이전에...
이전에 TMDB API 를 가지고 ottify 프로젝트를 진행할 때
이 수많은 데이터를 DB에 저장하는 방법을 찾지 못했다.
당시에는 출시 기간을 기준으로 영화 데이터를 분류해서 가져오는 것이 유일한 방법이라고 생각했고, 이 방식을 사용할 때
페이지가 500 페이지가 넘어가면 TMDB 자체에서 제한을 해주기에 사용하기 힘든 방법이였다.
따라서 그 때는 임시 방편으로 사용자가 검색 등 어떤 행위를 수행할 때 DB에 먼저 저장을 하고 JSON 형태로 프론트엔드에 전달하는 방식을 사용하였지만,
당연하게도 이는 동시성 문제를 수반할 수 밖에 없었다.
하지만 시간이 흐른 후 새로운 방법을 찾을 수 있었다.
TMDB를 사용한 프로젝트를 하는 사용자에게 도움이 되는 자료가 되었으면 좋겠다.
TMDB 데이터 파일로 저장
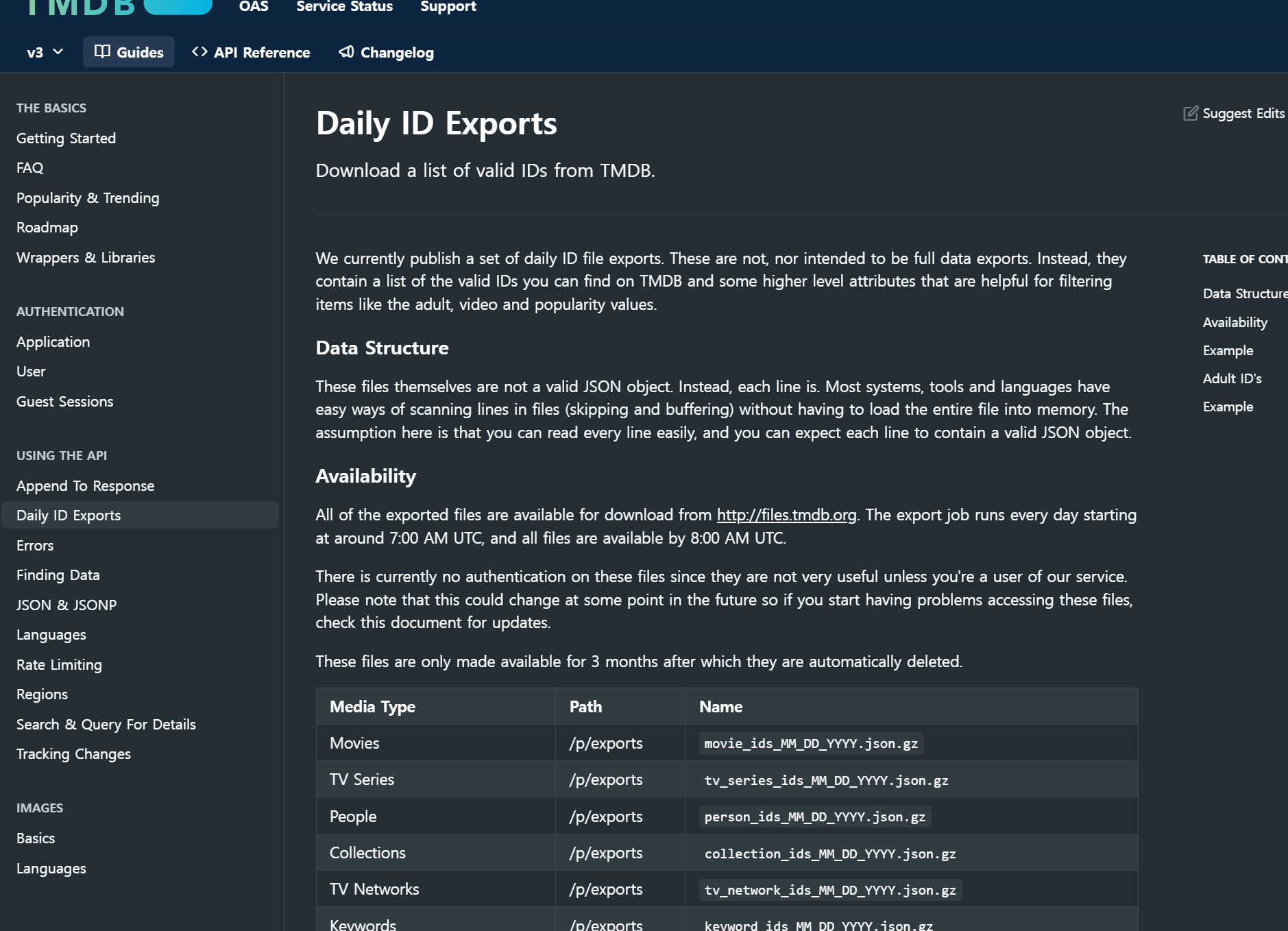
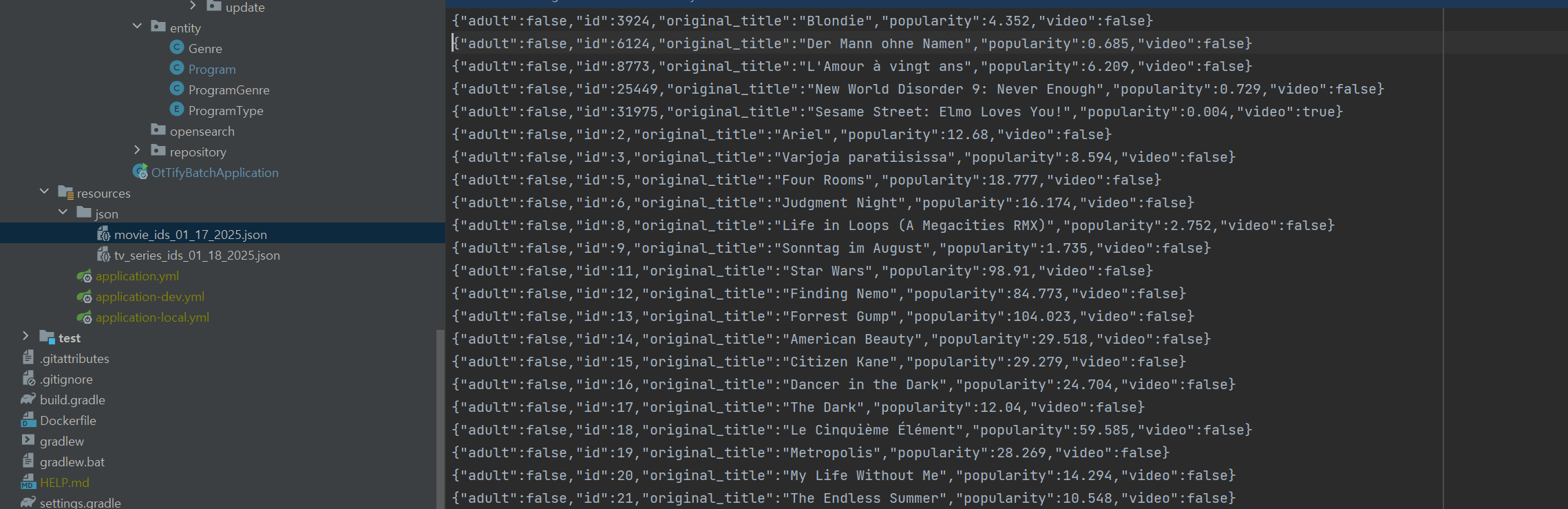
