20.1 — 함수 포인터 (Function Pointers)
이전 레슨에서 포인터는 변수의 주소를 저장하는 변수라고 배웠습니다.
함수 포인터도 이와 아주 비슷해요! 변수 대신 함수를 가리킨다는 점만 빼고요.
다음 함수를 한번 살펴볼까요?
int foo()
{
return 5;
}
foo()라는 이름이 함수의 이름이라는 건 알 수 있습니다.
그런데 이 함수의 '타입'은 무엇일까요? 함수도 자기만의 고유한 타입을 가지고 있습니다.
이 경우, '매개변수(입력값)가 없고 정수(int)를 반환하는 함수 타입'이 됩니다.
변수처럼 함수도 컴퓨터 메모리의 지정된 주소에 살고 있습니다.
함수를 호출하면(실행하면), 컴퓨터는 그 함수가 살고 있는 메모리 주소로 훌쩍 점프해서 코드를 실행합니다.
int foo() // foo를 위한 코드는 메모리 주소 0x002717f0에서 시작합니다
{
return 5;
}
int main()
{
foo(); // 주소 0x002717f0으로 점프합니다
return 0;
}
프로그래밍을 하다 보면 언젠가 이런 아주 흔한 실수를 하게 될 겁니다.
#include <iostream>
int foo() // 코드는 메모리 주소 0x002717f0에서 시작합니다
{
return 5;
}
int main()
{
std::cout << foo << '\n'; // foo()를 호출하려고 했는데, 실수로 foo 그 자체를 출력하고 있습니다!
return 0;
}
foo()를 실행해서 그 결과값을 화면에 띄우는 대신, foo라는 함수 자체를 출력하라고 화면에 던져버린 셈입니다. 이럴 땐 무슨 일이 일어날까요?
괄호 없이 함수 이름만 덩그러니 쓰면, C++은 이 함수를 '함수 포인터(함수의 주소를 들고 있는 녀석)'로 바꿔버립니다. 그러고 나서 출력하려고 시도하는데, C++의 기본 출력 기능은 함수 포인터를 어떻게 화면에 보여줘야 할지 모릅니다. 그래서 규칙에 따라 이 포인터를 참/거짓을 나타내는 bool 타입으로 바꿔버리죠. 함수는 빈 곳을 가리키는 게 아니니까 언제나 '참(true)'으로 평가됩니다. 따라서 결과적으로 화면에는 숫자 1이 출력됩니다.
팁
일부 컴파일러(예: Visual Studio)는 확장 기능을 통해 숫자 1 대신 함수의 진짜 주소를 출력해주기도 합니다:0x002717f0만약 여러분의 컴퓨터에서 주소가 안 나오는데 꼭 확인해보고 싶다면, 함수를 'void 포인터'라는 것으로 강제로 변환해서 출력해볼 수 있습니다.
#include <iostream> int foo() // code starts at memory address 0x002717f0 { return 5; } int main() { std::cout << reinterpret_cast<void*>(foo) << '\n'; // Tell C++ to interpret function foo as a void pointer (implementation-defined behavior) return 0; }다만 이 방법은 시스템 환경마다 다르게 동작할 수 있으니 참고만 하세요.
일반 변수를 가리키는 포인터를 만들 수 있듯이, 함수를 가리키는 포인터도 당연히 만들 수 있습니다. 지금부터 이 '함수 포인터'를 어떻게 만들고 쓰는지 알아볼 텐데요. 사실 이건 조금 어려운 주제라서, C++의 기초만 빠르게 배우고 싶은 초보자라면 나머지 내용은 그냥 가볍게 훑어보거나 건너뛰어도 괜찮습니다!
함수를 가리키는 포인터 만들기
함수 포인터를 만드는 문법은 C++에서 가장 못생긴 문법 중 하나로 꼽힙니다.
