
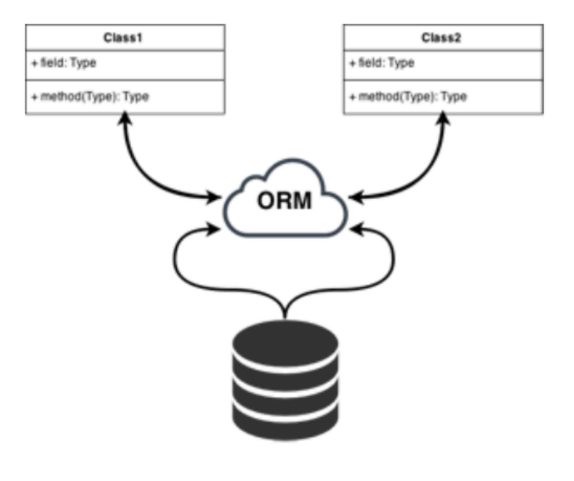
ORM이란?
ORM(Object-relatinal mapping)이란 객체(클래스)와 관계(관계형 데이터 베이스)와의 설정을 의미 합니다.
‘객체로 연결을 해준다’는 의미로, 어플리케이션과 데이터베이스 연결 시 SQL언어가 아닌 어플리케이션 개발언어로 데이터베이스를 접근할 수 있게 해주는 툴입니다.
객체 지향 프로그래밍은 클래스를 사용하고 관계형 데이터 베이스는 테이블을 사용합니다. 여기서 객체 모델과 관계형 모델간에 불일치가 존재 하는데 이 객체간의 관계를 바탕으로 SQL을 자동 생성하여 불일치를 해결 하는 것이 ORM입니다.
ORM은 SQL문법 대신 어플리케이션의 개발언어를 그대로 사용할 수 있게
함으로써, 개발 언어의 일관성과 가독성을 높여준다는 장점을 갖고 있습니다.
Object <= 매핑 => DB데이터에서 매핑의 역할을 하는 것이 ORM이라 할수 있습니다.
ORM 장점
◆ 객체 지향적 코드로 인해 더 직관적이고 비즈니스 로직에 집중할 수 있도록 도와준다.
- CRUD을 위한 긴 SQL 문장을 작성할 필요가 없다. (여전히 쿼리작성은 필요하지만)
- 각 객체(Model)별로 코드를 작성하여 가독성을 높여 준다.
- SQL의 절차적 접근이 아닌 객체적인 접근으로 생산성을 높여 준다.
◆ 재사용 및 유지보수의 편리성이 증가한다.
- 매핑 정보가 명확하여, ERD를 보는 것에 대한 의존도를 낮출 수 있다.
- ORM은 독립적으로 작성이 되어 있고 해당 객체들은 재사용이 가능 하다.
◆ DBMS에 대한 종속성이 줄어든다.
- 대부분의 ORM은 DB에 종속적이지 않다.
- 개발자는 Object에 집중함으로 DBMS를 교체하는 극단적인 작업에도 비교적 적은 리스크
와 시간이 소요된다. - 종속적이지 않다는 것은 구현 방법 뿐만 아니라 많은 솔루션에서 자료형 타입까지 유효하
다.
(*종속성: 프로그램 구조가 데이터 구조에 영향을 받는 것을 의미함.)
ORM 단점
◆ 완벽한 ORM만으로는 구현하기가 어렵다.
- 사용하기에는 편하지만 설계에는 매우 신중해야 한다.
- 프로젝트의 복잡성이 높아질 경우 난이도 또한 올라갈 수 있다.
- 잘못 구현된 경우 속도 저하 및 심한 경우 일관성이 무너지는 문제점이 생길 수 있다.
◆ 프로시저가 많은 시스템에서는 ORM의 객체 지향적인 장점을 활용하기
어렵다.
- 이미 프로시저가 많은 시스템에서는 다시 객체로 바꿔하 하며, 그 과정에서 생산성 저하
혹은 리스크가 발생할 수 있다.
(*프로시저: 특정작업을 위한 프로그램의 일부. 함수와 같은 의미)
데이터베이스를 쉽게 사용할 수 있게 해주는 ORM 알아보기
SQL 쿼리와 ORM을 비교해 보자. 다음과 같은 형태로 구성된 질문 테이블에 데이
터를 입력한다고 가정해 봅니다.

