Research Note #1
Research Note 콘텐츠는 개인 연구 과제나 연구 관련 공부에 대해,
아직 레퍼런스가 적은 도메인의 자료를 기술정리와 정보공유의 목적으로 정리하는 컨텐츠 시리즈입니다.
0. Kickoff
요즘, 다니고 있는 랩에서 맡은 연구가 있다. Push-block이라고 하는 task로, 강화학습 분야에 속하는 연구인데... 생각보다 개념이나 관념이 복잡한 편이고, 다양한 도메인을 건드려야 하는 연구라 요즘 고생을 좀 하고 있다.
이쪽 분야가 너무 레퍼런스가 아직은 부족한 느낌이 들어서... 강화학습과 World Model 방법론에 대해 포스트를 좀 써 보고, 개인 연구일지처럼 활용해보고자 한다.
1. World Model이란?
- World Model이 무엇인지에 대해 알아본다.
- 강화학습에서 World Model의 역할에 대해 알아본다.
David Ha, Jürgen Schmidhuber(2018) "World Models" arXiv:1803.10122
월드 모델의 목적
위 논문에서 World Model의 개념에 대해 제시하고 있다. World Model은 사람의 무의식 중의 결정 과정에 대해 인공지능도 그 과정을 모방할 수 있도록 설계하기 위해 고안되었다.
예를 들어, 도로주행 상황에서 갑자기 보행자가 튀어나오면 사람은 브레이크를 밟아 멈춘다. 이 과정에서, 사람에게 따로 초음파 센서 등을 달거나 도로주행 시 보행자가 튀어나오면 멈추도록 하는 독립적인 기작이 있는 것도 아니다. 사람은 오직 (이 경우에서) 시각 정보로만 행동에 대한 판단을 내린다.
이렇듯, 감각을 통한 무의식 중의 결정 과정을 인공지능에게 학습하기 위한 방법이 월드 모델이다.월드 모델의 구조
월드 모델은 3개의 모델로 구성된다.
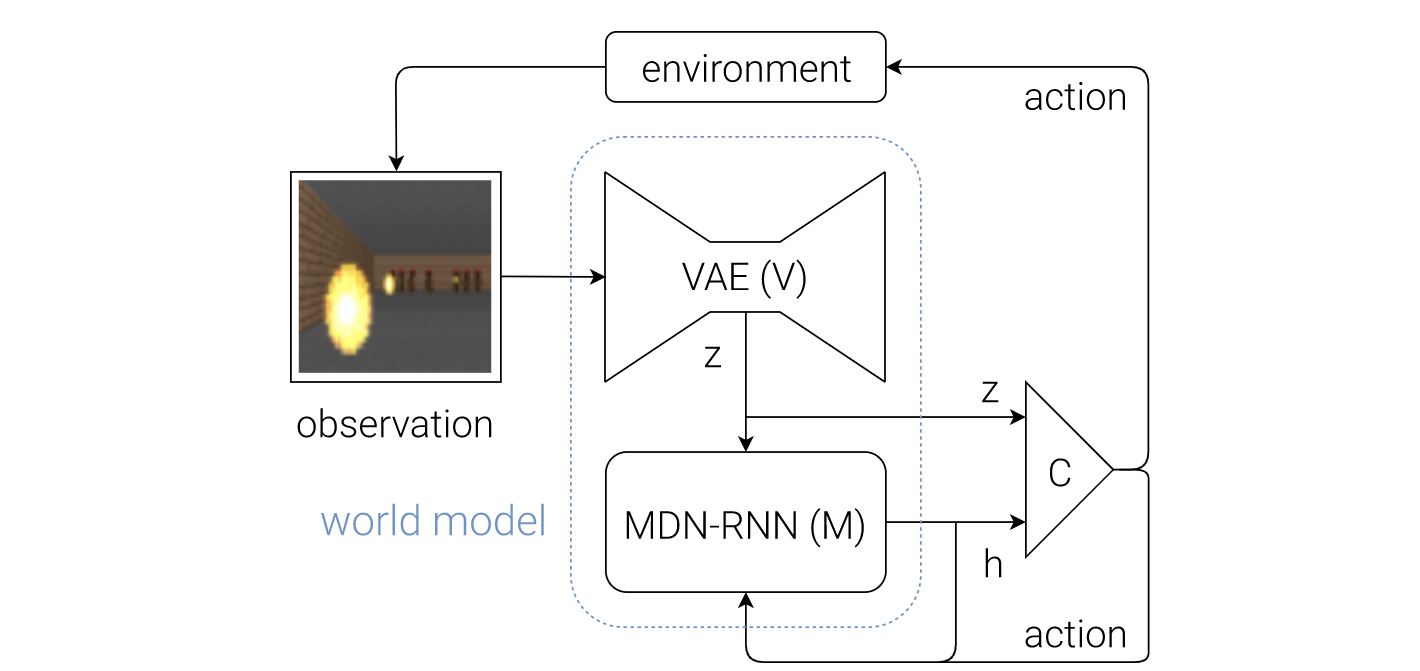
1. V Model
V 모델은 이미지(observation)를 인식하여 low-dimensional한 데이터로 압축하는 역할을 한다. 일반적으로 가상 환경이나 실제 환경에서 인식하는 이미지는 매우 용량이 크다.
