SoftIRQ 과 NAPI(New API)
인터럽트의 발생 빈도가 매우 높거나 인터럽트가 발생한 후 바로 처리해야하는 경우 Soft IRQ를 사용한다.
- SoftIRQ (소프트웨어 인터럽트)
하드웨어 인터럽트 처리가 끝나는 시점(irq_exit)에 인터럽트 컨텍스트의 연장선에서 지체 없이 바로 실행, 슬립 금지. (context switching 없음.)
콘텍스트 스위칭 오버헤드가 없어야 하는 대량의 네트워크 패킷 처리(NET_RX_SOFTIRQ)나 타이머 서브시스템에 제한적으로 사용한다.
per-CPU type 사용하므로, lockless 특징 사용 가능.
interrupt context 안에서 실행되므로, I/O 등 sleep이 필요한 작업은 사용 불가능.
네트워크 패킷 처리시, SoftIRQ를 사용하는 NAPI기법으로 패킷 처리
NAPI는 인터럽트와 Polling을 함께 사용해서 패킷을 처리하는 기법. 이때 SoftIRQ가 사용된다.
네트워크 처리의 특성:
네트워크 패킷 처리는 랜카드가 하드웨어적으로 패킷을 받아서 내부 DMA 메모리(RAM)에 다 적재해 둔 상태에서 인터럽트를 생성.
-> 1Gbps NIC의 경우, 많은 양의 인터럽트 생성(Interrupt Storm) 발생, 하나의 패킷당 하나의 인터럽트를 사용하면 인터럽트를 처리해야하는 Top Half 너무 많음 -> CPU 부하 발생.
-> NAPI 알고리즘: 최초 1회의 하드웨어 인터럽트 이후, SoftIRQ 서비스 핸들러에 등록된 드라이버의 polling 을 통해 64개씩 패킷을 처리하고, 임계치를 넘어가면 ksoftirqd thread에서 처리.
- 태스크릿 (Tasklet)
SoftIRQ와 마찬가지로 인터럽트 컨텍스트에서 실행되므로 슬립이 불가능
디바이스 드라이버 개발 시 제공됨.
순서.
open_softirq() -> raise_softirq() -> irq_exit() -> 확인 -> __do_softirq()
SoftIRQ등록은 kernel init 단계에서 이루어진다.
SoftIRQ요청과 실행
raise_softirq()
요청시 interrupt 비활성화, 요청 후 재활성화
인터럽트 컨텍스트가 아닐때 Soft IRQ 실행 -> ksoftirqd 스레드 wake.
or_softirq_pending을 실행하는데, 다음과 같다.
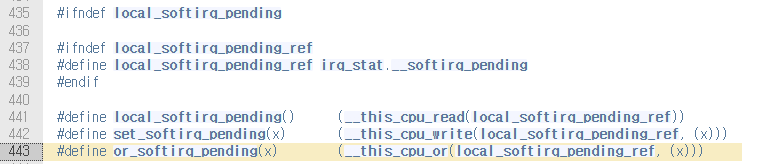
OR연산하여 irq_stat percpu 변수에 bit set.
irq_exit() -> invoke_softirq() 으로 SoftIRQ 중복 요청 방지 및 do_softirq_own_stack() 호출 -> do_softirq() 실행.
do_softirq()는 SoftIRQ 서비스 핸들러 실행이 2ms을 넘거나 10번이상 반복되었다면 종료.
NET_TX/RX_SOFTIRQ
NET_TX/RX_SOFTIRQ를 등록하는 net_dev_init.
kernel init시에 다음과 같이 등록된다.

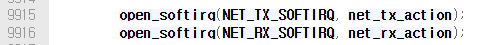
CPSW 드라이버
NAPI을 사용함.
