13.1 — 프로그램 정의 (사용자 정의) 타입 소개
기본 타입(Fundamental types)은 C++ 언어 자체에 내장되어 있기 때문에 즉시 사용할 수 있습니다.
예를 들어, int나 double 타입의 변수를 만들고 싶다면 다음과 같이 작성하면 됩니다.
int x; // 기본 타입 'int'의 변수 정의
double d; // 기본 타입 'double'의 변수 정의
이는 기본 타입을 간단하게 확장한 복합 타입 (함수, 포인터, 참조, 배열 등)에도 똑같이 적용됩니다.
void fcn(int) {}; // void(int) 타입의 함수 정의
int* ptr; // 'int에 대한 포인터'라는 복합 타입 변수 정의
int& ref { x }; // 'int에 대한 참조'라는 복합 타입 변수 정의 (x로 초기화됨)
int arr[5]; // int[5] 타입인 5개의 정수를 가진 배열 정의 (배열은 나중에 다룰 예정입니다)
C++ 언어는 이미 이러한 타입들의 이름과 기호가 무엇을 의미하는지 알고 있기 때문에 코드가 문제없이 잘 작동합니다.
즉, 우리가 따로 정의를 제공하거나 불러올 필요가 없습니다.
하지만 타입 별칭(Type alias, 10.7 레슨에서 소개함)을 생각해 봅시다. 타입 별칭은 기존 타입에 새로운 이름을 지어주는 기능입니다.
프로그램에 새로운 이름을 추가하는 것이기 때문에, 사용하기 전에 반드시 먼저 정의해야 합니다.
#include <iostream>
using Length = int; // 'Length'라는 이름으로 타입 별칭 정의
int main(){
Length x { 5 }; // 위에서 정의했기 때문에 여기서 'Length'를 사용할 수 있습니다
std::cout << x << '\n';
return 0;
}
만약 Length 의 정의를 빼먹는다면, 컴파일러는 Length 가 무엇인지 알 수 없어서 해당 타입으로 변수를 만들려 할 때 에러를 발생시킵니다. Length 의 정의는 실제 객체를 만드는 것이 아닙니다. 단지 컴파일러에게 Length 가 무엇인지 알려주어 나중에 사용할 수 있게 해줄 뿐입니다.
사용자 정의 / 프로그램 정의 타입이란 무엇인가요?
이전 장(12.1 - 복합 데이터 타입 소개)에서 우리는 분수(Fraction)를 저장할 때 겪는 문제에 대해 이야기했습니다. 분수는 개념적으로 하나로 연결된 분자와 분모를 가지고 있죠. 해당 레슨에서는 분자와 분모를 두 개의 독립적인 정수로 따로 떼어 저장할 때 생기는 어려움을 다루었습니다.
만약 C++에 분수를 위한 타입이 기본적으로 내장되어 있었다면 완벽했겠지만, 아쉽게도 없습니다. C++에는 사람들이 필요로 할 만한 모든 타입을 미리 예상하고 포함해 두는 것이 불가능하기 때문에 수백 가지의 유용한 타입들이 기본적으로 제공되지 않습니다.
대신 C++는 다른 방식으로 이 문제를 해결합니다. 바로 우리가 프로그램에서 사용할 수 있는 완전히 새로운 맞춤형 타입을 직접 만들 수 있게 해주는 것입니다! 이러한 타입을 사용자 정의 타입(User-defined types) 이라고 부릅니다. 하지만 이 레슨의 뒷부분에서 설명하겠지만, 우리가 직접 작성하는 프로그램에서 사용하기 위해 만든 타입은 프로그램 정의 타입(Program-defined types) 이라는 용어를 사용하는 것이 더 좋습니다.
C++에는 프로그램 정의 타입을 만들 때 사용할 수 있는 두 가지 종류의 복합 타입이 있습니다.
- 열거형 타입 (범위가 없는 열거형과 범위가 있는 열거형 포함)
- 클래스 타입 (구조체, 클래스, 공용체 포함)
프로그램 정의 타입 정의하기
타입 별칭과 마찬가지로, 프로그램 정의 타입도 사용하기 전에 반드시 정의하고 이름을 지어주어야 합니다.
프로그램 정의 타입의 정의를 타입 정의(Type definition) 라고 부릅니다.
핵심 포인트
프로그램 정의 타입은 사용하기 전에 반드시 이름과 정의가 있어야 합니다. 다른 복합 타입들은 이 두 가지가 필요하지 않습니다.
함수는 사용하기 전에 이름과 정의가 필요하지만 사용자 정의 타입으로 간주되지는 않습니다. 왜냐하면 이름과 정의가 주어지는 것은 함수 자체이지, 함수의 '타입'이 아니기 때문입니다. 우리가 직접 정의하는 함수는 '사용자 정의 함수'라고 부릅니다.
아직 구조체(struct)가 무엇인지 제대로 배우지 않았지만, 다음은 사용자 맞춤형 Fraction(분수) 타입을 정의하고 그 타입을 사용해 객체를 생성(인스턴스화)하는 예제입니다.
// 컴파일러가 Fraction이 무엇인지 이해할 수 있도록 Fraction이라는 프로그램 정의 타입을 정의합니다
// (구조체가 무엇이고 어떻게 사용하는지는 이번 장에서 나중에 설명하겠습니다)
// 이것은 단지 Fraction 타입이 어떻게 생겼는지 정의할 뿐, 실제 객체를 생성하지는 않습니다
struct Fraction{
int numerator {};
int denominator {};
};
// 이제 Fraction 타입을 사용할 수 있습니다
int main(){
Fraction f { 3, 4 }; // 이것은 실제로 f라는 이름의 Fraction 객체를 생성(인스턴스화)합니다
return 0;
}
이 예제에서 우리는 struct 키워드를 사용하여 Fraction 이라는 새로운 프로그램 정의 타입을 전역 범위에 정의했습니다 (파일의 어느 곳에서든 사용할 수 있도록 말이죠). 이 과정은 메모리를 할당하지 않습니다. 단지 컴파일러에게 Fraction 이 어떻게 생겼는지 알려주어 나중에 Fraction 타입의 객체를 할당할 수 있게 해주는 것입니다. 그 후 main() 함수 안에서 우리는 f 라는 이름의 Fraction 타입 변수를 생성하고 초기화합니다.
프로그램 정의 타입의 정의는 반드시 세미콜론(;)으로 끝나야 합니다. 타입 정의 끝에 세미콜론을 빼먹는 것은 프로그래머들이 아주 흔하게 하는 실수입니다. 컴파일러가 타입 정의 줄이 아닌 그 다음 줄에서 에러를 띄울 수 있기 때문에 버그를 찾기 매우 어려울 수 있습니다.
경고
타입 정의 끝에 세미콜론을 붙이는 것을 절대 잊지 마세요.
다음 레슨(13.2 - 범위가 없는 열거형)에서 프로그램 정의 타입을 정의하고 사용하는 더 많은 예제를 보여드릴 예정이며, 구조체에 대해서는 13.7 레슨부터 본격적으로 다룹니다.
프로그램 정의 타입 이름 짓기
관례적으로 프로그램 정의 타입의 이름은 대문자로 시작하며, 뒤에 따로 접미사를 붙이지 않습니다 (예: fraction, fraction_t, Fraction_t 가 아니라 Fraction 으로 작성).
모범 사례
프로그램 정의 타입의 이름은 대문자로 시작하게 짓고, 접미사를 사용하지 마세요.
초보 프로그래머들은 타입 이름과 변수 이름이 비슷해서 다음과 같은 변수 정의를 헷갈려하곤 합니다.
Fraction fraction {}; // Fraction 타입의 fraction이라는 이름의 변수를 생성합니다
이는 다른 변수를 정의하는 것과 전혀 다르지 않습니다. 타입(Fraction)이 먼저 오고 (대문자로 시작하기 때문에 프로그램 정의 타입이라는 것을 알 수 있죠), 그다음 변수 이름(fraction)이 오며, 마지막으로 선택적인 초기화 코드가 옵니다. C++는 대소문자를 구분하기 때문에 이름이 충돌할 일은 없습니다!
여러 파일로 이루어진 프로그램에서 프로그램 정의 타입 사용하기
프로그램 정의 타입을 사용하는 모든 코드 파일은 해당 타입을 사용하기 전에 전체 타입 정의를 반드시 확인해야 합니다.
전방 선언만으로는 충분하지 않습니다. 이는 컴파일러가 해당 타입의 객체를 위해 메모리를 얼마나 할당해야 하는지 알아야 하기 때문입니다.
타입 정의를 필요로 하는 여러 코드 파일에 전달하기 위해, 프로그램 정의 타입은 보통 헤더 파일에 정의됩니다.
그리고 그 타입 정의가 필요한 모든 코드 파일에서 #include 를 통해 불러옵니다. 이러한 헤더 파일의 이름은 보통 프로그램 정의 타입의 이름과 똑같이 짓습니다 (예를 들어, Fraction 이라는 프로그램 정의 타입은 Fraction.h 에 정의합니다).
모범 사례
단 하나의 코드 파일에서만 사용하는 프로그램 정의 타입은 해당 코드 파일 안에서 처음 사용하는 곳과 최대한 가까운 위치에 정의하세요.
여러 코드 파일에서 사용하는 프로그램 정의 타입은 타입 이름과 동일한 이름의 헤더 파일에 정의한 후, 필요한 코드 파일마다#include로 불러와야 합니다.
Fraction 타입을 헤더 파일(Fraction.h)로 옮겨서 여러 코드 파일에 포함시킬 수 있게 만들면 다음과 같은 모습이 됩니다.
Fraction.h:
#ifndef FRACTION_H
#define FRACTION_H
// Fraction이라는 새로운 타입을 정의합니다
// 이것은 단지 Fraction이 어떻게 생겼는지 정의할 뿐, 실제 객체를 생성하지는 않습니다
// 주의: 이것은 전방 선언이 아니라 완전한 정의입니다
struct Fraction{
int numerator {};
int denominator {};
};
#endif
Fraction.cpp:
#include "Fraction.h" // 이 코드 파일에 우리의 Fraction 정의를 포함시킵니다
// 이제 Fraction 타입을 사용할 수 있습니다
int main(){
Fraction f{ 3, 4 }; // 이것은 실제로 f라는 이름의 Fraction 객체를 생성합니다
return 0;
}
타입 정의는 단일 정의 규칙(ODR)에서 부분적으로 예외입니다
2.7 레슨(전방 선언과 정의)에서 우리는 단일 정의 규칙(ODR)에 따라 각 함수와 전역 변수가 프로그램 내에서 단 하나의 정의만 가져야 한다고 배웠습니다. 정의가 포함되지 않은 파일에서 해당 함수나 전역 변수를 사용하려면 전방 선언이 필요합니다 (우리는 보통 이를 헤더 파일을 통해 전달합니다). 함수나 constexpr 이 아닌 변수의 경우, 선언만으로도 컴파일러를 만족시킬 수 있고 나중에 링커(Linker)가 모든 것을 연결해 주기 때문에 이 방식이 잘 작동합니다.
하지만 타입에 대해 이와 비슷한 방식으로 전방 선언을 사용하는 것은 작동하지 않습니다. 컴파일러가 특정 타입을 사용하려면 보통 전체 정의를 직접 봐야 하기 때문입니다. 따라서 우리는 타입이 필요한 모든 코드 파일에 전체 타입 정의를 전달할 수 있어야 합니다.
이를 가능하게 하기 위해, 타입은 단일 정의 규칙(ODR)에서 부분적으로 예외 처리를 받습니다. 즉, 특정 타입은 여러 코드 파일에 걸쳐 정의될 수 있습니다.
여러분은 아마 눈치채지 못했겠지만 이미 이 기능을 사용해 보셨을 겁니다. 만약 여러분의 프로그램에 #include <iostream> 을 포함하는 두 개의 코드 파일이 있다면, 두 파일 모두에 입출력 관련 타입 정의들을 모두 가져오고 있는 셈이니까요.
여기서 알아두어야 할 두 가지 주의사항이 있습니다. 첫째, 하나의 코드 파일 안에는 여전히 하나의 타입 정의만 존재해야 합니다 (보통 헤더 가드(Header guards)가 이를 막아주기 때문에 큰 문제는 되지 않습니다). 둘째, 특정 타입에 대한 모든 타입 정의는 완전히 똑같아야 합니다. 그렇지 않으면 정의되지 않은 동작(Undefined behavior)이 발생합니다.
용어 정리: 사용자 정의 타입 vs 프로그램 정의 타입
사용자 정의 타입(User-defined type) 이라는 용어는 일상적인 대화에서 종종 등장하며, C++ 언어 표준에서도 언급됩니다 (하지만 명확히 정의되어 있지는 않습니다). 일상적인 대화에서 이 용어는 보통 '우리 자신의 프로그램 내에서 직접 정의한 타입'을 의미합니다 (위의 Fraction 타입 예제처럼요).
C++ 언어 표준은 사용자 정의 타입 이라는 용어를 조금 다르게 사용합니다. 언어 표준에서 '사용자 정의 타입'이란 여러분, 표준 라이브러리, 또는 구현체(예: 컴파일러가 언어 확장을 지원하기 위해 정의한 타입)가 정의한 모든 클래스 타입이나 열거형 타입을 뜻합니다. 직관적이지 않을 수 있지만, 이 기준에 따르면 std::string (표준 라이브러리에 정의된 클래스 타입)도 사용자 정의 타입으로 간주됩니다!
더 확실한 구분을 위해, C++20 언어 표준에서는 프로그램 정의 타입(Program-defined type) 이라는 용어를 새롭게 정의했습니다. 이는 표준 라이브러리, 구현체, 또는 핵심 언어의 일부로 정의되지 않은 클래스 타입과 열거형 타입을 의미합니다. 다시 말해, '프로그램 정의 타입'은 오직 우리 (또는 서드파티 라이브러리)가 직접 정의한 클래스 타입과 열거형 타입만을 포함합니다.
결과적으로, 우리가 직접 작성하는 프로그램에서 사용하기 위해 정의하는 클래스 타입과 열거형 타입만을 이야기할 때는 더 정확한 의미를 가진 프로그램 정의(Program-defined) 라는 용어를 사용하는 것이 좋습니다.
| 타입 (Type) | 의미 (Meaning) | 예시 (Examples) |
|---|---|---|
| 기본 (Fundamental) | C++ 핵심 언어에 내장된 기본 타입 | int, std::nullptr_t |
| 복합 (Compound) | 다른 타입들을 기반으로 정의된 타입 | int&, double*, std::string, Fraction |
| 사용자 정의 (User-defined) | 클래스 타입 또는 열거형 타입 |
13.2 — 범위 없는 열거형(Unscoped enumerations)
C++에는 유용한 기본 자료형과 복합 자료형이 많이 있습니다.
하지만 우리가 프로그래밍을 하다 보면 이런 기본적인 자료형만으로는 충분하지 않을 때가 있습니다.
예를 들어, 사과가 빨간색인지, 노란색인지, 초록색인지 기억해야 하거나, 정해진 목록에서 셔츠의 색상을 저장하는 프로그램을 만든다고 가정해 볼까요? 기본 자료형만 사용할 수 있다면 어떻게 코드를 짜야 할까요?
아마도 '0은 빨간색, 1은 초록색, 2는 파란색'처럼 암묵적인 규칙을 만들어 정수값으로 색상을 저장하게 될 것입니다.
int main(){
int appleColor{ 0 }; // 내 사과는 빨간색입니다
int shirtColor{ 1 }; // 내 셔츠는 초록색입니다
return 0;}
하지만 이 방식은 전혀 직관적이지 않습니다.
우리는 이미 코드에 덩그러니 쓰인 매직 넘버 가 왜 나쁜지 배운 적이 있죠.
기호 상수를 사용하면 이 매직 넘버를 없앨 수 있습니다.
constexpr int red{ 0 };
constexpr int green{ 1 };
constexpr int blue{ 2 };
int main(){
int appleColor{ red };
int shirtColor{ green };
return 0;}
코드를 읽기는 조금 편해졌지만, 프로그래머는 여전히 int 타입인 appleColor와 shirtColor가 따로 정의된 색상 상수값 중 하나를 가져야 한다는 사실을 직접 유추해 내야만 합니다.
타입 별칭을 사용하면 코드를 조금 더 명확하게 만들 수 있습니다.
using Color = int; // Color라는 이름의 타입 별칭을 정의합니다
// 다음 색상 값들은 Color 타입을 위해 사용되어야 합니다
constexpr Color red{ 0 };
constexpr Color green{ 1 };
constexpr Color blue{ 2 };
int main(){
Color appleColor{ red };
Color shirtColor{ green };
return 0;}
점점 나아지고 있네요! 코드를 읽는 사람은 이 색상 상수들이 Color 타입의 변수와 짝을 이뤄 사용된다는 것을 알 수 있습니다.
하지만 Color는 결국 int의 별칭일 뿐이므로, 여전히 이 상수들이 올바르게 쓰이도록 강제할 방법이 없다는 문제가 남습니다.
여전히 다음과 같은 엉뚱한 코드를 작성할 수 있죠.
Color eyeColor{ 8 }; // 문법적으로는 유효하지만, 의미상으로는 아무 뜻도 없습니다
게다가 디버거로 이 변수들을 확인해 보면, 기호의 의미인 'red'가 아니라 정수값인 '0'만 보이기 때문에 우리 프로그램이 올바르게 돌아가고 있는지 확인하기가 어렵습니다. 다행히도 C++에는 훨씬 더 좋은 방법이 있습니다.
bool 타입을 한 번 떠올려 보세요.
bool이 특별한 이유는 오직 true와 false라는 두 가지 값만 가질 수 있다는 점입니다.
컴파일러는 bool을 다른 타입과 명확히 구분할 수 있습니다.
만약 우리가 우리만의 맞춤형 타입 을 만들고, 그 타입이 가질 수 있는 이름표(값)들을 직접 정의할 수 있다면, 앞서 말한 문제를 우아하게 해결할 완벽한 도구가 될 것입니다.
열거형 (Enumerations)
열거형(Enumeration, 또는 Enum) 은 가질 수 있는 값이 우리가 이름 붙인 기호 상수(이를 열거자(Enumerator) 라고 부릅니다)들로만 제한되는 복합 자료형입니다.
C++는 두 가지 종류의 열거형을 지원합니다.
바로 범위 없는 열거형(Unscoped enumerations) 과 범위 있는 열거형(Scoped enumerations)입니다.
이번 장에서는 범위 없는 열거형에 대해 알아보겠습니다.
열거형은 프로그래머가 직접 정의하는 타입이므로, 사용하기 전에 전체 정의가 완료되어야 합니다. (전방 선언만으로는 부족합니다.)
범위 없는 열거형 (Unscoped enumerations)
범위 없는 열거형은 enum 키워드를 사용해 정의합니다.
백문이 불여일견이니, 색상 값을 담을 수 있는 열거형을 만들어보며 이해해 봅시다.
// Color라는 이름의 새로운 범위 없는 열거형을 정의합니다
enum Color{
// 여기에 열거자(enumerators)들이 있습니다
// 이 기호 상수들은 이 타입이 가질 수 있는 모든 가능한 값들을 정의합니다
// 각 열거자는 세미콜론이 아니라 쉼표로 구분합니다
red,
green,
blue, // 마지막 쉼표는 선택 사항이지만 권장됩니다
}; // 열거형 정의는 반드시 세미콜론으로 끝나야 합니다
int main(){
// Color 열거형 타입의 변수 몇 개를 정의합니다
Color apple { red }; // 내 사과는 빨간색입니다
Color shirt { green }; // 내 셔츠는 초록색입니다
Color cup { blue }; // 내 컵은 파란색입니다
Color socks { white }; // 에러: white는 Color의 열거자가 아닙니다
Color hat { 2 }; // 에러: 2는 Color의 열거자가 아닙니다
return 0;}
enum 키워드를 사용해 컴파일러에게 Color라는 범위 없는 열거형을 정의하겠다고 알려주는 것으로 시작합니다.
중괄호 안에는 Color 타입의 열거자(Enumerator) 인 red, green, blue를 정의합니다.
이 열거자들은 Color 타입이 가질 수 있는 구체적인 값들입니다.
주의할 점 은 각 열거자를 세미콜론(;)이 아닌 쉼표(,)로 구분해야 한다는 것입니다.
main() 함수 안에서 Color 타입의 변수 세 개를 만들었습니다.
열거형 변수를 초기화할 때는 반드시 해당 열거형에 정의된 열거자 중 하나만 사용해야 합니다.
변수 socks와 hat은 초기값인 white와 2가 Color의 열거자가 아니기 때문에 컴파일 에러가 발생합니다.
참고로 열거자들은 암묵적으로 constexpr(상수 표현식)로 취급됩니다.
용어 다시 보기
- 열거형(Enumeration, Enumerated type) 은 프로그래머가 만든 타입 그 자체를 말합니다. (예:
Color) - 열거자(Enumerator) 는 그 열거형에 속한 특정한 이름의 값을 말합니다. (예:
red)
이름 짓기 규칙
관례적으로 프로그래머가 정의한 모든 타입이 그렇듯, 열거형의 이름은 대문자로 시작합니다.
열거자의 이름에는 공통된 명명 규칙이 딱히 없습니다. 소문자로 시작하거나, 대문자로 시작하거나, 전체를 대문자로 쓰거나(RED), 접두사를 붙이기도 합니다.
하지만 모던 C++ 가이드라인 에서는 매크로와 충돌할 수 있는 전체 대문자(ALL CAPS) 표기법은 피하라고 권장합니다.
권장 사항
열거형의 이름은 대문자로 시작하고, 열거자의 이름은 소문자로 시작하도록 지어주세요.
열거형은 서로 다른 독립적인 타입입니다
여러분이 만든 각 열거형은 컴파일러가 다른 타입과 명확히 구분할 수 있는 독립적인 타입(Distinct type) 으로 취급됩니다.
따라서 한 열거형의 열거자를 다른 열거형 객체에 섞어서 쓸 수 없습니다.
enum Pet{
cat,
dog,
pig,
whale,
};
enum Color{
black,
red,
blue,
};
int main(){
Pet myPet { black }; // 컴파일 에러: black은 Pet의 열거자가 아닙니다
Color shirt { pig }; // 컴파일 에러: pig는 Color의 열거자가 아닙니다
return 0;}
열거형의 활용
열거자는 의미를 설명해 주기 때문에 코드의 가독성을 높여줍니다.
개수가 적고 서로 연관된 상수들의 집합이 있을 때 열거형을 쓰면 좋습니다.
흔히 요일, 방위, 카드 무늬 등을 정의할 때 사용됩니다.
enum DaysOfWeek{
sunday,
monday,
tuesday, // ... 등등
};
enum CardinalDirections{
north,
east,
south,
west,
};
가끔 함수가 제대로 실행되었는지 에러가 났는지 알려주는 상태 코드(Status code) 를 반환해야 할 때가 있죠.