(RGB 이미지의 경우 픽셀당 1바이트, 무압축 FHD 이미지는 약 2MB)주로 월드모델은 강화학습 방식으로 학습되므로 학습시 필요 데이터 수가 큰 World Model에서 이미지 데이터를 무압축으로 활용하는 것은 불가능에 가깝다. 따라서 VAE(Encoder)를 통해 이미지의 주요 정보들을 최대한 보존하는 방식으로 압축하게 된다.
2. M Model
MDN-RNN 모델은 압축된 이미지와 Agent의 Action을 통해 다음 시퀀스를 예측하게 된다. 2018년 공개된 이 논문에서는 시퀀스 예측 모델로 RNN 기반의 모델인 MDN-RNN을 채택하였다. 하지만 시경망 모델 RNN의 고질적인 문제점인 Gradient Vanishing 현상으로 인해 요즈음에 나오는 World Model에서는 RNN의 훌륭한 후발주자인 Transformers를 채택하고 있고, 필자도 현재 연구실에서 진행 중인 연구에서 Transformer World Model(TWM)을 채택하였다.
Vincent Micheli, Eloi Alonso, Francois Fleuret(2023), "Transformers are Sample-Efficient World Models", ICLR 2023
위 논문은 IRIS라는 아키텍처를 제안하며 Transformers를 월드 모델로 채택한 연구이다.
3. C Model
C Model은 이미지 시퀀스를 받아 가장 최적의 행위를 결정하는 모델이다. 주로 DQN, Actor-critic, A3C 등 대표적인 강화학습 알고리즘이 사용된다. World Model을 제안한 저자는 도표에서 이 부분을 빼고 W, M 모델만 월드모델의 아키텍처로 제한해놓은 것을 볼 수 있다. 이렇듯 사실 C Model은 점점 강화학습해 나가면서 리워드를 바탕으로 학습 초기보다 액션을 더 효용성 있게 구성하는 데 초점이 맞추어져 있다.
2. World Model의 의의
- 월드 모델의 의의는 무엇인가?
- 쉽게 설명해서, World Model의 각 기작은 인간의 어떤 부분과 유사한가?
간단하게 얘기하자면, 월드 모델은 인공지능에게 상상할 수 있는 능력을 부여해주는 것이다. 즉 인공지능이 환경을 실제로 인식하고, 행동을 결정했을 때 다음 시야(observation, image)를 예측해 나가면서 머릿속에서 상상을 할 수 있도록 해주는 것인데, 그래서 월드 모델은 현실의 논리 구조(물리 법칙, 시야 등)와 똑같은 방식으로 굴러가는 것이 중요하다.