이 화면에서 원하는 대로 조건을 수행하면 JSON LIST 형태의 일종의 JSON 파일을 다운 받을 수 있다.
이를 프로젝트 구조 내 resources 하위에 저장을 한다.
스프링 배치를 사용한 이유
-
스프링 배치는 실패한 배치 작업을 중단된 지점에서 다시 시작하거나 Skip 을 할 수 있는 기회가 주어집니다.
따라서 대용량의 데이터를 이제 open api 를 사용하여 저장을 할 것인데 이 과정에서 오류가 발생한다면 실패한 지점에서부터 다시 시작한다는 이점이 막강해 질 것이라고 느꼈습니다. 실제로도 이득을 많이 보았구요! -
영화와 TV 데이터는 매일 변경됩니다. 따라서 TMDB 도 이에 맞추어 변경된 영화 및 TV 아이디를 제공하여 줍니다. 이를 위해선 스케쥴링을 사용하여야 하지만 스프링 배치 없이 제대로 동작하는지 확인하는 것은 매우 귀찮은 작업이 될 것입니다.
하지만 스프링 배치를 사용하면 스프링 배치와 연관된 Job 과 Step 에 대한 메타테이블을 제공 해주므로 제대로 동작했는지 확인하는 것이 매우 용이해 질 것이라고 생각했습니다.