// fcnPtr은 매개변수가 없고 정수를 반환하는 함수를 가리키는 포인터입니다
int (*fcnPtr)();
위 코드에서 fcnPtr은 '매개변수가 없고 정수를 반환하는 함수'를 가리킬 수 있는 포인터입니다. 이런 똑같은 모양의 조건을 가진 함수라면 무엇이든 가리킬 수 있어요.
*fcnPtr 주변의 괄호는 아주 중요합니다. 만약 괄호를 빼고 int* fcnPtr()이라고 쓰면, 컴퓨터는 이걸 "매개변수가 없고 정수 포인터(int*)를 반환하는 함수"로 완전히 잘못 오해하게 됩니다.
함수 포인터를 상수처럼 고정하고 싶다면(한 번 가리킨 함수를 못 바꾸게 하려면) const를 별표(*) 뒤에 붙여주면 됩니다.
int (*const fcnPtr)();
만약 const를 맨 앞의 int 앞에 쓰면, "상수 정수(const int)를 반환하는 함수"를 뜻하게 되니 위치를 조심해야 합니다.
팁
함수 포인터 문법은 진짜 눈에 안 들어옵니다. 이런 복잡한 선언을 어떻게 읽어내는지 알려주는 글들이 있으니 참고해 보세요:
함수 포인터에 함수 지정하기
함수 포인터를 처음 만들 때 함수를 바로 연결해줄 수 있고, 나중에 다른 함수로 바꿀 수도 있습니다. 일반 변수처럼 & 기호를 써서 함수의 주소를 가져오면 됩니다.
int foo()
{
return 5;
}
int goo()
{
return 6;
}
int main()
{
int (*fcnPtr)(){ &foo }; // fcnPtr이 foo 함수를 가리키도록 설정합니다
fcnPtr = &goo; // 이제 fcnPtr은 goo 함수를 가리킵니다
return 0;
}
초보자들이 정말 많이 하는 실수가 바로 이것입니다:
fcnPtr = goo();
이렇게 괄호를 써버리면, goo() 함수를 실행한 결과값(숫자 6)을 포인터에 넣으려고 하게 됩니다. 하지만 함수 포인터는 숫자가 아니라 '주소'를 담는 상자이므로 에러가 납니다. 괄호를 꼭 빼고 주소를 넣어주세요.
또한, 포인터의 타입(매개변수와 반환값의 종류)이 가리키려는 함수의 타입과 완벽히 똑같아야 합니다.
// 함수 원형 (미리 모양만 선언해 둔 것)
int foo();
double goo();
int hoo(int x);
// 함수 포인터에 함수 연결해보기
int (*fcnPtr1)(){ &foo }; // 성공
int (*fcnPtr2)(){ &goo }; // 실패 -- 반환하는 타입(int vs double)이 다릅니다!
double (*fcnPtr4)(){ &goo }; // 성공
fcnPtr1 = &hoo; // 실패 -- fcnPtr1은 매개변수가 없는데, hoo()는 매개변수 x가 필요합니다
int (*fcnPtr3)(int){ &hoo }; // 성공
C++은 알아서 눈치껏 함수를 함수 포인터로 변환해 주기 때문에 사실 & 기호를 생략해도 잘 작동합니다. 하지만 함수 포인터를 'void 포인터' 같이 아예 다른 종류로는 바꿀 수 없어요.
// 함수 원형
int foo();
// 함수 포인터 초기화
int (*fcnPtr5)() { foo }; // 성공, foo가 알아서 함수 포인터로 변환됩니다
void* vPtr { foo }; // 실패, (일부 프로그램에선 억지로 될 수도 있지만 원칙적으로 안 됩니다)
아무것도 가리키지 않는다는 뜻의 빈 포인터, nullptr을 넣을 수도 있습니다:
int (*fcnptr)() { nullptr }; // 성공
함수 포인터로 함수 실행하기
함수 포인터의 진짜 쓸모는 바로 그 포인터를 이용해 함수를 짠! 하고 실행하는 겁니다. 여기엔 두 가지 방법이 있어요. 첫 번째는 정석대로 * 기호를 쓰는 방법입니다.