예전에는 의미를 알 수 없는 음수를 썼지만,
int readFileContents(){
if (!openFile())
return -1;
if (!readFile())
return -2;
// ...
return 0; // 성공
}
이제는 열거형을 써서 훨씬 명확하게 만들 수 있습니다.
enum FileReadResult{
readResultSuccess,
readResultErrorFileOpen,
readResultErrorFileRead,
readResultErrorFileParse,
};
FileReadResult readFileContents(){
if (!openFile())
return readResultErrorFileOpen;
// ...
return readResultSuccess;}
이렇게 하면 함수를 호출하는 쪽에서도 결과값을 이해하기 쉬운 열거자와 비교할 수 있습니다.
if (readFileContents() == readResultSuccess){
// 무언가를 수행합니다
}else{
// 에러 메시지를 출력합니다
}
게임에서 아이템이나 몬스터 종류를 구분할 때, 또는 사용자가 여러 옵션 중 하나를 선택해야 할 때도 아주 유용하게 쓰입니다.
enum SortOrder{
alphabetical,
alphabeticalReverse,
numerical,
};
void sortData(SortOrder order){
switch (order)
{
case alphabetical:
// 알파벳 정방향 순서로 데이터를 정렬합니다
break;
case alphabeticalReverse:
// 알파벳 역방향 순서로 데이터를 정렬합니다
break;
case numerical:
// 숫자 순서로 데이터를 정렬합니다
break;
}
}
범위 없는 열거형의 스코프(Scope) 문제
이 열거형들을 '범위 없는(Unscoped)'이라고 부르는 데는 이유가 있습니다.
열거자의 이름들이 열거형 자체가 정의된 공간(전역 스코프 등)과 똑같은 곳에 흩뿌려지기 때문입니다.
enum Color // 이 열거형은 전역 네임스페이스에 정의되었습니다
{
red, // 따라서 red도 전역 네임스페이스에 들어갑니다
green,
blue,
};
이러면 전역 스코프가 오염되고 이름 충돌(Naming collisions) 이 발생할 확률이 크게 높아집니다.
그래서 같은 스코프 안에서는 여러 열거형에서 똑같은 이름의 열거자를 쓸 수가 없습니다.
enum Color{
red,
green,
blue, // blue는 전역 네임스페이스에 들어갑니다
};
enum Feeling{
happy,
tired,
blue, // 에러: 위에서 정의한 blue와 이름 충돌이 발생합니다
};
열거자 이름 충돌 방지하기
이름 충돌을 막는 좋은 방법 중 하나는 열거형을 네임스페이스(Namespace) 안에 넣는 것입니다.
namespace Color{
// Color, red, blue, green이라는 이름들은 네임스페이스 Color 안에 정의됩니다
enum Color
{
red,
green,
blue,
};
}
namespace Feeling{
enum Feeling
{
happy,
tired,
blue, // Feeling::blue는 Color::blue와 충돌하지 않습니다
};
}
int main(){
Color::Color paint{ Color::blue };
Feeling::Feeling me{ Feeling::blue };
return 0;}
권장 사항
열거형이 전역 네임스페이스를 어지럽히지 않도록, 네임스페이스나 클래스 같은 명명된 스코프 안에 넣는 것을 항상 우선순위로 두세요.
열거자 비교하기
동등 연산자(== 및 !=)를 사용하여 열거형 변수가 어떤 값을 가지고 있는지 쉽게 테스트할 수 있습니다.
#include <iostream>
enum Color{
red,
green,
blue,
};
int main(){
Color shirt{ blue };
if (shirt == blue) // 셔츠가 파란색이라면
std::cout << "당신의 셔츠는 파란색입니다!";
else
std::cout << "당신의 셔츠는 파란색이 아닙니다!";
return 0;}
13.3 — 범위 없는 열거형의 정수 변환
이전 레슨(13.2 -- 범위 없는 열거형)에서는 열거자(enumerator)가 기호 상수(symbolic constant)라고 배웠습니다.
그때 말씀드리지 않은 사실이 하나 있는데, 바로 이 열거자들이 내부적으로는 정수형(integral type) 값을 가진다는 것입니다.
이는 char 자료형(4.11 -- 문자형)과 비슷합니다. 다음 코드를 볼까요?
char ch { 'A' };
char 는 실제로는 1바이트 크기의 정수 값입니다. 문자 'A' 는 내부적으로 정수 값(이 경우 65)으로 변환되어 저장되죠.
열거형을 정의할 때, 각각의 열거자는 목록에 있는 위치에 따라 자동으로 정수 값과 연결됩니다.
기본적으로 첫 번째 열거자는 정수 값 0 을 가지고, 그 다음 열거자들은 이전 값보다 1씩 큰 값을 가지게 됩니다.
enum Color
{
black, // 0
red, // 1
blue, // 2
green, // 3
white, // 4
cyan, // 5
yellow, // 6
magenta, // 7
};
int main()
{
Color shirt{ blue }; // shirt는 실제로 정수 값 2를 저장합니다
return 0;
}
열거자의 값을 우리가 직접 지정해 줄 수도 있습니다.
이 정수 값은 양수나 음수 모두 가능하며, 다른 열거자와 같은 값을 가질 수도 있습니다.
값을 직접 지정하지 않은 열거자는 바로 이전 열거자의 값보다 1 큰 값을 가집니다.
enum Animal
{
cat = -3, // 음수 값도 가능합니다
dog, // -2
pig, // -1
horse = 5,
giraffe = 5, // horse와 같은 값을 가집니다
chicken, // 6
};
위 코드에서 horse 와 giraffe 는 같은 값을 가집니다. 이렇게 되면 두 열거자는 구분이 안 되고 사실상 똑같이 취급됩니다.
C++ 에서는 이를 허용하지만, 같은 열거형 안에서 두 열거자에 같은 값을 할당하는 것은 일반적으로 피하는 것이 좋습니다.
대부분의 경우 열거자의 기본값만으로도 충분하므로, 특별한 이유가 없다면 값을 직접 지정하지 마세요.
모범 사례
특별한 이유가 없다면 열거자에 명시적인 값을 할당하지 마세요.
열거형의 값 초기화 (Value-initializing an enumeration)
값 초기화(value-initialization)를 사용하여 열거형을 0으로 초기화하면, 해당 값(0)을 가진 열거자가 목록에 없더라도 열거형은 0 값을 가지게 됩니다.
#include <iostream>
enum Animal
{
cat = -3, // -3
dog, // -2
pig, // -1
// 참고: 이 목록에는 값이 0인 열거자가 없습니다
horse = 5, // 5
giraffe = 5, // 5
chicken, // 6
};
int main()
{
Animal a {}; // 값 초기화를 통해 a를 0으로 초기화합니다
std::cout << a; // 0을 출력합니다
return 0;
}
여기에는 두 가지 의미론적 결과가 따릅니다.
- 값이 0인 열거자가 존재한다면, 값 초기화를 할 때 그 열거자의 의미가 기본값이 됩니다.
예를 들어 이전의Color열거형에서 값 초기화된 색상은 기본적으로black이 됩니다.
이러한 이유로, 값이 0인 열거자를 해당 열거형의 가장 적절한 기본 상태 를 나타내도록 설정하는 것이 좋습니다.
따라서 다음과 같은 코드는 문제를 일으킬 가능성이 높습니다.
enum UniverseResult
{
destroyUniverse, // 기본값 (0)
saveUniverse
};
- 값이 0인 열거자가 없다면, 값 초기화를 했을 때 의미상 유효하지 않은 상태가 만들어지기 쉽습니다.
이런 경우에는 값이 0인 "유효하지 않음(invalid)" 또는 "알 수 없음(unknown)"을 뜻하는 열거자를 추가하는 것을 추천합니다.
이렇게 하면 해당 상태의 의미를 문서화할 수 있고, 코드에서도 명시적으로 처리할 수 있습니다.
enum Winner
{
winnerUnknown, // 기본값 (0)
player1,
player2,
};
// 코드의 다른 부분에서
if (w == winnerUnknown) // 상황에 맞게 처리합니다
모범 사례
0값을 가지는 열거자를 해당 열거형의 가장 적절한 기본 상태로 만드세요. 마땅한 기본 상태가 없다면,0값을 가지는 "유효하지 않음(invalid)"이나 "알 수 없음(unknown)" 열거자를 추가하는 것을 고려해 보세요. 문서화도 되고 적절한 예외 처리도 가능해집니다.
범위 없는 열거형은 정수 값으로 암시적 변환됩니다
열거형은 정수 값을 저장하지만, 정수 자료형으로 취급되지는 않습니다(복합 자료형입니다).
하지만 범위 없는 열거형은 정수 값으로 암시적 변환(implicit conversion) 이 일어납니다.
열거자는 컴파일 타임 상수이기 때문에 이는 constexpr 변환에 해당합니다(이에 대해서는 10.4 레슨에서 다룹니다).
다음 프로그램을 살펴봅시다.
#include <iostream>
enum Color
{
black, // 0 할당됨
red, // 1 할당됨
blue, // 2 할당됨
green, // 3 할당됨
white, // 4 할당됨
cyan, // 5 할당됨
yellow, // 6 할당됨
magenta, // 7 할당됨
};
int main()
{
Color shirt{ blue };
std::cout << "Your shirt is " << shirt << '\n'; // 이 코드는 무엇을 할까요?
return 0;
}
열거형은 정수 값을 가지고 있기 때문에, 여러분이 예상하셨듯이 다음과 같이 출력됩니다.
Your shirt is 2
함수 호출이나 연산자에 열거형이 사용될 때, 컴파일러는 먼저 해당 열거형과 일치하는 함수나 연산자를 찾으려 시도합니다.
예를 들어 컴파일러가 std::cout << shirt 를 컴파일할 때, 먼저 operator<< 가 Color 타입의 객체를 출력할 줄 아는지 확인합니다.
하지만 해당 연산자는 그 방법을 모릅니다.
컴파일러는 일치하는 항목을 찾지 못했기 때문에, 이번에는 operator<< 가 이 범위 없는 열거형이 변환될 수 있는 정수 타입 의 객체를 출력할 줄 아는지 확인합니다. 이것은 가능하기 때문에 shirt 안의 값은 정수 값으로 변환되어 2 라는 정수로 출력됩니다.
- 관련 내용(Related content) * 13.4 레슨에서는 열거형을 문자열로 변환하는 방법을 다룹니다.
- 13.5 레슨에서는
std::cout에게 열거자를 직접 출력하는 방법을 가르쳐주는 오버로딩에 대해 배웁니다.
열거형의 크기와 기본 자료형 (Underlying type)
열거자들은 정수형 값을 가집니다. 그렇다면 구체적으로 어떤 정수형일까요?
열거자의 값을 표현하는 데 사용되는 특정 정수형을 열거형의 기본 자료형(underlying type 또는 base) 이라고 부릅니다.
범위 없는 열거형에 대해 C++ 표준은 구체적으로 어떤 정수형을 기본 자료형으로 써야 하는지 명시하지 않았으므로, 이는 컴파일러 구현에 따라 달라집니다. 대부분의 컴파일러는 int 를 기본 자료형으로 사용합니다(즉, 범위 없는 열거형의 크기는 int 와 동일합니다).
단, 열거자 값을 저장하는 데 더 큰 자료형이 필요한 경우는 예외입니다.
하지만 모든 컴파일러나 플랫폼에서 항상 이럴 것이라고 가정해서는 안 됩니다.
열거형의 기본 자료형을 명시적으로 지정할 수도 있습니다. 단, 기본 자료형은 반드시 정수형이어야 합니다.
예를 들어, 네트워크로 데이터를 전송하는 등 데이터 크기에 민감한 상황에서 작업한다면 열거형에 더 작은 크기의 자료형을 지정하고 싶을 수 있습니다.
#include <cstdint> // std::int8_t 사용을 위해
#include <iostream>
// 8비트 정수를 열거형의 기본 자료형으로 사용합니다
enum Color : std::int8_t
{
black,
red,
blue,
};
int main()
{
Color c{ black };
std::cout << sizeof(c) << '\n'; // 1(바이트)을 출력합니다
return 0;
}
모범 사례
꼭 필요할 때만 열거형의 기본 자료형을 명시적으로 지정하세요.
주의
std::int8_t와std::uint8_t는 일반적으로 문자형(char)의 타입 별칭이기 때문에, 이들을 열거형의 기본 자료형으로 사용하면 열거자가 정수 값이 아닌 문자 값으로 출력될 가능성이 높습니다.
정수를 범위 없는 열거자로 변환하기
컴파일러는 범위 없는 열거형을 정수로 암시적 변환해 주지만, 정수를 범위 없는 열거형으로 암시적 변환해 주지는 않습니다.
따라서 다음 코드는 컴파일 에러를 발생시킵니다.
enum Pet // 기본 자료형 지정 안 됨
{
cat, // 0 할당됨
dog, // 1 할당됨
pig, // 2 할당됨
whale, // 3 할당됨
};
int main()
{
Pet pet { 2 }; // 컴파일 에러: 정수 값 2는 Pet으로 암시적 변환되지 않습니다
pet = 3; // 컴파일 에러: 정수 값 3은 Pet으로 암시적 변환되지 않습니다
return 0;
}
이 문제를 해결하는 방법은 두 가지가 있습니다.
첫 번째 방법은 static_cast 를 사용하여 정수를 범위 없는 열거자로 명시적 변환(explicit conversion) 하는 것입니다.
enum Pet // 기본 자료형 지정 안 됨
{
cat, // 0 할당됨
dog, // 1 할당됨
pig, // 2 할당됨
whale, // 3 할당됨
};
int main()
{
Pet pet { static_cast<Pet>(2) }; // 정수 2를 Pet으로 변환합니다
pet = static_cast<Pet>(3); // 우리의 돼지가 고래로 진화했습니다!
return 0;
}
대상 열거형의 열거자가 실제로 가지고 있는 정수 값을 static_cast 로 변환하는 것은 안전합니다.
우리의 Pet 열거형은 0, 1, 2, 3 값을 가진 열거자들을 가지고 있으므로, 정수 값 0, 1, 2, 3 을 Pet 으로 변환하는 것은 유효합니다.
또한, 비록 그 값에 해당하는 열거자가 목록에 없더라도 대상 열거형의 기본 자료형이 표현할 수 있는 범위 내의 정수 값 이라면 static_cast 하는 것은 안전합니다. 기본 자료형의 범위를 벗어나는 값을 변환하면 정의되지 않은 동작(Undefined behavior)이 발생합니다.
심화 학습
- 열거형에 명시적으로 정의된 기본 자료형이 있다면, 열거형의 범위는 그 기본 자료형의 범위와 동일합니다.
- 명시적인 기본 자료형이 없다면 상황이 조금 더 복잡해집니다. 이 경우 컴파일러가 기본 자료형을 선택하게 되는데, 모든 열거자의 값이 들어갈 수만 있다면 부호 있는(signed) 타입이나 부호 없는(unsigned) 타입 중 아무거나 선택할 수 있습니다. 따라서, 모든 열거자의 값을 담을 수 있는 가장 작은 비트 수의 범위 안에 들어가는 정수 값 만
static_cast하는 것이 안전합니다.이해를 돕기 위해 두 가지 예를 들어보겠습니다.
- 열거자들의 값이 2, 9, 12라면, 이 값들은 범위가 0부터 15인 부호 없는 4비트 정수형에 딱 맞게 들어갈 수 있습니다.
따라서 이 열거형으로는 0부터 15까지의 정수 값만static_cast하는 것이 안전합니다.- 열거자들의 값이 -28, 2, 6이라면, 이 값들은 범위가 -32부터 31인 부호 있는 6비트 정수형에 들어갈 수 있습니다.
따라서 이 열거형으로는 -32부터 31까지의 정수 값만static_cast하는 것이 안전합니다.
두 번째 방법은 C++17부터 적용되는 것으로, 범위 없는 열거형에 명시적으로 기본 자료형이 지정된 경우, 컴파일러는 정수 값을 이용한 리스트 초기화(list initialization) 를 허용합니다.
enum Pet: int // 기본 자료형을 지정했습니다
{
cat, // 0 할당됨
dog, // 1 할당됨
pig, // 2 할당됨
whale, // 3 할당됨
};
int main()
{
Pet pet1 { 2 }; // 정상: 기본 자료형이 지정된 범위 없는 열거형은 정수로 중괄호 초기화가 가능합니다 (C++17)
Pet pet2 (2); // 컴파일 에러: 정수로 직접 초기화할 수 없습니다
Pet pet3 = 2; // 컴파일 에러: 정수로 복사 초기화할 수 없습니다
pet1 = 3; // 컴파일 에러: 정수를 할당(대입)할 수 없습니다
return 0;
}
13.4 — 열거형을 문자열로, 문자열을 열거형으로 변환하기
이전 레슨(13.3 -- 범위 없는 열거자의 정수 변환)에서 다음과 같은 예제를 살펴보았습니다.
#include <iostream>
enum Color
{
black, // 0
red, // 1
blue, // 2
};
int main()
{
Color shirt{ blue };
std::cout << "Your shirt is " << shirt << '\n';
return 0;
}
이 코드를 실행하면 다음과 같이 출력됩니다:
Your shirt is 2
operator<< 는 Color 를 어떻게 출력해야 할지 모르기 때문에, 컴파일러는 Color 를 정수 값 으로 암시적 변환하여 대신 출력합니다.
대부분의 경우 열거형을 2와 같은 정수 값으로 출력하는 것은 우리가 원하는 결과가 아닙니다. 그보다는 열거자가 나타내는 진짜 이름(예: blue)을 출력하고 싶어 하죠. C++는 이를 위한 기본 기능을 제공하지 않기 때문에 우리가 직접 해결책을 찾아야 합니다. 다행히도 이 작업은 그리 어렵지 않습니다.
열거자의 이름 가져오기
열거자의 이름을 가져오는 가장 일반적인 방법은 열거자를 전달받아 그 이름을 문자열로 반환하는 함수를 만드는 것입니다.
하지만 이를 위해서는 특정 열거자가 들어왔을 때 어떤 문자열을 반환할지 결정하는 방법이 필요합니다.
여기에는 두 가지 일반적인 방법이 있습니다.
레슨 8.5(switch 문 기초) 에서, switch 문 은 정수 값이나 열거형 값 모두에 사용할 수 있다고 배웠습니다.
다음 예제에서는 switch 문 을 사용하여 열거자를 확인하고, 해당 열거자에 맞는 색상 문자열 리터럴을 반환해 보겠습니다.
#include <iostream>
#include <string_view>
enum Color
{
black,
red,
blue,
};
constexpr std::string_view getColorName(Color color)
{
switch (color)
{
case black: return "black";
case red: return "red";
case blue: return "blue";
default: return "???";
}
}
int main()
{
constexpr Color shirt{ blue };
std::cout << "Your shirt is " << getColorName(shirt) << '\n';
return 0;
}
이 코드의 출력 결과는 다음과 같습니다.
Your shirt is blue
위 예제에서는 우리가 전달한 열거자를 담고 있는 color 변수에 대해 switch 문 을 사용합니다.
switch 문 내부에는 Color 의 각 열거자에 대한 case 라벨이 있습니다.
각 case는 알맞은 색상의 이름을 C 스타일 문자열 리터럴 로 반환합니다.
이 문자열 리터럴은 std::string_view 로 암시적 변환되어 함수를 호출한 곳으로 반환됩니다.
또한, 사용자가 예상치 못한 값을 전달할 경우를 대비하여 "???" 를 반환하는 default case도 마련해 두었습니다.
기억해 두세요
C 스타일 문자열 리터럴 은 프로그램이 실행되는 내내 존재합니다. 따라서 이를 바라보고 있는(viewing) std::string_view 를 반환해도 안전합니다. std::string_view 가 복사되어 반환되더라도, 참조하고 있는 원본 문자열은 여전히 존재하기 때문입니다.
이 함수는 상수 표현식(constant expression) 에서 색상 이름을 사용할 수 있도록 constexpr 로 선언되었습니다.
관련 내용
constexpr 함수 에 대한 자세한 내용은 레슨 F.1 -- Constexpr 함수에서 다룹니다.
이 방법을 사용하면 열거자의 이름을 문자열로 가져올 수 있습니다. 하지만 콘솔에 출력할 때 std::cout << getColorName(shirt) 라고 작성하는 것은 std::cout << shirt 만큼 깔끔하지는 않죠. 다음 레슨인 13.5 -- 입출력 연산자 오버로딩 소개에서 std::cout 이 열거형을 직접 출력할 수 있도록 만드는 방법을 배울 것입니다.
열거자를 문자열로 연결(매핑)하는 두 번째 방법은 배열(array) 을 사용하는 것입니다. 이 내용은 레슨 17.6 -- std::array 와 열거형에서 다룹니다.
범위 없는 열거자 입력받기
이제 입력을 받는 경우를 살펴봅시다.
다음 예제에서는 Pet 이라는 열거형을 정의합니다.
Pet 은 프로그램에서 우리가 직접 만든 타입이기 때문에, C++는 std::cin 을 사용해 Pet 을 어떻게 입력받아야 할지 모릅니다.
#include <iostream>
enum Pet
{
cat, // 0
dog, // 1
pig, // 2
whale, // 3
};
int main()
{
Pet pet { pig };
std::cin >> pet; // 컴파일 에러: std::cin은 Pet을 입력받는 방법을 모릅니다
return 0;
}
이 문제를 우회하는 간단한 방법은 먼저 정수를 입력받은 다음, static_cast 를 사용하여 그 정수를 알맞은 열거형 타입으로 변환하는 것입니다.
#include <iostream>
#include <string_view>
enum Pet
{
cat, // 0
dog, // 1
pig, // 2
whale, // 3
};
constexpr std::string_view getPetName(Pet pet)
{
switch (pet)
{
case cat: return "cat";
case dog: return "dog";
case pig: return "pig";
case whale: return "whale";
default: return "???";
}
}
int main()
{
std::cout << "Enter a pet (0=cat, 1=dog, 2=pig, 3=whale): ";
int input{};
std::cin >> input; // 정수를 입력받습니다
if (input < 0 || input > 3)
std::cout << "You entered an invalid pet\n";
else
{
Pet pet{ static_cast<Pet>(input) }; // 정수를 Pet으로 static_cast 변환합니다
std::cout << "You entered: " << getPetName(pet) << '\n';
}
return 0;
}
이 방법이 잘 작동하긴 하지만 조금 어색합니다. 또한, input 값이 열거자의 유효한 범위 안에 있다는 것을 확실히 확인한 후에만 static_cast<Pet>(input) 을 사용해야 한다는 점을 잊지 마세요.
문자열에서 열거형 가져오기
숫자를 입력하는 대신, 사용자가 열거자를 나타내는 문자열(예: "pig")을 직접 입력하고 코드가 이를 알맞은 Pet 열거자로 변환해 준다면 훨씬 편할 것입니다. 하지만 이를 구현하려면 두 가지 문제를 해결해야 합니다.
첫째, 문자열에는 switch 문 을 사용할 수 없으므로 사용자가 입력한 문자열을 비교할 다른 방법이 필요합니다.
여기서 가장 간단한 접근법은 여러 개의 if 문 을 사용하는 것입니다.
둘째, 사용자가 잘못된 문자열을 입력했을 때 어떤 Pet 열거자를 반환해야 할까요? "없음/잘못됨"을 뜻하는 열거자를 하나 추가해서 반환하는 것도 방법이겠지만, 여기서는 std::optional 을 사용하는 것이 더 좋은 선택입니다.
관련 내용
std::optional 에 대해서는 레슨 12.15 -- std::optional 에서 다룹니다.
