최근 최종 프로젝트를 RAG를 사용하게 되어 전반적인 RAG에 대한 이해를 하고자 팀원들과 논문리뷰를 진행하였다.
Advanced RAG부분에서는 좀 더 다른 자료들을 찾으며 논문에서 얘기한 것 이외에도 추가적인 내용이 포함되어 좀 더 길어졌다.
RAG를 처음 사용하려고 하거나 학문적으로 깊이있게 이해하고자 하는 사람이라면 읽기에 좋은 눈문이 될 것 같다.
해당 논문 링크 :
https://arxiv.org/html/2312.10997v5#S6
참조 블로그 :
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
https://cobusgreyling.medium.com/multihop-rag-1c695794eeda
💡 다운스트림 task이란? : 텍스트 생성, 번역, 요약, 질문과 답변 등과 같은 작업들을 칭함 https://blog.naver.com/dbwjd516/2229989885141. Introduction
RAG를 설명하기에 앞서 기존 LLM의 한계를 먼저 살펴보자.
-
Hallucination (잘못된 정보를 제공하는 경우
ex) Q. 너 홍길동 알아?
A. 네, 홍길동은 우리나라의 18번째 국회의원으로… (잘못된 정보를 생성함)
-
Outdated knowledge (오래된 정보들, 거대언어모델인 경우에 학습에 시간이 걸리므로 자연스럽게 오래된 정보일 수 밖에 없음.)
-
Untraceable reasoning process (불투명한 추론 과정)
→ 특히 Hallucination을 막기 위한 방법으로 RAG가 제안되었다.
RAG란?
LLM모델에서 전문적인 지식에 대해 hallucination이 발생하는 것을 보완하여, 금융, 의학, 법률적 지식과 같은 전문적인 지식을 요하는 경우에 적극적으로 활용되고 있음.
의미가 있는 유사성 계산을 통해 외부 지식 기반에서 관련 Document chunk를 검색하여 LLM을 향상 시킬 수 있다.
크게 Retrieval(검색)와 Generator(생성)으로 나누어 설명된다.
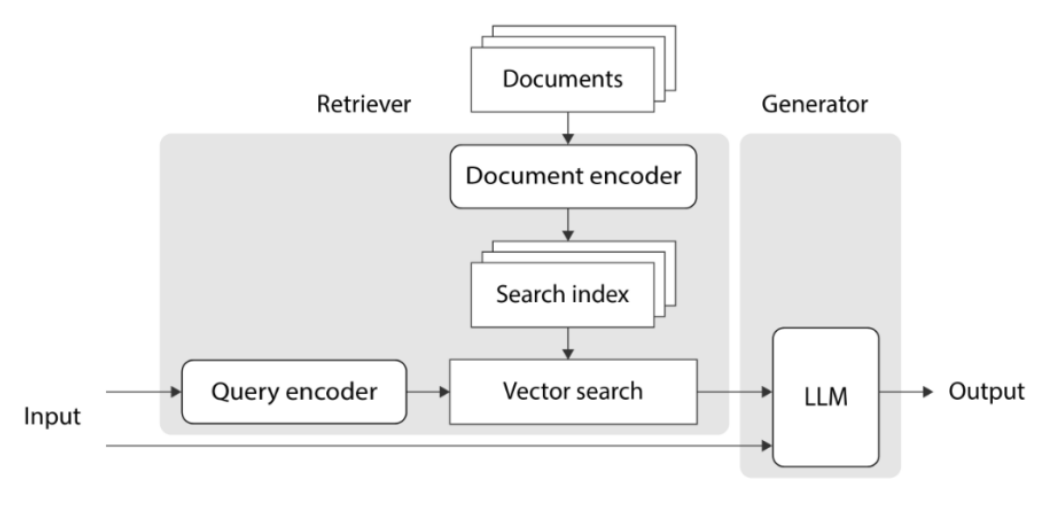
Retrieval을 이용해 외부 지식을 참조함으로써 RAG는 사실적으로 잘못된 컨텐츠를 생성하는 문제를 효과적으로 줄일 수 있었음
본 눈문에서는 RAG가 처음 제안되기 시작되었을 때부터 시작하여 Fine-tuning, Pre-training, Inference의 3가지 기술트리로 분류하였다.
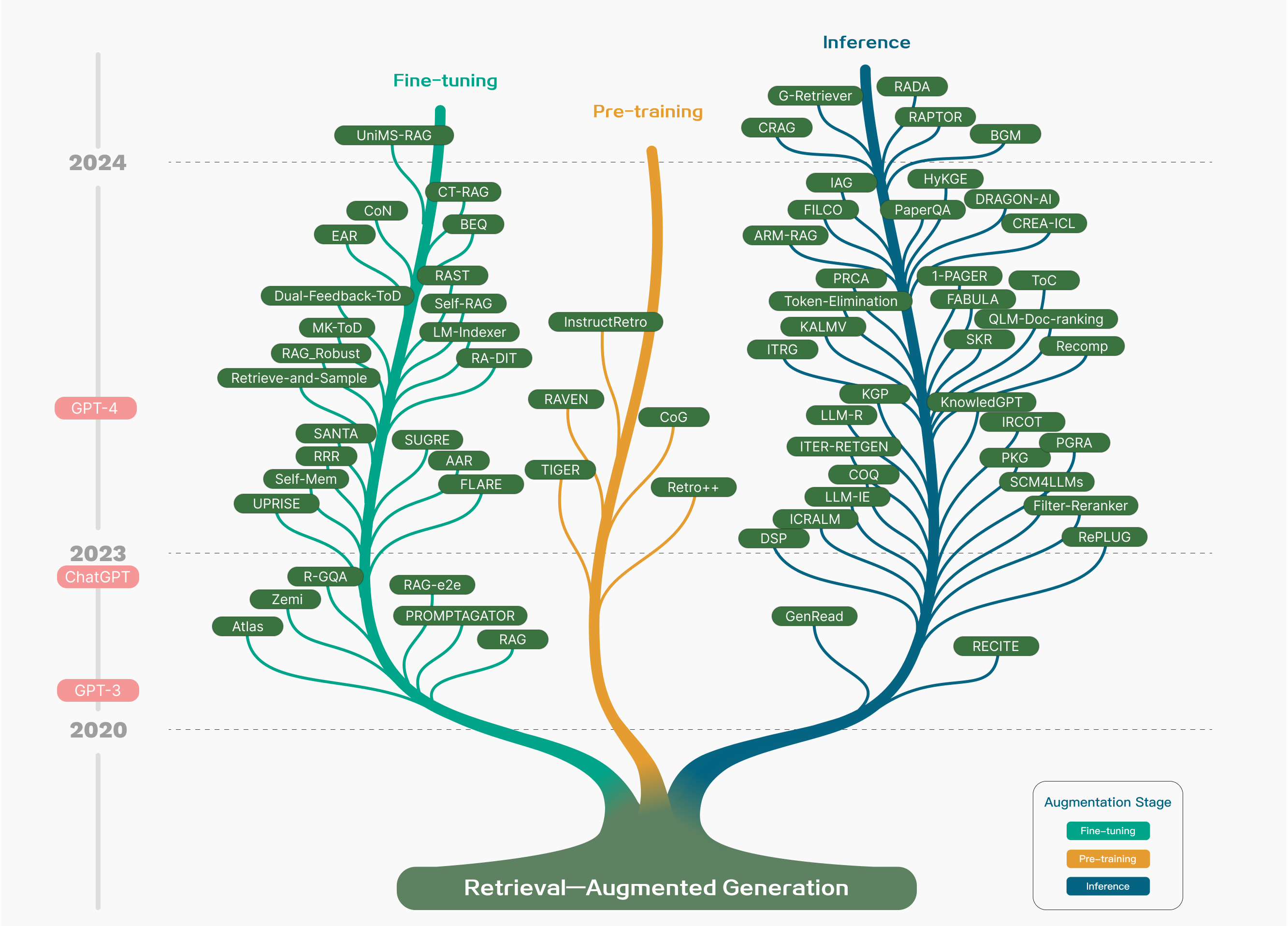
본 논문에서는 Retrieval, Generation, Augmentaion 3가지 기술에 초점을 맞추어 분석하였다.