Top-Half (SoftIRQ 요청)
probe()함수. (초기화 함수)
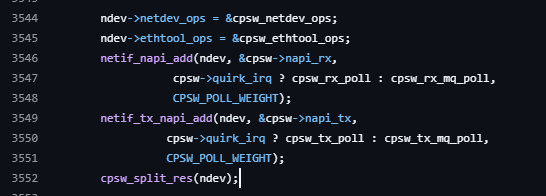
napi 함수 등록 부분, cpsw_rx_poll을 실행하게 한다.
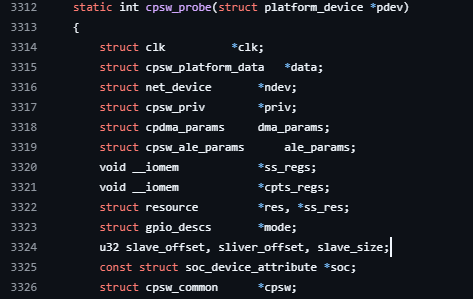
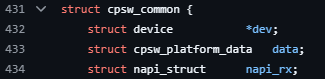
cpsw로 정의된 cpsw_common이라는 드라이버내 구조체내 napi_rx라는 napi_struct type 필드에 cpsw_rx_poll함수를 등록한다. (quirk_irq는 하드웨어적 오류를 해결하기 위한 플래그)
Top Half 등록 부분.

int devm_request_irq(struct device *dev, unsigned int irq,
irq_handler_t handler, unsigned long irqflags,
const char *devname, void *dev_id);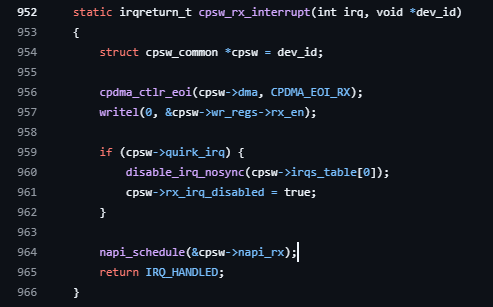
napi_schedule()을 실행시, 다음과 같은 내부함수 실행.
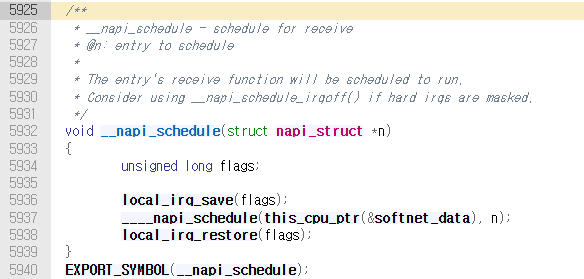
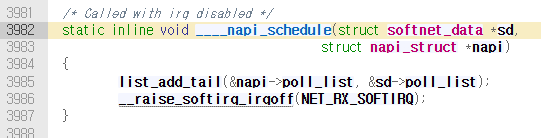
현재 CPU의 네트워크 데이터 구조체(softnet_data)가 관리하는 poll_list의 맨 뒤에, 해당 드라이버의 NAPI 구조체(napi_struct)를 추가한다.
###softnet_data 구조체는 per-CPU type 구조체로, 네트워크 패킷과 napi 드라이버를 관리하는 구조체임. 네트워크 후반부 처리를 위한 온갖 대기열과 제어 변수가 존재함.
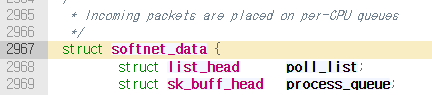
napi드라이버들이 등록되는 poll_list,
NAPI를 지원하지 않는 옛날 랜카드 드라이버들이 패킷을 임시로 쌓아두는 process_queue.
그 후, SoftIRQ 의 종류 중 NET_RX_SOFTIRQ에 bit set하여 irq_exit()시 open_softirq()로 등록되었던 net_rx_action 핸들러가 실행될 수 있게끔 만듦.
즉,
하드웨어 인터럽트 -> napi_schedule() -> per-CPU 구조체 sd->poll_list 대기열에 현재 napi 구조체 추가, raise_softirq로 NET_RX_SOFTIRQ bit set -> irq_exit()시 __do_softirq 으로 net_rx_action 함수 실행.
