BTREE를 통한 INDEX 장단점

MySql 의 기본 INDEX_type은 BTREE 이다.
장점
B-Tree 인덱스 구조를 이용하면 데이터에 빠르게 접근 할 수 있다. 아래 그림을 보자
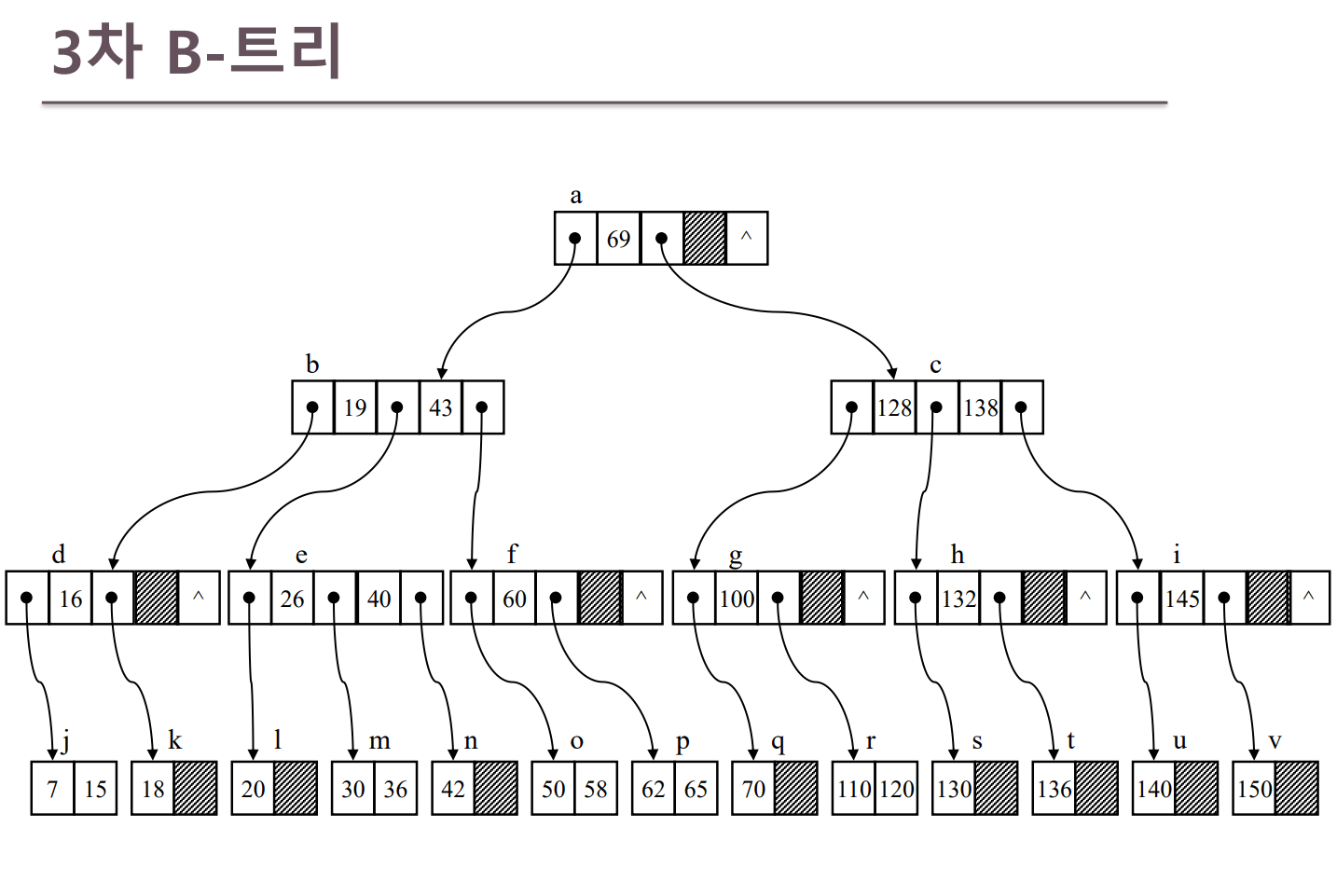
기존 그냥 단순 인덱스를 적용하지 않으면 숫자 70을 찾으려면 DB 전체를 순차적으로 검색할 수 밖에 없다.
7검색하고 30검색하고 120검색하고 136검색하고 150 검색하고 ...
이런식으로 말이다.
하지만 B-tree 를 적용하면
이제 70을 찾으려면 69보다 큰다-> 128보다 작다->100보다 작다 의 과정을 거쳐 단 3단계의 과정만 거치면 효율적으로 탐색할 수 있다. (심지어 128같은 경우는 한번만 거쳐도 찾을 수 있다).
만약 데이터가 몇만개 있다면???
인덱스를 적용안하고 최악의 상황은 진짜 몇만개의 데이터를 full scan으로 검사를 할 것이다.
하지만 위 그림과 같이 인덱스 구조를 사용하면 최소 log3(몇만개) 로 데이터를 쉽게 찾을 수 있다.
참고
위는 3차 B-트리 구조의 그림으로써 각 노드가 최대 3개의 서브트리를 가질 수 있는 구조이다.3차 B-트리 구조가 아니라 m 차 B-tree 구조라면 데이터를 logm(몇만개)로 데이터를 찾을 수 있을 것이다.
단점
데이터를 삽입할 때는 그만큼 힘들다.기존에 index를 적용안했을때는 그냥 뒤에다 데이터를 붙이기만 하니까 빨랐지만
위 그림처럼 index 를 적용 했을때는 삽입할 장소를 찾는 연산(logm(n))+ 삽입으로 인해 파생될 수 있는 노드들 구조 변경 으로 오버헤드가 생긴다. 이는 수정이나 삭제도 마찬가지로 구조 변경으로 인해 오버헤드가 생긴다. 하지만 수정이나 삭제를 위해 데이터를 찾는 작업 자체는 index로 인해서 빨라질 수 있다.
또한 index 관리를 위해 DB의 약 10% 정도 저장공간이 필요하다고 한다.
https://hongdosan.tistory.com/311
도입계기
현재 영화 및 tv 프로그램을
메인 페이지에서 또는 검색 페이지에서 보여줄 떄
각각의 프로그램에 대해서
DB에 저장되어 있는지 판단하고 저장되어 있지 않으면 DB에 저장하는 로직이 수행되고 있다.
따라서 DB에 프로그램이 쌓이면 쌓일 수록 insert 쿼리 보다는 이게 DB에 저장되어 있는지 판단하는 select 쿼리가 계속 수행이 된다.
더구나 DB에 프로그램 데이터가 쌓이면 쌓일수록 인기있는 프로그램을 검색하는 것은 자주 발생하고 그에 따라 select 쿼리가 많이 수행되고 인기없는 프로그램을 검색하는 것은 드문 일이므로 insert 쿼리가 드물게 수행된다.
이 data 를
where tmdb_program_id=? and type=?로 그냥 찾으면 전체 테이블을 순차적으로 검색하는 Full scan 을 하기 때문에 이 역시 데이터가 쌓이면 쌓일수록 성능이 감소할 수 밖에 없다.
따라서 시간이 지남에 따라 insert 쿼리의 숫자는 감소하고
select 쿼리의 숫자는 변함이 없고
update 나 delete 는 일어날 일이 아예 없으며
데이터가 쌓이면 쌓일 수록 성능이 걱정되었기 때문에
INDEX 도입을 검토하였다.
INDEX 적용 방법
인덱스를 적용할 칼럼이 여러개 일떄 적용 순서
