아래는 김영한 강사님의 스프링 JPA 강의를 듣고 핵심적인 내용을 정리한 것이빈다
프록시의 특징
단: 실제 사용 시점에서 헷갈렸던 것 중 findMember.getId()를 통해서 가져온 Member의 id를 출력하는 것은 실제 사용시점이 아니였다.
프록시 객체는 원본 Entity를 상속받아서 만들어지는데 instanceof는 상속에 사용했을때 이점이 있다.
그 이유는 성능 최적화와 JPA는 같은 트랜잭션 내에서는 동일성을 보장하려는 특성이 있기 때문
프록시에서는 영속성 컨텍스트를 이용해서 초기화를 하기 때문에 detach,em.close등으로 인해 준영속상태에 있을때 오류가 발생한다
참고
아래는 프록시가 초기화 되는 과정:
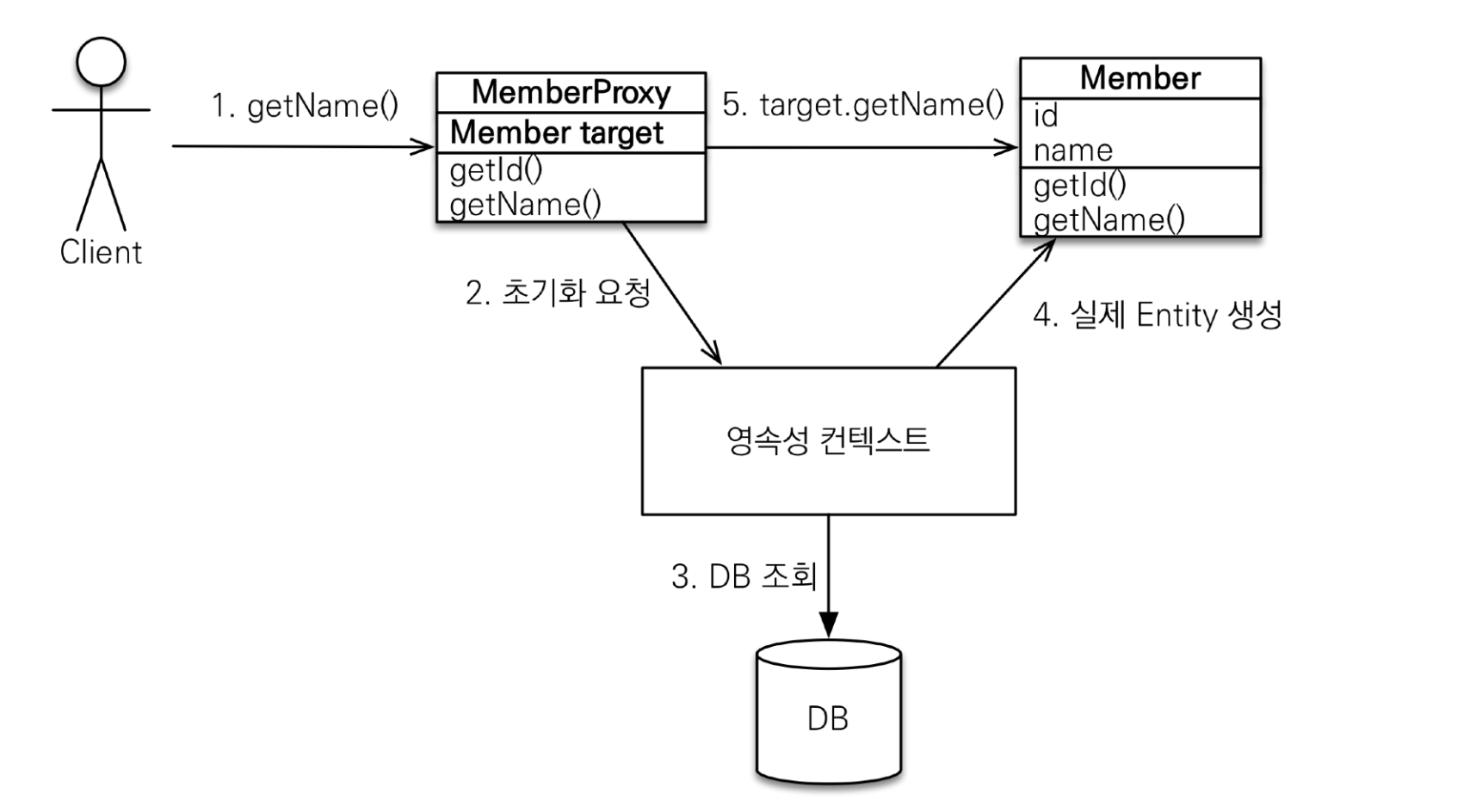
지연로딩vs즉시로딩
이론적으로는 member와 team을 함께 사용할 때는 Eager가 좋고(join으로 팀을 가져온다) 그렇지 않은 경우 member만 따로 쓰는 경우에는 지연로딩을 설정하여 쿼리 양을 줄일수 있다(팀은 프록시 객체이다)
지연로딩시: 실제 team을 사용하는 시점에 초기화된다.
하지만 실무에서는 N+1문제 등 때문에 Eager 의 사용을 지양하고 ManyToOne 이나 OneToOne 등 끝이 one으로 끝나는 것은 항상 FetchType=LAZY로 깐다.