Bottom-Half
여기까지가 Top-Half에서 napi_schedule을 수행했을때 어떤 함수들이 실행되는지 분석한것.
그후에는 bottom half에서 어떤 것들이 이루어지는지 살펴본다.
polling함수들은 어떤 방식으로 패킷들을 처리하는가?
napi_add로 등록했던 polling함수이다. SoftIRQ 서비스 핸들러(net_rx_action) 실행시 polling 리스트에 따라 호출되는 함수이다.
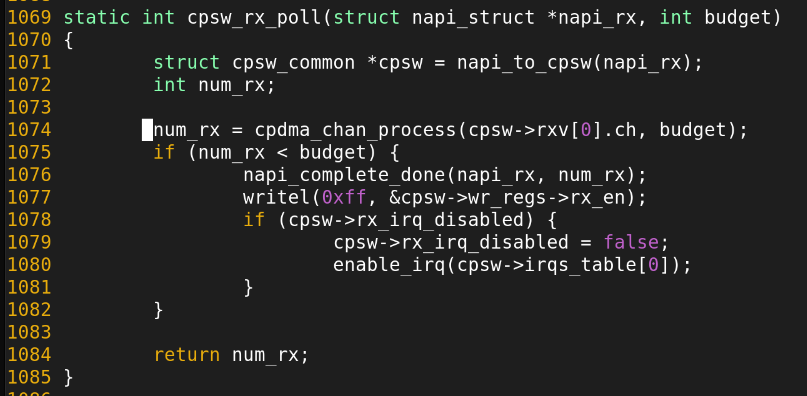
cpdma_chan_process의 동작.
랜카드의 DMA Ring buffer로부터 최대 budget수 만큼을 패킷을 읽어온다. 만약 읽어온 패킷 수가 budget수보다 작다면 마지막 루프인것이므로 마무리 작업을 수행한다.
1. sd->polling_list에서 이 napi 구조체를 제거한다.
2. 꺼져있던 interrupt 를 enable.참고로, napi->bugdet은 다음과 같이 정의되어있다. 즉, 한번에 최대 64개 패킷을 꺼내올 수 있게 하는것.

net_rx_action()은 어떤 방식으로 대기열에 등록된 드라이버들의 poll 함수들을 실행하는것인가?
net/core/dev.c의 net_rx_action 함수는 다음과 같다.
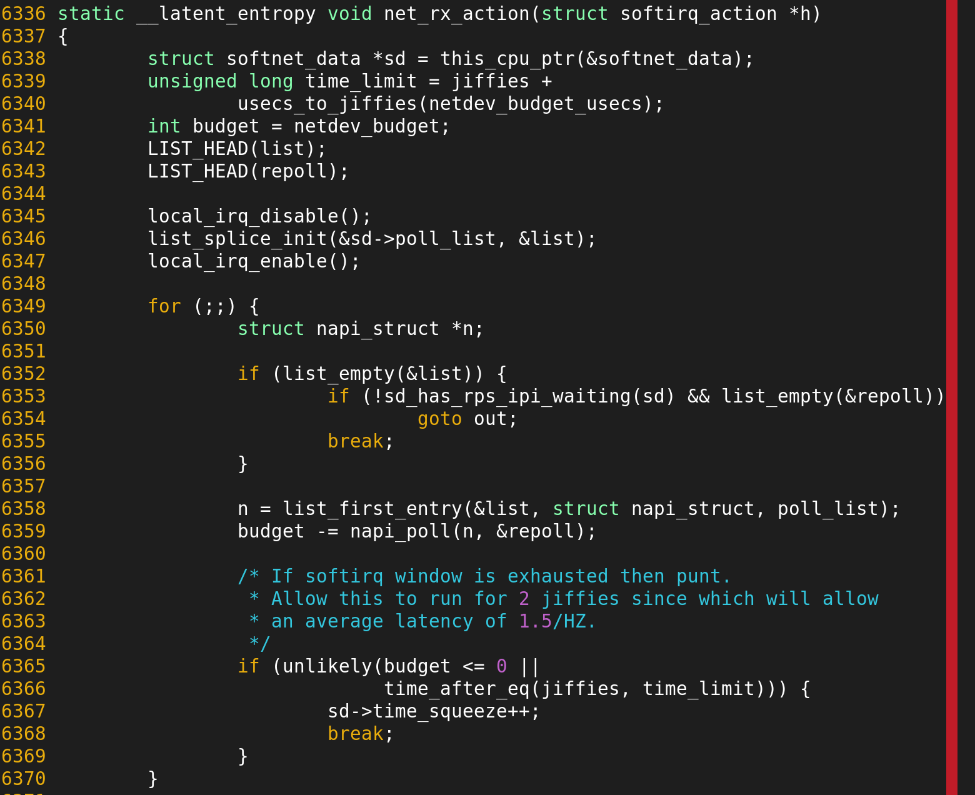
여기서 중요한것은 루프를 돌 때마다, sd->poll_list의 first entry를 가져와서, napi_poll()함수를 통해 등록된 함수를 실행한다는것.
cpsw의 경우, cpsw_rx_poll()함수가 실행될 것이고, return 값은 읽어온(처리한) 패킷의 갯수가 될 것이다.
