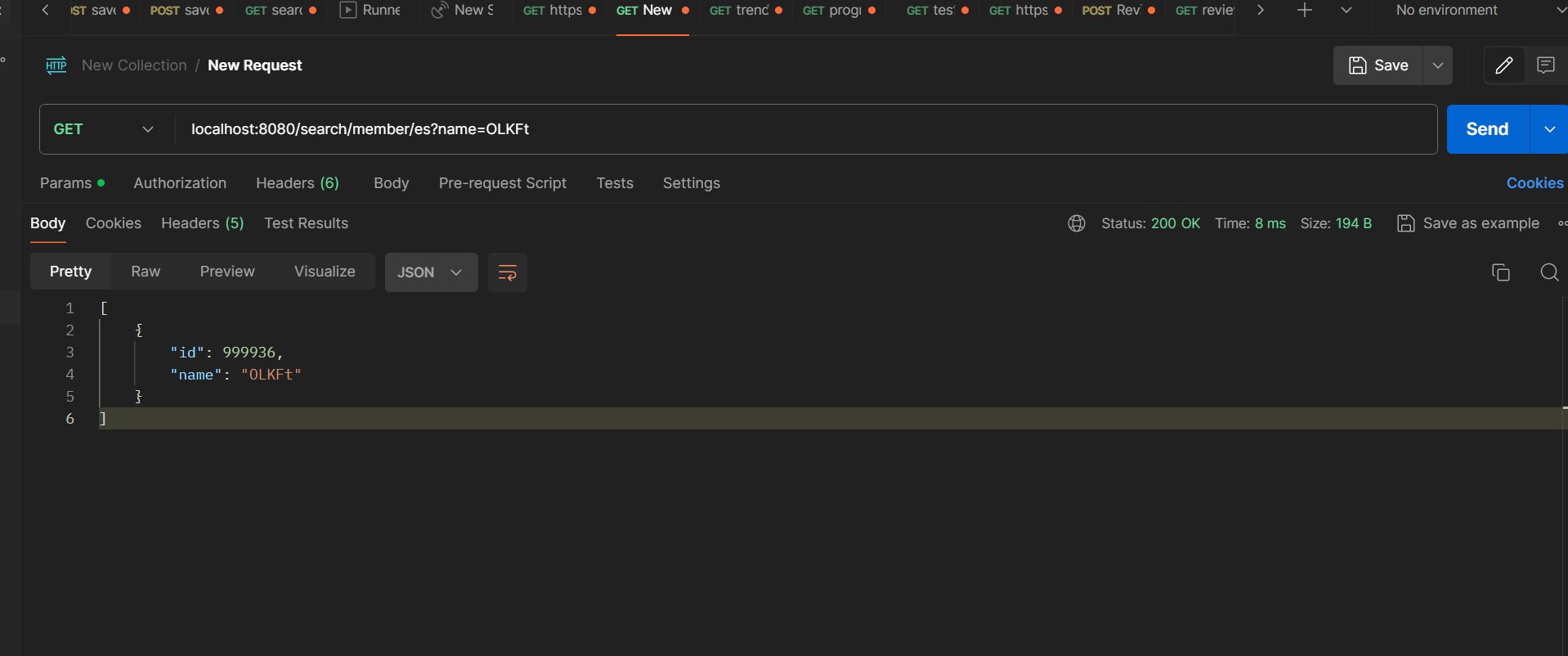
검색이 잘 수행이 되고 시간은 8ms 가 걸렸다. ㄷㄷㄷ 진짜 엄청 빠르구나