만약 그럼에도 같이 가지고 오고 싶다면 이제는 FetchJoin을 사용한다.
주의점
N+1문제 발생가능:n+1문제란 JPQL에서 member를 다 가져온다 하면(em.createQueury("select m from Member m",Member.class).getResultList()) 1은 원래 쿼리를 예상했던 값(member),Team은 member를 다 가져온다음에 또 다시 쿼리를 날려서
team을 select 한다. 따라서 쿼리가 더 나간다. 멤버가 여러명이고 팀이 같으면 팀 쿼리 하나만 나가지만 팀이 다양할 경우 팀 쿼리가 여러개 나간다. 이것을 N+1문제라 하며 fetch join으로 동적으로 별개의 쿼리 대신 한 쿼리로 동적으로 원하는 것을 가져올 수 있다(select m from Member m join fetch m.team)
끝이 One으로 끝나는 관계의 경우 기본이 즉시로딩이기 때문에 수동으로 꼭 LAZY설정 할 것!
그래서?
지연로딩을 기본적으로 깔되 같이 가져오고 싶은 쿼리가 있을 경우에는 fetch join 등을 활용한다.영속성 전이:CASCADE
즉시로딩,지연로딩과는 관계가 없고 특정 엔티티를 영속 상태로 만들 떄 연관된 엔티티도 함께 영속상태로 만들고 싶을때 사용한다.
1대 다 관계인 parent 와 child가 있을때 em.persist(child1),em.persist(child2),em.persist(parent)보다는 em.persist(parent)로 한번에 영속화 할 수 가 있다.
언제 쓰는가?
하나의 부모가 자식들을 관리할때 의미가 있다. ex)첨부 파일 경로는 한 게시물에서만 관리하기 때문에 의미 있다. 그러나 다른 엔티티에서 관리하거나 다른데랑 관련이 있다면 쓰지 않는다.
소유자가 하나일때 쓰자
단일 Entity에 완전히 종속적일때
lifeCycle이 똑같을때
CASCADE 종류
고아 객체
부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제하고 orphanRemoval=true로 한다면 parent.getChildren().remove(0)을하면 DELETE 쿼리가 나간다. 이것도 역시 참조하는 곳이 하나일때, 특정 엔티티가 개인 소유할때만 사용해야 하고, OneToOne,OneToMany에서만 가능하다마치 CASCADETYPE.REMOVE처럼 동작 그러므로 ALL도 이것 포함.
하지만 orphanRemovval=true로 설정함으로써 부모에서 개별적으로 관리가 가능.
즉 종합적으로
CascadeType.ALL+orphanRemoval=true를 해주면
부모 엔티티를 통해서 자식 생명 주기를 관리가 가능하다.
임베디드 타입
기본 값타입을 모아서 만들어진다. int,String 과 같은 값 타입이라서 복사만 한다.비슷한 성격을 모아서 클래스를 만들고 @Embeddable은 만든 클래스에, @Embedded 는 값 타입을 사용하는 곳에 붙여준다
기본생성자가 필수이다.
해당 값 타입만 사용하는 의미있는 메소드를 만들 수 있다
값 타입이라서 엔티티의 생명주기에 의존
테이블과 달리 객체는 데이터 뿐만 아니라 메소드가 있기에 묶었을 떄 장점이 크다
한 엔티티에서 같은 값 타입을 사용하면 @AttributeOverrides,@AttributeOverride 를 사용햐서 컬럼명을 바꾸어서 사용가능
값타입은 불변으로!
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유할 경우 member.getAddress().setCity("new City")등으로 하면 위험하다
엔티티에 들어간 값이 다 바뀌기 때문이다. 이러한 상황을 방지하려면 복사를 해야 하는데 값 타입이 기본 타입이 아니라 객체 타입이라서 =으로 복사하다가 참조가
공유될 수 있다
그렇기 때문에 set을 없앰으로써 불변 객체로 만들고 그래도 수정이 필요하면 새로 인스턴스를 생성해서 만들어야 함
값 타입 컬렉션
데이터베이스에선...
컬렉션이 적용이 안되므로 1대 다로 별도의 db테이블을 따로 만들어 관리한다. 단 식별자 ID를 도입하면 값타입이 아니라 Entity가 되어버리므로 이 점을 주의한다사용법
ex@ElementCollection
@CollectionTable(name="FAVORITE_FOODS",
JoinColumns=@JoinColumn(name="MEMBER_ID"))
private Set<String> favoriteFoods=new HashSet<>;조회
기본적으로 컬렉션을 지연로딩으로 가지고 온다수정
주인엔티티의 연관된 모든 데이터를 삭제하고, 값타입 컬렉션에 있는 현재 값을 모두 다시 저장해서 쓰지 말아야 한다결론은
값 타입 컬렉션 대신에 엔티티로 일대다를 고려하고 Cascade+고아 객체 제거를 활용해서 값타입 컬렉션처럼 사용해야 함값타입 컬렉션이 진짜 단순할 때 값 타입 컬렉션을 쓴다,값이 바뀌어도 update 칠 필요 없을때 selection box 같은 곳에서 활용
식별자가 필요하고, 지속해서 값을 추적,변경해야 한다면 그것은 값타입이 아닌 엔티티이다
