
JOIN 경우
// 3개 테이블 join 후 IDX = 557번 조회
SELECT *
FROM TMP_ONSET A, TMP_COURSE B , TMP_LITERATURE C
WHERE A.TMP_IDX = B.TMP_IDX
AND A.TMP_IDX = C.TMP_IDX
AND A.TMP_IDX = 557;
아래 값이 나옴.

GROUP BY 할경우
원하는 컬럼을 그룹으로 묶어주면 컬럼을 그룹으로 묶어줬기 때문에 결과값은 하나의 값만 나오게 된다. 따라서 SELECT에서도 *로 출력할시 에러로 값이 나오지 않는다. 원하는 컬럼값만 출력하거나 그 컬럼의 집계함수를 사용해서 원하는 값을 얻어라.
// 3개 테이블 join 후 TMP_IDX GROUP BY해줌.
SELECT B.TMP_IDX
FROM TMP_ONSET A, TMP_COURSE B , TMP_LITERATURE C
WHERE A.TMP_IDX = B.TMP_IDX
AND A.TMP_IDX = C.TMP_IDX
GROUP BY B.TMP_IDX;
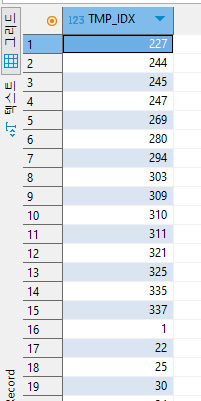
만약 동일한 TMP_IDX를 뽑을 경우 ex) TMP_IDX = 11; 할경우 회사테이들에서는 두개의 값이 나온다.
SELECT *
FROM TMP_COURSE
WHERE TMP_IDX = 11;
두개의 테이블을 조인한후 TMP_IDX로 그룹화 하여 원하는 값을 뽑는다.
SELECT COUNT(A.TMP_IDX)
FROM TMP_ONSET A, TMP_COURSE B
WHERE A.TMP_IDX = B.TMP_IDX AND A.TMP_IDX = 11
GROUP BY B.TMP_IDX;
EX 다른예)
SELECT COUNT(A.TMP_IDX)
FROM TMP_ONSET A, TMP_COURSE B
WHERE A.TMP_IDX = B.TMP_IDX AND A.TMP_IDX = 557
GROUP BY B.TMP_IDX;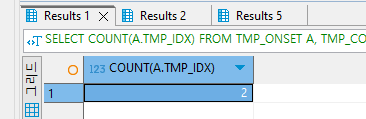
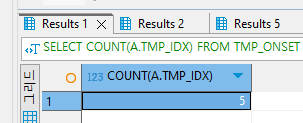
이렇게 위에 TMP_IDX = 11의 2개의 값이 그룹화 하여 COUNT()함수를 사용하여 해당 WHERE절의 토탈 갯수를 집계해주어 결과를 만들어 주었다.
이래서 GROUP BY 하면 집계함수 사용하거나 하여 그룹중 최고값이나 최소값, 토탈 카운트값을 얻는 거구나 알았음!!.
아래 쿼리는 TMP_IDX로 그룹화 하여 TMP_IDX = 11인 TMP_IDX 컬럼을 출력한것이다.
TMP_IDX로 그룹화 하였기 때문에 결과값은 어떤걸 그룹화 했는지에 대한 결과값 한개만 나오게 된다!.
SELECT A.TMP_IDX
FROM TMP_ONSET A, TMP_COURSE B
WHERE A.TMP_IDX = B.TMP_IDX AND A.TMP_IDX = 11
GROUP BY A.TMP_IDX;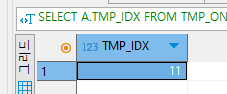
DISTINCT를 사용하여 중복 제거
이렇게 사용하면 중복을 제거 할수 있다. 결과값은 그룹화 한거와 같은 값이 나온다. 아래처럼
SELECT DISTINCT A.TMP_IDX
FROM TMP_COURSE A, TMP_ONSET B
WHERE A.TMP_IDX = 557;

hi