쉽게 설명하자면, 유니티 등 물리 엔진을 만들 때 현실과 가장 비슷한 모델을 만들어야 사람이 게임을 할 때 몰입감을 많이 느낄 수 있는 것처럼 똑같이 인공지능에게 월드 모델을 부여하여 현실과 가장 유사하게 스스로 상상하여 예측 및 학습할 수 있도록 하는 것이 World Model의 목적이다.
- VAE
월드 모델의 V 부분은 눈, 시각겉질과 같다. 눈은 이미지를 인식하고 시각겉질은 이미지를 처리한다. 이처럼 월드 모델의 VAE 부분이 이미지를 인식하고, 그를 추상화하는 것을 담당한다. - M Model
월드 모델의 M 부분은 전두엽과 같다. 정보를 바탕으로 상황을 예측한다.
이처럼 월드 모델은 Sequence 모델과 Vision Model, Reinforcement Learning까지 합쳐서 고안된 복합적인 timeseries model이다.
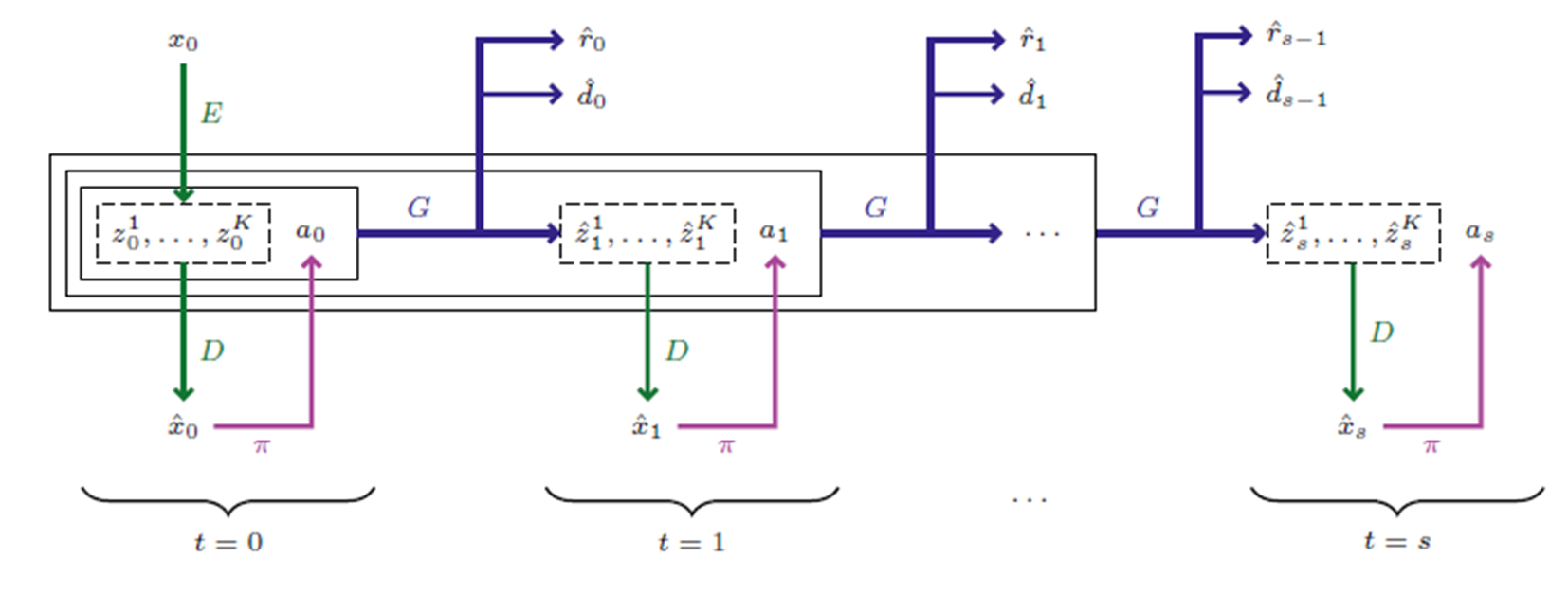
따라서 월드 모델에 사용되는 많은 변인들(observation, observation encoded token, action, rewards, policy 등)은 마르코프 결정 과정의 일부로 취급될 수 있다. 위 그림은 IRIS를 제안한 "Transformers are Sample-Efficient World Models" 논문에 있는 이미지이다.