RAG에 필요한 다운스트림 작업, 데이터 세트, 벤치마크 및 평가방법에 대해서도 종합적으로 검토한다.
2. Overview of RAG(RAG 기술 요약)
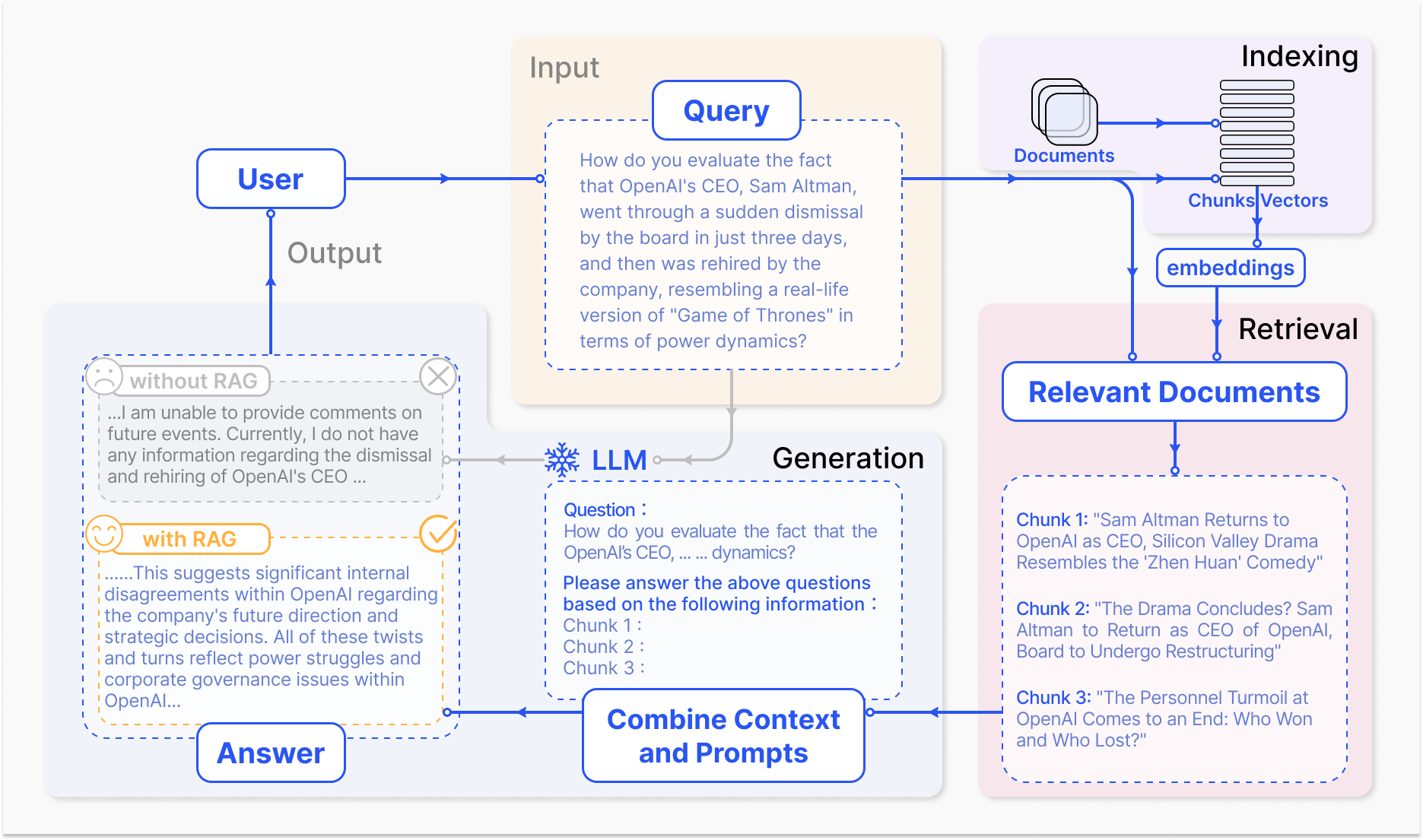
질문 답변에 적용된 RAG프로세스의 대표적인 사례
- 인덱싱(Indexing), 문서를 청크로 분할하고 벡터로 인코딩하여 벡터데이터 베이스에 저장한다.
- 검색(Retrieval), 의미적 유사성을 기반으로 질문과 가장 관련성이 있는 상위 k개
- 생성(Generation), 원래 질문과 검색된 청크를 함께 LLM에 입력하여 최종 답변을 생성한다.