#include <iostream>
#include <optional> // std::optional을 사용하기 위함
#include <string>
#include <string_view>
enum Pet
{
cat, // 0
dog, // 1
pig, // 2
whale, // 3
};
constexpr std::string_view getPetName(Pet pet)
{
switch (pet)
{
case cat: return "cat";
case dog: return "dog";
case pig: return "pig";
case whale: return "whale";
default: return "???";
}
}
constexpr std::optional<Pet> getPetFromString(std::string_view sv)
{
// 문자열이 아닌 정수 값(또는 열거형)에만 switch 문을 사용할 수 있으므로
// 여기서는 if 문을 사용해야 합니다
if (sv == "cat") return cat;
if (sv == "dog") return dog;
if (sv == "pig") return pig;
if (sv == "whale") return whale;
return {};
}
int main()
{
std::cout << "Enter a pet: cat, dog, pig, or whale: ";
std::string s{};
std::cin >> s;
std::optional<Pet> pet { getPetFromString(s) };
if (!pet)
std::cout << "You entered an invalid pet\n";
else
std::cout << "You entered: " << getPetName(*pet) << '\n';
return 0;
}
위의 해결책에서는 문자열을 비교하기 위해 여러 개의 if-else 문을 사용했습니다.
사용자가 입력한 문자열이 열거자의 이름과 일치하면 해당하는 열거자를 반환합니다.
일치하는 문자열이 없으면 "값이 없음"을 뜻하는 {} 를 반환합니다.
심화 학습
참고로 위의 코드는 소문자만 인식합니다. 대소문자 구분 없이 입력받고 싶다면, 다음 함수를 사용하여 사용자의 입력을 모두 소문자로 변환할 수 있습니다:
#include <algorithm> // std::transform을 사용하기 위함
#include <cctype> // std::tolower를 사용하기 위함
#include <iterator> // std::back_inserter를 사용하기 위함
#include <string>
#include <string_view>
// 이 함수는 전달받은 std::string_view의 소문자 버전인 std::string을 반환합니다.
// 이 함수는 1:1 문자 매핑만 수행할 수 있습니다.
std::string toASCIILowerCase(std::string_view sv)
{
std::string lower{};
std::transform(sv.begin(), sv.end(), std::back_inserter(lower),
[](char c)
{
return static_cast<char>(std::tolower(static_cast<unsigned char>(c)));
});
return lower;
}
이 함수는 std::string_view sv 의 문자를 하나씩 확인하면서, 람다(lambda) 함수와 std::tolower() 를 사용하여 소문자로 변환한 다음, 그 소문자를 lower 문자열에 덧붙입니다.
람다(lambda) 에 대한 내용은 레슨 20.6 -- 람다(익명 함수) 소개에서 다룹니다.
출력과 마찬가지로, std::cin >> pet 처럼 바로 입력받을 수 있다면 가장 좋을 것입니다. 이 내용은 다음 레슨인 13.5 -- 입출력 연산자 오버로딩 소개에서 배울 예정입니다.
13.5 — 입출력(I/O) 연산자 오버로딩 소개
이전 레슨(13.4 - 열거형과 문자열 간의 변환)에서는 열거형을 문자열로 변환하는 함수를 사용하는 예제를 살펴보았습니다.
#include <iostream>
#include <string_view>
enum Color
{
black,
red,
blue,
};
constexpr std::string_view getColorName(Color color)
{
switch (color)
{
case black: return "black";
case red: return "red";
case blue: return "blue";
default: return "???";
}
}
int main()
{
constexpr Color shirt{ blue };
std::cout << "Your shirt is " << getColorName(shirt) << '\n';
return 0;
}
위 예제는 잘 작동하지만, 두 가지 단점이 있습니다.
- 열거자의 이름을 가져오기 위해 직접 만든 함수 이름을 일일이 기억해야 합니다.
- 출력할 때마다 함수를 호출해야 하므로 코드가 지저분해집니다.
가장 이상적인 방법은 operator<< 에게 열거형을 출력하는 방법을 알려주어, std::cout << shirt 처럼 코드를 작성했을 때 우리가 기대하는 대로 바로 출력되게 만드는 것입니다.
연산자 오버로딩(Operator overloading) 소개
레슨 11.1에서 함수 오버로딩에 대해 배웠습니다.
함수 오버로딩을 사용하면 매개변수가 다를 경우 같은 이름의 함수를 여러 개 만들 수 있습니다.
덕분에 데이터 타입마다 새로운 함수 이름을 고민할 필요가 없었죠.
마찬가지로 C++은 연산자 오버로딩 을 지원합니다.
이를 통해 기존 연산자(+, -, << 등)의 기능을 확장하여, 우리가 직접 만든 데이터 타입(클래스나 열거형 등)에서도 작동하도록 만들 수 있습니다.
기본적인 연산자 오버로딩 방법은 꽤 간단합니다.
- 오버로딩할 연산자의 이름을 함수 이름으로 사용하여 함수를 정의합니다 (예:
operator+). - 각 피연산자(왼쪽에서 오른쪽 순서)에 맞는 타입의 매개변수를 추가합니다. 이때 매개변수 중 최소 하나는 반드시 사용자 정의 타입(클래스나 열거형)이어야 합니다. 그렇지 않으면 컴파일 에러가 발생합니다.
- 논리적으로 알맞은 반환 타입(return type)을 설정합니다.
return문을 사용해 연산 결과를 반환합니다.
컴파일러는 수식에서 연산자를 만났을 때, 피연산자 중 하나라도 사용자 정의 타입이 있다면 이를 처리할 수 있는 오버로딩된 연산자 함수가 있는지 확인합니다. 예를 들어 x + y 라는 코드가 있다면, 컴파일러는 이 연산을 수행할 수 있는 operator+(x, y) 함수가 있는지 찾습니다. 모호하지 않고 명확한 operator+ 함수를 찾으면 이를 호출하고 그 결과를 반환합니다.
관련 내용: 연산자 오버로딩에 대한 더 자세한 내용은 21장에서 다룹니다.
심화 학습: 연산자는 가장 왼쪽 피연산자의 멤버 함수로도 오버로딩할 수 있습니다. 이는 레슨 21.5에서 다룹니다.
열거자를 출력하기 위한 operator<< 오버로딩
본격적으로 시작하기 전에, 출력할 때 operator<< 가 어떻게 작동하는지 짧게 복습해 보겠습니다.
std::cout << 5 같은 간단한 코드를 생각해 봅시다.
std::cout 은 std::ostream 타입(표준 라이브러리에서 제공하는 사용자 정의 타입)이고, 5 는 int 타입의 리터럴(숫자 값)입니다.
이 코드가 실행되면, 컴파일러는 std::ostream 과 int 타입을 인자로 받을 수 있는 오버로딩된 operator<< 함수를 찾아서 호출합니다 (이 함수도 표준 입출력 라이브러리에 정의되어 있습니다). 이 함수 내부에서는 콘솔 화면에 값(5)을 출력하는 작업이 이루어집니다. 마지막으로, operator<< 함수는 왼쪽 피연산자(여기서는 std::cout)를 다시 반환합니다. 덕분에 여러 번 연속해서 operator<< 를 사용할 수 있는 것(체이닝)입니다.
이 원리를 바탕으로 Color 열거형을 출력하는 operator<< 를 직접 구현해 봅시다.
#include <iostream>
#include <string_view>
enum Color
{
black,
red,
blue,
};
constexpr std::string_view getColorName(Color color)
{
switch (color)
{
case black: return "black";
case red: return "red";
case blue: return "blue";
default: return "???";
}
}
// operator<< 에게 Color 열거형을 출력하는 방법을 알려줍니다.
// std::ostream은 std::cout, std::cerr 등의 타입입니다.
// 복사본이 생성되는 것을 막기 위해 반환 타입과 매개변수 타입으로 참조(&)를 사용합니다.
std::ostream& operator<<(std::ostream& out, Color color)
{
out << getColorName(color); // 전달받은 출력 스트림(out)에 색상 이름을 출력합니다.
return out; // operator<< 는 관례적으로 왼쪽 피연산자를 반환합니다.
// 위 코드는 다음 한 줄로 줄일 수 있습니다:
// return out << getColorName(color);
}
int main()
{
Color shirt{ blue };
std::cout << "Your shirt is " << shirt << '\n'; // 잘 작동합니다!
return 0;
}
출력 결과는 다음과 같습니다:
Your shirt is blue
방금 만든 오버로딩 함수를 조금 더 자세히 살펴보겠습니다.
먼저, 우리가 오버로딩하려는 연산자가 << 이므로 함수 이름은 operator<< 가 됩니다.
이 함수는 두 개의 매개변수를 가집니다.
왼쪽 매개변수(왼쪽 피연산자와 연결됨)는 출력 스트림이며, 타입은 std::ostream 입니다.
함수를 호출할 때 std::ostream 객체의 복사본이 만들어지는 것을 원치 않지만, 출력을 위해 객체의 상태가 변경되어야 하므로 상수(const)가 아닌 일반 참조(reference) 로 전달합니다. 오른쪽 매개변수(오른쪽 피연산자와 연결됨)는 우리의 Color 객체입니다. operator<< 는 관례적으로 왼쪽 피연산자를 반환하므로, 반환 타입 역시 왼쪽 피연산자의 타입인 std::ostream& 가 됩니다.
이제 함수 내부를 봅시다. std::ostream 객체는 이미 std::string_view 를 출력하는 방법을 알고 있습니다(표준 라이브러리 덕분입니다). 따라서 out << getColorName(color) 코드는 색상 이름을 std::string_view 로 가져와서 그대로 출력 스트림에 밀어 넣기만 하면 됩니다.
여기서 std::cout 대신 out 매개변수를 사용했다는 점을 주목하세요. 이렇게 해야 함수를 호출하는 쪽에서 원하는 출력 스트림을 유연하게 결정할 수 있습니다(예를 들어 std::cerr << color 라고 작성하면 std::cout 이 아니라 std::cerr 로 출력됩니다).
왼쪽 피연산자를 반환하는 것도 쉽습니다. 매개변수 out 이 왼쪽 피연산자이므로, 단순히 out 을 반환하면 됩니다.
종합해 볼까요? 우리가 std::cout << shirt 를 호출하면, 컴파일러는 Color 타입에 맞게 오버로딩된 operator<< 함수를 찾습니다. 그런 다음 out 매개변수에는 std::cout 이, color 매개변수에는 shirt 변수(값은 blue)가 전달되어 함수가 실행됩니다. out 은 std::cout 의 참조이고 color 는 blue 의 복사본이므로, out << getColorName(color) 는 화면에 "blue" 를 출력합니다. 마지막으로, 추가적인 출력이 이어질 수 있도록 out 이 호출자에게 다시 반환됩니다.
열거자를 입력받기 위한 operator>> 오버로딩
위에서 operator<< 에게 열거형 출력 방법을 알려준 것과 비슷하게, operator>> 에게 열거형 입력 방법을 알려줄 수도 있습니다.
#include <iostream>
#include <limits>
#include <optional>
#include <string>
#include <string_view>
enum Pet
{
cat, // 0
dog, // 1
pig, // 2
whale, // 3
};
constexpr std::string_view getPetName(Pet pet)
{
switch (pet)
{
case cat: return "cat";
case dog: return "dog";
case pig: return "pig";
case whale: return "whale";
default: return "???";
}
}
constexpr std::optional<Pet> getPetFromString(std::string_view sv)
{
if (sv == "cat") return cat;
if (sv == "dog") return dog;
if (sv == "pig") return pig;
if (sv == "whale") return whale;
return {};
}
// pet은 입력 및 출력(in/out)을 모두 담당하는 매개변수입니다.
std::istream& operator>>(std::istream& in, Pet& pet)
{
std::string s{};
in >> s; // 사용자로부터 문자열을 입력받습니다.
std::optional<Pet> match { getPetFromString(s) };
if (match) // 일치하는 항목을 찾았다면
{
pet = *match; // std::optional을 역참조하여 일치하는 열거자를 가져옵니다.
return in;
}
// 일치하는 항목을 찾지 못했다면 입력이 잘못된 것입니다.
// 따라서 입력 스트림을 실패(fail) 상태로 설정합니다.
in.setstate(std::ios_base::failbit);
// 데이터 추출에 실패하면 operator>> 는 기본 타입들을 0으로 초기화합니다.
// 이 연산자도 똑같이 동작하게 하려면 아래 줄의 주석을 해제하세요.
// pet = {};
return in;
}
int main()
{
std::cout << "Enter a pet: cat, dog, pig, or whale: ";
Pet pet{};
std::cin >> pet;
if (std::cin) // 일치하는 항목을 찾았다면
std::cout << "You chose: " << getPetName(pet) << '\n';
else
{
std::cin.clear(); // 입력 스트림을 정상(good) 상태로 초기화합니다.
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
std::cout << "Your pet was not valid\n";
}
return 0;
}
출력할 때와 비교해서 눈여겨볼 만한 몇 가지 차이점이 있습니다.
첫째, std::cin 은 std::istream 타입이므로 왼쪽 매개변수와 반환 타입을 std::ostream& 대신 std::istream& 로 사용합니다.
둘째, pet 매개변수는 상수(const)가 아닌 일반 참조입니다. 이를 통해 추출(입력)에 성공했을 때 operator>> 함수가 전달받은 오른쪽 피연산자의 값을 직접 수정할 수 있게 됩니다.
핵심 포인트: 오른쪽 피연산자인
pet은 출력(out) 매개변수입니다. 출력 매개변수에 대해서는 레슨 12.13에서 다룹니다.
만약 pet 이 참조 매개변수가 아니라 값 매개변수(value parameter)였다면, operator>> 함수는 실제 오른쪽 피연산자가 아니라 넘겨받은 복사본에 새로운 값을 할당해버리고 말았을 것입니다. 우리는 실제 피연산자의 값이 업데이트되기를 원하므로 참조를 사용해야 합니다.
함수 내부에서는 이미 문자열 입력 방법을 알고 있는 operator>> 를 이용해 std::string 으로 우선 입력을 받습니다. 사용자가 입력한 값이 동물의 이름 중 하나와 일치하면, pet 에 해당 열거자를 할당하고 왼쪽 피연산자(in)를 반환합니다.
만약 사용자가 유효하지 않은 동물 이름을 입력했다면, std::cin 을 "실패 모드(failure mode)"로 설정하여 예외 상황을 처리합니다. 이는 입력 추출에 실패했을 때 std::cin 이 보통 취하는 상태입니다. 호출하는 쪽에서는 std::cin 의 상태를 확인하여 입력이 성공했는지 실패했는지 알아낼 수 있습니다.
관련 내용: 레슨 17.6(std::array와 열거형)에서는
std::array를 사용하여 입출력 연산자의 중복을 줄이고, 새로운 열거자가 추가될 때마다 연산자를 수정해야 하는 번거로움을 피하는 방법을 알아봅니다.
13.6 — 영역 지정 열거형 (enum class)
기존의 일반 열거형은 C++에서 고유한 자료형(타입)으로 취급되지만, 타입 검사가 엄격하지 않아 가끔 상식적으로 말이 안 되는 동작을 허용하기도 합니다. 다음 예시를 살펴봅시다.
#include <iostream>
int main()
{
enum Color
{
red,
blue,
};
enum Fruit
{
banana,
apple,
};
Color color { red };
Fruit fruit { banana };
if (color == fruit) // 컴파일러는 color와 fruit를 정수로 변환하여 비교합니다
std::cout << "color and fruit are equal\n"; // 그리고 둘이 같다고 판단합니다!
else
std::cout << "color and fruit are not equal\n";
return 0;
}
이 코드는 다음과 같이 출력됩니다:
color and fruit are equal
컴파일러가 color 와 fruit 를 비교할 때, 서로 다른 타입인 Color 와 Fruit 를 어떻게 비교해야 할지 모릅니다.
그래서 두 값을 모두 정수로 변환해 봅니다. 둘 다 정수로 바꾸면 숫자끼리의 비교가 가능해지기 때문입니다. 이 예시에서 color 와 fruit 는 모두 숫자 0 으로 변환되는 열거자(enumerator)를 가지고 있기 때문에, 컴파일러는 두 값이 같다고 판단해 버립니다.
하지만 color 와 fruit 는 서로 다른 열거형에 속해 있고 애초에 비교할 목적으로 만든 것이 아니기 때문에, 이는 의미상 맞지 않는 행동입니다. 안타깝게도 일반 열거형에서는 이런 문제를 쉽게 막을 방법이 없습니다.
이러한 문제와 더불어 네임스페이스 오염(일반 열거형을 전역에 정의하면 그 안의 값들이 전역 네임스페이스를 꽉 채워버리는 문제) 때문에, C++ 설계자들은 열거형을 더 깔끔하게 사용할 수 있는 새로운 해결책이 필요하다고 판단했습니다.
영역 지정 열거형 (Scoped enumerations)
그 해결책이 바로 영역 지정 열거형(Scoped enumeration) 입니다.
(왜 이런 이름이 붙었는지는 곧 알게 되시겠지만, C++에서는 보통 enum class 라고 부릅니다.)
영역 지정 열거형은 일반 열거형과 비슷하게 작동하지만 두 가지 큰 차이점이 있습니다. 첫째, 정수로 자동(암시적) 변환되지 않습니다. 둘째, 열거형 값들이 열거형이 정의된 주변 영역이 아니라 해당 열거형 내부 영역(scope)에만 속하게 됩니다.
영역 지정 열거형을 만들려면 enum class 라는 키워드를 사용합니다. 나머지 작성법은 일반 열거형과 똑같습니다. 다음 예시를 확인해 보세요.
#include <iostream>
int main()
{
enum class Color // "enum class"는 이것을 일반 열거형이 아닌 영역 지정 열거형으로 정의합니다
{
red, // red는 Color의 영역 안에 속하는 것으로 간주됩니다
blue,
};
enum class Fruit
{
banana, // banana는 Fruit의 영역 안에 속하는 것으로 간주됩니다
apple,
};
Color color { Color::red }; // 참고: red에 직접 접근할 수 없으며, Color::red를 사용해야 합니다
Fruit fruit { Fruit::banana }; // 참고: banana에 직접 접근할 수 없으며, Fruit::banana를 사용해야 합니다
if (color == fruit) // 컴파일 에러: 컴파일러는 서로 다른 타입인 Color와 Fruit를 비교하는 방법을 모릅니다
std::cout << "color and fruit are equal\n";
else
std::cout << "color and fruit are not equal\n";
return 0;
}
영역 지정 열거형은 다른 타입과 비교할 수 있도록 자동으로 형태가 변환되지 않기 때문에, 위 프로그램은 19번째 줄에서 컴파일 에러를 발생시킵니다.
참고 사항
C++에서class키워드(그리고static키워드)는 문맥에 따라 여러 가지 의미를 가질 수 있는, 가장 많이 재사용되는 키워드 중 하나입니다. 영역 지정 열거형이class키워드를 사용하긴 하지만, 구조체나 클래스처럼 진짜 "클래스 타입"으로 취급되지는 않습니다.
이 문맥에서는enum struct를 사용해도enum class와 완전히 똑같이 작동합니다. 하지만enum struct는 관례적으로 잘 쓰이지 않는 표현이므로 사용을 피하는 것이 좋습니다.
영역 지정 열거형은 자신만의 독립적인 영역을 가집니다
일반 열거형은 자신의 값들을 열거형이 정의된 곳과 같은 영역에 둡니다.
반면 영역 지정 열거형은 자신의 값들을 해당 열거형 내부 영역에만 둡니다.
즉, 영역 지정 열거형은 자신의 값들을 담아두는 '네임스페이스(namespace)' 역할을 합니다.
이렇게 내장된 네임스페이스 기능 덕분에 이름이 겹쳐서 충돌하는 일을 막아주고, 전역 공간이 지저분해지는 것을 방지할 수 있습니다.
영역 지정 열거형의 값에 접근할 때는, 마치 열거형 이름과 똑같은 네임스페이스 안에 있는 값에 접근하는 것처럼 작성하면 됩니다.
#include <iostream>
int main()
{
enum class Color // "enum class"는 이것을 일반 열거형이 아닌 영역 지정 열거형으로 정의합니다
{
red, // red는 Color의 영역 안에 속하는 것으로 간주됩니다
blue,
};
std::cout << red << '\n'; // 컴파일 에러: 이 영역에는 red가 정의되어 있지 않습니다
std::cout << Color::red << '\n'; // 컴파일 에러: std::cout은 이것을 출력하는 방법을 모릅니다 (정수로 자동 변환되지 않음)
Color color { Color::blue }; // 정상 작동
return 0;
}
영역 지정 열거형 자체가 이미 이름 공간을 분리해 주는 역할을 하므로, 특별한 이유가 없다면 굳이 또 다른 네임스페이스 안에 넣을 필요가 없습니다. 불필요한 중복일 뿐입니다.
영역 지정 열거형은 정수로 자동(암시적) 변환되지 않습니다
일반 열거형과 달리, 영역 지정 열거형의 값들은 정수로 몰래 자동으로 바뀌지 않습니다. 열거형을 숫자로 바꿀 일이 별로 없고, 다른 열거형끼리 실수로 비교하거나 red + 5 같은 이상한 연산을 원천 차단해 주기 때문에 대부분의 경우 이는 아주 좋은 기능입니다.
물론, 아래처럼 같은 영역 지정 열거형 안에 있는 값들끼리는 (타입이 같으므로) 정상적으로 비교할 수 있습니다.
#include <iostream>
int main()
{
enum class Color
{
red,
blue,
};
Color shirt { Color::red };
if (shirt == Color::red) // 이처럼 같은 Color 타입끼리의 비교는 괜찮습니다
std::cout << "The shirt is red!\n";
else if (shirt == Color::blue)
std::cout << "The shirt is blue!\n";
return 0;
}
가끔은 영역 지정 열거형의 값을 정수처럼 사용해야 할 때도 있습니다. 이럴 때는 static_cast 를 사용하여 정수로 명시적 변환(강제 변환)을 할 수 있습니다. C++23부터는 <utility> 헤더에 있는 std::to_underlying() 함수를 사용하는 것이 더 좋습니다. 이 함수는 열거형 값을 그 열거형의 바탕이 되는 실제 타입(보통 정수형)으로 안전하게 변환해 줍니다.
#include <iostream>
#include <utility> // std::to_underlying() 사용을 위해 추가 (C++23)
int main()
{
enum class Color
{
red,
blue,
};
Color color { Color::blue };
std::cout << color << '\n'; // 정수로 자동 변환되지 않기 때문에 작동하지 않습니다
std::cout << static_cast<int>(color) << '\n'; // int로 명시적 변환, 1을 출력합니다
std::cout << std::to_underlying(color) << '\n'; // 바탕 타입(underlying type)으로 변환, 1을 출력합니다 (C++23)
return 0;
}
반대로 정수를 영역 지정 열거형으로 static_cast 할 수도 있습니다. 이는 사용자로부터 입력을 받을 때 무척 유용합니다.