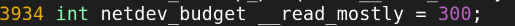
여기서는 300이므로, 총 300개의 패킷을 SoftIRQ thread를 사용하지 않고 처리할 수 있다.
그 후 ksoftirqd 로 넘어가기전, Interrupt context에서 처리할 수 있는 패킷의 양인 budget 에서 그 읽어온 패킷의 갯수를 빼고, break할것인지 루프를 진행할것인지 결정한다.
정리하자면, 다음과 같다.
-
드라이버에서 처리해야할 패킷 양이 64개보다 적을때는, list에서 빠져나오므로 해당 드라이버의 poll함수는 실행되지 않고 다음 순서로 넘어감.
-
break되어서 poll함수 실행 루프에서 빠져나오는 2가지 경우.(처리해야할 패킷이 너무 많을때)
- budget <= 0 일때
다시 대기열에 넣고, NET_RX_SOFTIRQ 비트를 set.
__do_softirq에서 action을 10번하였는지/2ms가 넘어갔는지 확인.
2ms가 넘어갔다면 wakeup_softirqd() - time_limit를 넘긴 상황.
다시 대기열에 넣고, NET_RX_SOFTIRQ 비트를 set.
time_limit를 넘겼으므로, __do_softirq에서 wakeup_softirqd()
- budget <= 0 일때
run_softirqd() -> __do_softirq() 를 통해 다시 break 전까지 리스트에 있는 poll() 반복 실행. -> cond_sched()을 통해 context switching.
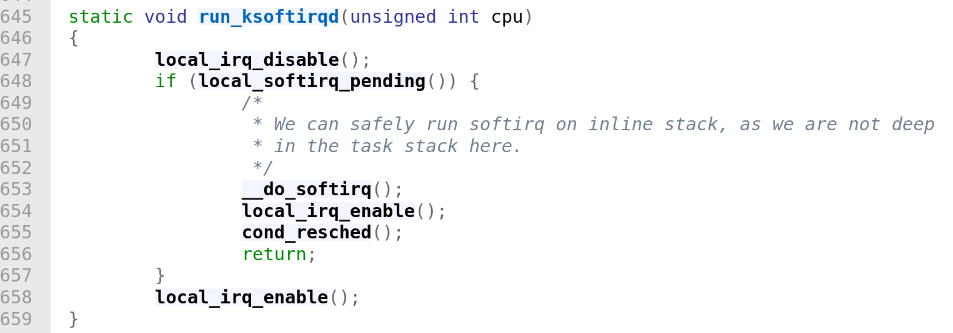
이렇게 시간이 오래걸리는것들은 ksoftirqd 로 처리되도록한다.