Like 키워드 검색
rdbms , like 키워드를 이용한 검색
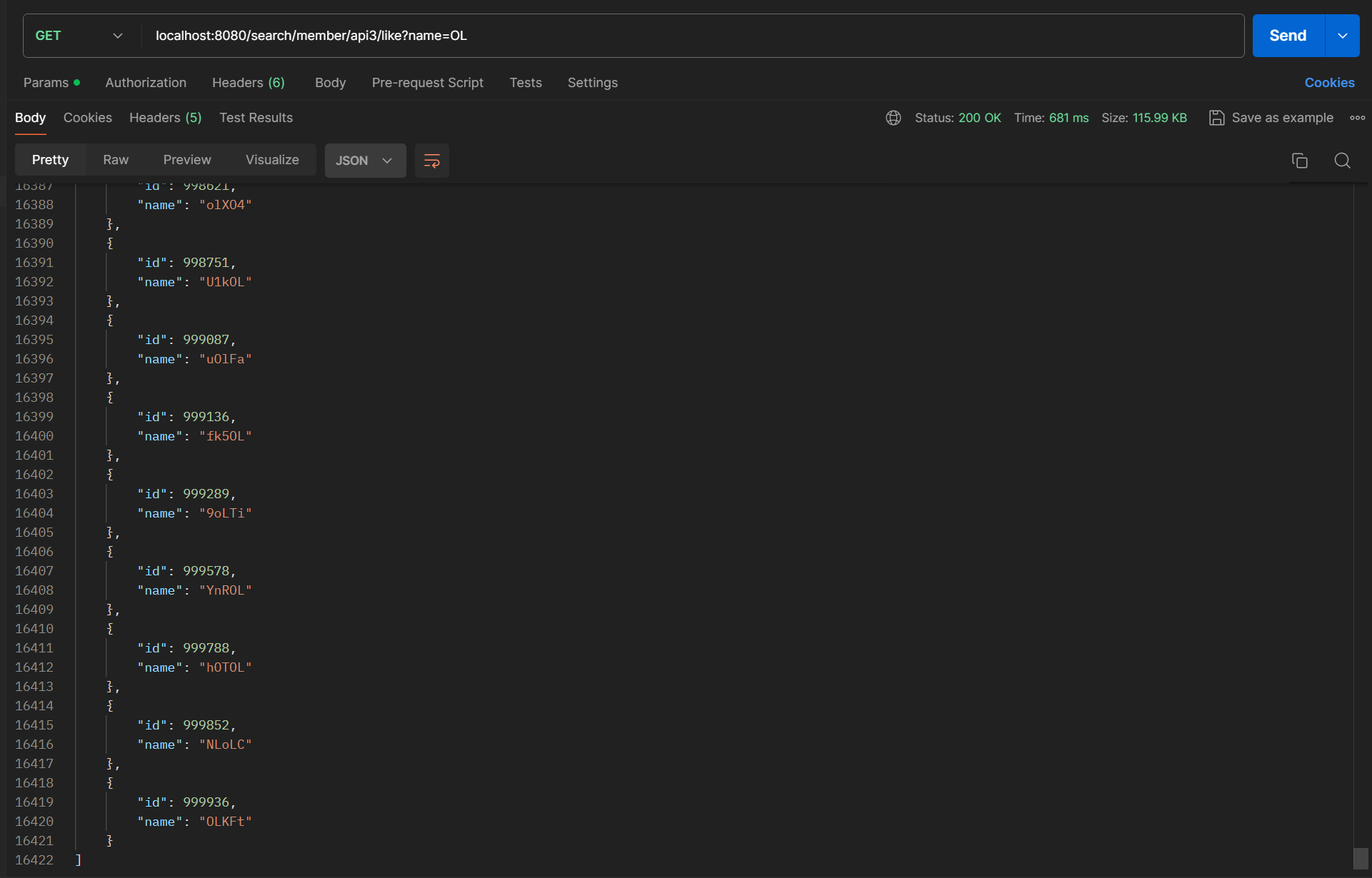
681ms 언저리가 걸렸다.