#include <iostream>
int main()
{
enum class Pet
{
cat, // 0이 할당됨
dog, // 1이 할당됨
pig, // 2가 할당됨
whale, // 3이 할당됨
};
std::cout << "Enter a pet (0=cat, 1=dog, 2=pig, 3=whale): ";
int input{};
std::cin >> input; // 정수를 입력받음
Pet pet{ static_cast<Pet>(input) }; // 정수를 Pet 타입으로 강제 변환(static_cast)
return 0;
}
C++17부터는 static_cast 가 없어도 정수값을 사용하여 영역 지정 열거형을 중괄호 초기화(list initialize) 할 수 있습니다. (일반 열거형과 달리 바탕 타입을 명시하지 않아도 됩니다.)
// 이전 예제의 enum class Pet을 사용
Pet pet { 1 }; // 정상 작동
모범 사례
어쩔 수 없는 특별한 이유가 없다면 일반 열거형보다 영역 지정 열거형(enum class) 을 사용하는 것이 좋습니다.
영역 지정 열거형이 주는 많은 장점에도 불구하고, 실무에서는 일반 열거형 역시 여전히 많이 쓰입니다. 정수로 자동 변환되는 것이 꼭 필요하거나(매번static_cast를 쓰기 번거로울 때), 굳이 네임스페이스 영역을 분리할 필요가 없는 상황들이 있기 때문입니다.
영역 지정 열거형을 정수로 더 쉽게 변환하기 (고급)
영역 지정 열거형은 훌륭한 기능이지만, 정수로 자동 변환되지 않는다는 점이 가끔 귀찮게 느껴질 수 있습니다. 예를 들어 열거형 값을 배열의 인덱스로 쓰려고 할 때처럼 정수 변환이 자주 필요한 경우, 매번 static_cast 를 적어주는 것은 코드를 꽤 지저분하게 만듭니다.
만약 변환 과정을 더 편하게 만들고 싶다면, 단항 연산자 + (unary operator+)를 오버로딩하여 이 변환을 수행하게 만드는 유용한 꼼수(hack)가 있습니다.
#include <iostream>
#include <type_traits> // std::underlying_type_t 사용을 위해 추가
enum class Animals
{
chicken, // 0
dog, // 1
cat, // 2
elephant, // 3
duck, // 4
snake, // 5
maxAnimals,
};
// 단항 + 연산자를 오버로딩하여 열거형을 바탕 타입으로 변환
// https://stackoverflow.com/a/42198760 에서 발췌, 아이디어를 제공한 Pixelchemist에게 감사
// C++23에서는 <utility>를 인클루드하고 대신 std::to_underlying(a)를 반환할 수 있습니다
template <typename T>
constexpr auto operator+(T a) noexcept
{
return static_cast<std::underlying_type_t<T>>(a);
}
int main()
{
std::cout << +Animals::elephant << '\n'; // 단항 연산자 + 를 사용하여 Animals::elephant를 정수로 변환
return 0;
}
이 코드는 다음을 출력합니다:
3
이 방법은 실수로 정수로 자동 변환되는 것은 든든하게 막아주면서도, 필요할 때만 + 기호를 써서 명시적이고 편리하게 변환할 수 있도록 해줍니다.
using enum 문 (C++20)
C++20에 도입된 using enum 문은 열거형 안에 있는 모든 값들을 현재 영역(scope)으로 바로 불러옵니다.
enum class 와 함께 사용하면, 매번 앞에 열거형 이름을 접두사처럼 붙이지 않고도 값에 곧바로 접근할 수 있게 해 줍니다.
이 기능은 switch 문 안에서처럼 똑같은 접두사를 반복해서 계속 써야 하는 경우에 매우 유용합니다.
#include <iostream>
#include <string_view>
enum class Color
{
black,
red,
blue,
};
constexpr std::string_view getColor(Color color)
{
using enum Color; // 모든 Color 열거형 값을 현재 영역으로 가져옵니다 (C++20)
// 이제 Color:: 접두사 없이 Color의 열거형 값에 접근할 수 있습니다
switch (color)
{
case black: return "black"; // 참고: Color::black 대신 black만 사용
case red: return "red";
case blue: return "blue";
default: return "???";
}
}
int main()
{
Color shirt{ Color::blue };
std::cout << "Your shirt is " << getColor(shirt) << '\n';
return 0;
}
위 예제에서 Color 는 enum class 이기 때문에, 보통은 Color::blue 처럼 전체 이름을 모두 적어주어야 합니다. 하지만 getColor() 함수 안에서 using enum Color; 라는 문장을 적어주었기 때문에, 이제 Color:: 라는 접두사 없이 값들에 접근할 수 있게 되었습니다.
덕분에 switch 문 안에서 길고 뻔한 접두사를 여러 번 반복해서 써야 하는 수고를 크게 덜 수 있습니다.
13.7 — 구조체, 멤버, 그리고 멤버 선택 소개
프로그래밍을 하다 보면 어떤 대상을 표현하기 위해 여러 개의 변수가 필요한 경우가 많습니다.
이전 장(12.1 -- 복합 데이터 타입 소개)에서 이야기했듯이, 분수는 분자와 분모가 하나로 연결되어 하나의 수학적 객체를 이룹니다.
또 다른 예로, 회사 직원의 정보를 저장하는 프로그램을 만든다고 가정해 봅시다.
직원의 이름, 직함, 나이, 사원 번호, 매니저 번호, 급여, 생일, 입사일 같은 다양한 정보들을 관리해야 할 것입니다.
만약 이 모든 정보를 독립적인 개별 변수로 관리한다면, 다음과 같은 형태가 될 것입니다.
std::string name;
std::string title;
int age;
int id;
int managerId;
double wage;
int birthdayYear;
int birthdayMonth;
int birthdayDay;
int hireYear;
int hireMonth;
int hireDay;
하지만 이렇게 개별 변수를 사용하는 방식에는 몇 가지 문제가 있습니다.
첫째, 이 변수들이 서로 관련되어 있는지 한눈에 알기 어렵습니다(주석을 읽거나 코드 문맥을 파악해야만 알 수 있죠).
둘째, 당장 관리해야 할 변수가 12개나 됩니다. 만약 이 직원 정보를 함수에 전달하려면 12개의 인수를 순서에 맞게 넘겨줘야 하는데, 이렇게 되면 함수 원형과 호출 코드가 아주 지저분해집니다. 게다가 함수는 오직 하나의 값만 반환할 수 있는데, 어떻게 직원 정보 전체를 반환할 수 있을까요?
만약 직원이 한 명이 아니라면 어떨까요? 직원이 한 명 추가될 때마다 12개의 변수를 새로 만들고, 각각 고유한 이름을 붙여줘야 합니다! 이는 전혀 효율적이지 않습니다. 우리에게 정말 필요한 것은 이렇게 서로 관련된 데이터들을 모아서 한 번에 쉽게 관리할 수 있는 방법입니다.
다행히도 C++에는 이런 문제를 해결하기 위해 고안된 두 가지 복합 데이터 타입이 있습니다. 바로 지금부터 알아볼 구조체(struct) 와 곧 배우게 될 클래스(class) 입니다. 구조체(structure의 줄임말) 는 프로그래머가 직접 정의하는 데이터 타입(13.1 -- 프로그램 정의(사용자 정의) 타입 소개)으로, 여러 개의 변수를 하나의 타입으로 묶을 수 있게 해줍니다. 곧 보시겠지만, 이를 통해 관련된 변수 묶음을 훨씬 쉽게 관리할 수 있습니다!
참고 사항
구조체는 클래스 타입의 일종입니다(클래스와 공용체도 마찬가지입니다).
따라서 클래스 타입에 적용되는 모든 규칙은 구조체에도 동일하게 적용됩니다.
구조체 정의하기
구조체는 프로그래머가 정의하는 타입이므로, 사용하기 전에 먼저 컴파일러에게 이 구조체가 어떻게 생겼는지 알려주어야 합니다.
다음은 간단한 직원 정보를 담는 구조체를 정의한 예시입니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
struct 키워드는 컴파일러에게 우리가 구조체를 정의하고 있다는 것을 알려줍니다.
여기서는 구조체의 이름을 Employee라고 지었습니다(프로그램에서 정의하는 타입은 보통 대문자로 시작하는 이름을 사용합니다).
그런 다음 중괄호 {} 안에 각 Employee 객체가 가질 변수들을 정의합니다. 이 예시에서 우리가 만들 각 Employee는 int id, int age, double wage라는 3개의 변수를 가집니다. 이렇게 구조체의 일부로 포함된 변수들을 데이터 멤버(data members) 또는 멤버 변수(member variables) 라고 부릅니다.
팁
일상생활에서 멤버(회원)는 어떤 그룹에 속한 개인을 뜻합니다.
예를 들어, 여러분은 농구팀의 멤버일 수 있고, 동생은 합창단의 멤버일 수 있죠.C++에서 멤버(member) 란 구조체(또는 클래스)에 속하는 변수, 함수, 또는 타입을 의미합니다.
모든 멤버는 반드시 구조체(또는 클래스) 정의 안에 선언되어야 합니다.
앞으로의 강의에서 멤버 라는 단어를 아주 많이 사용할 테니, 그 의미를 꼭 기억해 두세요.
일반 변수를 값 초기화할 때 빈 중괄호를 사용하는 것처럼, 각 멤버 변수 뒤에 있는 빈 중괄호는 Employee 객체가 생성될 때 내부의 멤버 변수들이 기본값으로 초기화되도록 보장해 줍니다. 이에 대해서는 몇 단원 뒤에 나오는 기본 멤버 초기화(13.9 -- 기본 멤버 초기화)에서 더 자세히 다루겠습니다.
마지막으로, 타입 정의의 끝은 항상 세미콜론(;)으로 맺어야 합니다.
다시 한 번 말씀드리지만, Employee는 단지 타입을 정의한 것일 뿐, 아직 실제로 어떤 객체가 생성된 것은 아닙니다.
구조체 객체 정의하기
Employee 타입을 사용하려면, 간단히 Employee 타입의 변수를 정의하면 됩니다.
Employee joe {}; // Employee는 타입이고, joe는 변수 이름입니다.
위 코드는 이름이 joe인 Employee 타입의 변수를 정의합니다. 코드가 실행되면 3개의 데이터 멤버를 포함하는 Employee 객체가 생성(인스턴스화)됩니다. 빈 중괄호는 객체가 값으로 초기화되도록 보장합니다.
다른 타입들과 마찬가지로, 같은 구조체 타입의 변수를 여러 개 정의하는 것도 가능합니다.
Employee joe {}; // Joe를 위한 Employee 구조체 생성
Employee frank {}; // Frank를 위한 Employee 구조체 생성
멤버 접근하기
다음 예시를 살펴보겠습니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe {};
return 0;
}
위 예시에서 joe라는 이름은 전체 구조체 객체(멤버 변수들을 포함하는)를 가리킵니다. 특정 멤버 변수에 접근하려면, 구조체 변수 이름과 멤버 이름 사이에 멤버 선택 연산자(.) 를 사용합니다. 예를 들어 Joe의 나이 멤버에 접근하려면 joe.age라고 작성하면 됩니다.
구조체의 멤버 변수는 일반 변수와 똑같이 작동합니다. 따라서 대입, 산술 연산, 비교 연산 등 일반적인 작업들을 모두 수행할 수 있습니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe {};
joe.age = 32; // 멤버 선택 연산자(.)를 사용하여 변수 joe의 age 멤버를 선택합니다.
std::cout << joe.age << '\n'; // joe의 나이를 출력합니다.
return 0;
}
위 코드는 다음을 출력합니다:
32
구조체의 가장 큰 장점 중 하나는 구조체 변수당 오직 하나의 새로운 이름만 만들면 된다는 것입니다(멤버 변수의 이름들은 구조체 타입 정의의 일부로 이미 고정되어 있습니다). 다음 예시에서는 joe와 frank라는 두 개의 Employee 객체를 생성해 보겠습니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe {};
joe.id = 14;
joe.age = 32;
joe.wage = 60000.0;
Employee frank {};
frank.id = 15;
frank.age = 28;
frank.wage = 45000.0;
int totalAge { joe.age + frank.age };
std::cout << "Joe and Frank have lived " << totalAge << " total years\n";
if (joe.wage > frank.wage)
std::cout << "Joe makes more than Frank\n";
else if (joe.wage < frank.wage)
std::cout << "Joe makes less than Frank\n";
else
std::cout << "Joe and Frank make the same amount\n";
// Frank가 승진을 했습니다.
frank.wage += 5000.0;
// 오늘은 Joe의 생일입니다.
++joe.age; // 전위 증감 연산자를 사용하여 Joe의 나이를 1 증가시킵니다.
return 0;
}
위 예시를 보면 어떤 멤버 변수가 Joe의 것이고 어떤 것이 Frank의 것인지 아주 쉽게 구분할 수 있습니다. 이는 개별 변수들을 사용할 때보다 훨씬 더 높은 수준의 체계성을 제공합니다. 게다가 Joe와 Frank의 멤버들이 같은 이름을 공유하기 때문에, 동일한 구조체 타입의 변수가 여러 개 있을 때 일관성을 유지할 수 있습니다.
다음 단원에서는 구조체를 어떻게 초기화하는지 등 구조체에 대해 계속해서 더 깊이 알아보겠습니다.
13.8 — 구조체 집합체 초기화 (Struct aggregate initialization)
이전 레슨(13.7 -- 구조체, 멤버, 멤버 선택 소개)에서는 구조체를 정의하고, 구조체 객체를 생성하며, 멤버에 접근하는 방법에 대해 이야기했습니다. 이번 레슨에서는 구조체를 어떻게 초기화하는지 알아보겠습니다.
데이터 멤버는 기본적으로 초기화되지 않습니다
일반 변수와 마찬가지로, 데이터 멤버는 기본적으로 초기화되지 않습니다. 다음 구조체를 살펴보세요.
#include <iostream>
struct Employee
{
int id; // 참고: 여기에 초기화 구문이 없습니다.
int age;
double wage;
};
int main()
{
Employee joe; // 참고: 여기에도 초기화 구문이 없습니다.
std::cout << joe.id << '\n';
return 0;
}
초기값을 전혀 제공하지 않았기 때문에, joe 가 생성될 때 joe.id, joe.age, joe.wage 는 모두 초기화되지 않은 상태로 남습니다. 따라서 joe.id 의 값을 출력하려고 시도하면 예측할 수 없는 결과(정의되지 않은 동작)가 발생합니다.
하지만 구조체를 초기화하는 방법을 본격적으로 알아보기 전에, 잠시 다른 이야기를 먼저 해보겠습니다.
집합체(Aggregate)란 무엇일까요?
일반적인 프로그래밍에서 집합체 데이터 타입(Aggregate data type) (또는 간단히 집합체(Aggregate) ) 이란 여러 개의 데이터 멤버를 포함할 수 있는 모든 타입을 뜻합니다. 어떤 집합체는 멤버들이 서로 다른 타입(예: 구조체)을 가질 수 있고, 어떤 집합체는 모든 멤버가 반드시 동일한 타입(예: 배열)이어야 합니다.
C++에서 집합체의 정의는 이보다 좀 더 좁고 상당히 복잡한 편입니다.
저자의 참고 사항
이 튜토리얼 시리즈에서 "집합체" (또는 "비집합체") 라는 용어를 사용할 때는 C++에서의 집합체 정의를 의미합니다.
고급 독자를 위한 참고 사항
간단히 말해서, C++의 집합체는 C스타일 배열(17.7 -- C스타일 배열 소개)이거나, 다음 조건을 만족하는 클래스 타입(구조체, 클래스, 공용체)입니다.
- 사용자가 선언한 생성자가 없음 (14.9 -- 생성자 소개)
- private 또는 protected인 비정적(non-static) 데이터 멤버가 없음 (14.5 -- Public 및 private 멤버와 접근 지정자)
- 가상(virtual) 함수가 없음 (25.2 -- 가상 함수와 다형성)
널리 쓰이는
std::array(17.1 -- std::array 소개) 타입 역시 집합체입니다. C++ 집합체의 정확한 정의는 여기서 확인하실 수 있습니다.
지금 단계에서 이해해야 할 핵심은 데이터 멤버만 있는 구조체는 집합체 라는 사실입니다.
구조체의 집합체 초기화
일반 변수는 단일 값만 가질 수 있으므로 초기값도 하나만 제공하면 됩니다.
int x { 5 };
하지만 구조체는 여러 멤버를 가질 수 있습니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
구조체 타입으로 객체를 정의할 때는, 초기화 시점에 여러 멤버를 동시에 초기화할 방법이 필요합니다.
Employee joe; // joe.id, joe.age, joe.wage를 어떻게 초기화할까요?
집합체는 집합체 초기화(Aggregate initialization) 라는 방식을 사용하여 멤버들을 직접 초기화할 수 있습니다.
이를 위해 중괄호 안에 쉼표로 값을 나열한 초기화 리스트(Initializer list) 를 제공하면 됩니다.
집합체 초기화에는 주로 두 가지 형태가 있습니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee frank = { 1, 32, 60000.0 }; // 중괄호 리스트를 사용한 복사 리스트 초기화
Employee joe { 2, 28, 45000.0 }; // 중괄호 리스트를 사용한 리스트 초기화 (권장 방식)
return 0;
}
이러한 초기화 방식은 각각 멤버별 초기화(Memberwise initialization) 를 수행합니다.
즉, 구조체에 선언된 순서대로 각 멤버가 초기화된다는 뜻입니다. 따라서 Employee joe { 2, 28, 45000.0 }; 코드는 먼저 joe.id 를 2로, 그 다음 joe.age 를 28로, 마지막으로 joe.wage 를 45000.0으로 초기화합니다.
모범 사례 (Best practice)
집합체를 초기화할 때는 (복사가 아닌) 중괄호 리스트 형태를 사용하는 것을 권장합니다.
C++20부터는 괄호로 묶인 값 목록을 사용하여 (일부) 집합체를 초기화할 수도 있습니다.
Employee robert ( 3, 45, 62500.0 ); // 괄호 리스트를 사용한 직접 초기화 (C++20)
이 마지막 방식은 가급적 피하는 것이 좋습니다.
중괄호 생략(brace elision)을 활용하는 집합체(특히 std::array)에서는 현재 이 문법이 제대로 작동하지 않기 때문입니다.
초기화 리스트에서 초기값이 누락된 경우
집합체를 초기화할 때 입력한 값의 개수가 멤버 수보다 적다면, 명시적인 초기값이 없는 멤버들은 다음과 같이 초기화됩니다.
- 멤버에 기본 초기값이 정의되어 있다면, 그 값을 사용합니다.
- 그렇지 않다면, 해당 멤버는 빈 초기화 리스트로부터 복사 초기화됩니다.
대부분의 경우, 이 과정에서 해당 멤버들은 값 초기화 가 됩니다
(클래스 타입의 경우, 리스트 생성자가 있더라도 기본 생성자가 호출됩니다).
struct Employee
{
int id {};
int age {};
double wage { 76000.0 };
double whatever;
};
int main()
{
Employee joe { 2, 28 }; // joe.whatever는 0.0으로 값 초기화가 됩니다.
return 0;
}
위 예제에서 joe.id 는 2로, joe.age 는 28로 초기화됩니다. joe.wage 는 명시적인 초기값이 주어지지 않았지만 구조체 내부에 기본 초기값이 지정되어 있으므로 76000.0으로 초기화됩니다. 마지막으로 joe.whatever 역시 명시적인 초기값이 주어지지 않았으므로 0.0으로 값 초기화가 됩니다.
팁 (Tip)
이는 곧 빈 초기화 리스트를 사용하면 구조체의 모든 멤버를 한 번에 값 초기화할 수 있다는 뜻입니다.
Employee joe {}; // 모든 멤버를 값 초기화합니다.
구조체를 출력하기 위한 operator<< 오버로딩
이전 13.5 레슨(I/O 연산자 오버로딩 소개)에서는 열거형(enum)을 출력하기 위해 operator<< 를 오버로딩하는 방법을 보여드렸습니다.
구조체를 위해 operator<< 를 오버로딩하는 것 역시 매우 유용합니다.
이전 섹션과 동일한 예제에 오버로딩된 operator<< 를 추가해 보았습니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
std::ostream& operator<<(std::ostream& out, const Employee& e)
{
out << e.id << ' ' << e.age << ' ' << e.wage;
return out;
}
int main()
{
Employee joe { 2, 28 }; // joe.wage는 0.0으로 값 초기화가 됩니다.
std::cout << joe << '\n';
return 0;
}
출력 결과는 다음과 같습니다.
2 28 0
joe.wage 가 실제로 0.0으로 값 초기화된 것을 확인할 수 있습니다 (출력은 0으로 나옵니다).
열거형과 달리 구조체는 여러 값을 담을 수 있습니다. 출력 형식(예: 값을 구분하는 방법)은 전적으로 여러분의 자유입니다.
위에서 우리가 작성한 operator<< 가 출력하는 세 개의 값은 직관적이지 않습니다. 이 값들이 무엇을 의미하는지 전혀 알 수 없기 때문입니다. 동일한 예제에서 출력 함수가 좀 더 친절하게 설명해 주도록 업데이트해 보겠습니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
std::ostream& operator<<(std::ostream& out, const Employee& e)
{
out << "id: " << e.id << " age: " << e.age << " wage: " << e.wage;
return out;
}
int main()
{
Employee joe { 2, 28 }; // joe.wage는 0.0으로 값 초기화가 됩니다.
std::cout << joe << '\n';
return 0;
}
이제 출력 결과는 다음과 같습니다:
id: 2 age: 28 wage: 0
훨씬 이해하기 쉬워졌습니다.
Const 구조체
구조체 타입의 변수도 const (또는 constexpr)가 될 수 있으며, 다른 모든 const 변수와 마찬가지로 반드시 초기화되어야 합니다.
struct Rectangle
{
double length {};
double width {};
};
int main()
{
const Rectangle unit { 1.0, 1.0 };
const Rectangle zero { }; // 모든 멤버를 값 초기화합니다.
return 0;
}
지정 초기자 (Designated initializers) (C++20)
값 리스트를 통해 구조체를 초기화할 때, 초기값들은 선언된 순서대로 멤버에 차례차례 적용됩니다.
struct Foo
{
int a {};
int c {};
};
int main()
{
Foo f { 1, 3 }; // f.a = 1, f.c = 3
return 0;
}
만약 이 구조체 정의를 업데이트해서 마지막이 아닌 중간 위치에 새로운 멤버를 추가한다면 어떤 일이 벌어질지 생각해 보세요.
struct Foo
{
int a {};
int b {}; // 방금 추가됨
int c {};
};
int main()
{
Foo f { 1, 3 }; // 이제 f.a = 1, f.b = 3, f.c = 0이 됩니다.
return 0;
}
이제 모든 초기값이 뒤로 밀려버렸습니다.
더 큰 문제는 문법 자체는 여전히 유효하기 때문에 컴파일러가 이를 에러로 감지하지 못할 수도 있다는 점입니다.
이런 문제를 피하기 위해 C++20에서는 구조체 멤버를 초기화하는 새로운 방법인 지정 초기자(Designated initializers) 를 추가했습니다.
지정 초기자를 사용하면 어떤 초기값이 어떤 멤버와 연결되는지 명확하게 지정할 수 있습니다.
각 멤버는 리스트 또는 복사 초기화를 사용하여 초기화할 수 있으며, 구조체에 선언된 순서와 동일한 순서로 초기화해야 합니다.