순서는 중복성이 낮은 것(카디널리티가 높은것) -> 중복성이 높은 것(카디널리티가 낮은 것) 순으로 설정한다.
참고: https://jojoldu.tistory.com/243
나같은 경우 중복성이 낮은 tmdb_program_id 를 먼저 설정하여 성능을 향상 시켰다.
craete로 테이블 자동생성할때
엔티티에 아래와 같이
@Table(indexes = {@Index(name = "IDX_tm_db_program_id_type", columnList = "tmDbProgramId,type")})
public class Program {
를 붙여주면 된다
그러면
Hibernate: create index IDX_tm_db_program_id_type on program (tm_db_program_id, type)
2024-02-01 16:50:19.438 INFO 1920 --- [ main] p6spy : #1706773819438 | took 19ms | statement | connection 2| url jdbc:mysql://localhost:3306/ottifyjinu?serverTimezone=Asia/Seoul&characterEncoding=UTF-8
create index IDX_tm_db_program_id_type on program (tm_db_program_id, type)
create index IDX_tm_db_program_id_type on program (tm_db_program_id, type);show sql 로 위와 같은 쿼리가 실행된다는 것을 파악할 수 있고

mysql 에서 index 생성을 확인할 수 있다.
실제 쿼리가 인덱스를 타는지 확인하려면
select program0_.program_id as program_1_7_, program0_.average_rating as average_2_7_, program0_.created_year as created_3_7_, program0_.poster_path as poster_p4_7_, program0_.review_count as review_c5_7_, program0_.title as title6_7_, program0_.tm_db_program_id as tm_db_pr7_7_, program0_.type as type8_7_ from program program0_ where program0_.tm_db_program_id=68482 and program0_.type='TV';이후 이 쿼리를 mysql workbench에서 EXPLAIN 을 붙여서 확인하면 된다.

이렇게 index 를 타는지 확인할 수 있다.
이미 테이블 생성되어 있을때
mysql workbench에서
CREATE INDEX IDX_tm_db_program_id_type ON program (tm_db_program_id,type);를 입력한다.
이 정도만 해도 쿼리가 실행되면 index가 적용되는지 확인이 가능하지만
코드에 명시를 위해서
@Table(indexes = {@Index(name = "IDX_tm_db_program_id_type", columnList = "tmDbProgramId,type")})
public class Program {이렇게 적어주는게 좋을 것같다.