이렇게 구성된 question 테이블에 새로운 데이터를 삽입하는 쿼리는 보통 다음처럼
작성한다.

하지만 ORM을 사용하면 쿼리 대신 파이썬 코드로 다음처럼 작성할 수 있다.

코드에서 Question은 파이썬 클래스이며, 이처럼 데이터를 관리하는데 사용하는 ORM 클래스를 모델이라고 합니다. 모델을 사용하면 내부에서 SQL 쿼리를 자동으로 생성해 주므로 직접 작성하지 않아도 된다. 즉, 파이썬만 알아도 데이터베이스 처리를 할수 있습니다.
예시로 FastAPI + SQLAlchemy 사용하기
SQLAlchemy : SQLAlchemy는 파이썬에서 ORM이 가능하도록 해주는 툴킷이다.
SQLAlchemy를 이용하면 훨씬 더 편하게 파이썬에서 DB를 제어할 수 있습니다.
SQLAlchemy에서 지원하는 DB는 아래와 같습니다.

SQLAlchemy 설치하기
> pip install sqlalchemyDB 생성하기
database.py파일을 아래와 같이 작성합니다.
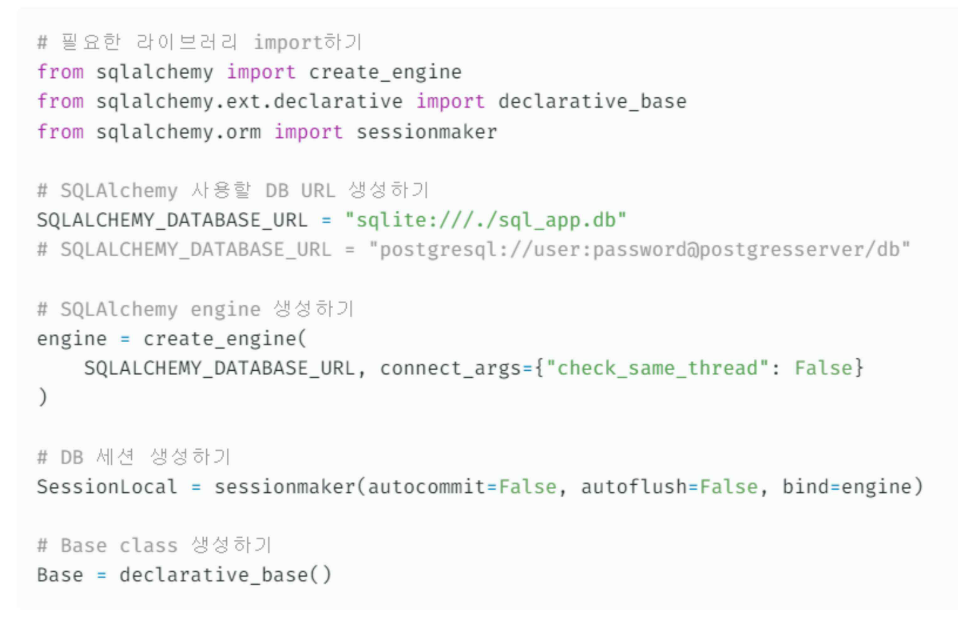
CreateaBaseclass
declarative_base함수로 부터Base클래스를 리턴받을 수 있습니다.
이 클래스는 나중에 객체를 테이블로 맵핑하는 ORMmodel이 됩니다.
SQLAlchemy models 생성하기
models.py는 아래와 같습니다.