그렇지 않으면 경고나 에러가 발생합니다. 명시적으로 지정되지 않은 멤버는 값 초기화가 됩니다.
struct Foo
{
int a{ };
int b{ };
int c{ };
};
int main()
{
Foo f1{ .a{ 1 }, .c{ 3 } }; // 정상: f1.a = 1, f1.b = 0 (값 초기화됨), f1.c = 3
Foo f2{ .a = 1, .c = 3 }; // 정상: f2.a = 1, f2.b = 0 (값 초기화됨), f2.c = 3
Foo f3{ .b{ 2 }, .a{ 1 } }; // 에러: 초기화 순서가 구조체에 선언된 순서와 일치하지 않습니다.
return 0;
}
Clang 사용자를 위한 참고 사항
중괄호를 사용하여 단일 값의 지정 초기자를 작성할 때, Clang 컴파일러가 "스칼라 초기화 주변에 중괄호가 있습니다(braces around scalar initializer)"라는 경고를 부적절하게 표시하는 경우가 있습니다. 곧 수정되기를 바랍니다.
지정 초기자는 코드만 보고도 어떤 값이 들어가는지 쉽게 알 수 있게 해주고(자체 문서화), 초기값의 순서를 실수로 섞는 것을 방지해주기 때문에 아주 유용합니다. 하지만 초기화 리스트를 눈에 띄게 길고 복잡하게 만들기도 하므로, 현 시점에서는 이를 1순위 모범 사례로 권장하지는 않습니다.
또한, 집합체를 초기화할 때마다 지정 초기자를 항상 사용하도록 강제하는 규칙이 없기 때문에, 초기값이 밀리는 위험을 막으려면 기존 집합체 정의의 중간에 새로운 멤버를 추가하는 것은 피하는 것이 좋습니다.
모범 사례 (Best practice)
집합체에 새 멤버를 추가할 때는 다른 멤버의 초기값이 밀리지 않도록 정의 목록의 맨 아래에 추가하는 것이 가장 안전합니다.
초기화 리스트를 사용한 할당 (Assignment)
이전 레슨에서 보여드린 것처럼, 구조체의 각 멤버에 개별적으로 값을 할당할 수 있습니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe { 1, 32, 60000.0 };
joe.age = 33; // Joe의 생일이 지났습니다.
joe.wage = 66000.0; // 그리고 급여가 올랐습니다.
return 0;
}
하나의 멤버만 변경할 때는 괜찮지만, 여러 멤버를 동시에 업데이트하고 싶을 때는 좋은 방법이 아닙니다. 초기화 리스트로 구조체를 초기화하는 것과 비슷하게, 초기화 리스트를 사용하여 구조체에 한 번에 값을 할당할 수도 있습니다 (이 역시 멤버별 할당을 수행합니다).
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe { 1, 32, 60000.0 };
joe = { joe.id, 33, 66000.0 }; // Joe의 생일이 지났고 급여가 올랐습니다.
return 0;
}
여기서 joe.id 의 값은 변경하고 싶지 않았기 때문에, 멤버별 할당 과정에서 자기 자신의 값을 그대로 유지할 수 있도록 리스트에 기존 joe.id 의 값을 자리 표시자(placeholder)로 다시 적어주어야 했습니다. 모양새가 조금 번거롭고 예쁘지 않죠.
지정 초기자를 사용한 할당 (C++20)
리스트 할당에서도 지정 초기자를 사용할 수 있습니다.
struct Employee
{
int id {};
int age {};
double wage {};
};
int main()
{
Employee joe { 1, 32, 60000.0 };
joe = { .id = joe.id, .age = 33, .wage = 66000.0 }; // Joe의 생일이 지났고 급여가 올랐습니다.
return 0;
}
이러한 할당 과정에서 명시적으로 지정되지 않은 멤버들은 값 초기화가 될 때 사용되는 기본값으로 덮어쓰기 됩니다.
만약 우리가 joe.id 에 지정 초기자를 써주지 않았다면, joe.id 에는 0이 할당되었을 것입니다.
같은 타입의 다른 구조체로 구조체 초기화하기
구조체는 동일한 타입의 다른 구조체를 사용하여 초기화될 수도 있습니다.
#include <iostream>
struct Foo
{
int a{};
int b{};
int c{};
};
std::ostream& operator<<(std::ostream& out, const Foo& f)
{
out << f.a << ' ' << f.b << ' ' << f.c;
return out;
}
int main()
{
Foo foo { 1, 2, 3 };
Foo x = foo; // 복사 초기화
Foo y(foo); // 직접 초기화
Foo z {foo}; // 직접 리스트 초기화
std::cout << x << '\n';
std::cout << y << '\n';
std::cout << z << '\n';
return 0;
}
위 코드의 출력 결과는 다음과 같습니다:
1 2 3
1 2 3
1 2 3
이 방식은 앞서 배웠던 집합체 초기화가 아니라, 우리가 이미 익숙한 표준 초기화 형태(복사, 직접 또는 직접 리스트 초기화)를 사용한다는 점을 기억하세요.
이러한 패턴은 동일한 타입의 구조체를 반환하는 함수의 결과값으로 구조체를 초기화할 때 가장 자주 볼 수 있습니다. 이 부분은 13.10 레슨(구조체 전달 및 반환)에서 더 자세히 다루도록 하겠습니다.
13.9 — 기본 멤버 초기화 (Default member initialization)
구조체(또는 클래스) 타입을 정의할 때, 타입 정의의 일부로 각 멤버에 대한 기본 초기화 값을 지정할 수 있습니다.
static으로 표시되지 않은 멤버의 경우, 이 과정을 비정적 멤버 초기화 라고 부르기도 합니다.
이때 사용하는 초기화 값을 기본 멤버 초기화 값 이라고 합니다.
관련 내용
정적 멤버와 정적 멤버 초기화는 '15.6 -- 정적 멤버 변수' 단원에서 다룹니다.
다음은 그 예시입니다.
struct Something{
int x; // 초기화 값 없음 (나쁨)
int y {}; // 기본적으로 값 초기화됨
int z { 2 }; // 명시적인 기본값
};
int main(){
Something s1; // s1.x는 초기화되지 않음, s1.y는 0, s1.z는 2임
return 0;
}
위 Something 구조체 정의에서 x는 기본값이 없고, y는 기본적으로 값 초기화되며, z는 2라는 기본값을 가집니다.
사용자가 Something 타입의 객체를 만들 때 직접 초기화 값을 주지 않으면, 이 기본 멤버 초기화 값들이 대신 사용됩니다.
우리가 만든 s1 객체는 별도의 초기화 값을 가지지 않으므로, s1의 멤버들은 기본값으로 초기화됩니다.
s1.x는 기본 초기화 값이 없어서 초기화되지 않은(쓰레기 값이 들어있는) 상태로 남습니다.
s1.y는 기본적으로 값 초기화가 진행되어 0이 됩니다. 그리고 s1.z는 2로 초기화됩니다.
s1.z에 명시적인 초기화 값을 직접 주지 않았음에도 불구하고,
미리 제공된 기본 멤버 초기화 값 덕분에 0이 아닌 값으로 초기화된다는 점을 기억해 두세요.
핵심 포인트
기본 멤버 초기화(또는 나중에 다룰 다른 방법들)를 사용하면, 명시적인 초기화 값을 주지 않아도 구조체와 클래스가 스스로 초기화될 수 있습니다!
고급 독자를 위한 참고
CTAD('13.14 -- 클래스 템플릿 인수 추론(CTAD)과 추론 가이드'에서 다룸)는 비정적 멤버 초기화에 사용할 수 없습니다.
명시적 초기화 값이 기본값보다 우선합니다
초기화 리스트에서 사용자가 명시적으로 지정한 값은 항상 기본 멤버 초기화 값보다 우선해서 적용됩니다.
struct Something{
int x; // 기본 초기화 값 없음 (나쁨)
int y {}; // 기본적으로 값 초기화됨
int z { 2 }; // 명시적인 기본값
};
int main(){
Something s2 { 5, 6, 7 }; // s2.x, s2.y, s2.z에 명시적 초기화 값 사용 (기본값은 사용되지 않음)
return 0;
}
위의 경우 s2는 모든 멤버에 대해 직접 명시적인 초기화 값을 입력했으므로, 기본 멤버 초기화 값은 전혀 사용되지 않습니다.
즉, s2.x, s2.y, s2.z는 각각 5, 6, 7로 초기화됩니다.
기본값이 있을 때 초기화 리스트의 값이 생략된 경우
이전 단원('13.8 -- 구조체 집합체 초기화')에서, 집합체를 초기화할 때 제공된 값이 멤버의 수보다 적으면 나머지 멤버들은 모두 값 초기화(0으로 초기화)된다고 배웠습니다. 하지만 특정 멤버에 기본 멤버 초기화 값이 이미 설정되어 있다면, 값 초기화 대신 그 기본값이 사용됩니다.
struct Something{
int x; // 기본 초기화 값 없음 (나쁨)
int y {}; // 기본적으로 값 초기화됨
int z { 2 }; // 명시적인 기본값
};
int main(){
Something s3 {}; // s3.x는 값 초기화, s3.y와 s3.z는 기본값 사용
return 0;
}
위의 경우 s3는 빈 리스트 {} 로 초기화되었기 때문에 초기화 값이 모두 생략되었습니다. 이는 기본 멤버 초기화 값이 존재하면 그것을 사용하고, 없다면 값 초기화를 진행한다는 것을 의미합니다. 따라서 (기본 초기화 값이 없는) s3.x는 0으로 값 초기화되고, s3.y는 기본 설정에 따라 0으로 값 초기화되며, s3.z는 설정된 기본값인 2로 초기화됩니다.
초기화 경우의 수 요약
집합체가 초기화 리스트 와 함께 정의된 경우:
- 명시적인 초기화 값이 있으면, 그 명시적 값을 사용합니다.
- 초기화 값이 생략되었고 기본 멤버 초기화 값이 있다면, 기본값을 사용합니다.
- 초기화 값이 생략되었고 기본 멤버 초기화 값도 없다면, 값 초기화가 일어납니다.
집합체가 초기화 리스트 없이 정의된 경우:
- 기본 멤버 초기화 값이 있으면, 기본값을 사용합니다.
- 기본 멤버 초기화 값이 없으면, 멤버는 초기화되지 않은 상태로 남습니다.
멤버는 항상 선언된 순서대로 초기화됩니다. 다음 예제는 모든 경우의 수를 보여줍니다:
struct Something{
int x; // 기본 초기화 값 없음 (나쁨)
int y {}; // 기본적으로 값 초기화됨
int z { 2 }; // 명시적인 기본값
};
int main(){
Something s1; // 초기화 리스트 없음: s1.x는 초기화되지 않음, s1.y와 s1.z는 기본값 사용
Something s2 { 5, 6, 7 }; // 명시적 초기화: s2.x, s2.y, s2.z는 명시적 값 사용 (기본값은 사용되지 않음)
Something s3 {}; // 초기화 값 생략: s3.x는 값 초기화됨, s3.y와 s3.z는 기본값 사용
return 0;
}
우리가 가장 주의해야 할 부분은 s1.x입니다. s1은 초기화 리스트가 없고 x는 기본 멤버 초기화 값도 없기 때문에, s1.x는 초기화되지 않은 상태로 남습니다 (변수는 항상 초기화해야 하므로 이는 좋지 않은 코드입니다).
멤버에 항상 기본값을 제공하세요
멤버가 초기화되지 않은 상태로 남는 것을 방지하려면, 단순히 각 멤버가 기본값(명시적인 숫자 형태든 빈 중괄호 {} 든)을 가지도록 만들어주면 됩니다. 이렇게 하면 초기화 리스트를 제공하든 안 하든 상관없이 모든 멤버가 어떤 값으로든 안전하게 초기화됩니다.
모든 멤버가 기본값을 가지고 있는 다음 구조체를 살펴보세요:
struct Fraction{
int numerator { }; // 여기에 { 0 }을 사용해야 하지만, 예제를 위해 대신 값 초기화를 사용하겠습니다.
int denominator { 1 };
};
int main(){
Fraction f1; // f1.numerator는 0으로 값 초기화, f1.denominator는 1을 기본값으로 사용
Fraction f2 {}; // f2.numerator는 0으로 값 초기화, f2.denominator는 1을 기본값으로 사용
Fraction f3 { 6 }; // f3.numerator는 6으로 초기화, f3.denominator는 1을 기본값으로 사용
Fraction f4 { 5, 8 }; // f4.numerator는 5로 초기화, f4.denominator는 8로 초기화
return 0;
}
어떤 방식으로 객체를 생성하든 우리의 멤버들은 안전하게 값으로 초기화됩니다.
권장 사항 (Best practice)
모든 멤버에 기본값을 제공하세요.
변수를 정의할 때 초기화 리스트가 빠져 있더라도 멤버가 초기화되도록 보장해 줍니다.
집합체에서 기본 초기화(Default initialization) vs 값 초기화(Value initialization)
위 예제의 두 줄을 다시 살펴보겠습니다:
Fraction f1; // f1.numerator는 0으로 값 초기화, f1.denominator는 1을 기본값으로 사용
Fraction f2 {}; // f2.numerator는 0으로 값 초기화, f2.denominator는 1을 기본값으로 사용
f1은 (아무것도 없는) 기본 초기화가 되었고, f2는 (빈 중괄호 {} 를 사용한) 값 초기화가 되었지만, 결과는 같다는 것(numerator는 0, denominator는 1로 초기화됨)을 눈치채셨을 것입니다. 그렇다면 어느 것을 선택해야 할까요?
값 초기화 방식(f2)이 더 안전합니다. 왜냐하면 기본값이 지정되지 않은 멤버가 있더라도 확실하게 값 초기화(0으로 초기화) 되도록 보장해주기 때문입니다. (물론 항상 멤버에 기본값을 제공하는 것이 원칙이지만, 혹시라도 하나를 빼먹었을 경우를 대비한 훌륭한 안전망이 됩니다.)
값 초기화를 선호해야 하는 또 다른 장점이 있습니다. 바로 다른 타입의 객체를 초기화하는 방식과 일관성이 생긴다는 점입니다. 일관된 코딩 스타일은 오류를 예방하는 데 큰 도움이 됩니다.
권장 사항 (Best practice) > 집합체의 경우, (중괄호가 없는) 기본 초기화보다 (빈 중괄호를 사용하는) 값 초기화를 더 선호하세요.
그렇긴 하지만, 프로그래머들이 클래스 타입에 대해 값 초기화 대신 기본 초기화를 사용하는 모습도 흔하게 볼 수 있습니다. 이는 역사적인 이유(값 초기화는 C++11부터 도입됨) 때문이기도 하고, 비집합체(non-aggregates)의 특정 상황에서는 기본 초기화가 값 초기화보다 더 효율적으로 동작할 수 있기 때문이기도 합니다 (이 내용은 '14.11 -- 기본 생성자와 기본 인수' 단원에서 다룹니다).
따라서 이 튜토리얼에서 구조체와 클래스에 대한 값 초기화 사용을 강박적으로 강요하지는 않겠지만, 강력하게 권장하는 바입니다.
13.10 — 구조체 전달 및 반환하기 (Passing and returning structs)
직원의 정보가 3개의 개별 변수로 나뉘어 있다고 상상해 보세요.
int main()
{
int id { 1 };
int age { 24 };
double wage { 52400.0 };
return 0;
}
이 직원 정보를 어떤 함수에 전달하려면, 세 개의 변수를 모두 넘겨주어야 합니다.
#include <iostream>
void printEmployee(int id, int age, double wage)
{
std::cout << "ID: " << id << '\n';
std::cout << "Age: " << age << '\n';
std::cout << "Wage: " << wage << '\n';
}
int main()
{
int id { 1 };
int age { 24 };
double wage { 52400.0 };
printEmployee(id, age, wage);
return 0;
}
변수 3개를 따로 전달하는 것은 그럭저럭 괜찮아 보일 수 있습니다. 하지만 직원 변수가 10개나 12개라면 어떨까요? 각각의 변수를 따로 전달하는 것은 시간도 오래 걸리고 실수하기도 쉽습니다. 게다가 직원의 속성(예: 이름)을 새로 추가하게 되면, 그 새로운 매개변수와 데이터를 받기 위해 모든 함수의 선언부, 정의부, 호출부를 일일이 수정해야 합니다!
구조체 전달하기 (참조 방식)
개별 변수 대신 구조체(Struct) 를 사용할 때 얻는 가장 큰 장점은, 데이터가 필요한 함수에 구조체 전체를 한 번에 전달할 수 있다는 것입니다. 구조체는 일반적으로 복사본이 생성되어 성능이 떨어지는 것을 막기 위해 참조(Reference) (보통 const 참조) 방식으로 전달됩니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
void printEmployee(const Employee& employee) // 참고: 여기서 참조(reference) 방식으로 전달합니다
{
std::cout << "ID: " << employee.id << '\n';
std::cout << "Age: " << employee.age << '\n';
std::cout << "Wage: " << employee.wage << '\n';
}
int main()
{
Employee joe { 14, 32, 24.15 };
Employee frank { 15, 28, 18.27 };
// Joe의 정보 출력
printEmployee(joe);
std::cout << '\n';
// Frank의 정보 출력
printEmployee(frank);
return 0;
}
위 예제에서 우리는 printEmployee() 함수에 Employee 구조체 전체를 통째로 전달했습니다 (joe를 위해 한 번, frank를 위해 한 번).
위 프로그램의 출력 결과는 다음과 같습니다:
ID: 14
Age: 32
Wage: 24.15
ID: 15
Age: 28
Wage: 18.27
개별 멤버가 아닌 구조체 객체 전체를 전달하기 때문에, 구조체 안에 멤버 변수가 아무리 많아도 매개변수는 단 한 개만 필요합니다. 그리고 나중에 Employee 구조체에 새로운 멤버를 추가하기로 결정하더라도, 함수의 선언이나 호출 부분을 바꿀 필요가 없습니다! 새로운 멤버도 자동으로 함께 전달되기 때문입니다.
관련 내용
구조체를 언제 값(Value)으로 전달하고, 언제 참조(Reference)로 전달해야 하는지에 대해서는 레슨 12.6 - const 좌측값 참조로 전달하기 에서 자세히 다룹니다.
임시 구조체 전달하기
이전 예제에서는 printEmployee() 함수에 전달하기 전에 joe 라는 이름의 Employee 변수를 먼저 만들었습니다. 이렇게 하면 변수에 이름을 붙일 수 있어 코드를 설명하는 데 유용할 수 있습니다. 하지만 두 줄의 코드(하나는 joe를 만드는 코드, 다른 하나는 joe를 사용하는 코드)가 필요하게 됩니다.
변수를 딱 한 번만 사용할 때는, 굳이 변수에 이름을 붙이고 생성과 사용 과정을 분리하는 것이 코드를 더 복잡하게 만들 수 있습니다. 이런 경우에는 임시 객체(Temporary object) 를 사용하는 것이 더 좋을 수 있습니다. 임시 객체는 일반적인 변수가 아니기 때문에 이름(식별자)을 가지지 않습니다.
위와 똑같은 예제이지만, joe 와 frank 변수를 임시 객체로 바꾼 코드입니다:
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
void printEmployee(const Employee& employee) // 참고: 여기서 참조(reference) 방식으로 전달합니다
{
std::cout << "ID: " << employee.id << '\n';
std::cout << "Age: " << employee.age << '\n';
std::cout << "Wage: " << employee.wage << '\n';
}
int main()
{
// Joe의 정보 출력
printEmployee(Employee { 14, 32, 24.15 }); // 함수에 전달할 임시 Employee 객체 생성 (타입을 명시적으로 지정함) (권장)
std::cout << '\n';
// Frank의 정보 출력
printEmployee({ 15, 28, 18.27 }); // 함수에 전달할 임시 Employee 객체 생성 (매개변수에서 타입을 추론함)
return 0;
}
우리는 임시 Employee 객체를 두 가지 방법으로 만들 수 있습니다.
첫 번째 호출에서는 Employee { 14, 32, 24.15 } 문법을 사용했습니다. 이는 컴파일러에게 Employee 객체를 만들고, 우리가 제공한 값들로 초기화하라고 지시하는 것입니다. 이 방식은 우리가 어떤 종류의 임시 객체를 만들고 있는지 명확하게 보여주고, 컴파일러가 우리의 의도를 오해할 일이 없기 때문에 더 권장되는 문법 입니다.
두 번째 호출에서는 { 15, 28, 18.27 } 문법을 사용했습니다. 컴파일러는 똑똑하게도, 함수 호출이 성공하려면 이 값들이 Employee 타입으로 변환되어야 한다는 것을 알아냅니다. 참고로 이 형태는 '암시적 변환(implicit conversion)'으로 간주되므로, 오직 '명시적 변환'만 허용되는 까다로운 상황에서는 작동하지 않습니다.
관련 내용
클래스 타입의 임시 객체와 변환에 대해서는 레슨 14.13 - 임시 클래스 객체 에서 더 자세히 다룹니다.
임시 객체에 대해 몇 가지 더 알아둘 점이 있습니다. 임시 객체는 정의되는 순간에 생성 및 초기화되며, 자신이 만들어진 전체 표현식(코드 한 줄)의 실행이 끝날 때 파괴됩니다. 그리고 임시 객체는 '우측값(rvalue)'으로 취급되므로, 우측값을 허용하는 곳에서만 사용할 수 있습니다. 임시 객체가 함수 인수로 사용될 때는, 우측값을 받아들일 수 있는 매개변수와만 연결됩니다. 여기에는 '값에 의한 전달(pass by value)'과 'const 참조에 의한 전달'이 포함되며, 'non-const 참조'나 '주소에 의한 전달'은 허용되지 않습니다.
구조체 반환하기
3차원 데카르트 좌표계의 한 점을 반환해야 하는 함수가 있다고 생각해 봅시다. 이 점은 x 좌표, y 좌표, z 좌표라는 3개의 속성을 가집니다.
하지만 함수는 오직 하나의 값만 반환할 수 있습니다. 그렇다면 3개의 좌표를 모두 사용자에게 반환하려면 어떻게 해야 할까요?
가장 흔한 방법 중 하나는 구조체를 반환하는 것입니다.
#include <iostream>
struct Point3d
{
double x { 0.0 };
double y { 0.0 };
double z { 0.0 };
};
Point3d getZeroPoint()
{
// 변수를 만들어서 반환할 수 있습니다 (아래에서 이 코드를 더 개선해 볼 것입니다)
Point3d temp { 0.0, 0.0, 0.0 };
return temp;
}
int main()
{
Point3d zero{ getZeroPoint() };
if (zero.x == 0.0 && zero.y == 0.0 && zero.z == 0.0)
std::cout << "The point is zero\n";
else
std::cout << "The point is not zero\n";
return 0;
}
이 코드는 다음과 같이 출력합니다:
The point is zero
함수 내부에서 정의된 구조체는 소멸된 참조를 반환하는 문제를 피하기 위해 보통 값(Value)으로 반환됩니다.
위의 getZeroPoint() 함수에서는 오직 값을 반환하기 위한 목적만으로 temp 라는 이름의 객체를 새로 만들었습니다:
Point3d getZeroPoint()
{
// 변수를 만들어서 반환할 수 있습니다 (아래에서 이 코드를 더 개선해 볼 것입니다)
Point3d temp { 0.0, 0.0, 0.0 };
return temp;
}
하지만 여기서 객체의 이름(temp)은 코드를 읽는 데 아무런 추가적인 정보나 도움을 주지 않습니다.
