DB에 접근하지 않으면서 주문번호를 생성해야한다.
이 프로젝트와 관련된 GitHub Link ➡ petLink
DB에 접근하지 않으면서 주문번호를 생성해야한다.
현재 내가 구현중인 기능에서 중요한 부분이였습니다.
여러 주문이 동시에 올걸 생각해서 동시성 문제도 고려하고
최적화도 고민해보고 있는데 가장 기본적으로 주문번호를 생성하면서
매번 DB에 갔다 오면서 유니크한 키를 채번해 오는건 어불성설한 일이었습니다.
현재 요구사항
- 유니크 ID이여야 한다.(중복되지 않아야한다)
- DB를 갔다오지 않아야 한다.
UUID
가장 먼저 생각한건 UUID였습니다.
Universally Unique IDentifier는 고유성을 보장하는 ID를 만들기 위한 표준 규약입니다.
UUID uuid = UUID.randomUUID();장점
고유성 보장 :
UUID는 전 세계적으로 고유한 값을 생성하는 알고리즘을 사용하기 때문에 중복될 확률이 극히 낮습니다.DB 독립성:
UUID는 데이터베이스에 접근하지 않고도 생성할 수 있어, DB의 부하를 줄일 수 있습니다.분산 환경 적합:
고유성 보장과 동일한 말이지만 여러 서버나 데이터베이스에서 동시에 ID를 생성해도 중복될 확률이 거의 없어 분산 환경에서 유용합니다.순차적이지 않은 값:
UUID는 랜덤하게 생성되므로 외부에서 생성 규칙을 추측하기 어렵습니다.
단점
길이:
UUID는 36자리 문자열로, 다른 단순 숫자 ID에 비해 길어서 관리가 더 필요합니다.가독성:
UUID는 긴 문자열로 인해 사람이 읽기 어렵고, 로깅이나 디버깅 시에도 불편할 수 있습니다.성능 이슈:
UUID를 기본 키로 사용하는 경우, 인덱스의 크기가 커져서 데이터베이스의 성능에 영향을 줄 수 있습니다.순차적이지 않음:
일부 환경에서는 ID가 순차적으로 증가하는 것이 유리할 수 있는데, UUID는 이를 만족시키지 못합니다. 예를 들어 정렬 같은 환경에서 활용 불가능합니다.
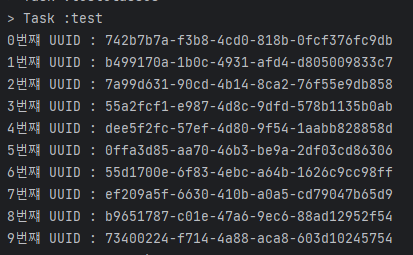
보기만 해도 주문번호로는 활용하기 힘들다고 판단되어
다른 방식을 고려해보기로 했습니다.
DB Accecss
위에서 이미 사용 안한다고 말은 했지만 DB Accecss 를 설명하자면
장점
완벽한 고유성 보장:
DB의 row - count를 참고해 생성하거나, 비지니스 정보를 참고 할 수있어 완벽한 고유성을 확보할 수 있습니다.비지니스 정보 관리:
특수한 정보 규칙을 담아 주문 번호만 봐도 연관자가 파악할 수 있도록 할 수 있습니다. ex ) 주문자PK_ID + 결제일자 + 결제일자 총 주문 갯수정렬,통계 :
위에서 비지니스 정보를 통해 아이디를 만들게 되면 정렬 혹은 통계성 자료를 모두 주문번호만 분석해서 파악할 수 있게 됩니다.