아래 사진은 실제로 매일 배치와 스케쥴링을 통해 데이터 일일 변경에 대한 저장이 완료되었는지 확인할 수 있는 화면입니다.
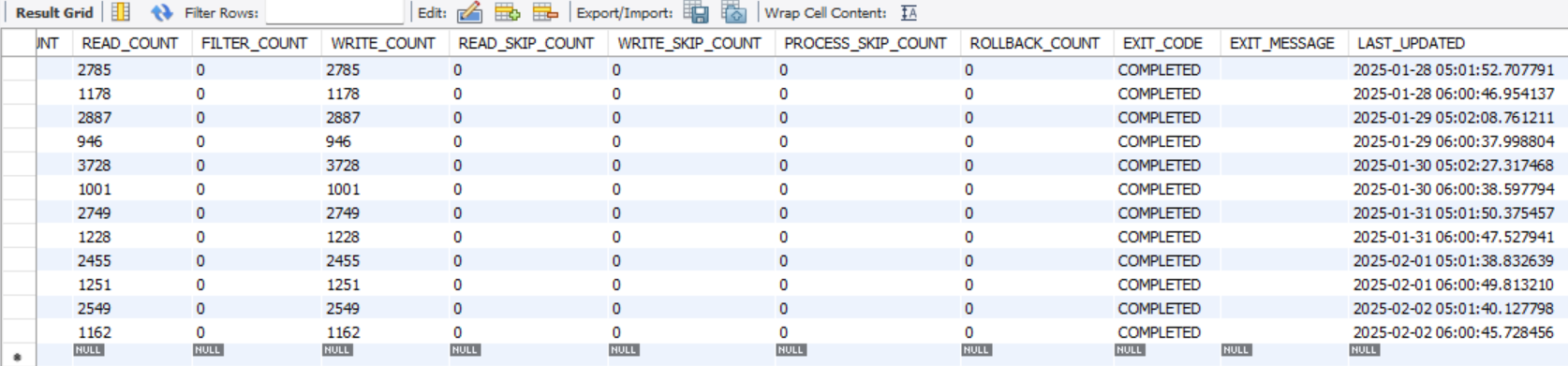
실제로 새벽 5시와 6시 매일 배치작업을 통해 작업이 잘 완료되었는지 편리하게 확인하고 있습니다.
스프링 배치를 사용
Job & Step
@Slf4j
@Configuration
@RequiredArgsConstructor
public class MovieBasicSaveJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final ProgramRepository programRepository;
private final EntityManagerFactory entityManagerFactory;
private final WebClient webClient;
private final GenreRepository genreRepository;
private final TaskExecutor apiExecutor;
@Bean
public Job movieBasicSaveJob(Step movieBasicSaveStep) {
return new JobBuilder("movieBasicSaveJob",jobRepository)
.start(movieBasicSaveStep)
.build();
}
@Bean
public Step movieBasicSaveStep() {
return new StepBuilder("movieBasicSaveStep",jobRepository)
.<MovieJsonReadDto, Future<Program>>chunk(50,transactionManager)
.reader(jsonMovieItemReader())
.processor(asyncMovieApiProcessor())
.writer(asyncJpaMovieBasicSaveWriter())
.faultTolerant()
.skip(NotFoundException.class)
.skipLimit(Integer.MAX_VALUE)
.retry(Exception.class)
.retryLimit(3)
.backOffPolicy(new FixedBackOffPolicy() {{
setBackOffPeriod(2000); // 2초 대기
}})
.noRetry(NotFoundException.class)
.allowStartIfComplete(false)
.build();
}위와 같이 기본적인 Job 과 Step 을 구성하여 준다.
- Step 에서 기본적인 reader , processor, writer 를 설정한다.
- 이 Step 과정에서 어떤 오류가 생기면 2초를 기다린 후 3번까지 시도를 한다.
- 만약
NotFoundException이 발생한다면 Retry 를 하지 않도록 설정한다.
이외의 설정은 추후 설명
Reader
사용할 데이터를 먼저 가지고 오자.