2-A. Native RAG
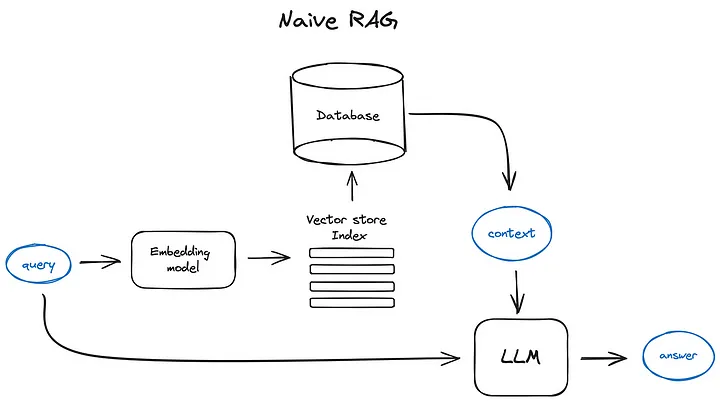
Native RAG는 인덱싱, 검색 및 생성을 포함하는 기존 프로세스를 따르며, ‘검색-읽기’ 와 같은 형식이 특징이다.
인덱싱 : 언어모델의 길이제한(context limitations)에 맞추기 위해서 텍스트를 더 작은 chunk로 쪼개어 활용한다. 이렇게 쪼갠 chunk는 Embedding Model을 사용하여 벡터표현으로 인코딩되고 벡터 데이터베이스에 저장된다.
→ 후속 단계(검색)에서 효율적인 유사성 검색을 가능하게 한다.
검색 : 인덱싱 단계에서 사용된 것과 동일한 Encodding Model을 사용하여 질의를 벡터표현으로 변환한다. 그 후 질의 벡터와 인덱싱된 코퍼스 내의 chunk vector 간의 유사도 점수를 계산한다.
시스템은 질의와 가장 큰 유사도를 보이는 상위 k개 chunk를 우선순위를 정하고 검색한다.
→ chunk는 이후 프롬프트에서 확장된 context로 사용된다.
생성 : 사용자의 질문(query) + 검색단계에서 선택된 document(문서) → 프롬프트로 전달
대규모언어모델(LLM)이 이에대한 응답을 공식화하는 작업을 한다.
진행중인 대화의 경우, 기존 대화 내역을 프롬프트에 통합하여 모델이 효과적으로 여러 차례 대화 상호작용에 참여할 수 있다.
Natvie RAG의 단점
- Retrieval Challenges (검색) : precision과 recall 부분에서 관련없는 청크를 선택하고 중요한 정보를 놓치게 되는 경우가 있음
- Generation Difficulties(생성의 어려움) : 생성 모델이 hallucination 문제에 직면할 수 있음. 이는 검색된 context에서 지원하지 않았던 retrival context를 생성하게 된다.
- Augmentation Hurdles(증강 장애물) : 검색된 정보를 다른 task와 합치는 것은 어려움. 가끔씩은 일관성 없는 출력이 나오거나 분리될 수 있음. 여러 출처에서 유사한 정보를 검색할 경우 프로세스가 중복되어 반복적인 대답을 내놓을 수 있다.
- generation model이 증강된 정보에 의존하여 insignt나 종합적인 정보를 추가하지 않는 검색된 내용을 그대로 반영하는 출력이 나올 수도 있음
이러한 단점들을 보완하기 위해 다양한 Advanced RAG가 제안되기 시작함.
2-B. Advanced RAG
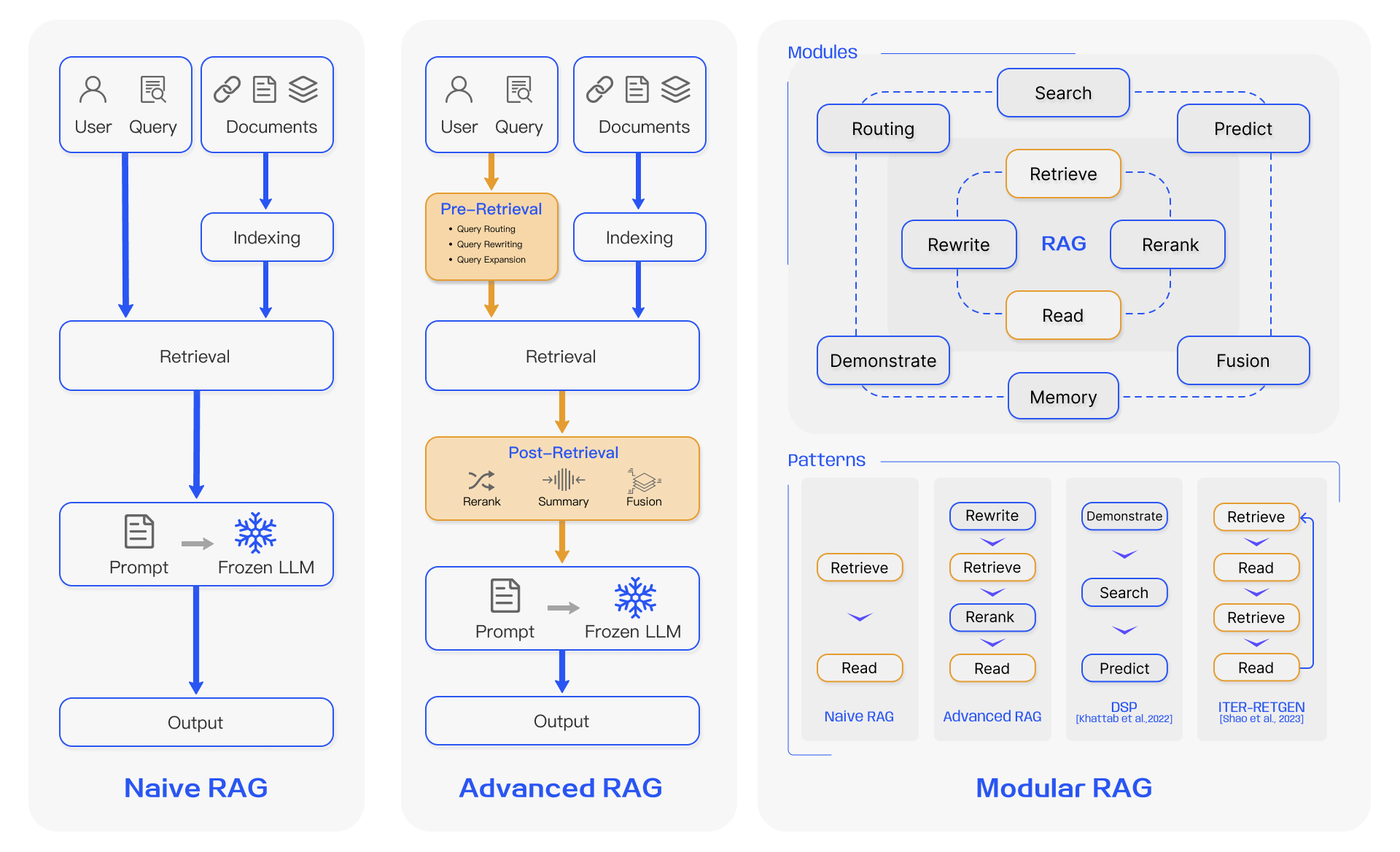
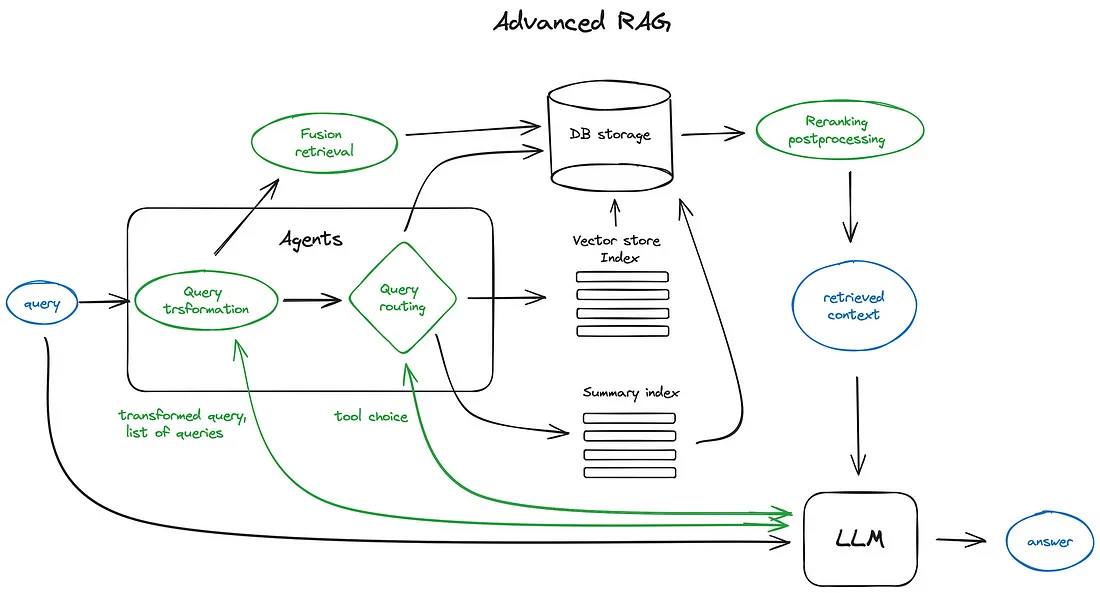