int foo(int x)
{
return x;
}
int main()
{
int (*fcnPtr)(int){ &foo }; // fcnPtr을 foo 함수로 초기화합니다
(*fcnPtr)(5); // fcnPtr을 통해 숫자 5를 넣고 foo 함수를 실행합니다!
return 0;
}
두 번째는 굳이 *를 쓰지 않고 자연스럽게 부르는 방법입니다.
int foo(int x)
{
return x;
}
int main()
{
int (*fcnPtr)(int){ &foo }; // fcnPtr을 foo 함수로 초기화합니다
fcnPtr(5); // fcnPtr을 통해 숫자 5를 넣고 foo 함수를 실행합니다!
return 0;
}
보시다시피 두 번째 방법이 우리가 평소에 함수를 부르던 모습이랑 완전 똑같아서 훨씬 편합니다. (실은 우리가 쓰는 일반 함수 이름도 다 함수 포인터처럼 작동하거든요!) 최신 프로그램들은 다 이 편한 방법을 지원합니다.
한 가지 주의할 점! 포인터가 빈 껍데기(nullptr)일 수도 있으니, 실행하기 전에 포인터가 비어있지 않은지 꼭 확인하는 습관을 들이세요. 빈 포인터를 실행하면 프로그램이 펑하고 터질 수 있습니다.
int foo(int x)
{
return x;
}
int main()
{
int (*fcnPtr)(int){ &foo }; // fcnPtr을 foo 함수로 초기화합니다
if (fcnPtr) // fcnPtr이 빈 포인터(null)가 아닌지 확인합니다
fcnPtr(5); // 안전하다면 실행합니다 (확인 안 하고 실행하면 오류가 날 수 있어요)
return 0;
}
기본 인자는 함수 포인터를 통해 호출할 때 작동하지 않습니다 (고급)
보통 함수에 "값을 안 넣으면 이 값으로 쳐줘!"라는 기본값(기본 인자)이 있으면, 컴퓨터가 코드를 번역할 때(컴파일 타임) 알아서 그 빈칸을 채워줍니다.
하지만 함수 포인터를 통해 함수를 부를 때는 이야기가 달라집니다. 이건 프로그램이 실제로 돌아가는 중간(런타임)에 어떤 함수가 선택될지 결정되기 때문에, 컴퓨터가 미리 빈칸을 기본값으로 채워줄 수가 없어요.
핵심 통찰
어떤 함수를 부를지가 프로그램 실행 중(런타임)에 결정되기 때문에, 함수 포인터를 써서 실행할 때는 설정해둔 '기본 인자(기본값)'가 적용되지 않습니다.
이 특징을 잘 이용하면, 이름은 똑같고 모양만 달라서 컴퓨터가 헷갈려하는 함수들 중에 딱 하나만 콕 집어서 실행하도록 만들 수 있습니다.
#include <iostream>
void print(int x)
{
std::cout << "print(int)\n";
}
void print(int x, int y = 10)
{
std::cout << "print(int, int)\n";
}
int main()
{
// print(1); // 어떤 print 함수를 부르는 건지 애매해서 컴퓨터가 에러를 냅니다
// 단계별로 풀어서 해결하는 방법
using vnptr = void(*)(int); // void(int) 형태의 함수 포인터에 대한 별명을 만듭니다
vnptr pi { print }; // 우리의 함수 포인터를 print 함수와 연결합니다
pi(1); // 함수 포인터를 통해 매개변수가 하나인 print(int) 함수만 정확히 부릅니다
// 짧고 굵게 해결하는 방법
static_cast<void(*)(int)>(print)(1); // print를 void(int) 형태로 변환한 뒤 숫자 1을 넣고 부릅니다
return 0;
}
함수를 다른 함수의 인자(매개변수)로 전달하기
함수 포인터를 배우는 가장 큰 이유가 바로 여기에 있습니다. 함수 안에 다른 함수를 재료처럼 집어넣을 수 있다는 것! 이렇게 다른 함수의 매개변수로 쏙 들어가는 함수를 흔히 '콜백 함수(callback functions)'라고 부릅니다.