@Bean
public FlatFileItemReader<MovieJsonReadDto> jsonMovieItemReader() {
return new FlatFileItemReaderBuilder<MovieJsonReadDto>()
.name("movieIdReader")
.resource(new ClassPathResource("json/movie_ids_01_17_2025.json"))
.lineMapper(new JsonLineMapper())
.strict(false) // strict 모드를 비활성화
.build();
}아까 저장한 파일을 바탕으로 한줄 씩 정보를 읽는다.
public class JsonLineMapper implements LineMapper<MovieJsonReadDto> {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public MovieJsonReadDto mapLine(String line, int lineNumber) throws Exception {
return objectMapper.readValue(line,MovieJsonReadDto.class);
}
}위 코드를 통해서 한줄 씩 읽은 program 정보를 MovieJsonReadDto 에 매핑한다.
(추가적으로 아까 말했던 것처럼 중간에 오류가 나서 배치작업이 멈추더라도 우리가 다운 받은 Json 파일에서 어느 줄 까지 읽었는지 저장하는 메타테이블이 존재한다.)
Processor
이제 이 읽은 데이터를 바탕으로 어떤 process 를 진행할 지 코드를 작성한다.
나는 Process로 아까 읽었던 정보에서 tmDbProgramId 값을 바탕으로 API 요청을 보내서 그 반환된 응답값을 Program Entity 에 담는 작업을 선택했다.
@Bean
public AsyncItemProcessor<MovieJsonReadDto, Program> asyncMovieApiProcessor(){
final AsyncItemProcessor<MovieJsonReadDto,Program> processor = new AsyncItemProcessor<>();
processor.setDelegate(movieApiProcessor());
processor.setTaskExecutor(apiExecutor);
return processor;
}
@Bean
public ItemProcessor<MovieJsonReadDto,Program> movieApiProcessor(){
return new ItemProcessor<MovieJsonReadDto, Program>() {
@Override
public Program process(MovieJsonReadDto item) throws Exception {
long movieId= item.getId();
log.info("API 호출 현재 영화: {}",movieId);
OpenApiMovieDetailDto openApiMovieDetailDto = getApiProgram(movieId);
String originalCountryName = (openApiMovieDetailDto.getProductionCountries() == null
|| openApiMovieDetailDto.getProductionCountries().isEmpty())
? null : openApiMovieDetailDto.getProductionCountries().get(0).getName();
Program program = getProgram(item, openApiMovieDetailDto, originalCountryName);
openApiMovieDetailDto.getTmDbGenreInfos().forEach(genreInfo -> {
Genre genre = genreRepository.findByTmDbGenreId(genreInfo.getId()).orElseThrow();
program.addGenre(genre);
});
return program;
}
private Program getProgram(MovieJsonReadDto item, OpenApiMovieDetailDto openApiMovieDetailDto,
String originalCountryName) {
Program program = Program.builder()
.tmDbProgramId(item.getId())
.title(openApiMovieDetailDto.getTitle())
.originalTitle(openApiMovieDetailDto.getOriginal_title())
.createdDate(openApiMovieDetailDto.getReleaseDate())
.createdYear(openApiMovieDetailDto.getReleaseDate().length() >= 4 ? openApiMovieDetailDto.getReleaseDate().substring(0, 4) : null)
.originalCountry(originalCountryName)
.backDropPath(openApiMovieDetailDto.getBackdrop_path())
.type(ProgramType.Movie)
.posterPath(openApiMovieDetailDto.getPoster_path())
.overView(openApiMovieDetailDto.getOverview())
.tagLine(openApiMovieDetailDto.getTagline())
.build();
return program;
}
};
}- 일단 ItemProcessor에서는 위에서 설명했던 것처럼 OpenApi 를 호출한다.
private OpenApiMovieDetailDto getApiProgram(long id) throws NotFoundException {
try{
OpenApiMovieDetailDto openApiProgramDto = webClient.get()
.uri("/movie/"+id+"?language=ko")
.retrieve()
.bodyToMono(OpenApiMovieDetailDto.class)
.block();
return openApiProgramDto;
}catch (WebClientResponseException e){
if(e.getMessage().contains("404 Not Found")){
throw new NotFoundException();
}
}
return null;
}open api 를 통해 프로그램 상세 정보를 호출하는 코드는 위와 같고 만일 정상적으로 요청을 보냈는데도 404 Not Found 라는 에러가 Tmdb에서 발생한다면 아마 Tmdb 내에서 삭제한 정보일 것이다. 그렇기 때문에 Throw New NotFoundException 을 내보내서 아까 Step 내에서 이와 관련된 오류는 retry를 안하도록 설정했다.
Processor 를 비동기 처리로 해야 하는 이유!