출처 : https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
Advanced RAG는 기존의 RAG의 한계를 극복하기 위한 개선점을 추가하였다.
검색품질향상에 초점을 맞춰 pre-retriveal 과 post-retrieval로 나누어 검색을 진행한다.
기존에 있었던 인덱싱 문제를 없애기 위해 슬라이딩 윈도우, 메타데이터의 통합, fine-grained segmentation*(?)을 추가하였다.
2-C. Modular RAG
모듈형 RAG 구조는 이전의 두 RAG 패러다임을 넘어서 향상된 적응성과 다양성을 제공함.
유사성 검색을 위한 검색 모듈을 추가하고 미세조정을 통해 검색기를 개선하는 등 구성 요소를 개선하기 위한 다양한 전략을 통합한다.
New modules
- 검색 모듈은 특정 시나리오에 적응하여 LLM에서 생성된 코드와 쿼리언어를 사용하여 검색 엔진, 데이터베이스 및 지식 그래프와 같은 다양한 데이터 소스에서 직접 검색을 가능하게 한다.
- RAG-Fusion은 사용자 질의를 다양한 관점에서 확장하고 병렬 벡터 검색과 지능형 재순위 지정을 활용하여 명시적 지식과 변형적 지식을 모두 발견하는 다중 질의 전략을 채택하여 기존 검색 제한을 해결한다.
- 메모리 모듈은 LLM의 메모리를 활용하여 검색을 안내하고 반복적인 자체 향상을 통해 텍스트를 데이터 분포와 더욱 밀접하게 정렬하는 무제한 메모리풀을 생성한다.
- RAG시스템의 라우팅은 다양한 데이터 소스를 탐색하여 요약, 특정 데이터베이스 검색 또는 다양한 정보 스트림 병합을 포함하는 쿼리에 대한 최적의 경로를 선택한다.
- Predict 모듈은 LLM을 통해 직접 컨텍스트를 생성하여 중복성과 노이즈를 줄이고 관련성과 정확성을 보장하는 것을 목표로 한다.
- Task Adapter 모듈은 RAG를 다양한 다운스트림 작업에 맞춰 조정하여 제로샷입력에 대한 신속한 검색을 자동화하고 몇가지 샷 쿼리 생성을 통해 작업별 검색기를 생성한다.
이러한 포괄적인 접근 방식은 검색 프로세스를 감소화 할 뿐만 아니라 검색된 정보의 품질과 관련성을 크게 개선하여 더욱 향상된 정확도와 유연성으로 다양한 작업과 질의에 부응한다.
3. Retrieval
Vector store index
RAG 파이프라인의 중요한 부분은 검색 인덱스로, 이전단계에서 얻은 벡터화된 컨텐츠를 저장한다.
가장 간단한 구현 방법은 플랫한 인덱스를 사용하는것이다. (쿼리 벡터와 모든 청크 벡터간의 무차별 대립 거리 계산)
hierarchical indices
검색할 문서가 많은 경우 효율적으로 문서 내부를 검색하고 관련 정보를 찾아 출처에 대한 참조와 함께 단일 답변으로 종합할 수 있어야 한다.