단점
DB 접근:
실시간으로 몇개의 주문이 들어왓는지 확인해야 되어. 무조건 DB에 접근해야하는데, 이 방식은 비용 측면에서 매우 높은 리스크를 발생시킵니다.정보 보안 :
비지니스 정보의 노출:
주문 번호에 비지니스 정보를 포함시키면, 이를 분석하는 제 3자에게 회사의 내부 정보가 노출될 수 있습니다. 예를 들어, 주문자의 PK_ID나 결제일자 등의 정보가 주문 번호에 포함되어 있다면, 이를 통해 회사의 주문 트렌드나 특정 고객의 주문 패턴 등을 추측할 수 있습니다.악의적 활용:
제 3자가 이러한 정보를 악의적으로 활용한다면, 고객의 개인정보 보호는 물론, 회사의 비즈니스 전략이나 마케팅 전략 등에도 영향을 줄 수 있습니다. 특히, 경쟁사나 마케팅 관련 업체 등이 이 정보를 활용한다면, 비즈니스에 큰 손해를 입을 수 있습니다.데이터 변조 위험:
주문 번호의 구조나 생성 규칙을 알게 된 제 3자가 주문 번호를 변조하거나 가짜 주문을 생성하는 등의 악의적인 행위를 할 수 있습니다. 이로 인해 데이터의 무결성이 손상될 수 있으며, 이에 따른 재무적 손해나 고객 불만이 발생할 수 있습니다.
Server
현재 Petlink 프로젝트는 별도의 redis 서버를 통해 재고 동시성 문제를 해결 하고 있습니다.
주문번호 또한 이런 채번서버를 만들수 있습ㄴ다.
장점
동시성 처리:
채번 서버를 사용하면 동시에 여러 주문이 들어와도 각 주문에 대해 고유한 주문 번호를 할당할 수 있습니다. Redis와 같은 인메모리 데이터베이스를 사용하면 빠른 속도로 주문 번호를 생성할 수 있습니다.부하 분산:
주문 번호 생성 요청이 몰릴 경우, 채번 서버를 확장하여 부하를 분산시킬 수 있습니다. 이를 통해 시스템의 안정성을 유지할 수 있습니다.유연한 주문 번호 생성 규칙:
채번 서버를 사용하면 주문 번호 생성 규칙을 유연하게 변경할 수 있습니다. 예를 들어, 특정 이벤트나 프로모션에 따라서 주문 번호의 접두사나 접미사를 변경할 수 있습니다.분산 환경 해소 :
여러 어플리케이션으로 떠있는 상태에서도 하나의 서버에서 처리합으로 일관성을 보장합니다.
단점
서버 관리 비용:
별도의 채번 서버를 운영하려면 추가적인 서버 비용이 발생합니다. 또한, 서버의 유지 보수와 관리에도 비용이 들게 됩니다.서버 다운 위험:
채번 서버가 다운되면 주문 번호를 생성할 수 없게 되므로, 전체 시스템에 큰 영향을 줄 수 있습니다. 따라서 높은 가용성을 보장하는 인프라 구성이 필요합니다. 그런 가용성은 비용이 과하게 발생합니다.복잡한 시스템 구성:
주문 시스템과 별도로 채번 서버를 운영하게 되면 시스템 구성이 복잡해집니다. 이로 인해 별도의 시스템의 오류 가능성이 높아질 수 있습니다.
여기까지가 제가 생각할 수 있는 방식이였습니다.
어떻게 해야 최소한의 리소스로 중복되지 않는 키를 만들까 고민중
멘토님께서 팁을 주셔서 . 트위터 스노우플레이크라는 것을 알게 되었습니다.
트위터 스노우플레이크
트위터 스노우플레이크는 트위터에서 개발한 고유 ID 생성 시스템입니다.
이 시스템은 분산 환경에서도 빠르게 고유한 ID를 생성할 수 있도록 설계되었습니다.
특징
- 64비트 값:
스노우플레이크는 64비트의 정수로 ID를 생성합니다.
이 중 41비트는 시간 정보, 10비트는 머신 또는 노드 정보,
12비트는 시퀀스 번호로 구성되어 있습니다.- 시간 기반 생성:
스노우플레이크는 현재 시간을 기반으로 ID를 생성합니다.