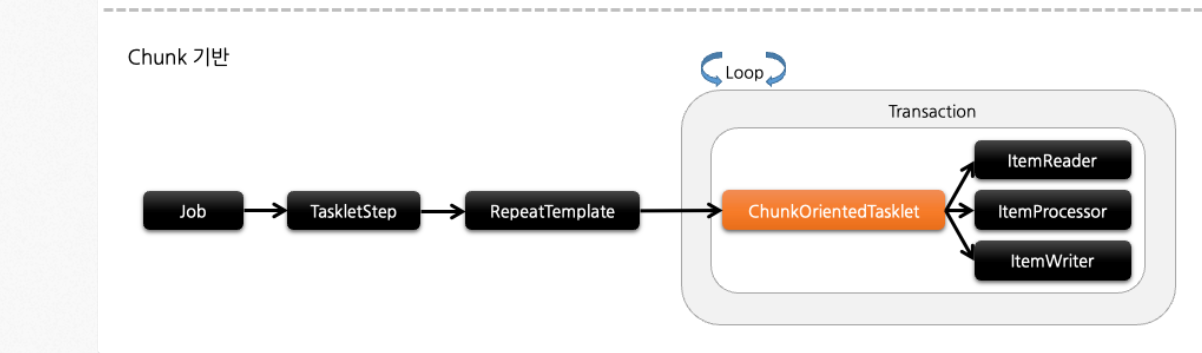
배치 그림
ItemProcessor 를 동기적인 방식으로 정상적으로(?) 사용한다면 아래와 같은 그림의 흐름을 가진다.
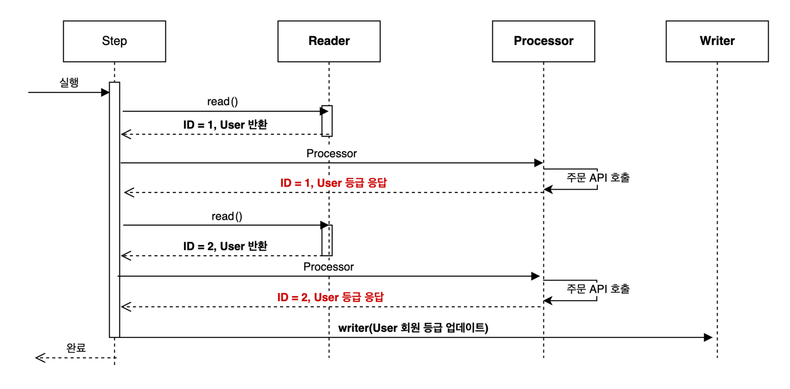
참고: https://tech.kakaopay.com/post/spring-batch-performance/
TMDB 단점
하지만 TMDB 에는 치명적인 단점이 있다.
이상하게도 최근에 검색을 한 프로그램 상세 정보는 굉장히 빠른 시간 내에 정보를 전달해 주는데 호출을 오래 하지 않은 프로그램은 호출하는데 300~500 ms 의 시간이 지나야 겨우 호출을 한다. (아무래도 TMDB 내부에 캐시 관련된 기능이 있지 않을까 한다)
이러한 상황에서 동기적으로 호출을 한다면
Json 파일에서 프로그램 하나 읽기 - > OpenApi 호출을 통한 프로그램 정보 받아오기 (500ms) -> Json 파일에서 프로그램 하나 읽기 -> open API 호출을 통한 프로그램 정보 받아오기 (500ms) 이 과정을 chunk size 만큼 반복을 하게 된다.
그러면 chunk size 가 50이라고 가정하면 최소 500ms * 50 즉 25 초가 지나야 50개를 DB에 저장할 수 있게 된다. (물론 최악의 상황이긴하다.)
병목 구간 => Open API 호출
따라서 Open API 를 호출하는 구간은 병목 구간이기 때문에 이를 해결하기 위해 ItemProcessor 를 비동기적으로 활용한다.
단순히 하나씩 처리하는 것이 아니라
processor 에 진입할 떄마다 새로운 쓰레드 내에서 open api 를 호출하고 메인 쓰레드는 계속 진행한다면?
한 프로그램에 대해 open api 를 호출하는데 걸리는 시간이 500ms 라도 chunk size 만큼 거의 한 번에 진행한다.
프로그램 1 호출 (300ms)
프로그램 2 호출 (300ms)
프로그램 3 호출 (300ms)
을 미묘하지만 거의 동시에 호출한다고 해도 무방할 것이다.