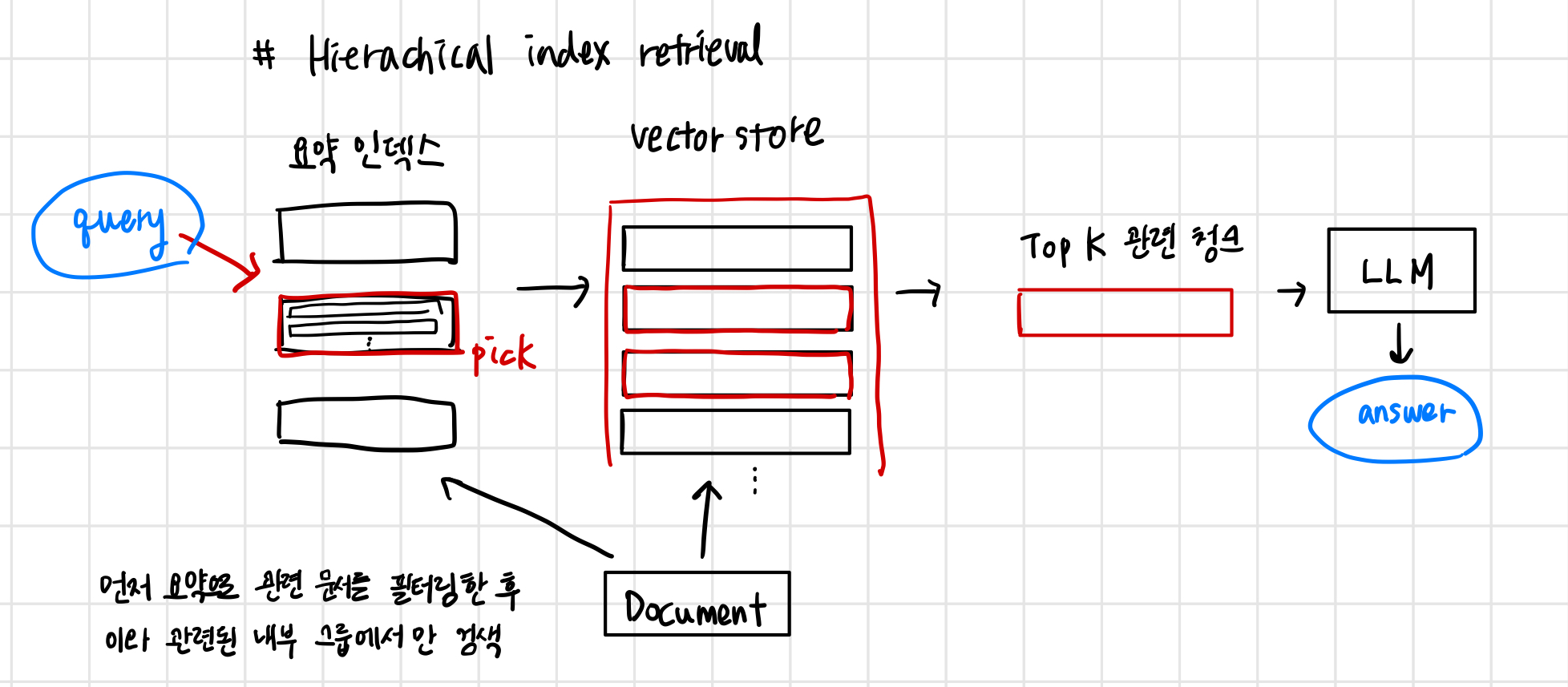
대규모 데이터베이스의 경우 이를 수행하는 효율적인 방법은 요약으로 구성된 인덱스와 문서 청크로 구성된 인덱스 두개를 만들고 두단계로 검색하는 것. 먼저 요약으로 관련 문서를 필터링한 다음 이 관련 그룹 내부에서만 검색한다.
가정적 질문과 HyDE
또 다른 접근 방식은 LLM에 각 청크에 대한 질문을 생성하도록 요청하고 이러한 질문을 벡터에 임베드한 다음 런타임에 이 질문 벡터 인덱스에 대한 쿼리 검색을 수행하고 (chunk벡터를 인덱스의 질문 벡터로 대체) 검색 후 원래 텍스트 청크로 경로를 지정하여 LLM이 답변을 얻> 을 수 있는 컨텍스트로 보낸다.
→ 실제 청크에 대한 것보다 쿼리와 가상 질문 간의 의미적 유사성이 더 높기 때문에 검색 품질이 향상된다.
HyDE : 역 논리 접근법. LLM에게 쿼리에 따라 가정된 응답을 생성하도록 요청한 다음, 해당 벡터를 쿼리 벡터와 함께 사용하여 검색 품질을 향상시킨다.
Context enrichment
Sentence Window Retrieval

녹색부분은 인덱스에서 검색하는 동안 발견된 문장 임베딩이고, 전체 검정색 + 녹색 문단은 제공된 쿼리에 대한 추론하는 동안 컨텍스트를 확장하기 위해 LLM 에 공급된다.
Auto-merging Retriever (Parent Document Retriever)
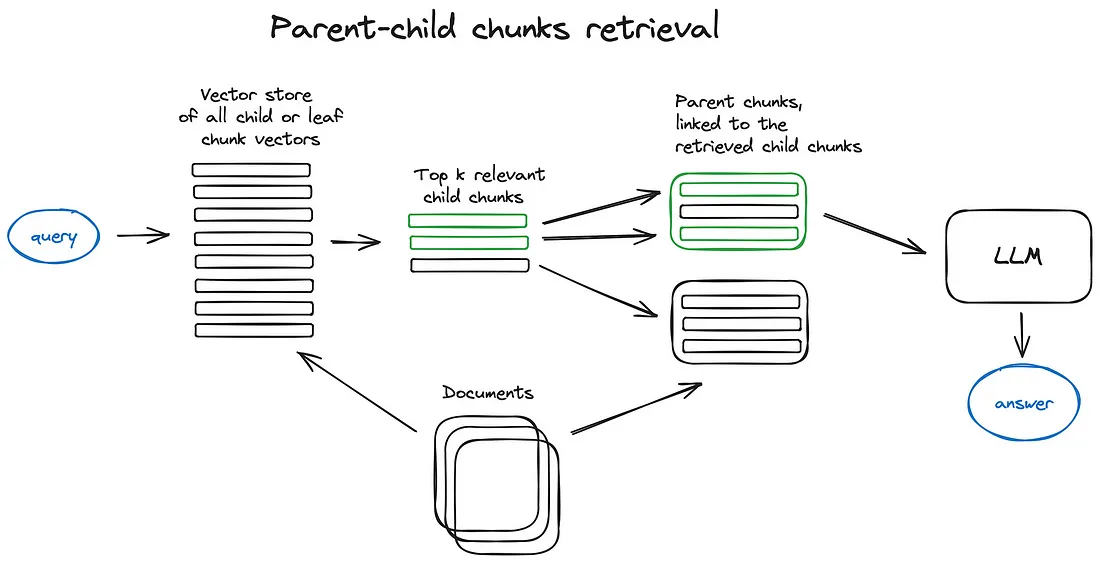
Sentence Window Retrieval과 매우 유사한 아이디어로, 더 세부적인 정보를 검색한 다음 해당 컨텍스트를 추론을 위해 LLM에 공급하기 전에 컨텍스트 창을 확장하는 것이다.
문서는 더 큰 부모 청크를 참조하는 더 작은 자식 청크로 나뉜다.