대신 이름이 없는 임시 객체(익명 객체)를 반환하도록 수정하면 코드를 조금 더 깔끔하게 만들 수 있습니다:
Point3d getZeroPoint()
{
return Point3d { 0.0, 0.0, 0.0 }; // 이름 없는 Point3d 객체 반환
}
이 경우, 임시 Point3d 객체가 생성되어 함수를 호출한 쪽으로 복사된 후, 표현식이 끝날 때 파괴됩니다. 코드가 훨씬 더 깔끔해졌다는 점에 주목해 보세요. (두 줄이 한 줄로 줄었고, temp 변수가 다른 곳에서 또 쓰이는 건 아닌지 고민할 필요도 없어졌습니다.)
관련 내용
익명 객체에 대해서는 레슨 14.13 - 임시 클래스 객체 에서 더 자세히 다룹니다.
반환 타입 추론하기
함수에 명시적인 반환 타입(예: Point3d)이 이미 적혀 있는 경우, return 문에서 타입을 아예 생략할 수도 있습니다:
Point3d getZeroPoint()
{
// 함수 선언부에서 이미 타입을 지정했으므로
// 여기서 다시 타입을 적어줄 필요가 없습니다
return { 0.0, 0.0, 0.0 }; // 이름 없는 Point3d 객체 반환
}
이는 암시적 변환으로 간주됩니다.
또한, 이 경우에는 모든 값을 0으로 반환하려고 하므로, 빈 중괄호를 사용하여 값 초기화(value-initialized)된 Point3d 객체를 반환할 수도 있습니다:
Point3d getZeroPoint()
{
// 빈 중괄호를 사용하여 모든 멤버를 값 초기화(value-initialize) 할 수 있습니다
return {};
}
중요한 구성 요소인 구조체
구조체 그 자체로도 매우 유용하지만, C++와 객체 지향 프로그래밍의 핵심이라고 할 수 있는 클래스(Class) 는 우리가 여기서 소개한 개념들 바로 위에 세워집니다. 구조체(특히 데이터 멤버, 멤버 선택, 기본 멤버 초기화 등)를 잘 이해해 두면, 나중에 클래스를 배울 때 훨씬 더 쉽고 수월하게 넘어갈 수 있을 것입니다.
13.11 — 구조체 기타 주제들 (Struct miscellany)
프로그램 정의 멤버를 가지는 구조체
C++에서 구조체(그리고 클래스)는 프로그래머가 직접 정의한 다른 타입을 멤버로 가질 수 있습니다. 여기에는 두 가지 방법이 있습니다.
첫 번째로, (전역 범위에) 프로그래머 정의 타입을 하나 만든 다음, 이를 다른 프로그래머 정의 타입의 멤버로 사용하는 방법입니다.
#include <iostream>
struct Employee
{
int id {};
int age {};
double wage {};
};
struct Company
{
int numberOfEmployees {};
Employee CEO {}; // Employee는 Company 구조체 내부에 있는 구조체입니다
};
int main()
{
Company myCompany{ 7, { 1, 32, 55000.0 } }; // Employee를 초기화하기 위한 중첩된 초기화 리스트
std::cout << myCompany.CEO.wage << '\n'; // CEO의 급여를 출력
return 0;
}
위 예제에서는 Employee 구조체를 먼저 정의한 뒤, 이를 Company 구조체의 멤버로 사용했습니다. Company 를 초기화할 때, 중첩된 초기화 리스트를 사용하면 내부에 있는 Employee 도 한 번에 초기화할 수 있습니다. 만약 CEO의 급여를 확인하고 싶다면, 멤버 선택 연산자(.)를 두 번 연속해서 사용하면 됩니다: myCompany.CEO.wage;
두 번째로, 어떤 타입을 다른 타입 안에 완전히 중첩시킬 수도 있습니다.
만약 Employee 라는 타입이 Company 의 일부로만 존재한다면, Employee 타입을 아예 Company 구조체 내부로 쏙 집어넣을 수 있습니다.
#include <iostream>
struct Company
{
struct Employee // Company::Employee를 통해 접근합니다
{
int id{};
int age{};
double wage{};
};
int numberOfEmployees{};
Employee CEO{}; // Employee는 Company 구조체 내부에 있는 구조체입니다
};
int main()
{
Company myCompany{ 7, { 1, 32, 55000.0 } }; // Employee를 초기화하기 위한 중첩된 초기화 리스트
std::cout << myCompany.CEO.wage << '\n'; // CEO의 급여를 출력
return 0;
}
이런 중첩 방식은 주로 클래스에서 더 자주 쓰입니다.
따라서 이 부분은 나중에 다룰 '15.3 — 중첩 타입(멤버 타입)' 레슨에서 조금 더 자세히 이야기해 보겠습니다.
소유자인 구조체는 소유자인 데이터 멤버를 가져야 합니다
지난 '5.9 레슨 — std::string_view (2부)'에서, 우리는 소유자(Owner) 와 관찰자(Viewer) 라는 두 가지 중요한 개념을 배웠습니다.
소유자는 자신의 데이터를 직접 관리하고, 그 데이터가 언제 사라질지 통제합니다. 반면에 관찰자는 그저 남의 데이터를 쳐다보기만 할 뿐, 그 데이터가 변경되거나 사라지는 것을 통제할 수 없습니다.
대부분의 경우, 우리는 구조체(나 클래스)가 자신이 품고 있는 데이터의 진정한 소유자가 되기를 원합니다.
이렇게 하면 몇 가지 아주 좋은 장점이 있습니다.
- 구조체가 존재하는 한, 그 안에 있는 데이터 멤버들도 안전하게 유지됩니다.
- 데이터 멤버의 값이 예상치 못한 순간에 마음대로 변하지 않습니다.
구조체를 소유자로 만드는 가장 쉬운 방법은, 각각의 데이터 멤버들에게 '소유권을 가진 타입'을 주는 것입니다 (예를 들어 관찰자, 포인터, 참조자 같은 타입은 피하는 것이죠). 구조체 안의 모든 데이터 멤버가 소유자라면, 그 구조체 자체도 자동으로 소유자가 됩니다.
만약 구조체가 '관찰자'인 데이터 멤버를 하나라도 가지고 있다면, 그 멤버가 쳐다보고 있는 원본 데이터가 구조체보다 먼저 사라져버릴 위험이 있습니다. 이런 일이 발생하면 구조체 안에는 이미 사라진 데이터를 가리키는 허상(dangling) 멤버 가 남게 되며, 이 멤버를 사용하려고 하면 프로그램이 어떻게 동작할지 알 수 없는 심각한 오류(미정의 동작)가 발생합니다.
모범 사례 (Best practice)
대부분의 경우 구조체(그리고 클래스)를 소유자로 만드는 것이 안전합니다.
이를 위한 가장 쉬운 방법은 각 데이터 멤버가 소유권이 있는 타입(관찰자, 포인터, 참조자가 아닌 타입)인지 꼼꼼히 확인하는 것입니다.
저자의 노트 (Author’s note)
항상 안전한 구조체를 만드는 습관을 들이세요. 여러분의 멤버 변수가 길 잃은 허상(dangling) 상태가 되도록 방치하지 마세요!
문자열 데이터 멤버를 만들 때 (관찰자인) std::string_view 대신 거의 항상 (소유자인) std::string 을 사용하는 이유도 바로 이 때문입니다. 아래 예제를 보시면 왜 이것이 중요한지 바로 이해되실 거예요.
#include <iostream>
#include <string>
#include <string_view>
struct Owner
{
std::string name{}; // std::string은 소유자입니다
};
struct Viewer
{
std::string_view name {}; // std::string_view는 관찰자입니다
};
// getName()은 사용자가 입력한 문자열을 임시 std::string으로 반환합니다.
// 이 임시 std::string은 함수 호출이 포함된 전체 표현식이 끝날 때 파괴됩니다.
std::string getName()
{
std::cout << "Enter a name: ";
std::string name{};
std::cin >> name;
return name;
}
int main()
{
Owner o { getName() }; // getName()의 반환 값은 초기화 직후에 파괴됩니다
std::cout << "The owners name is " << o.name << '\n'; // 정상 작동
Viewer v { getName() }; // getName()의 반환 값은 초기화 직후에 파괴됩니다
std::cout << "The viewers name is " << v.name << '\n'; // 미정의 동작 (알 수 없는 결과)
return 0;
}
위 코드에서 getName() 함수는 사용자가 입력한 이름을 '임시 std::string'으로 돌려줍니다.
이 임시 데이터는 함수 호출이 끝나는 문장의 마지막에서 수명을 다하고 사라집니다.
o 의 경우를 살펴볼까요? 이 임시 std::string 은 o.name 을 초기화하는 데 사용됩니다. o.name 은 std::string 이기 때문에, 전달받은 임시 데이터를 안전하게 자기 공간으로 복사합니다. 복사가 끝난 뒤 원본 임시 데이터는 사라지지만, o.name 은 복사본을 안전하게 가지고 있으므로 아무런 문제가 없습니다. 그 다음 줄에서 o.name 을 출력하면 우리가 예상한 대로 이름이 잘 나옵니다.
하지만 v 의 경우는 다릅니다. 여기서도 임시 std::string 이 v.name 을 초기화하는 데 쓰입니다. 그런데 v.name 은 std::string_view (관찰자)이기 때문에 복사본을 만들지 않고 임시 데이터를 그저 '바라보기만' 합니다. 그 직후 임시 데이터가 수명을 다해 파괴되면, v.name 은 허공을 바라보는 허상(dangling) 상태 가 되어버립니다. 다음 줄에서 v.name 을 출력하려고 하면, 이미 사라진 데이터에 접근하는 꼴이 되므로 오류(미정의 동작)가 발생합니다.
구조체 크기와 데이터 구조 정렬 (Struct size and data structure alignment)
보통 구조체의 크기는 그 안에 들어있는 모든 멤버 변수들의 크기를 합친 것과 같다고 생각하기 쉽습니다. 하지만 항상 그런 것은 아닙니다!
다음 프로그램을 한 번 볼까요?
#include <iostream>
struct Foo
{
short a {};
int b {};
double c {};
};
int main()
{
std::cout << "The size of short is " << sizeof(short) << " bytes\n";
std::cout << "The size of int is " << sizeof(int) << " bytes\n";
std::cout << "The size of double is " << sizeof(double) << " bytes\n";
std::cout << "The size of Foo is " << sizeof(Foo) << " bytes\n";
return 0;
}
저자의 컴퓨터에서 이 코드를 실행하면 다음과 같이 출력됩니다.
The size of short is 2 bytes
The size of int is 4 bytes
The size of double is 8 bytes
The size of Foo is 16 bytes
분명 short(2) + int(4) + double(8) 을 더하면 14바이트인데, Foo 구조체의 전체 크기는 16바이트가 나왔습니다! 왜 그럴까요?
사실, 구조체의 크기는 내부 변수들의 크기를 모두 합친 것보다 최소한 같거나 크다 고만 확신할 수 있습니다. 즉, 실제로는 더 커질 수도 있다는 뜻이죠. 그 이유는 C++ 컴파일러가 컴퓨터의 처리 속도(성능)를 높이기 위해 구조체 변수들 사이에 몰래 빈 공간을 끼워 넣기 때문입니다. 이렇게 빈 공간을 추가하는 것을 패딩(padding) 이라고 부릅니다.
위의 Foo 구조체에서 컴파일러는 멤버 a 뒤에 2바이트의 패딩(빈 공간)을 보이지 않게 추가했습니다. 그 결과 14바이트가 아니라 16바이트가 된 것입니다.
심화 학습자를 위해 (For advanced readers) >
컴파일러가 대체 왜 이런 빈 공간을 끼워 넣는지(패딩) 그 구체적인 원리는 이 튜토리얼의 범위를 벗어납니다. 하지만 궁금하시다면 위키백과에서 데이터 구조 정렬(data structure alignment) 에 대해 더 찾아보실 수 있습니다. 물론 이것은 구조체나 C++의 기본을 이해하기 위해 꼭 알아야 하는 필수 내용은 아니니 가볍게 넘어가셔도 괜찮습니다!
이 패딩이라는 녀석은 구조체의 크기에 생각보다 꽤 큰 영향을 미칩니다. 다음 예제를 확인해 보세요.
#include <iostream>
struct Foo1
{
short a{}; // a 뒤에 2바이트의 패딩이 생깁니다
int b{};
short c{}; // c 뒤에 2바이트의 패딩이 생깁니다
};
struct Foo2
{
int b{};
short a{};
short c{};
};
int main()
{
std::cout << sizeof(Foo1) << '\n'; // 12 출력
std::cout << sizeof(Foo2) << '\n'; // 8 출력
return 0;
}
이 프로그램을 실행하면 다음과 같이 출력됩니다.
12
8
놀랍지 않나요? Foo1 과 Foo2 는 들어있는 멤버가 완전히 똑같습니다.
단지 멤버를 선언한 '순서'만 다를 뿐이죠. 그런데도 중간중간 끼어든 패딩 때문에 Foo1 의 크기가 무려 50%나 더 큽니다.
꿀팁 (Tip)
크기가 가장 큰 멤버부터 가장 작은 멤버 순서(내림차순)로 변수를 정의하면, 불필요한 패딩을 최소한으로 줄일 수 있습니다.
C++ 컴파일러는 프로그래머가 적어 놓은 변수 순서를 마음대로 바꿀 수 없도록 규칙이 정해져 있습니다.
따라서 이런 최적화 작업은 우리가 직접 코드를 짤 때 신경 써 주어야 합니다.
13.12 — 포인터와 참조를 사용한 멤버 선택
구조체와 구조체 참조를 위한 멤버 선택
13.7 - 구조체, 멤버, 멤버 선택 소개 레슨에서, 우리는 멤버 선택 연산자 (.)를 사용하여 구조체 객체에서 멤버를 선택할 수 있다는 것을 보여주었습니다.
#include <iostream>
struct Employee{
int id {};
int age {};
double wage {};
};
int main(){
Employee joe { 1, 34, 65000.0 };
// 구조체 객체에서 멤버를 선택하기 위해 멤버 선택 연산자 (.)를 사용합니다.
++joe.age; // Joe의 생일이 지났습니다.
joe.wage = 68000.0; // Joe가 승진했습니다.
return 0;
}
객체에 대한 참조는 객체 자체와 똑같이 작동하므로, 참조를 통해 구조체의 멤버를 선택할 때도 멤버 선택 연산자 (.)를 사용할 수 있습니다.
#include <iostream>
struct Employee{
int id{};
int age{};
double wage{};
};
void printEmployee(const Employee& e){
// 구조체 참조에서 멤버를 선택하기 위해 멤버 선택 연산자 (.)를 사용합니다.
std::cout << "Id: " << e.id << '\n';
std::cout << "Age: " << e.age << '\n';
std::cout << "Wage: " << e.wage << '\n';
}
int main(){
Employee joe{ 1, 34, 65000.0 };
++joe.age;
joe.wage = 68000.0;
printEmployee(joe);
return 0;
}
구조체 포인터를 위한 멤버 선택
하지만, 멤버 선택 연산자 (.)는 구조체를 가리키는 포인터에는 직접 사용할 수 없습니다.
#include <iostream>
struct Employee{
int id{};
int age{};
double wage{};
};
int main(){
Employee joe{ 1, 34, 65000.0 };
++joe.age;
joe.wage = 68000.0;
Employee* ptr{ &joe };
std::cout << ptr.id << '\n'; // 컴파일 에러: 포인터에는 . 연산자를 사용할 수 없습니다.
return 0;
}
일반적인 변수나 참조를 사용하면 객체에 직접 접근할 수 있습니다.
하지만 포인터는 '주소'를 담고 있기 때문에, 포인터를 가지고 무언가를 하기 전에는 먼저 포인터를 역참조 (dereference) 하여 객체를 가져와야 합니다. 따라서 포인터를 통해 구조체 멤버에 접근하는 한 가지 방법은 다음과 같습니다.
#include <iostream>
struct Employee{
int id{};
int age{};
double wage{};
};
int main(){
Employee joe{ 1, 34, 65000.0 };
++joe.age;
joe.wage = 68000.0;
Employee* ptr{ &joe };
std::cout << (*ptr).id << '\n'; // 썩 좋진 않지만 작동합니다: 먼저 ptr을 역참조한 다음, 멤버 선택 연산자를 사용합니다.
return 0;
}
하지만 이 방법은 조금 보기 안 좋습니다. 특히 역참조 연산(*)이 멤버 선택 연산(.)보다 먼저 실행되도록 꼭 괄호로 묶어줘야 하기 때문입니다.
더 깔끔한 코드를 작성하기 위해, C++은 포인터에서 객체의 멤버를 쉽게 선택할 수 있는 포인터를 통한 멤버 선택 연산자 (->) (때로는 화살표 연산자 라고도 부름)를 제공합니다.
#include <iostream>
struct Employee{
int id{};
int age{};
double wage{};
};
int main(){
Employee joe{ 1, 34, 65000.0 };
++joe.age;
joe.wage = 68000.0;
Employee* ptr{ &joe };
std::cout << ptr->id << '\n'; // 더 좋은 방법: -> 연산자를 사용하여 객체를 가리키는 포인터에서 멤버를 선택합니다.
return 0;
}
이 포인터를 통한 멤버 선택 연산자 (->)는 일반 멤버 선택 연산자 (.)와 똑같이 작동하지만, 멤버를 선택하기 전에 포인터 객체를 자동으로 역참조해 줍니다. 따라서 ptr->id 는 (*ptr).id 와 완전히 똑같은 의미입니다.
이 화살표 연산자는 키보드로 치기 쉬울 뿐만 아니라, 간접 참조를 알아서 처리해 주므로 연산자 우선순위를 걱정할 필요가 없어 실수를 훨씬 줄여줍니다. 결론적으로, 포인터를 통해 멤버에 접근할 때는 항상 . 연산자 대신 -> 연산자를 사용하는 것이 좋습니다.
모범 사례
포인터를 사용하여 멤버에 접근할 때는 멤버 선택 연산자 (.) 대신 포인터를 통한 멤버 선택 연산자 (->)를 사용하세요.
operator-> 연속해서 사용하기 (체이닝)
operator->를 통해 접근한 멤버가 클래스나 구조체를 가리키는 포인터라면,
같은 줄에서 operator->를 한 번 더 사용하여 그 내부의 멤버에 다시 접근할 수 있습니다.
다음 예제는 이 과정을 잘 보여줍니다.
#include <iostream>
struct Point{
double x {};
double y {};
};
struct Triangle{
Point* a {};
Point* b {};
Point* c {};
};
int main(){
Point a {1,2};
Point b {3,7};
Point c {10,2};
Triangle tr { &a, &b, &c };
Triangle* ptr {&tr};
// ptr은 Triangle을 가리키는 포인터이고, 이 구조체 안에는 Point를 가리키는 포인터들이 들어있습니다.
// ptr이 가리키는 Triangle 안의 멤버 c(Point 포인터)를 통해 멤버 y에 접근하려면, 다음 두 가지 방법은 동일한 역할을 합니다:
// . 연산자를 사용한 접근
std::cout << (*(*ptr).c).y << '\n'; // 보기 안 좋습니다!
// -> 연산자를 사용한 접근
std::cout << ptr -> c -> y << '\n'; // 훨씬 낫습니다!
}
두 개 이상의 operator->를 연속해서 사용할 때 (예: ptr->c->y), 코드가 한눈에 안 들어올 수 있습니다.
이때 멤버와 operator-> 사이에 띄어쓰기를 추가하면 (예: ptr -> c -> y) 어떤 멤버에 접근하고 있는지 조금 더 쉽게 알아볼 수 있습니다.
포인터 멤버와 일반 멤버 섞어 쓰기
멤버 선택 연산자는 항상 '현재 선택된 변수'에 맞게 사용해야 합니다.
만약 포인터 멤버와 일반 멤버 변수가 섞여 있다면, . 과 -> 가 이어서 함께 쓰이는 모습을 볼 수 있습니다.
#include <iostream>
#include <string>
struct Paw{
int claws{};
};
struct Animal{
std::string name{};
Paw paw{};
};
int main(){
Animal puma{ "Puma", { 5 } };
Animal* ptr{ &puma };
// ptr은 포인터이므로 ->를 사용합니다.
// paw는 포인터가 아니므로 .을 사용합니다.
std::cout << (ptr->paw).claws << '\n';
return 0;
}
참고로 (ptr->paw).claws 에서 operator-> 와 operator. 모두 왼쪽에서 오른쪽 순서로 계산되기 때문에 괄호가 반드시 필요한 것은 아닙니다. 하지만 괄호를 쳐주면 코드를 읽기가 조금 더 편해집니다.
13.13 — 클래스 템플릿 (Class templates)
이전 11.6 레슨 -- 함수 템플릿 에서는 우리가 다루고 싶은 다양한 데이터 타입마다 똑같은 역할을 하는 함수를 여러 개(오버로딩) 만들어야 하는 불편함에 대해 이야기했습니다.
#include <iostream>
// 두 int 값 중 더 큰 값을 계산하는 함수
int max(int x, int y)
{
return (x < y) ? y : x;
}
// 두 double 값 중 더 큰 값을 계산하는 거의 동일한 함수
// 유일한 차이점은 타입 정보뿐입니다
double max(double x, double y)
{
return (x < y) ? y : x;
}
int main()
{
std::cout << max(5, 6); // max(int, int) 호출
std::cout << '\n';
std::cout << max(1.2, 3.4); // max(double, double) 호출
return 0;
}
이 문제에 대한 해결책은 함수 템플릿 을 만드는 것이었습니다.
템플릿 하나만 만들어 두면, 컴파일러가 필요한 타입에 맞춰 일반 함수를 자동으로 찍어내(인스턴스화) 사용할 수 있기 때문입니다.
#include <iostream>
// max를 위한 단일 함수 템플릿
template <typename T>
T max(T x, T y)
{
return (x < y) ? y : x;
}
int main()
{
std::cout << max(5, 6); // max<int>(int, int)를 인스턴스화하고 호출
std::cout << '\n';
std::cout << max(1.2, 3.4); // max<double>(double, double)를 인스턴스화하고 호출
return 0;
}
관련 내용
함수 템플릿이 어떻게 함수를 찍어내는지(인스턴스화)에 대한 자세한 내용은 11.7 레슨 -- 함수 템플릿 인스턴스화 에서 다룹니다.
집계 타입(Aggregate types)도 비슷한 문제를 겪습니다
구조체, 클래스, 공용체, 배열 같은 집계 타입 도 비슷한 문제에 부딪힙니다.
예를 들어, 두 개의 int 값 쌍(pair)을 다루면서 둘 중 어느 숫자가 더 큰지 알아내야 하는 프로그램을 작성한다고 가정해 보겠습니다.
아마 다음과 같이 코드를 짤 수 있을 것입니다.
#include <iostream>
struct Pair
{
int first{};
int second{};
};
constexpr int max(Pair p) // Pair의 크기가 작으므로 값으로 전달(pass by value)
{
return (p.first < p.second ? p.second : p.first);
}
int main()
{
Pair p1{ 5, 6 };
std::cout << max(p1) << " is larger\n";
return 0;
}
나중에 개발을 하다 보니 double 값의 쌍(pair)도 필요해졌습니다. 그래서 프로그램을 다음과 같이 업데이트했습니다.