따라서 생성된 ID는 시간 순으로 증가하는 특성을 가집니다.- 분산 환경 적합:
각 머신 또는 노드는 고유한 ID를 가지고 있어,
여러 노드에서 동시에 ID를 생성해도 중복될 확률이 없습니다.장점
빠른 생성 속도:
메모리 기반 연산을 통해 ID를 생성하기 때문에 매우 빠른 속도로 ID를 생성할 수 있습니다.고유성 보장:
시간 정보와 노드 정보, 시퀀스 번호의 조합으로 ID를 생성하기 때문에 진짜 거의 완벽하게 고유한 ID를 보장합니다.스케일 아웃 가능:
노드 정보를 포함하여 ID를 생성하기 때문에, 시스템을 확장하더라도 안정적으로 ID를 생성할 수 있습니다.
단점
시간 동기화 필요:
시스템 시간이 변경되거나 동기화되지 않을 경우, ID 생성에 문제가 발생할 수 있습니다.생성 제한:
1ms 동안 생성할 수 있는 ID의 수에는 제한이 있습니다. 이 제한을 초과할 경우, ID 생성이 지연될 수 있습니다.
단점에 대해서
트위터 스노우플레이크의 단점 중 하나는 1ms 동안 생성할 수 있는 ID의 수에 제한이 있다는 것입니다. 그렇다면, 이 제한은 실제로 어느 정도일까요. 스노우플레이크에서 1ms 동안 생성할 수 있는 ID의 수는 2^12, 즉 4,096개입니다. 이는 1ms 동안 4,096개의 고유한 ID를 생성할 수 있다는 것을 의미합니다. 이제 이 숫자를 실제 비즈니스 환경에 대입해보겠습니다. 대부분의 온라인 비즈니스에서 1ms 동안 4,096개의 주문이 발생하는 것은 매우 드문 일입니다. 심지어 아마존에서도 이러한 주문량은 거의 발생하지 않을 것입니다. 예를 들어,대형 쇼핑몰에서 세일 이벤트 중에 초당 수천 건의 주문이 발생한다고 해도, 1ms 동안 4,096건의 주문이 발생하는 것은 매우 희박한 확률입니다. 즉, 실제 비즈니스 환경에서는 스노우플레이크의 이러한 제한이 문제가 되기 어렵습니다. 또한, 만약 이 제한에 도달하게 된다면, 다음 밀리초에 새로운 ID를 생성할 수 있기 때문에, 실질적인 서비스 지연은 거의 발생하지 않을 것입니다. 결론적으로, 트위터 스노우플레이크의 1ms 동안의 ID 생성 제한은 이론적인 단점일 뿐, 실제 비즈니스 환경에서는 큰 문제가 되지 않습니다. 그런 의미로 이 시스템은 고유한 ID 생성에 있어 매우 효율적이며 신뢰할 수 있는 방법으로 평가받고 있고 저또한 그렇다고 생가각합니다.
그렇다면 이 코드를 제 서비스에 추가해보도록 하겟습니다.
일단 이 스노우 플레이크 방식의 구성에 대해 설명해보자면
총 64개의 비트로 구성되어
첫 번째 비트
이 비트는 항상 0으로 설정됩니다. 이유는, 우리가 생성하려는 ID가 양의 정수값이기 때문입니다.
이 비트는 부호를 나타내는 데 사용되기 때문에 양수를 표현하려면 0으로 설정해야 합니다.
41비트
이 부분은 현재 시간과 "시작 시간"의 차이를 나타냅니다.
예를 들어, 오늘 날짜가 2023년 8월 8일이라면, "시작 시간"인 2010년 11월 4일 10시 42분 54초부터
지금까지의 시간 차이를 이 41비트에 저장합니다.
이 방식으로, 2010년부터 시작하여 약 69~70년 동안 각각의 시간 차이에 따라 고유한 ID를 만들 수 있게 됩니다. 쉽게 말해, 2010년부터 2080년까지의 각각의 시간을 이 41비트로 표현할 수 있습니다.
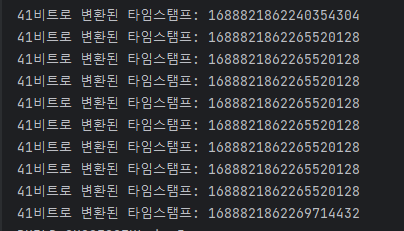
10비트
서비스나 장비의 고유 번호를 나타냅니다. 이 10비트를 더 세분화하여 5비트는 클러스터 ID, 나머지 5비트는 인스턴스 ID로 사용할 수도 있습니다.