예를 들어 숫자들이 들어있는 배열을 정렬하는 프로그램을 만든다고 쳐볼게요. 정렬은 알아서 잘하되, 숫자를 오름차순(작은 것부터)으로 할지, 내림차순(큰 것부터)으로 할지는 사용하는 사람이 입맛대로 고르게 해주고 싶습니다.
정렬 프로그램들은 보통 '숫자 두 개를 비교해서 자리를 바꿀까 말까?'를 결정하는 방식으로 작동합니다. 즉, 이 비교하는 부분만 바꿔 끼울 수 있게 만들면 정렬 코드를 통째로 다시 짤 필요가 없다는 거죠!
우리가 예전에 만들었던 선택 정렬 코드를 볼까요?
#include <utility> // std::swap을 사용하기 위해 필요합니다
void SelectionSort(int* array, int size)
{
if (!array)
return;
// 배열의 모든 요소를 하나씩 밟고 지나갑니다
for (int startIndex{ 0 }; startIndex < (size - 1); ++startIndex)
{
// smallestIndex는 지금까지 발견한 가장 작은 숫자의 위치입니다.
int smallestIndex{ startIndex };
// 배열의 나머지 부분에서 가장 작은 숫자를 찾습니다
for (int currentIndex{ startIndex + 1 }; currentIndex < size; ++currentIndex)
{
// 만약 현재 숫자가 우리가 찾았던 가장 작은 숫자보다 작다면
if (array[smallestIndex] > array[currentIndex]) // 여기서 비교가 일어납니다!
{
// 이 숫자가 이번 턴의 새로운 제일 작은 숫자가 됩니다
smallestIndex = currentIndex;
}
}
// 맨 앞의 숫자와 우리가 찾은 가장 작은 숫자의 자리를 바꿉니다
std::swap(array[startIndex], array[smallestIndex]);
}
}
저기 > 기호로 고정되어 있는 비교 부분을 함수로 따로 빼내 보겠습니다. 두 숫자를 비교해서 자리를 바꿀지 말지(true/false) 알려주는 함수예요.
bool ascending(int x, int y)
{
return x > y; // 첫 번째 숫자가 두 번째 숫자보다 크면 자리를 바꾸라고 알려줍니다 (오름차순)
}
이걸 원래 코드에 끼워 넣으면 이렇게 됩니다:
#include <utility> // std::swap을 사용하기 위해 필요합니다
void SelectionSort(int* array, int size)
{
if (!array)
return;
// 배열의 모든 요소를 하나씩 밟고 지나갑니다
for (int startIndex{ 0 }; startIndex < (size - 1); ++startIndex)
{
// smallestIndex는 지금까지 발견한 가장 작은 숫자의 위치입니다.
int smallestIndex{ startIndex };
// 배열의 나머지 부분에서 가장 작은 숫자를 찾습니다
for (int currentIndex{ startIndex + 1 }; currentIndex < size; ++currentIndex)
{
// 만약 현재 숫자가 우리가 찾았던 가장 작은 숫자보다 작다면
if (ascending(array[smallestIndex], array[currentIndex])) // 비교를 함수에게 맡겼습니다!
{
// 이 숫자가 이번 턴의 새로운 제일 작은 숫자가 됩니다
smallestIndex = currentIndex;
}
}
// 맨 앞의 숫자와 우리가 찾은 가장 작은 숫자의 자리를 바꿉니다
std::swap(array[startIndex], array[smallestIndex]);
}
}
자, 이제 하이라이트입니다! 우리가 직접 비교 함수를 못 박아두는 대신, 프로그램을 사용하는 사람이 직접 자기가 원하는 비교 함수를 넣을 수 있도록 빈칸(함수 포인터)을 뚫어줄 겁니다.