마르코프 결정 과정이란?
강화학습에서 사용되는 아주 중요한 개념이다.
ML/AI 분야에는 Classification, Regression, Generation 등의 과정도 있지만, Decision Process라는 분야도 있다. 이는 에이전트(의사 결정자, 행위를 결정해서 수행할 수 있는 능력이 있는 객체)가 주어진 환경 속에서 최적의 결정을 내리는 정책을 찾도록 하는 분야이다. 현재는 자율주행이나 로보틱스 쪽에서 널리 활용되며, AGI의 필수 요소 중 하나이다.마르코프 결정 과정은 Decision Process를 모델링하는 커다란 수학적 틀을 제공한다.
마르코프 결정 과정은 이산시간 확률 제어 과정이며, 이산적인 상태를 정의할 수 있는 환경에서 작동한다.마르코르 결정 과정의 조건(마르코프 속성)은 다음과 같다.
0. 상태s와 행동a가 있을 때,
1. 다음 시점에서 마르코프 결정 과정은 새로운 상태s'로 전이한다. 이때 보상함수에 따라 보상R(s, s')가 주어진다.
2. 상태 s에서 상태 s'로 전이할 때에는 의사결정자의 행동 a에만 영향을 받는다(환경에 따른 무작위성이 주어질 수는 있다, 다만 이전의 모든 상태들에는 독립적이어야 한다).
---> 즉, 바로 이전 시퀀스에 대해서만 영향을 받는 확률 문제(1-gram)이다.
실제로 World Model을 연구하는 여러 논문들을 보면 사용되는 변인이나 세부적인 연산 법칙, 학습 정책 등이 (당연하겠지만) 분별성 있게 구성되어 있다.
World Model을 연구하는 연구자 입장에서는 이 변인들과 정책들을 수학적으로 마르코프 결정 과정을 충실히 따르면서 World Model이 효과적으로 학습되기 위한 방식으로 구성할 것이다.
월드 모델은 Robotics나 Embodied AI 등에 사용될 가능성이 높기 때문에 연구가 특히 최근 들어 많이 시작되고 있다.
더불어 Tesla의 차량에도 World model이 사용되었다고 한다.
테슬라의 자율주행 AI가 World Model이라고 불리는 이유
3. RL과 World Model
- 강화 학습과 월드 모델의 연관성
강화 학습과 월드모델은 떼려야 뗄 수 없는 관계이다. 앞서 설명했듯, 월드 모델을 통해 인식하고 상상한 결과를 통해, 에이전트는 다음 행동을 결정하게 되며 이는 강화 학습을 통해 학습된다.
일반적으로 World Model 아키텍처가 없는 강화학습은 MCTS처럼 수많은 데이터가 존재하는 환경에서 효율적으로 학습이 가능하다. 알파고가 MCTS를 사용했다고 널리 알려져 있다. 하지만 이는 학습용 데이터를 충분히 구성할 수 있는 "Go"라는 도메인을 채택했기 때문에 많은 데이터로 학습을 진행할 수 있었다. 하지만 재난구조로봇이나 실제 환경에서는 zero-shot 상황에도 많이 마주할 수 있고, 실제 환경의 데이터를 구성하는 것은 힘들다.
따라서 World Model을 통해서 인공지능이 스스로 환경 위에서 상상할 수 있도록 해주는 것이 앞으로의 강화학습 분야 연구에서 중요한 스트림이 될 수 있을 것이라고 생각한다.
아무튼 월드 모델과 강화학습에 대해서 알아보았다. 다음 포스팅은 연구를 마무리하고 앞서 올린 IRIS나 내 연구에 대해서 돌아보고 연구 시 발생했던 이슈사항이나 내 연구에 대한 이런저런 정보들을 올려볼 예정이다.