검색 중에 먼저 작은 청크를 가져온 다음, 상위 k개의 검색된 청크에서 n개 이상의 청크가 동일한 부모노트(더 큰 청크)에 연결되어 있는 경우, LLM에 공급된 컨텍스트를 이 부모노드로 대체한다.
이는 몇개의 검색된 청크를 더 큰 부모 청크로 자동 병합하는 것과 같다. 참고로 검색은 자식 노트 인덱스 내에서만 수행됨.
4. Generation
4-A. Context Curation
중복된 정보는 LLM의 최종 생성을 방해할 수 있고, 너무 긴 context는 LLM을 중간에서 소실되는 문제를 발생시킬 수 있다. 인간과 마찬가지로 LLM은 긴 텍스트의 시작과 끝에만 집중하는 경향이 있고 중간부분은 잊게 된다. 따라서 RAG 시스템에서는 일반적으로 검색된 컨텐츠는 추가로 처리해주어야 한다.
Reranking
Reranking은 문서 chunk를 근본적으로 재정렬하여 가장 관련성 있는 결과를 먼저 강조하여 전체 문서 풀을 효과적으로 줄이고 정보 검색의 이중 목적으로 깨뜨려 강화기와 필터 역할을 모두 수행하여 보다 정확한 언어모델 처리를 위한 정제된 입력을 제공한다. 재순위 매기기는 다양성, 관련성 및 MRR과 같은 사전 정의된 메트릭에 의존하는 규칙 기반 방법이나 BERT시리즈의 encoder-decoder 모델, cohere-rerank 과 같은 특수 재순위 매기기 모델, GPT와 같은 일반적인 대규모 언어모델과 같은 모델 기반 접근 방식을 사용하여 수행할 수 잇다.
Context Selection/Compression
RAG 프로세스에서 흔히 오해하는 것은 가능한 많은 관련 문서를 검색하고 이를 연결하여 긴 검색 프롬프트를 형성하는 것이 유익하다는 믿음이다.
그러나 과도한 context는 더 많은 노이즈를 만들어 LLM의 핵심 정보 인식을 약화시킬 수 있음
context를 압축하는 것 이외에도 문서수를 줄이는 것은 모델의 답변 정확도를 개선하는데에도 도움이 된다. Ma et al의 논문에서는 LLM과 SLM(small language model)*의 장점을 결합한 filter-reranker 패러다임을 제시함.
- SLM이란? 언어 모델의 유형 (출처 : https://dis.qa/rmGGb) 언어 모델에 대한 연구는 현재에도 진행형입니다. 본격적으로 작동 원리에 대해 이해하기 전에, 개발 단계를 네 가지로 나눠 알아보겠습니다.
- SLM (Small Language Model): 제한된 양의 텍스트 데이터를 학습하여, 작업 전반에 걸쳐 국소적인 문맥을 이해하는 데에 초점을 맞춥니다. 작은 규모에도 불구하고, SLM은 가볍고 실행 속도도 빠른 특징을 가지고 있습니다.
- NLM (Neural Language Model): NLM은 기존의 통계 기반 언어 모델보다 더 정확한 성능을 제공합니다. 이러한 모델은 주로 단어 임베딩, 문장 완성, 기계 번역 등 다양한 NLP 작업에 사용됩니다.
- PLM (Pretrained Language Model): PLM은 대규모 데이터셋으로 미리 학습되며, 이후 다양한 NLP 작업에 전이학습(Transfer Learning)을 통해 적용됩니다. BERT와 GPT와 같은 주요 모델들은 이 PLM에 속합니다.
연구자들은 PLM을 확장하면 다운스트림 작업에서 모델 용량이 향상될 수 있다는 사실을 발견했습니다. 많은 연구에서 훨씬 더 큰 PLM을 훈련하면서 성능 한계를 탐색해보고자 했죠. 이러한 대형 PLM은 소형 PLM과는 다르게, 일련의 복잡한 작업을 해결할 때 놀라운 능력을 발휘한다는 점이 밝혀졌습니다. 예를 들어, GPT-3는 상황을 학습하여 단발성 과제를 해결할 수 있는 능력을 가졌지만 GPT-2는 그렇지 못했죠. 따라서 연구 커뮤니티에서는 이러한 대형 PLM을 두고 “대규모 언어 모델(LLM)”이라는 용어를 사용하기 시작했습니다. 즉, LLM은 언어 모델의 현주소이자 최종 개발 단계라고 할 수 있습니다.
4-B. LLM Fine-tuning
LLM에 특정 도메인의 데이터가 부족한 경우 미세 조정을 통해 LLM에 추가 지식을 제공할 수 있다.
HuggingFace의 미세 조정 데이터로 초기 단계로 사용할 수 있음.
Fine tuning의 또다른 장점은 모델의 입력 및 출력을 조정할 수 있는 기능.
강화 학습을 통해 LLM출력을 인간 또는 retriever 선호도에 맞추는 것은 잠재적인 접근 방식이다. 예를 들어 최종 생성된 답변에 수동으로 주석을 달고 강화학습을 통해 피드백을 제공한다.