예를 들어 현재 어플리케이션서버가 여러개 떠있다고 전제할때
리전코드 5비트 , 리전내 어플케이션 위치 5비트 이렇게 구성할 수 있습니다이렇게 구별함으로서. 다중 서버에서도 중복되지 않는 코드를 생성해냅니다.
12비트
같은 시간에 여러 ID가 생성될 수 있기 때문에,
이를 구분하기 위한 시퀀스 번호를 저장합니다.
이 번호는 1씩 증가하며, 동일한 타임스탬프 내에서 ID의 중복을 방지합니다.이 값은 ms기준으로 증가됩니다.
// 동시에 여러 스레드에서 안전하게 시퀀스 번호를 관리하기 위한 AtomicInteger
private static final AtomicInteger sequenceNumber = new AtomicInteger(0);
// 마지막으로 ID를 생성한 시간을 저장하는 변수
private static long lastTimestamp = -1;
// 동기화된 메소드로 여러 스레드에서 동시에 호출될 때의 동기화 문제를 해결
public static synchronized String generateOrderNumber() throws InterruptedException {
long id = 0L;
// 현재 시간에서 시작 시간을 뺀 값을 계산
long timestamp = System.currentTimeMillis() - 1288834974657L;
// 동일한 밀리초에 여러 번 호출될 경우의 처리
if (timestamp == lastTimestamp) {
int currentSequence = sequenceNumber.incrementAndGet();
// 12비트의 최대 값인 4095를 초과하면 다음 밀리초까지 기다림
if (currentSequence > 4095) {
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis() - 1288834974657L;
}
sequenceNumber.set(0); // 시퀀스 번호 초기화
}
} else {
sequenceNumber.set(0); // 새로운 밀리초에는 시퀀스 번호를 초기화
}
lastTimestamp = timestamp;
// 타임스탬프 값을 ID에 할당
id |= (timestamp << 22);
// 리전 코드와 서버 위치 값을 합쳐 ID에 할당
int regionCode = 3;
int serverPosition = 5;
long serverInfo = (regionCode << 7) | serverPosition;
id |= (serverInfo << 12);
// 시퀀스 번호를 ID에 할당
id |= sequenceNumber.get();
return String.valueOf(id);
}TEST CODE
@Test
void testGenerateOrderNumberInParallel() throws InterruptedException, ExecutionException {
int numberOfThreads = 1000; // 동시에 실행할 스레드의 수
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
Set<String> orderNumbers = Collections.synchronizedSet(new HashSet<>());
List<Callable<Void>> tasks = new ArrayList<>();
for (int i = 0; i < numberOfThreads; i++) {
tasks.add(() -> {
String orderNumber = generateOrderNumber();
orderNumbers.add(orderNumber);
return null;
});
}
List<Future<Void>> futures = executorService.invokeAll(tasks);
// 모든 작업이 완료될 때까지 대기
for (Future<Void> future : futures) {
future.get();
}
assertEquals(numberOfThreads, orderNumbers.size());
executorService.shutdown();
orderNumbers.forEach(System.out::println);
}
- 예시를 위해 임의로 작성한 코드입니다. 실제로는 이런식으로 구현하면 안됩니다
- 1000건이 동시에 들어와도 중복되지 않는 키가 생성되면서 적당한 수준의 길이가 완성되었습니다.
- 또한 정렬을 날짜 기준으로 할 수 있고 , 서버의 정보등을 다른 정보로 치환해 활용할 수 있습니다.
@Test
void changeTimeMillis()throws InterruptedException, ExecutionException{
//1288834974657L 는 Twitter의 Snowflake ID 생성 알고리즘에서 사용되는 특정 시작 시점의 타임스탬프 값.
long timestamp = System.currentTimeMillis() - 1288834974657L;
// 타임스탬프를 원래의 시간 값으로 변환
long originalTimeMillis = timestamp + 1288834974657L;
// Date 객체로 변환하여 출력
Date date = new Date(originalTimeMillis);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(date));
}
공감하며 읽었습니다. 좋은 글 감사드립니다.