elastic search, like 키워드를 이용한 검색
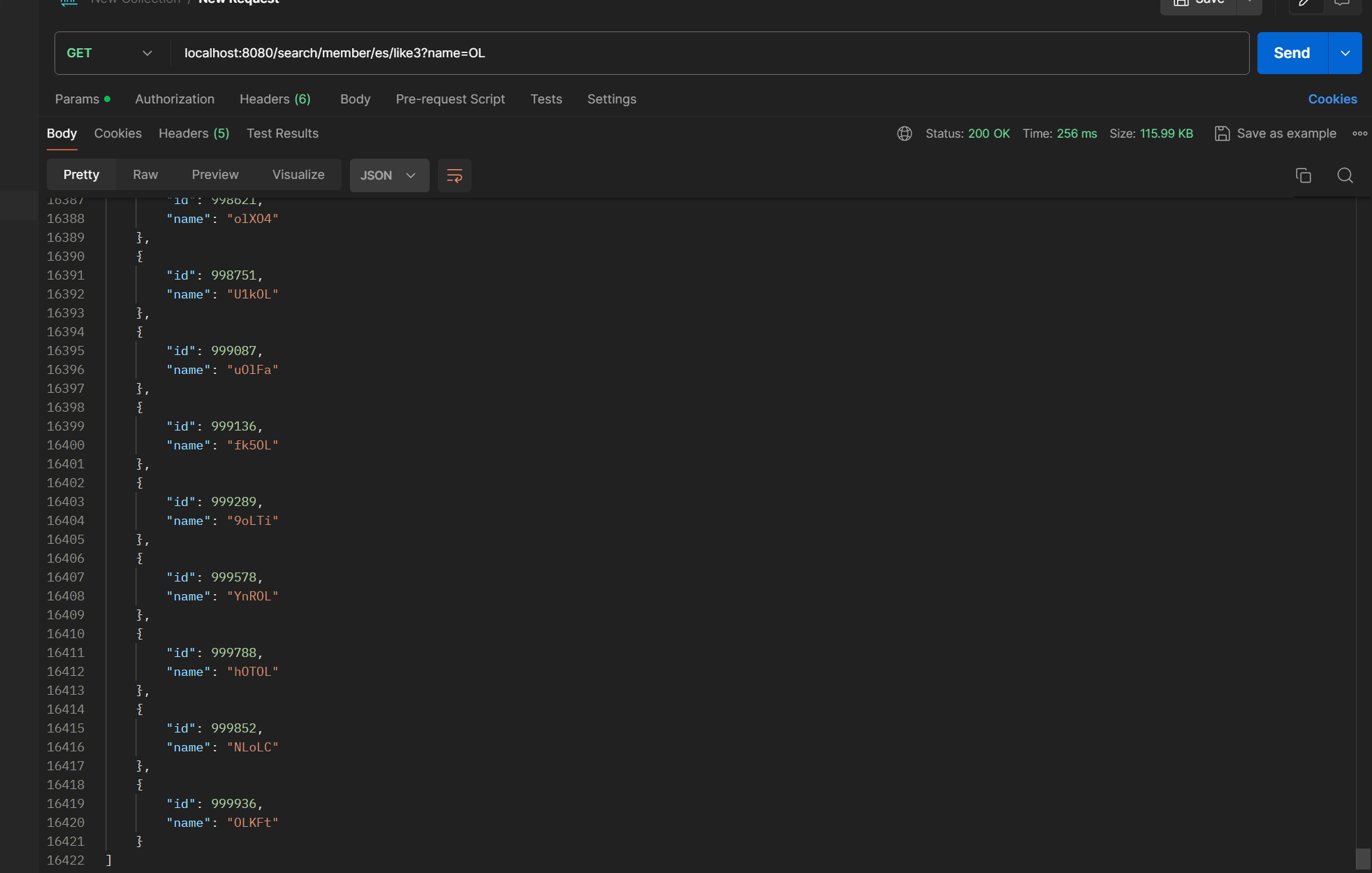
256 ms 로 rdbms 의 like 키워드를 통한 검색보다 3배 더 빠른 것으로 보았다.
후기
세팅하는게 정말 힘들었지만 elastic search가 왜 뛰어난 검색 엔진이라고 하는지 조금은 알 것 같다.
지금은 그렇게 많이 알지는 못하지만
어떨 때 필요하고 잘 쓰면 순전히 검색 측면에서 성능 향상이 일어난다는 것을 봤으므로 elastic search 에 대해 공부하고 싶은 마음이 샘솟고 있다!!!