그러면 다시 궁금한것...이게 어떻게 interrupt storm을 해결할 수 있는가?
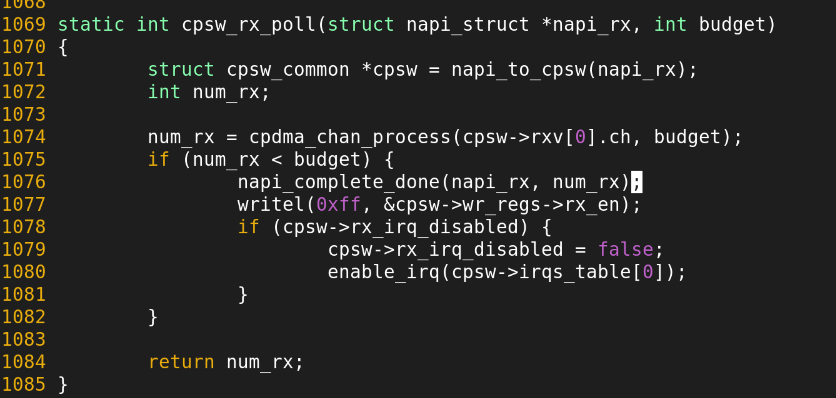
num_rx < budget 전까지, 즉 버퍼에 쌓여있는 패킷들을 모두 처리하기 전까지는 interrupt를 절대 재활성화하지 않는다.
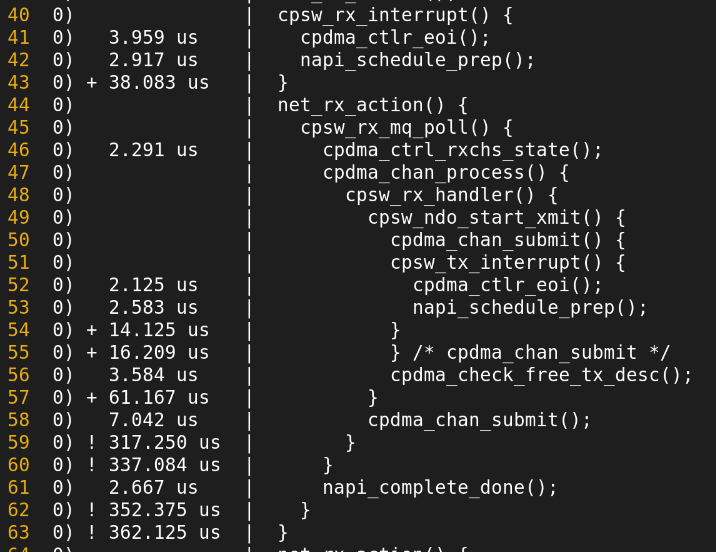
SoftIRQ, NET_RX 관련 확인 가능한것들
현재 존재하는 ksoftirqd들.
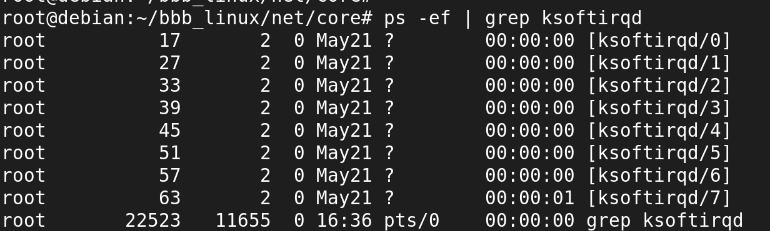
CPU1에서 NET_RX을 처리했음을 알 수 있다.

watch -n 1 cat /proc/softirqs 사용시 1초마다 코어별로 __do_softirq를 실행되는 횟수를 볼 수 있다.
ftrace