동기적으로 실행하면?
실제로 실행해보면 초당 4개에서 8개까지 api 호출을 하는 것이 최대였다. 많이 쳐줘야 초당 10 정도 호출을 할 수 있었다.
Chunk Size 와 쓰레드 개수는 몇개로?
TMDB 에서 제공하는 API limit 이 존재한다. 초당 50개의 API 를 호출하여 정보를 받아볼 수 있다.
따라서 ChunkSize 와 쓰레드 개수를 50으로 설정해 주었다.
.<MovieJsonReadDto, Future<Program>>chunk(50,transactionManager)
.reader(jsonMovieItemReader())
.processor(asyncMovieApiProcessor())- 비동기 처리를 위해서
Future<Progam>을 선언한다. - chunk size 는 위 처럼 50 이다.
@Configuration
public class ProgramExecutor {
@Bean
public TaskExecutor apiExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(50);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(0);
taskExecutor.setThreadNamePrefix("Executor-Batch-");
return taskExecutor;
}
}- corePoolSize 는 50으로 항상 존재하게 하고 , 딱 이정도만 존재하게 해두었다.
어차피 이 이상으로 쓰레드가 넘어갈일이 없다. chunk size 를 50으로 잡았기 때문이다.
Writer
위 참고 자료에 따르면
ItemProcessor for an item on a new thread.
Once the item completes, the Future is passed to the AsyncItemWriter to be written.이 문장을 통해서 Writer 에 Future 타입의 클래스가 도착한다는 것을 알 수 있다
(우리의 경우 Future 이겠다)
따라서 이에 맞추어 코드를 작성한다.
@Bean
public JpaItemWriter<Program> jpaMovieBasicSaveWriter(EntityManagerFactory entityManagerFactory) {
JpaItemWriter<Program> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
return writer;
} @Bean
public AsyncItemWriter<Program> asyncJpaMovieBasicSaveWriter(){
final AsyncItemWriter<Program> writer = new AsyncItemWriter<>();
writer.setDelegate(jpaMovieBasicSaveWriter(entityManagerFactory));
return writer;
}대표적을 ItemWriter 에서는 JpaItemWriter 을 사용할 수도 JdbcItemWriter 을 사용할 수도 있다.
만약 JdbcItemWriter 를 사용한다면 배치 형태로 insert 할 수 있다.
예를 들어 insert into values (3,3,3), (3,3,3),(3,3,3)... 이렇게 여러개의 데이터를 하나의 쿼리를 통해 요청을 보내는 과정을 통해 네트워크 IO 를 줄이는 것이 가능하지만
사실상 나의 경우에서 최대한 이 부분에서 성능을 줄여봤자, 시간을 줄여봤자 앞에 API LIMIT이 50 인 곳이 병목지점으로 남아있어서 유의미한 성능 개선을 기대하기 어렵다.
따라서 그냥 JpaItemWriter 를 사용하였다.
추가적으로 Jpa 의 기능 중 하나인 일대다 연관관계 도 사용하고 있었기 때문이다.
참고: https://jojoldu.tistory.com/339
결과 : 성능 개선
최대 초당 8~9 에서 1.5 초당 50 으로 성능이 5배 개선되었다.
관리
관리도 TMDB의 change 를 사용하여 특정 기간에 무엇이 바뀌었나 확인할 수 있다.
스케쥴링을 통해서 매일 오전 5시와 6시에 변경 사항에 대해 업데이트를 수행한다.
위의 save 코드와 별반 다를 바 없기 때문에 코드는 생략한다.
주의할 점
비동기 처리를 위한 쓰레드 내에서
delete 나 이런 부분을 호출할 수 없다.
만약 그렇게 된다면 예외 처리가 날 것이다.
위 사진과 같이 트랜잭션의 범위는 꽤 크지만
쓰레드가 새로 할당 되었을 때 그곳은 영속성 컨텍스트가 미치지 않는 곳이다.
따라서 delete 를 호출하고 싶다면 별도의 @Transactional 을 가진 메소드에서 호출해야 할 것이다.
물론 변경감지는 다르다.
비동기 쓰레드 내에서 수정을 한 이후에 마지막으로 ItemWriter 에서 write 혹은 doWrite 를 호출하면서 변경감지를 통해 동작하기 때문이다.
만약 비동기 쓰레드모다 메인 쓰레드가 먼저 끝나면 변경 감지가 동작하지 않겠지만 우리는 그럴일이 없다.