sql_app/database.py에서 declarative_base함수를 통해 얻은Base클래스를 가져옵니다. 그리고 이클래스를 상속받는 커스텀 클래스를 선언함으로써 우리가 사용할 수있는 ORM model이 생성 됩니다. 현재 위에서는 User와 Item은 Base를 상속받은 클래스로 각각의 테이블 ‘데이터의 집’이 만들어 집니다.
데이터집이 만들어 졌다면 아래는 실제 데이터베이스에 들어갈 ‘레코드(=record)’, 데이터 자체/실제 내용물을 생성하는 함수 코드입니다.
CRUD기능들 작성한 메소드들 중 레코드/ 데이터 추가 기능의 함수 입니다.
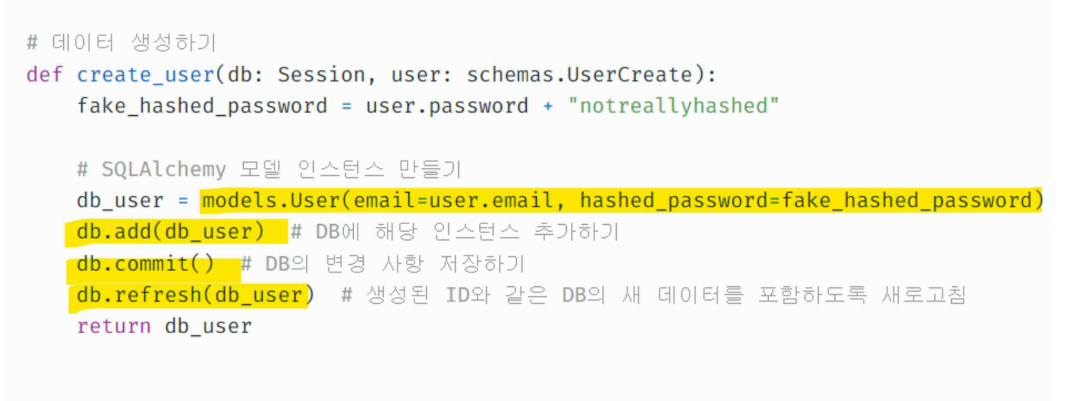
아래 코드는 Item테이블에 레코드 추가 기능 의 함수 입니다.