인간의 선호도를 맞추는 것 외에도 미세조정된 모델과 retriever의 선호도에 맞추는 것도 가능함
5. Augmentation in RAG
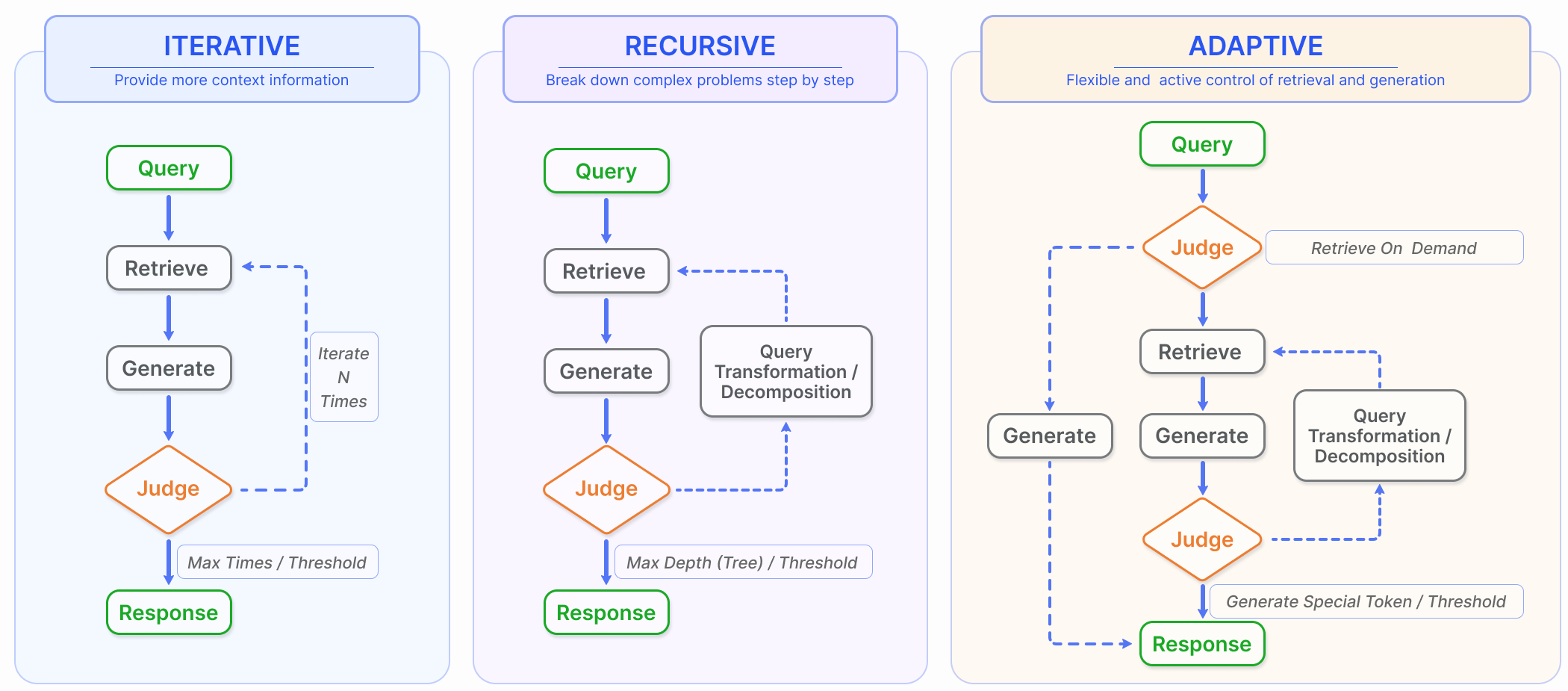
5-A. Iterative Retrieval (반복적 검색)
초기 질의와 지금까지 생성된 텍스트를 기반으로 지식기반을 반복적으로 검색하는 프로세스로, LLM에 보다 포괄적인 지식을 제공할 수 있다.
이러한 접근방식은 여러번의 검색 반복을 통해 추가적인 맥락적 참조를 제공함으로써 후속 답변 생성의 견고성을 향상시키는 것으로 나타났음. 그러나 의미적 불연속성과 무관한 정보의 축적에 영향을 받을 수 있음.
5-B. Recursive Retrieval
이전 검색에서 얻은 결과를 기반으로 검색 쿼리를 반복적으로 정제함
Recursive Retrieval은 피드백 루프를 통해 가장 관련성 있는 정보에 점진적으로 수렴하여 검색 경험을 향상시키는 것을 목표로 한다.
특정 데이터 시나리오를 처리하기 위해 recursive retrieval과multi-hop retrieval 기술이 함께 활용된다.
재귀적 검색에는 계층적 방식으로 데이터를 처리하고 검색하는 구조화된 인덱스가 포함되며, 이 요약을 기반으로 검색을 수행하기 전에 문서 또는 긴 PDF의 섹션을 요약하는 것이 포함 될 수 있음
6. Task and Evaluation
6-A. Downstream Task
RAG의 핵심 작업은 전통적인 단일 홉/멀티 홉 QA, 다중 선택, 도메인별 QA뿐만 아니라 RAG에 적합한 긴 형태의 시나리오를 포함하여 질문 응답(QA)으로 남아 있습니다.
QA 외에도 RAG는 정보 추출(IE), 대화 생성, 코드 검색 등과 같은 여러 다운스트림 작업으로 지속적으로 확장되고 있습니다. RAG의 주요 다운스트림 작업과 해당 데이터 세트는 표 II에 요약되어 있습니다
6-B. Evaluation Target
역사적으로 RAG 모델 평가는 특정 다운스트림 작업에서의 실행에 중점을 두었습니다. 이러한 평가는 당면한 작업에 적합한 확립된 메트릭을 사용합니다.
예를 들어, 질문 답변 평가는 EM 및 F1 점수[45, 72, 59, 7]에 의존할 수 있는 반면, 사실 확인 작업은 기본 메트릭으로서 정확도에 의존하는 경우가 많습니다[4, 42, 14]. BLEU 및 ROUGE 메트릭도 일반적으로 답변 품질을 평가하는 데 사용됩니다[26, 78, 52, 32]. RAG 애플리케이션의 자동 평가를 위해 설계된 RALLE와 같은 도구도 마찬가지로 이러한 작업별 메트릭에 평가를 기반으로 합니다[160]. 그럼에도 불구하고 RAG 모델의 고유한 특성을 평가하는 데 전념하는 연구가 눈에 띄게 부족합니다. 주요 평가 목표는 다음을 포함합니다:
Retrieval Quality.
검색 품질을 평가하는 것은 리트리버 구성 요소가 제공하는 컨텍스트의 효율성을 결정하는 데 중요합니다. RAG 검색 모듈의 성능을 측정하기 위해 검색 엔진, 추천 시스템 및 정보 검색 시스템 영역의 표준 메트릭이 사용됩니다. 이를 위해 Hit Rate, MRR 및 NDCG와 같은 메트릭이 일반적으로 사용됩니다[161, 162].
Generation Quality.
생성 품질의 평가는 검색된 컨텍스트에서 일관되고 관련성 있는 답변을 합성하는 제너레이터의 능력에 중점을 둡니다. 이 평가는 콘텐츠의 목표, 즉 레이블이 지정되지 않은 콘텐츠 및 레이블이 지정된 콘텐츠를 기반으로 분류될 수 있습니다. 레이블이 지정되지 않은 콘텐츠의 경우, 평가는 생성된 답변의 충실성, 관련성 및 무해성을 포함합니다. 대조적으로 레이블이 지정된 콘텐츠의 경우 모델에 의해 생성된 정보의 정확성에 중점을 둡니다[161]. 또한 수동 또는 자동 평가 방법을 통해 검색 및 생성 품질 평가를 모두 수행할 수 있습니다[161, 29, 163].