#include <iostream>
struct Pair
{
int first{};
int second{};
};
struct Pair // 컴파일 에러: 잘못된 Pair 재정의
{
double first{};
double second{};
};
constexpr int max(Pair p)
{
return (p.first < p.second ? p.second : p.first);
}
constexpr double max(Pair p) // 컴파일 에러: 오버로딩된 함수가 반환 타입만 다름
{
return (p.first < p.second ? p.second : p.first);
}
int main()
{
Pair p1{ 5, 6 };
std::cout << max(p1) << " is larger\n";
Pair p2{ 1.2, 3.4 };
std::cout << max(p2) << " is larger\n";
return 0;
}
안타깝게도 이 프로그램은 컴파일되지 않으며, 해결해야 할 몇 가지 문제가 있습니다.
- 타입은 오버로딩 불가 함수와 달리 타입 정의는 오버로딩할 수 없습니다.
컴파일러는 두 번째double버전의Pair를 처음 정의된Pair를 잘못 재정의한 것으로 간주합니다. - 반환 타입만으론 구분 불가 함수는 오버로딩할 수 있지만, 위 코드의
max(Pair)함수들은 반환 타입만 다를 뿐 매개변수가 똑같습니다. 오버로딩된 함수는 반환 타입만으로 구분할 수 없습니다. - 코드의 심각한 중복
Pair구조체들은 데이터 타입만 빼면 완전히 똑같고,max(Pair)함수들도 반환 타입만 빼면 완전히 똑같습니다.
Pair 구조체의 이름을 서로 다르게 지어주면(예: PairInt, PairDouble) 첫 번째와 두 번째 문제는 해결할 수 있습니다.
하지만 이 방식은 만들어둔 이름들을 전부 외워야 하고, 새로운 타입이 필요할 때마다 똑같은 코드를 계속 복사해서 붙여넣어야 하므로 중복 문제를 전혀 해결하지 못합니다.
다행히 훨씬 더 좋은 방법이 있습니다.
작성자의 노트
다음 내용으로 넘어가기 전에, 함수 템플릿, 템플릿 타입, 혹은 템플릿이 함수를 어떻게 생성하는지 기억나지 않는다면 11.6 레슨 과 11.7 레슨 을 다시 한번 복습해 주세요.
클래스 템플릿 (Class templates)
함수 템플릿이 함수를 붕어빵처럼 찍어내는 틀이라면, 클래스 템플릿 은 클래스나 구조체를 찍어내는 템플릿 틀입니다.
참고
'클래스 타입'은 구조체(struct), 클래스(class), 공용체(union)를 모두 아우르는 말입니다.
설명을 쉽게 하기 위해 구조체를 예시로 '클래스 템플릿'을 설명하겠지만, 여기서 배우는 모든 내용은 클래스에도 똑같이 적용됩니다.
우리가 처음에 만들었던 int 버전의 Pair 구조체를 다시 한번 보겠습니다.
struct Pair
{
int first{};
int second{};
};
이제 이 구조체를 클래스 템플릿 으로 다시 작성해 보겠습니다.
#include <iostream>
template <typename T>
struct Pair
{
T first{};
T second{};
};
int main()
{
Pair<int> p1{ 5, 6 }; // Pair<int>를 인스턴스화하고 객체 p1 생성
std::cout << p1.first << ' ' << p1.second << '\n';
Pair<double> p2{ 1.2, 3.4 }; // Pair<double>를 인스턴스화하고 객체 p2 생성
std::cout << p2.first << ' ' << p2.second << '\n';
Pair<double> p3{ 7.8, 9.0 }; // 이전에 정의된 Pair<double>을 사용하여 객체 p3 생성
std::cout << p3.first << ' ' << p3.second << '\n';
return 0;
}
함수 템플릿과 마찬가지로, 클래스 템플릿도 템플릿 매개변수 선언 으로 시작합니다. template 키워드를 먼저 쓰고, 그다음 꺾쇠괄호(< >) 안에 클래스 템플릿에서 사용할 모든 템플릿 타입을 지정합니다. 필요한 타입마다 typename (권장) 또는 class (비권장) 키워드를 쓰고 그 뒤에 템플릿 타입의 이름(예: T)을 적어주면 됩니다. 이 예제에서는 구조체의 두 멤버 변수가 같은 타입을 사용할 것이므로 템플릿 타입이 하나만 있으면 됩니다.
그다음은 평소처럼 구조체를 정의하면 되는데, 나중에 실제 타입(int, double 등)으로 바뀔 자리에 아까 정해둔 템플릿 타입(T)을 넣어주기만 하면 됩니다. 정말 쉽죠! 이것으로 클래스 템플릿 정의가 끝났습니다.
main 함수 안에서는 우리가 원하는 어떤 타입으로든 Pair 객체를 만들어낼 수 있습니다.
- 먼저
Pair<int>타입의 객체를 만듭니다. 컴파일러는Pair<int>에 대한 정의가 아직 없다는 것을 확인하고, 템플릿 틀을 사용해 모든T가int로 바뀐Pair<int>구조체를 만들어냅니다. - 다음으로
Pair<double>객체를 만듭니다. 마찬가지로T가double로 바뀐Pair<double>구조체를 찍어냅니다. - 마지막
p3의 경우,Pair<double>이 이미 방금 전에 만들어졌기 때문에 컴파일러는 새로 만들지 않고 기존에 만들어둔 것을 재사용합니다.
다음은 템플릿 인스턴스화가 모두 끝난 후, 컴파일러가 실제로 변환해서 컴파일하게 되는 내부 코드의 모습입니다.
위 예제와 완전히 동일하게 작동합니다.
#include <iostream>
// Pair 클래스 템플릿 선언
// (더 이상 사용되지 않으므로 정의가 필요 없습니다)
template <typename T>
struct Pair;
// Pair<int>의 모습을 명시적으로 정의
template <> // 컴파일러에게 이것이 템플릿 매개변수가 없는 템플릿 타입임을 알려줌
struct Pair<int>
{
int first{};
int second{};
};
// Pair<double>의 모습을 명시적으로 정의
template <> // 컴파일러에게 이것이 템플릿 매개변수가 없는 템플릿 타입임을 알려줌
struct Pair<double>
{
double first{};
double second{};
};
int main()
{
Pair<int> p1{ 5, 6 }; // Pair<int>를 인스턴스화하고 객체 p1 생성
std::cout << p1.first << ' ' << p1.second << '\n';
Pair<double> p2{ 1.2, 3.4 }; // Pair<double>를 인스턴스화하고 객체 p2 생성
std::cout << p2.first << ' ' << p2.second << '\n';
Pair<double> p3{ 7.8, 9.0 }; // 이전에 정의된 Pair<double>을 사용하여 객체 p3 생성
std::cout << p3.first << ' ' << p3.second << '\n';
return 0;
}
이 코드를 직접 컴파일해 보시면 예상대로 잘 작동하는 것을 확인할 수 있습니다!
심화 학습자를 위해
위 예제는 '클래스 템플릿 특수화(Class template specialization)'라는 기능을 사용하고 있습니다(향후 26.4 레슨 에서 다룹니다).
지금 당장 이 기능이 어떻게 작동하는지 알 필요는 없습니다.
함수에서 클래스 템플릿 사용하기
이제 다시 max() 함수가 여러 타입에서 작동하게 만들었던 과제로 돌아가 봅시다.
컴파일러는 Pair<int>와 Pair<double>을 완전히 별개의 타입으로 취급하기 때문에, 매개변수 타입이 다른 오버로딩 함수를 사용할 수 있습니다.
constexpr int max(Pair<int> p)
{
return (p.first < p.second ? p.second : p.first);
}
constexpr double max(Pair<double> p) // 정상 작동: 매개변수 타입으로 구분되는 오버로딩된 함수
{
return (p.first < p.second ? p.second : p.first);
}
이렇게 하면 컴파일은 잘 되지만, 중복 문제는 여전히 해결되지 않습니다.
우리가 진짜로 원하는 건 어떤 타입의 Pair가 들어오든 다 처리해 주는 단 하나의 함수 입니다.
즉, 템플릿 타입 T를 사용하는 Pair<T>를 매개변수로 받는 함수가 필요합니다. 이를 위해서는 함수 템플릿 이 제격이죠!
max()를 함수 템플릿으로 구현한 전체 예제는 다음과 같습니다.
#include <iostream>
template <typename T>
struct Pair
{
T first{};
T second{};
};
template <typename T>
constexpr T max(Pair<T> p)
{
return (p.first < p.second ? p.second : p.first);
}
int main()
{
Pair<int> p1{ 5, 6 };
std::cout << max<int>(p1) << " is larger\n"; // 명시적으로 max<int> 호출
Pair<double> p2{ 1.2, 3.4 };
std::cout << max(p2) << " is larger\n"; // 템플릿 인수 연역(추론)을 사용하여 max<double> 호출 (권장)
return 0;
}
max() 함수 템플릿은 아주 직관적입니다. Pair<T>를 전달받고 싶기 때문에, 컴파일러에게 T가 무엇인지 알려주어야 합니다. 따라서 템플릿 타입 T를 정의하는 템플릿 매개변수 선언으로 함수를 시작합니다. 그러면 이 T를 함수의 반환 타입으로도 쓰고, 매개변수인 Pair<T>의 템플릿 타입으로도 쓸 수 있습니다.
max() 함수에 Pair<int> 인수를 넣어 호출하면, 컴파일러는 이 함수 템플릿에서 T를 int로 바꿔서 int max<int>(Pair<int>)라는 실제 함수를 만들어냅니다. 아래는 이 상황에서 컴파일러가 실제로 만들어내는 코드입니다.
template <>
constexpr int max(Pair<int> p)
{
return (p.first < p.second ? p.second : p.first);
}
모든 함수 템플릿 호출과 마찬가지로, max<int>(p1)처럼 템플릿 타입을 명시적으로 지정해 주거나, max(p2)처럼 템플릿 인수 연역(Type deduction) 기능을 통해 컴파일러가 알아서 추론하게 내버려 둘 수도 있습니다. (후자를 권장합니다!)
템플릿 타입 멤버와 일반 멤버가 함께 있는 클래스 템플릿
클래스 템플릿 내부에서 일부 멤버는 템플릿 타입(T)을 사용하고, 다른 멤버는 일반 타입(예: int)을 사용할 수도 있습니다.
template <typename T>
struct Foo
{
T first{}; // first는 T가 대체되는 어떤 타입이든 가질 수 있습니다
int second{}; // second는 T의 타입과 상관없이 항상 int 타입을 가집니다
};
직관적으로 이해되는 그대로 작동합니다. first의 자료형은 템플릿 타입 T에 따라 달라지며, second는 무조건 int 자료형이 됩니다.
다중 템플릿 타입을 가진 클래스 템플릿
클래스 템플릿은 여러 개의 템플릿 타입을 가질 수도 있습니다. 예를 들어, Pair 클래스의 두 멤버 변수가 서로 다른 자료형을 가질 수 있게 만들고 싶다면, 두 개의 템플릿 타입을 지정하면 됩니다.
#include <iostream>
template <typename T, typename U>
struct Pair
{
T first{};
U second{};
};
template <typename T, typename U>
void print(Pair<T, U> p)
{
std::cout << '[' << p.first << ", " << p.second << ']';
}
int main()
{
Pair<int, double> p1{ 1, 2.3 }; // int와 double을 담고 있는 쌍(pair)
Pair<double, int> p2{ 4.5, 6 }; // double과 int를 담고 있는 쌍(pair)
Pair<int, int> p3{ 7, 8 }; // 두 개의 int를 담고 있는 쌍(pair)
print(p2);
return 0;
}
여러 템플릿 타입을 정의하려면 꺾쇠괄호 안에 원하는 타입들을 쉼표(,)로 구분해서 적어줍니다. 위 예제에서는 T와 U라는 두 개의 템플릿 타입을 정의했습니다. 위 코드의 p1, p2처럼 T와 U에 들어갈 실제 타입을 서로 다르게 지정할 수도 있고, p3처럼 동일한 타입으로 지정할 수도 있습니다.
둘 이상의 클래스 타입과 호환되는 함수 템플릿 만들기
위 예제의 print() 함수 템플릿을 다시 살펴봅시다.
template <typename T, typename U>
void print(Pair<T, U> p)
{
std::cout << '[' << p.first << ", " << p.second << ']';
}
함수 매개변수 타입을 아예 Pair<T, U>로 명시해 놓았기 때문에, 이 함수는 Pair<T, U> 타입이거나 그 타입으로 변환될 수 있는 인수만 받을 수 있습니다. 함수를 Pair<T, U> 전용으로 쓰고 싶을 때는 이 방식이 아주 이상적입니다.
하지만 때로는 '조건만 맞으면 어떤 타입의 클래스라도 다 받아주는' 범용 함수 템플릿을 만들고 싶을 때가 있습니다.
이럴 때는 매개변수 자리에 구체적인 클래스 대신 타입 템플릿 매개변수를 사용하면 됩니다.
#include <iostream>
template <typename T, typename U>
struct Pair
{
T first{};
U second{};
};
struct Point
{
int first{};
int second{};
};
template <typename T>
void print(T p) // 타입 템플릿 매개변수는 어떤 타입과도 일치합니다
{
std::cout << '[' << p.first << ", " << p.second << ']'; // 타입에 first와 second 멤버가 있어야만 컴파일됩니다
}
int main()
{
Pair<double, int> p1{ 4.5, 6 };
print(p1); // print(Pair<double, int>)와 일치
std::cout << '\n';
Point p2 { 7, 8 };
print(p2); // print(Point)와 일치
std::cout << '\n';
return 0;
}
위 예제의 print() 함수는 이제 단일 타입 템플릿 매개변수(T)만을 가집니다. 즉 어떤 타입이 들어오든 다 매칭해 줍니다. 대신 함수 내부에서 .first와 .second에 접근하므로, 인수로 넘어온 타입 내부에 first와 second라는 멤버 변수만 존재하면 어떤 클래스/구조체든 문제없이 컴파일됩니다. Pair 객체와 Point 객체 모두를 성공적으로 출력하는 것을 볼 수 있습니다.
주의할 점이 하나 있습니다. 다음 코드를 봐주세요.
template <typename T, typename U>
struct Pair // Pair라는 이름의 클래스 타입을 정의
{
T first{};
U second{};
};
template <typename Pair> // Pair라는 이름의 타입 템플릿 매개변수를 정의 (Pair 클래스 타입을 가림)
void print(Pair p) // 이것은 클래스 타입 Pair가 아니라 템플릿 매개변수 Pair를 참조합니다
{
std::cout << '[' << p.first << ", " << p.second << ']';
}
얼핏 보면 이 print() 함수는 우리가 만들어둔 Pair 클래스 전용 함수처럼 보일 수 있습니다. 하지만 이 함수는 직전 예제(매개변수 이름을 T로 지었던 예제)와 완전히 똑같이 작동하며, 모든 타입 과 일치합니다.
문제는 템플릿 매개변수 이름을 Pair라고 지어버리면서 발생합니다. 이 이름이 전역 스코프에 있던 구조체 이름인 Pair를 가려버립니다(Shadowing). 따라서 함수 템플릿 안에서 Pair는 더 이상 구조체 이름이 아니라 임의의 템플릿 타입 변수로 취급됩니다. 템플릿 타입은 어떤 타입과도 매칭되므로, 이것은 우리가 만든 Pair 구조체뿐만 아니라 온갖 타입과 다 매칭되어 버립니다!
이것이 템플릿 매개변수 이름을 T, U, N처럼 짧고 단순하게 지어야 하는 이유입니다. 기존 클래스 이름과 겹쳐서 가려버릴 확률을 줄일 수 있으니까요.
std::pair
이렇게 두 개의 데이터를 쌍으로 묶어서 다루는 일은 실무에서 아주 흔합니다. 그래서 C++ 표준 라이브러리는 <utility> 헤더 안에 std::pair 라는 클래스 템플릿을 이미 제공하고 있습니다. 이 기능은 방금 우리가 만들었던 다중 템플릿 방식의 Pair 클래스와 완전히 동일합니다!
사실 우리가 짠 코드를 std::pair로 깔끔하게 바꿀 수 있습니다.
#include <iostream>
#include <utility>
template <typename T, typename U>
void print(std::pair<T, U> p)
{
// std::pair의 멤버는 `first`와 `second`라는 미리 정의된 이름을 가집니다
std::cout << '[' << p.first << ", " << p.second << ']';
}
int main()
{
std::pair<int, double> p1{ 1, 2.3 }; // int와 double을 담고 있는 쌍(pair)
std::pair<double, int> p2{ 4.5, 6 }; // double과 int를 담고 있는 쌍(pair)
std::pair<int, int> p3{ 7, 8 }; // 두 개의 int를 담고 있는 쌍(pair)
print(p2);
return 0;
}
이 레슨에서는 내부 원리를 이해하기 위해 Pair 클래스를 직접 만들어 보았지만, 실제 프로그래밍을 할 때는 직접 만드는 것보다 표준 라이브러리인 std::pair를 사용하는 것을 강력히 권장합니다.
여러 파일에서 클래스 템플릿 사용하기
함수 템플릿과 마찬가지로, 클래스 템플릿도 보통 헤더 파일(.h) 에 정의합니다. 그래야 코드가 필요한 여러 파일에서 #include 하여 사용할 수 있기 때문입니다. 템플릿 정의와 타입 정의는 C++의 '단일 정의 원칙(One-definition rule)'의 예외가 적용되므로 여러 파일에서 포함되어도 충돌을 일으키지 않습니다.
pair.h:
#ifndef PAIR_H
#define PAIR_H
template <typename T>
struct Pair
{
T first{};
T second{};
};
template <typename T>
constexpr T max(Pair<T> p)
{
return (p.first < p.second ? p.second : p.first);
}
#endif
foo.cpp:
#include "pair.h"
#include <iostream>
void foo()
{
Pair<int> p1{ 1, 2 };
std::cout << max(p1) << " is larger\n";
}
main.cpp:
#include "pair.h"
#include <iostream>
void foo(); // 함수 foo()에 대한 전방 선언(forward declaration)
int main()
{
Pair<double> p2 { 3.4, 5.6 };
std::cout << max(p2) << " is larger\n";
foo();
return 0;
}
13.14 — 클래스 템플릿 인수 추론 (CTAD) 및 추론 가이드
클래스 템플릿 인수 추론 (CTAD) (C++17)
C++17부터는 클래스 템플릿으로 객체를 생성할 때, 컴파일러가 객체의 초기값을 보고 템플릿 타입을 자동으로 알아낼(추론할) 수 있습니다. 이를 클래스 템플릿 인수 추론 (Class template argument deduction), 줄여서 CTAD 라고 부릅니다. 예를 들어 보겠습니다.
#include <utility> // std::pair를 사용하기 위해
int main()
{
std::pair<int, int> p1{ 1, 2 }; // 클래스 템플릿 std::pair<int, int>를 명시적으로 지정 (C++11 이후)
std::pair p2{ 1, 2 }; // 초기값으로부터 std::pair<int, int>를 추론하기 위해 CTAD 사용 (C++17)
return 0;
}
CTAD 는 템플릿 인수 목록이 아예 없을 때만 동작합니다. 따라서 다음 두 가지 경우는 모두 에러가 발생합니다.
#include <utility> // std::pair를 사용하기 위해
int main()
{
std::pair<> p1 { 1, 2 }; // 에러: 템플릿 인수가 너무 적음, 두 인수 모두 추론되지 않음
std::pair<int> p2 { 3, 4 }; // 에러: 템플릿 인수가 너무 적음, 두 번째 인수가 추론되지 않음
return 0;
}
저자의 노트
앞으로 이 사이트의 많은 강의에서 CTAD 를 사용할 예정입니다. 만약 C++14(또는 그 이전) 표준으로 예제 코드를 컴파일한다면 템플릿 인수가 빠졌다는 에러가 발생할 것입니다. 컴파일이 성공하게 하려면 예제 코드에 템플릿 인수를 직접 추가해 주어야 합니다.
CTAD 도 일종의 타입 추론이기 때문에, 리터럴 접미사(literal suffixes)를 사용해서 추론되는 타입을 바꿀 수 있습니다.
#include <utility> // std::pair를 사용하기 위해
int main()
{
std::pair p1 { 3.4f, 5.6f }; // pair<float, float>로 추론됨
std::pair p2 { 1u, 2u }; // pair<unsigned int, unsigned int>로 추론됨
return 0;
}
템플릿 인수 추론 가이드 (C++17)
대부분의 경우 CTAD 는 별다른 설정 없이도 잘 작동합니다.
하지만 어떤 경우에는 컴파일러가 템플릿 인수를 올바르게 추론할 수 있도록 약간의 힌트를 주어야 할 때가 있습니다.
위에서 본 std::pair 예제와 거의 똑같이 생긴 다음 프로그램이 오직 C++17에서만 컴파일되지 않는다는 사실에 놀라실 수도 있습니다.
// 우리만의 Pair 타입 정의
template <typename T, typename U>
struct Pair
{
T first{};
U second{};
};
int main()
{
Pair<int, int> p1{ 1, 2 }; // 성공: 템플릿 인수를 명시적으로 지정함
Pair p2{ 1, 2 }; // C++17에서 컴파일 에러 발생 (C++20에서는 성공)
return 0;
}
이 코드를 C++17에서 컴파일하면 "클래스 템플릿 인수 추론 실패"나 "템플릿 인수를 추론할 수 없음" 또는 "적합한 생성자나 추론 가이드가 없음"과 같은 에러가 발생할 것입니다.
이런 에러가 나는 이유는, C++17에서는 CTAD 가 집합체(aggregate) 클래스 템플릿에 대해 템플릿 인수를 어떻게 추론해야 하는지 모르기 때문입니다. 이 문제를 해결하기 위해 컴파일러에게 추론 가이드 (deduction guide) 를 제공하여, 특정 클래스 템플릿의 인수를 어떻게 추론해야 하는지 알려줄 수 있습니다.
다음은 추론 가이드를 추가한 동일한 프로그램입니다.
template <typename T, typename U>
struct Pair
{
T first{};
U second{};
};
// 다음은 우리가 만든 Pair를 위한 추론 가이드입니다 (C++17에서만 필요함)
// T와 U 타입의 인수로 초기화된 Pair 객체는 Pair<T, U>로 추론되어야 합니다
template <typename T, typename U>
Pair(T, U) -> Pair<T, U>;
int main()
{
Pair<int, int> p1{ 1, 2 }; // 클래스 템플릿 Pair<int, int>를 명시적으로 지정 (C++11 이후)
Pair p2{ 1, 2 }; // 초기값으로부터 Pair<int, int>를 추론하기 위해 CTAD 사용 (C++17)
return 0;
}
이 예제는 C++17에서 정상적으로 컴파일됩니다. 우리가 만든 Pair 클래스의 추론 가이드는 꽤 단순하지만, 어떻게 작동하는지 조금 더 자세히 살펴보겠습니다.
