Redis란?
Key-Value 구조의 비정형 데이터를 저장 + 관리하는 오픈 소스 기반의 비관계형 데이터 베이스 관리 시스템(DBMS)이다.
데이터베이스, 캐시, 메세지 브로커로 사용되며 인메모리 데이터 구조로 구성되어 있다.
Redis를 알아보기 전 Cache란 무엇인가?
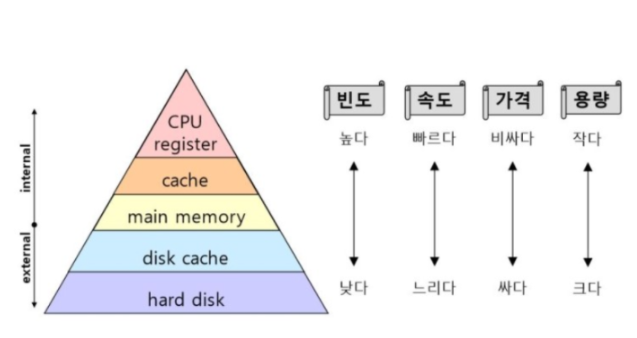
데이터 베이스가 있는데도 Redis라는 인메모리 데이터 구조 저장소를 사용하는 이유는 무엇일까?
데이터 베이스는 데이터를 물리 디스크에 직접 쓰기 때문에 서버에 문제가 생겨 갑작스럽게 다운 되더라도 데이터의 손실이 없다. 하지만 매번 디스크로 접근해야 하는 단점이 있다.
만약 서비스의 규모가 큰 서버를 운영한다고 생각해보자. 클라이언트가 요청을 할 때마다 매번 디스크로 접근을 한다면 사용자가 많아질 수록 디스크에 접근하는 횟수가 많아져 서비스가 느려질 것 이다.
이러한 문제를 해결하기 위해 캐시 서버로 사용할 수 있는 것이 바로 Redis 이다.
캐시는 한번 읽어온 데이터를 임의의 공간에 저장하여 다음에 읽을 때는 빠르게 결과값을 받을 수 있도록 해준다. 따라서 같은 요청이 여러 번 들어오는 경우 매번 데이터 베이스를 거치는 것이 아니라 캐시 서버에서 첫 번째 요청 이후에 저장된 결과 값을 바로 내려주기 때문에 DB의 부하를 줄이고 서비스의 속도가 느려지지 않는다는 장점이 있다.
캐시 서버는 Look aside cache 패턴과 Write Back 패턴이 존재합니다.
Look aside cache
- 클라이언트가 데이터를 요청
- 웹서버는 데이터가 존재하는지 Cache 서버에 먼저 확인
- Cache 서버에 데이터가 있으면 DB에 데이터를 조회하지 않고 Cache 서버에 있는 결과값을 클라이언트에게 바로 반환 (Cache Hit)
- Cache 서버에 데이터가 없으면 DB에 데이터를 조회하여 Cache 서버에 저장하고 결과값을 클라이언트에게 반환 (Cache Miss)
Write Back
- 웹서버는 모든 데이터를 Cache 서버에 저장
- Cache 서버에 특정 시간 동안 데이터가 저장됨
- Cache 서버에 있는 데이터를 DB에 저장
- DB에 저장된 Cache 서버의 데이터를 삭제
- insert 쿼리를 한 번씩 500번 날리는 것보다 insert 쿼리 500개를 붙여서 한 번에 날리는 것이 더 효율적이라는 원리입니다.
- 처음에 cache(메모리)에 먼저 저장하기 때문에 데이터가 날아갈 위험이 있습니다.
Redis의 특징
Redis는 Memcached와 비슷한 캐시 시스템으로 동일한 기능을 제공할 뿐만 아니라 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원하고 있음. Redis는 모든 데이터를 메모리에 저장하고 조회함. 즉, 인메모리 데이터베이스임. Redis는 모든 데이터를 메모리에 저장하는 빠른 DB라고 생각할 수도 있지만 이것은 Redis의 특징 중 일부분으로 다른 인메모리 디비들과의 가장 큰 차이점은 Redis의 다양한 자료구조이다.
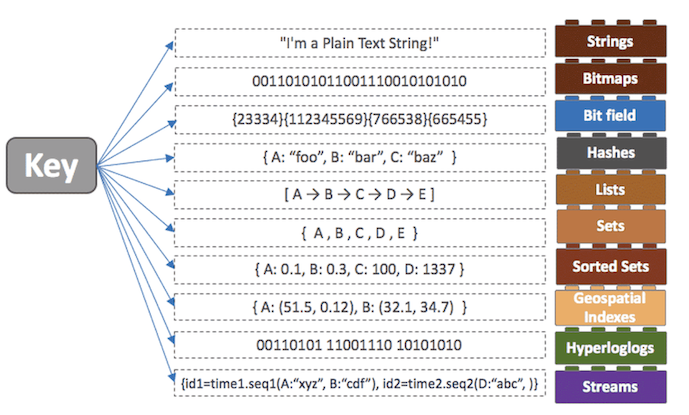
다양한 자료구조를 지원함으로 개발의 편의성 및 난이도가 낮아진다는 장점이 있다. 예를 들어, 어떤 데이터를 정렬 해야하는 상황이 있을 때, DBMS를 이용한다면 시간이 오래 걸릴 것이다. 하지만 이 때 Redis의 Sorted-Set을 사용하면 더 빠르고 간단하게 데이터를 정렬할 수 있다.
- Key-Value 구조로 쿼리를 사용할 필요가 없음
- 데이터를 디스크가 아닌 메모리에서 처리하기 때문에 속도가 빠름
- String, Lists, Sets, Sorted Sets, Hashes 등 다양한 자료 구조를 지원함.
- String : 가장 일반적인 key - value 구조의 형태입니다.
- Sets : String의 집합입니다. 여러 개의 값을 하나의 value에 넣을 수 있습니다. 포스트의 태깅 같은 곳에 사용될 수 있습니다.
- Sorted Sets : 중복된 데이터를 담지 않는 Set 구조에 정렬 Sort를 적용한 구조로 랭킹 보드 서버 같은 구현에 사용할 수 있습니다.
- Lists : Array 형식의 데이터 구조입니다. List를 사용하면 처음과 끝에 데이터를 넣고 빼는 건 빠르지만 중간에 데이터를 삽입하거나 삭제하는 것은 어렵습니다.
- Single Threaded 구조 이다.(한 번에 하나의 명령만 처리할 수 있음)
Redis 영속성
Redis는 지속성을 보장하기 위해 데이터를 DISK에 저장할 수 있습니다. 서버가 내려가더라도 DISK에 저장된 데이터를 읽어서 메모리에 로딩을 합니다.
데이터를 DISK에 저장하는 방식은 크게 두 가지 방식이 있습니다.
- RDB(Snapshotting) 방식
- 순간적으로 메모리에 있는 내용을 DISK에 전체를 옮겨 담는 방식
- AOF(Append On File) 방식
- Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태
Redis의 주의점
- 인메모리 데이터 저장소로 서버가 다운되었을 때 데이터 유실이 발생 할 수 있음