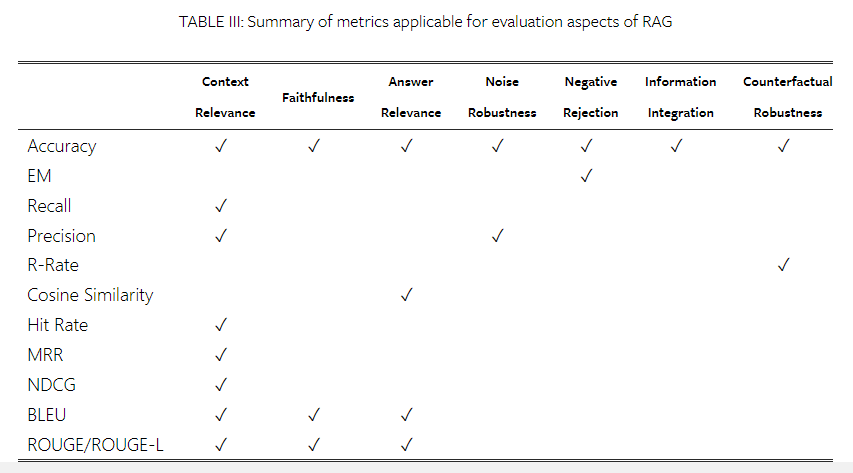
6-C. Evaluation Aspects
RAG 모델의 현대적 평가 관행은 세 가지 주요 품질 점수와 네 가지 필수 능력을 강조하는데, 이는 RAG 모델의 두 가지 주요 목표인 검색과 생성을 평가하는 데 전체적으로 영향을 미칩니다.
-
품질 점수
- *Context Relevance(*맥락 관련성) : 검색된 맥락의 정확성과 구체성을 평가하여 관련성을 보장하고 관련성이 없는 컨텐츠와 관련된 내용을 최소화 한다.
- *Answer Faithfulness(*답변 충실성) : 생성된 답변이 검색된 맥락에 충실하도록 보장하여 일관성을 유지하고 모순을 피한다.
- *Answer Relevance(*답변 관련성) : 생성된 답변이 제기된 질문과 직접적으로 관련이 있고 핵심적인 질문에 효과적으로 대응해야 한다는 것을 의미.
-
필수 능력
- *Noise Robustness*(노이즈 견고성) : 질문과 관련이 있으나 실질적인 정보가 부족한 노이즈 문서를 관리할 수 있는 모델의 능력을 평가
- *Negative Rejection(*부정 거부) : 검색된 문서의 질문에 대답하는데 필요한 지식이 없을 때 모델이 응답을 자제하는 식별력을 평가
- *Information Integration(*정보 통합) : 복잡한 문제를 해결하기 위해 여러 문서의 정보를 종합하는 모델의 능력을 평가
- *Counterfactual Robustness(*반사실적 견고성) : 문서 내의 알려진 부정확한 내용을 인식하고 무시하는 모델의 능력을 테스트하는것으로, 잠재적인 잘못된 정보에 대한 지시가 있을 때도 적용된다.
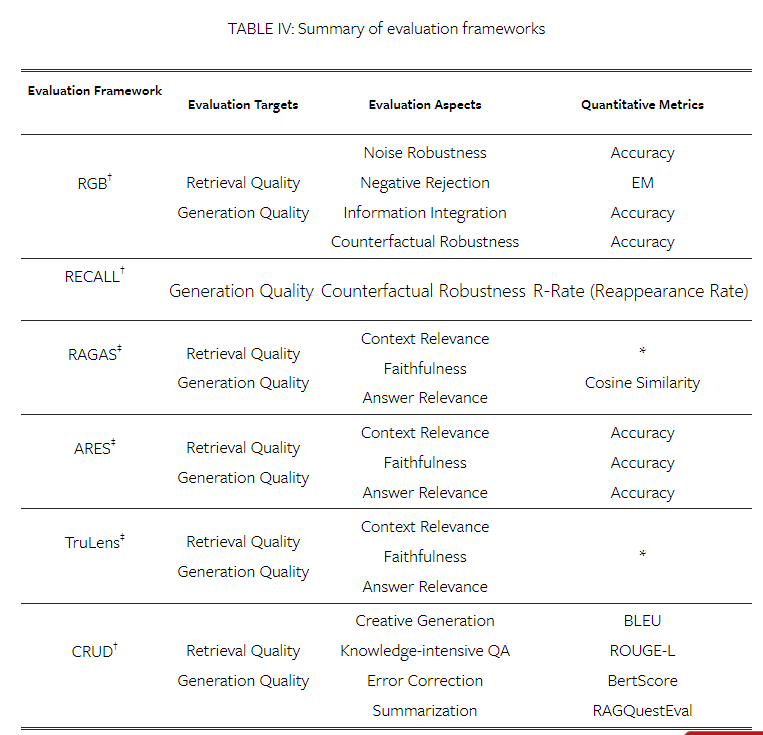
6-D. Evaluation Banchmark ans Tools
RAG의 평가를 용이하게 하기 위해 일련의 벤치마크 테스트와 도구가 제안되었습니다. 이러한 도구는 RAG 모델 성능을 측정할 뿐만 아니라 다양한 평가 측면에서 모델의 기능에 대한 이해를 향상시키는 정량적 메트릭을 제공합니다.
RGB, RECALL 및 CRUD[167, 168, 169]와 같은 저명한 벤치마크는 RAG 모델의 필수 능력을 평가하는 데 중점을 둡니다. 동시에 RAGAS[164], ARES[165] 및 TruLens8과 같은 최첨단 자동화 도구는 LLM을 사용하여 품질 점수를 판단합니다. 이러한 도구와 벤치마크는 표 IV에 요약된 바와 같이 RAG 모델의 체계적인 평가를 위한 강력한 프레임워크를 집합적으로 형성합니다.
7. Discussion ans Future Prospects
RAG 기술의 상당한 발전에도 불구하고 심층적인 연구가 필요한 몇 가지 과제가 남아 있습니다. 이 장에서는 주로 RAG가 직면한 현재의 과제와 향후 연구 방향을 소개한다.
시사점
RAG가 어떤 식으로 발전하고 분화되었는지에 대해 전반적으로 이해하기 좋았던 내용이었다.
논문의 내용을 처음부터 끝까지 파기보다 읽으면서 좀 더 관심이 생겼던 내용들을 찾아보고 덧붙이다보니 굉장히 길어진 것 같지만 좋은 인사이트를 얻을 수 있었다.
특히 Advanced RAG와 Module RAG에 포함되던 hierarchical indices가 현재 진행하고 있는 프로젝트에 좋은 성능을 보일 수 있을 것 같아 이에 대해 좀 더 찾아보려고 한다!