// 다음은 우리가 만든 Pair를 위한 추론 가이드입니다 (C++17에서만 필요함)
// T와 U 타입의 인수로 초기화된 Pair 객체는 Pair<T, U>로 추론되어야 합니다
template <typename T, typename U>
Pair(T, U) -> Pair<T, U>;
첫째, Pair 클래스에서 사용한 것과 똑같은 템플릿 타입 정의를 사용합니다. 우리의 추론 가이드가 컴파일러에게 Pair<T, U>의 타입을 추론하는 방법을 알려주려면 T와 U가 무엇인지(템플릿 타입이라는 것을) 정의해야 하므로 이는 매우 자연스러운 일입니다.
둘째, 화살표 오른쪽에는 우리가 컴파일러의 추론을 도와줄 목적지 타입을 적습니다. 이 경우 컴파일러가 Pair<T, U> 타입 객체의 템플릿 인수를 추론할 수 있게 하고 싶으므로, 그 형태를 그대로 적어줍니다.
마지막으로, 화살표 왼쪽에는 컴파일러가 어떤 형태의 선언을 찾아야 하는지 알려줍니다. 여기서는 Pair라는 이름의 객체가 두 개의 인수(T 타입 하나, U 타입 하나)를 가진 선언을 찾으라고 알려주는 것입니다. 이를 Pair(T t, U u)처럼 적을 수도 있지만, 매개변수 이름인 t와 u는 실제로 사용하지 않기 때문에 이름을 생략해도 괜찮습니다.
요약하자면, 컴파일러가 두 개의 인수(각각 T와 U 타입)를 가지는 Pair 객체의 선언을 보게 되면 그 타입을 Pair<T, U>로 추론하라고 알려주는 것입니다.
따라서 프로그램 안에서 컴파일러가 Pair p2{ 1, 2 };라는 정의를 보게 되면, "아, 이건 Pair의 선언이고 int 타입 인수가 두 개 있네. 그러니까 추론 가이드를 사용해서 이것을 Pair<int, int>로 추론해야겠다."라고 생각하게 됩니다.
다음은 단일 템플릿 타입을 사용하는 Pair의 비슷한 예시입니다.
template <typename T>
struct Pair
{
T first{};
T second{};
};
// 다음은 우리가 만든 Pair를 위한 추론 가이드입니다 (C++17에서만 필요함)
// T와 T 타입의 인수로 초기화된 Pair 객체는 Pair<T>로 추론되어야 합니다
template <typename T>
Pair(T, T) -> Pair<T>;
int main()
{
Pair<int> p1{ 1, 2 }; // 클래스 템플릿 Pair<int>를 명시적으로 지정 (C++11 이후)
Pair p2{ 1, 2 }; // 초기값으로부터 Pair<int>를 추론하기 위해 CTAD 사용 (C++17)
return 0;
}
이 경우, 우리의 추론 가이드는 Pair(T, T)(T 타입 인수가 두 개인 Pair)를 Pair<T>와 연결해 줍니다.
팁
C++20부터는 컴파일러가 집합체(aggregates)를 위한 추론 가이드를 자동으로 만들어주는 기능이 추가되었습니다. 따라서 추론 가이드는 오직 C++17과의 호환성을 위해서만 필요합니다.
그렇기 때문에 추론 가이드가 없는 버전의Pair도 C++20에서는 잘 컴파일됩니다.
std::pair(그리고 다른 표준 라이브러리 템플릿 타입들)는 미리 정의된 추론 가이드를 포함하고 있습니다. 그래서 우리가 직접 추론 가이드를 제공하지 않아도std::pair를 사용한 처음 예제가 C++17에서 정상적으로 컴파일되었던 것입니다.
고급 독자를 위해
집합체가 아닌(Non-aggregates) 경우에는 생성자가 그 역할을 대신해 주기 때문에 C++17에서도 추론 가이드가 필요하지 않습니다.
기본값이 있는 타입 템플릿 매개변수
함수 매개변수가 기본 인수를 가질 수 있는 것처럼, 템플릿 매개변수에도 기본값을 줄 수 있습니다. 이 기본값들은 템플릿 매개변수가 직접 명시되지 않았고 추론할 수도 없을 때 사용됩니다.
다음은 위에서 작성한 Pair<T, U> 클래스 템플릿 프로그램을 수정하여 타입 템플릿 매개변수 T와 U의 기본값을 int 타입으로 설정한 예시입니다.
template <typename T=int, typename U=int> // T와 U의 기본값을 int 타입으로 설정
struct Pair
{
T first{};
U second{};
};
template <typename T, typename U>
Pair(T, U) -> Pair<T, U>;
int main()
{
Pair<int, int> p1{ 1, 2 }; // 클래스 템플릿 Pair<int, int>를 명시적으로 지정 (C++11 이후)
Pair p2{ 1, 2 }; // 초기값으로부터 Pair<int, int>를 추론하기 위해 CTAD 사용 (C++17)
Pair p3; // 기본값인 Pair<int, int>를 사용
return 0;
}
p3를 정의할 때 타입 템플릿 매개변수에 대한 타입을 직접 명시하지 않았고, 타입을 추론할 수 있는 초기값도 없습니다. 따라서 컴파일러는 지정된 기본값을 사용하게 되며, 결과적으로 p3는 Pair<int, int> 타입이 됩니다.
비정적 멤버 초기화에서는 CTAD가 동작하지 않습니다
비정적 멤버 초기화(non-static member initialization)를 사용해서 클래스 타입의 멤버를 초기화할 때는 이 상황에서 CTAD 가 동작하지 않습니다. 반드시 모든 템플릿 인수를 직접 명시해야 합니다.
#include <utility> // std::pair를 사용하기 위해
struct Foo
{
std::pair<int, int> p1{ 1, 2 }; // 성공, 템플릿 인수가 명시적으로 지정됨
std::pair p2{ 1, 2 }; // 컴파일 에러, 이 문맥에서는 CTAD를 사용할 수 없음
};
int main()
{
std::pair p3{ 1, 2 }; // 성공, 여기서는 CTAD를 사용할 수 있음
return 0;
}
함수 매개변수에서는 CTAD가 동작하지 않습니다
CTAD는 클래스 템플릿 인수(argument) 추론의 약자이며, 클래스 템플릿 매개변수(parameter) 추론이 아닙니다. 따라서 템플릿 매개변수의 타입이 아닌, 템플릿 인수의 타입만 추론합니다.
그러므로 함수 매개변수에는 CTAD 를 사용할 수 없습니다.
#include <iostream>
#include <utility>
void print(std::pair p) // 컴파일 에러, 여기서는 CTAD를 사용할 수 없음
{
std::cout << p.first << ' ' << p.second << '\n';
}
int main()
{
std::pair p { 1, 2 }; // p는 std::pair<int, int>로 추론됨
print(p);
return 0;
}
이런 경우에는 대신 템플릿을 사용해야 합니다.
#include <iostream>
#include <utility>
template <typename T, typename U>
void print(std::pair<T, U> p)
{
std::cout << p.first << ' ' << p.second << '\n';
}
int main()
{
std::pair p { 1, 2 }; // p는 std::pair<int, int>로 추론됨
print(p);
return 0;
}
13.15 — 템플릿 별칭 (Alias templates)
10.7 레슨 -- typedef와 타입 별칭(Type aliases)에서는 기존 타입에 대해 별칭을 지정하는 방법에 대해 알아보았습니다.
모든 템플릿 인수가 명확하게 지정된 클래스 템플릿의 별칭을 만드는 것은 일반적인 타입 별칭을 만드는 것과 똑같이 작동합니다.
#include <iostream>
template <typename T>
struct Pair
{
T first{};
T second{};
};
template <typename T>
void print(const Pair<T>& p)
{
std::cout << p.first << ' ' << p.second << '\n';
}
int main()
{
using Point = Pair<int>; // 일반적인 타입 별칭 만들기
Point p { 1, 2 }; // 컴파일러는 이것을 Pair<int>로 바꿉니다.
print(p);
return 0;
}
이러한 별칭은 (함수 내부처럼) 지역적으로 정의할 수도 있고, 전역적으로 정의할 수도 있습니다.
템플릿 별칭 (Alias templates)
때로는 템플릿 클래스의 별칭을 만들 때 템플릿 인수를 미리 다 정해두지 않고, 나중에 별칭을 사용하는 사람이 직접 인수를 넣도록 비워두고 싶을 때가 있습니다. 이럴 때 템플릿 별칭(Alias template) 을 정의할 수 있습니다. 템플릿 별칭은 말 그대로 타입 별칭을 찍어내는 템플릿이라고 생각하면 쉽습니다. 일반 타입 별칭이 아예 새로운 타입을 만드는 것이 아니듯, 템플릿 별칭도 완전히 새로운 독립적인 타입을 정의하는 것은 아닙니다.
작동 방식을 보여주는 예제는 다음과 같습니다.
#include <iostream>
template <typename T>
struct Pair
{
T first{};
T second{};
};
// 여기에 템플릿 별칭이 있습니다.
// 템플릿 별칭은 반드시 전역 스코프(global scope)에 정의해야 합니다.
template <typename T>
using Coord = Pair<T>; // Coord는 Pair<T>의 별칭입니다.
// print 함수 템플릿은 Coord의 템플릿 매개변수 T가 '타입 템플릿 매개변수'라는 것을 알아야 합니다.
template <typename T>
void print(const Coord<T>& c)
{
std::cout << c.first << ' ' << c.second << '\n';
}
int main()
{
Coord<int> p1 { 1, 2 }; // C++20 이전: 모든 타입 템플릿 인수를 명시적으로 지정해야 합니다.
Coord p2 { 1, 2 }; // C++20 이후: CTAD가 작동하는 상황에서는 '템플릿 별칭 추론(alias template deduction)'을 사용하여 인수를 알아낼 수 있습니다.
std::cout << p1.first << ' ' << p1.second << '\n';
print(p2);
return 0;
}
이 예제에서는 Pair<T>의 별칭으로 Coord라는 템플릿 별칭을 정의했습니다. 여기서 타입 템플릿 매개변수 T는 Coord 별칭을 사용하는 사용자가 나중에 정하게 됩니다. Coord는 템플릿 별칭이고, Coord<T>는 Pair<T>를 위해 생성된(인스턴스화된) 타입 별칭입니다. 한 번 정의하고 나면, Pair를 쓸 자리에 Coord를 쓸 수 있고, Pair<T>를 쓸 자리에 Coord<T>를 쓸 수 있습니다.
이 예제에서 기억해 둘 만한 몇 가지 중요한 점이 있습니다.
- 첫째, 블록(중괄호) 안에서 정의할 수 있는 일반적인 타입 별칭과는 다르게, 템플릿 별칭은 (다른 모든 템플릿과 마찬가지로) 반드시 전역 스코프(global scope)에서 정의해야 합니다.
- 둘째, C++20 이전에는 템플릿 별칭으로 객체를 생성할 때 템플릿 인수를 직접 명확하게 적어주어야 했습니다. 하지만 C++20부터는 템플릿 별칭 추론(alias template deduction) 을 사용할 수 있습니다. 이를 통해 별칭이 지정된 원래 타입이 CTAD(클래스 템플릿 인수 추론)를 지원하는 경우라면, 초기화 값만 보고도 템플릿 인수의 타입을 자동으로 알아낼 수 있습니다.
- 셋째, CTAD는 함수 매개변수에서는 작동하지 않습니다. 따라서 템플릿 별칭을 함수 매개변수로 사용할 때는, 템플릿 별칭이 사용할 템플릿 인수를 반드시 명확하게 정의해주어야 합니다. 즉, 다음과 같이 작성해야 합니다.
template <typename T>
void print(const Coord<T>& c)
{
std::cout << c.first << ' ' << c.second << '\n';
}
다음과 같이 쓰면 안 됩니다.
void print(const Coord& c) // 작동하지 않습니다. 템플릿 인수가 빠져 있습니다.
{
std::cout << c.first << ' ' << c.second << '\n';
}
이 규칙은 Coord나 Coord<T> 대신에 원래 타입인 Pair나 Pair<T>를 사용할 때의 규칙과 전혀 다르지 않습니다.
13.y — 언어 레퍼런스(Reference) 사용하기
프로그래밍 언어(특히 C++) 학습 여정의 어느 단계에 있든, LearnCpp.com이 C++를 배우거나 무언가를 찾아보기 위해 사용하는 유일한 리소스일 수 있습니다. LearnCpp.com은 초보자에게 친숙한 방식으로 개념을 설명하도록 설계되었지만, 언어의 모든 측면을 다룰 수는 없습니다. 이 튜토리얼에서 다루는 주제를 벗어나 탐색을 시작하면, 필연적으로 이 튜토리얼에서 답하지 않는 질문에 부딪히게 될 것입니다. 이 경우 외부 리소스를 활용해야 합니다.
그런 리소스 중 하나가 질문을 올릴 수 있는(또는 더 좋게는, 다른 사람이 먼저 한 동일한 질문의 답변을 읽을 수 있는) Stack Overflow입니다. 하지만 때로는 레퍼런스 가이드(Reference guide, 참조 설명서)를 먼저 살펴보는 것이 더 나을 수 있습니다. 가장 중요한 주제에 집중하고 학습을 더 쉽게 하기 위해 비공식적이고 일반적인 언어를 사용하는 튜토리얼과 달리, 레퍼런스 가이드는 공식적인 용어를 사용하여 C++를 정확하게 설명합니다. 이 때문에 레퍼런스 자료는 포괄적이고 정확하며... 이해하기 어렵습니다.
이 레슨에서는 3가지 예제를 조사하면서 레슨 전반에 걸쳐 언급하는 인기 있는 표준 레퍼런스인 cppreference를 사용하는 방법을 보여드리겠습니다.
개요 (Overview)
Cppreference는 핵심 언어와 라이브러리에 대한 개요(overview)로 여러분을 맞이합니다.
여기서부터 cppreference가 제공하는 모든 것에 접근할 수 있지만, 검색 기능이나 검색 엔진을 사용하는 것이 더 쉽습니다. 이 개요는 LearnCpp.com의 튜토리얼을 마친 후 라이브러리를 더 깊이 파고들고, 아직 알지 못했던 언어의 다른 기능들을 확인하기 위해 방문하기에 아주 좋은 곳입니다.
표의 상단 절반은 현재 언어에 포함된 기능을 보여주는 반면, 하단 절반은 기술 사양(technical specifications)을 보여주는데, 이는 향후 C++ 버전에 추가될 수도 있고 추가되지 않을 수도 있는 기능이거나, 이미 언어에 부분적으로 수용된 기능입니다. 이는 곧 어떤 새로운 기능이 출시될지 확인하고 싶을 때 유용할 수 있습니다.
C++11부터 cppreference는 모든 기능에 해당 기능이 추가된 언어 표준 버전을 표시합니다. 표준 버전은 위 이미지의 일부 링크 옆에 보이는 작은 녹색 숫자입니다. 버전 번호가 없는 기능은 C++98/03부터 사용 가능했던 기능입니다. 버전 번호는 개요뿐만 아니라 cppreference의 모든 곳에 있으며, 특정 C++ 버전에서 무엇을 사용할 수 있고 없는지 정확히 알려줍니다.
경고 (Warning)
검색 엔진을 사용하는데 기술 사양이 막 표준으로 채택된 경우, 공식 레퍼런스 대신 기술 사양 문서로 연결될 수 있으며, 두 문서의 내용이 다를 수 있습니다.
팁 (Tip)
Cppreference는 C++와 C 모두를 위한 레퍼런스입니다. C++는 C와 일부 함수 이름을 공유하기 때문에 무언가를 검색한 후 C 레퍼런스 페이지에 접속하게 될 수도 있습니다. cppreference 상단의 URL과 탐색 모음(navigation bar)은 현재 C 또는 C++ 레퍼런스를 탐색하고 있는지 항상 보여줍니다.
std::string::length
이전 레슨에서 배운 함수인 문자열의 길이를 반환하는 std::string::length를 조사하는 것부터 시작하겠습니다.
cppreference 우측 상단에서 "string"을 검색해 보세요. 그러면 타입과 함수들의 긴 목록이 나타나며, 지금은 가장 위에 있는 것만 관련이 있습니다.
곧바로 "string length"를 검색할 수도 있었지만, 이번 레슨에서 가능한 많은 것을 보여주기 위해 긴 경로를 택하고 있습니다. "Strings library"를 클릭하면 C++가 지원하는 다양한 종류의 문자열에 대해 이야기하는 페이지로 이동합니다.
"std::basic_string" 섹션 아래를 보면 typedef 목록을 볼 수 있고, 그 목록 안에 std::string이 있습니다.
"std::string"을 클릭하면 std::basic_string 페이지로 연결됩니다. std::string은 std::basic_string<char>의 typedef이기 때문에 std::string에 대한 별도의 페이지는 없으며, 이는 typedef 목록에서 다시 확인할 수 있습니다.
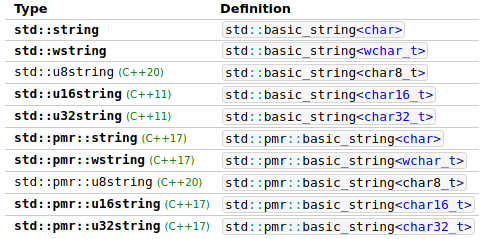
<char>는 문자열의 각 문자가 char 타입임을 의미합니다. C++는 다른 문자 타입을 사용하는 여러 문자열을 제공한다는 점에 유의하세요. 이들은 ASCII 대신 유니코드(Unicode)를 사용할 때 유용할 수 있습니다.
같은 페이지를 조금 더 내려가면 멤버 함수 목록(타입이 갖는 동작)이 있습니다. 어떤 타입으로 무엇을 할 수 있는지 알고 싶다면 이 목록이 매우 편리합니다. 이 목록에서 length(그리고 size) 행을 찾을 수 있습니다.
링크를 따라가면 둘 다 동일한 작업을 수행하는 length와 size의 상세 함수 설명으로 이동합니다.
각 페이지의 상단은 해당 기능과 구문, 오버로드(overloads) 또는 선언에 대한 짧은 요약으로 시작합니다.
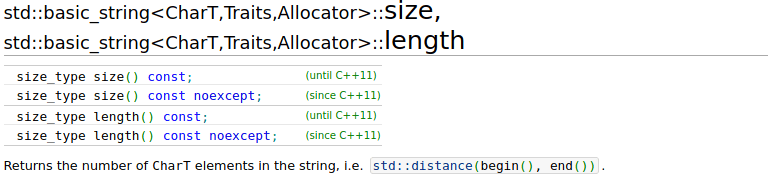
페이지 제목은 모든 템플릿 매개변수와 함께 클래스와 함수의 이름을 보여줍니다. 이 부분은 무시해도 됩니다. 제목 아래에는 다양한 함수 오버로드(같은 이름을 공유하는 여러 버전의 함수)와 그것들이 어떤 언어 표준에 적용되는지 볼 수 있습니다.
그 아래에서, 함수가 받는 매개변수들과 반환값이 의미하는 바를 볼 수 있습니다.
std::string::length는 간단한 함수이기 때문에 이 페이지에는 내용이 많지 않습니다. 많은 페이지에서 해당 기능의 사용 예제를 보여주며, 이 페이지도 예외는 아닙니다.
C++를 여전히 배우고 있는 동안에는 예제에 아직 본 적 없는 기능들이 있을 것입니다. 예제가 충분히 있다면, 아마도 함수가 어떻게 사용되고 무엇을 하는지 아이디어를 얻을 수 있을 만큼은 이해할 수 있을 것입니다. 예제가 너무 복잡하다면 다른 곳에서 예제를 검색하거나, 이해하지 못하는 부분의 레퍼런스를 읽을 수 있습니다(예제에서 함수와 타입을 클릭하여 무엇을 하는지 볼 수 있습니다).
이제 우리는 std::string::length가 무엇을 하는지 알게 되었습니다. 비록 전부터 알고 있었지만 말이죠. 새로운 것을 한번 살펴봅시다!
std::cin.ignore
레슨 9.5 -- std::cin과 잘못된 입력 처리에서, 줄바꿈까지 모든 것을 무시하는 데 사용하는 std::cin.ignore에 대해 이야기했습니다. 이 함수의 매개변수 중 하나는 길고 장황한 값입니다. 그게 다시 뭐였죠? 그냥 큰 숫자를 사용하면 안 되나요? 어쨌든 이 인수는 무슨 역할을 할까요? 알아봅시다!
cppreference 검색창에 "std::cin.ignore"를 입력하면 다음과 같은 결과가 나옵니다.
std::cin, std::wcin- 우리는 단순한std::cin이 아니라.ignore를 원합니다.std::basic_istream<CharT,Traits>::ignore- 으, 이게 뭐죠? 일단 건너뜁시다.std::ignore- 아니요, 그게 아닙니다.std::basic_istream- 이것도 아닙니다.
검색 결과에 원하는게 없네요, 이제 어쩌죠? std::cin으로 이동하여 거기서부터 찾아봅시다. 해당 페이지에 즉시 눈에 띄는 것은 없습니다. 상단에서 std::cin 및 std::wcin의 선언을 볼 수 있고, std::cin을 사용하기 위해 어떤 헤더를 포함해야 하는지 알려줍니다.

std::cin이 std::istream 타입의 객체라는 것을 알 수 있습니다. std::istream 링크를 따라가 봅시다.
잠깐! 검색 엔진에서 "std::cin.ignore"를 검색했을 때 std::basic_istream을 본 적이 있습니다. 알고 보니 istream은 basic_istream의 typedef 이름이었으므로, 어쩌면 우리의 검색이 아주 틀린 것은 아니었을지도 모릅니다.
페이지를 아래로 스크롤하면 친숙한 함수들이 우리를 맞이합니다.
우리는 operator>>, get, getline, ignore 등 이 함수들 중 다수를 이미 사용해 보았습니다. 해당 페이지를 스크롤하며 std::cin에 또 어떤 것들이 있는지 살펴보세요. 그런 다음, 우리가 관심을 갖고 있는 ignore를 클릭합니다.

페이지 상단에는 함수 시그니처와 함수 및 그 두 매개변수가 하는 역할에 대한 설명이 있습니다. 매개변수 뒤의 = 기호는 기본 인수(default argument)를 나타냅니다(이에 대해서는 레슨 11.5 -- 기본 인수에서 다룹니다). 기본값이 있는 매개변수에 대한 인수를 제공하지 않으면 기본값이 사용됩니다.
첫 번째 항목이 우리의 모든 질문에 답해줍니다. std::numeric_limits<std::streamsize>::max()가 문자 수 확인을 비활성화한다는 점에서 std::cin.ignore에 특별한 의미가 있다는 것을 알 수 있습니다. 이는 std::cin.ignore가 구분 기호를 찾거나 검사할 문자가 부족해질 때까지 계속해서 문자를 무시한다는 것을 의미합니다.
이미 알고 있는 함수의 매개변수나 반환값이 의미하는 바를 잊어버린 경우에는 전체 설명을 다 읽을 필요가 없는 경우가 많습니다. 그러한 상황에서는 매개변수나 반환값에 대한 설명만 읽어도 충분합니다.

매개변수 설명은 간결합니다. std::numeric_limits<std::streamsize>::max()에 대한 특별한 처리나 다른 중지 조건을 포함하고 있지는 않지만, 좋은 리마인더(reminder) 역할을 합니다.