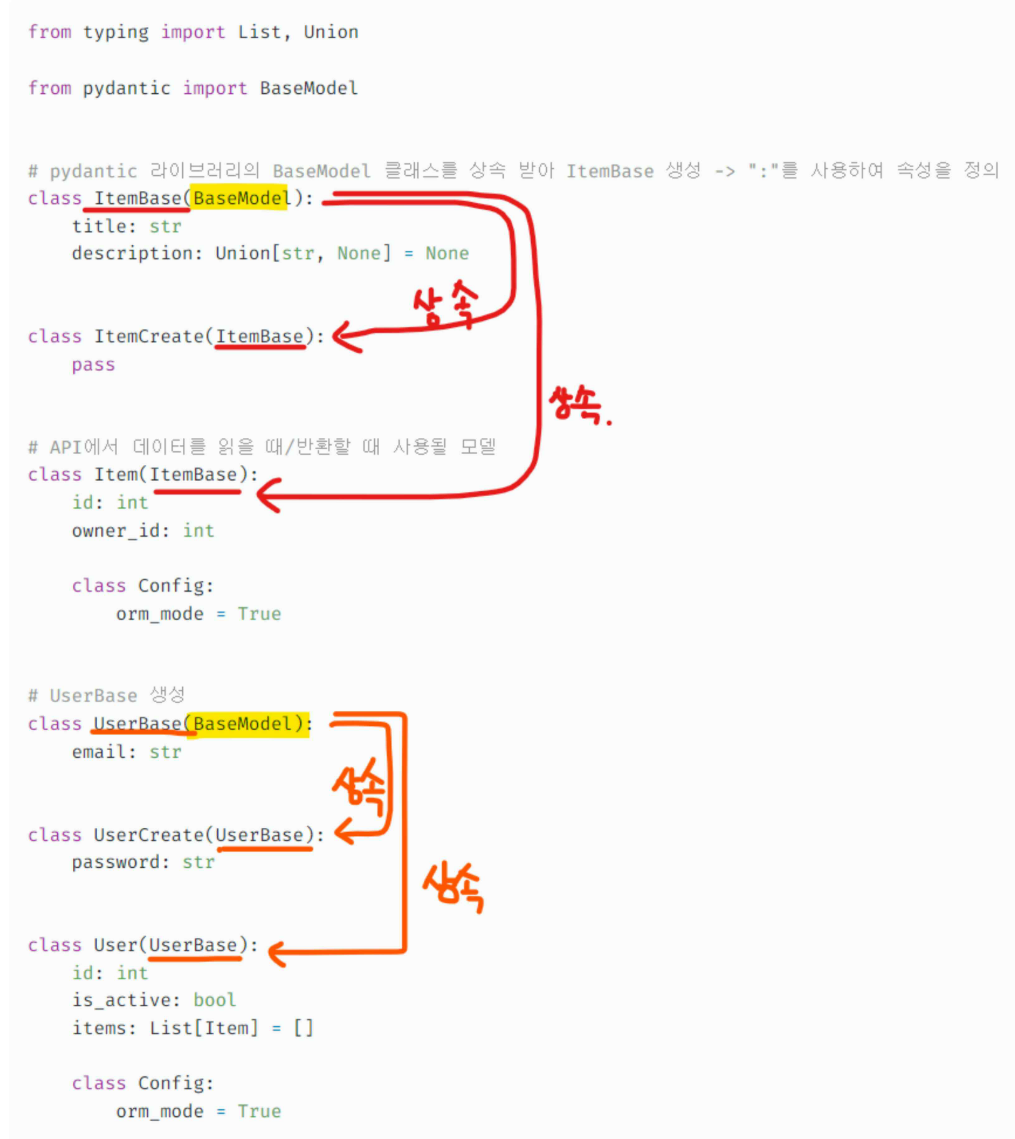
여기서 어제 제가 놓쳐서 햇갈렸던 부분이 위 두 함수의 파라미터에서
user: schemas.UserCreate와 item: schemas.ItemCreate등 요 두파라미터의 Pydantic models 에서 선언한 class model들은 BaseModel을 상속받아 만든 자식 클래스에서 부분적으로 원하는 필드의 데이터 타입을 선언하여 또한번 각각 상속을 해주었습니다.
이렇게하면 자식 클래스는 부모클래스 필드를 모두 상속받아 접근가능하며, 멘토님 말씀처럼 가지고 오고 싶은 칼럼 타입들을 미리 정의해두고, 검증을 해줄수 있는 거라고 보여집니다. 이러한 부분을 놓쳐서 아래코드들이 햇갈리게 되었습니다.
(더욱이.. 파이썬코드가 아직 익숙하지 않았습니다...)
sqlalchemy에서 말하는 model은 DB에 맵핑하기 위한 객체를 말하고 pydantic에서 말하는 model은 어떤 값의 validation(검증)을 위해서 사용된다고 합니다.
이런 언급이 있는 이유는 Fastapi에서 POST와 같이 request body가 있는 경우나, response body가 있는 경우 pydantic을 이용해서 데이터의 형태가 올바른지 검증 하기 때문입니다. 그러므로 실재app을 만들 때는 이 두가지를 혼동하면 안됩니다.
Pydantic models 생성 코드
마지막으로 데이터베이스에서 원하는 값을 필터 해주고 싶을때 아래코드 처럼
query.filter 메소드 활용하여 SQL 데이터 접근 할수 있습니다.

이건 스크롤 한번 할때마다 offset()부터 limit()까지 가져오는게 아닌가 한다.

위 코드 예시들 처럼 파이썬 FastAPI + SQLAlchemy의 메소드를 활용해
SQL데이터를 생성하고 조회할 수 있기 때문에 가독성이 높아지고 개발언어
를 일관되게 활용할 수 있어 굉장히 편리한 것 같습니다.
다음엔 Spring + ORM구현 방법도 공부해 보겠습니다~.
출처 : https://velog.io/@k0310kjy/FastAPI-FastAPI-SQL-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0
출처: https://davi06000.tistory.com/147
출처 : tps://velog.io/@alskt0419/ORM%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C...-
iek4f0o3fg