사용자가 넣을 함수는 두 개의 숫자를 받아서 참/거짓을 알려주는 형태니까, 함수 포인터의 모양은 이렇게 될 겁니다.
bool (*comparisonFcn)(int, int);
이제 정렬 함수의 세 번째 재료로 이 포인터를 받아서 쓰기만 하면 됩니다. 사용자가 오름차순 함수를 넣으면 오름차순으로, 내림차순 함수를 넣으면 내림차순으로 작동하는 마법 같은 정렬 함수가 완성됩니다!
#include <utility> // std::swap을 사용하기 위해 필요합니다
#include <iostream>
// 세 번째 매개변수가 바로 사용자가 직접 만들어 넣을 비교 함수입니다!
void selectionSort(int* array, int size, bool (*comparisonFcn)(int, int))
{
if (!array || !comparisonFcn)
return;
// 배열의 모든 요소를 하나씩 밟고 지나갑니다
for (int startIndex{ 0 }; startIndex < (size - 1); ++startIndex)
{
// bestIndex는 지금까지 발견한 가장 조건에 맞는 숫자의 위치입니다.
int bestIndex{ startIndex };
// 배열의 나머지 부분에서 가장 조건에 맞는 숫자를 찾습니다
for (int currentIndex{ startIndex + 1 }; currentIndex < size; ++currentIndex)
{
// 사용자가 넘겨준 함수를 이용해 두 숫자를 비교합니다!
if (comparisonFcn(array[bestIndex], array[currentIndex])) // 여기서 비교가 일어납니다
{
// 이 숫자가 이번 턴의 새로운 '최고의' 숫자가 됩니다
bestIndex = currentIndex;
}
}
// 맨 앞의 숫자와 우리가 찾은 최고의 숫자의 자리를 바꿉니다
std::swap(array[startIndex], array[bestIndex]);
}
}
// 오름차순(점점 커지게)으로 정렬해주는 비교 함수입니다
bool ascending(int x, int y)
{
return x > y; // 첫 번째 숫자가 더 크면 자리를 바꿉니다
}
// 내림차순(점점 작아지게)으로 정렬해주는 비교 함수입니다
bool descending(int x, int y)
{
return x < y; // 두 번째 숫자가 더 크면 자리를 바꿉니다
}
// 화면에 배열의 숫자들을 예쁘게 출력해주는 함수입니다
void printArray(int* array, int size)
{
if (!array)
return;
for (int index{ 0 }; index < size; ++index)
{
std::cout << array[index] << ' ';
}
std::cout << '\n';
}
int main()
{
int array[9]{ 3, 7, 9, 5, 6, 1, 8, 2, 4 };
// descending() 함수를 넣어서 배열을 내림차순으로 정렬합니다
selectionSort(array, 9, descending);
printArray(array, 9);
// ascending() 함수를 넣어서 배열을 오름차순으로 정렬합니다
selectionSort(array, 9, ascending);
printArray(array, 9);
return 0;
}
결과가 어떻게 나올까요?
9 8 7 6 5 4 3 2 1
1 2 3 4 5 6 7 8 9
정말 멋지죠! 우리는 뼈대 역할을 하는 정렬 함수 하나만 만들었을 뿐인데, 사용자가 원하는 대로 입맛에 맞게 정렬 방식을 조종할 수 있게 되었습니다.
심지어 "짝수를 먼저 세워!" 같은 아주 특이한 비교 함수를 만들어서 넣어도 찰떡같이 알아듣습니다.
bool evensFirst(int x, int y)
{
// x가 짝수이고 y가 홀수면, 짝수인 x가 먼저입니다 (자리 안 바꿈)
if ((x % 2 == 0) && !(y % 2 == 0))
return false;
// x가 홀수이고 y가 짝수면, 짝수인 y가 먼저 가야 합니다 (자리 바꿈)
if (!(x % 2 == 0) && (y % 2 == 0))
return true;
// 둘 다 짝수거나 둘 다 홀수면, 그냥 오름차순으로 정리합니다
return ascending(x, y);
}
int main()
{
int array[9]{ 3, 7, 9, 5, 6, 1, 8, 2, 4 };
selectionSort(array, 9, evensFirst);
printArray(array, 9);
return 0;
}
이 코드의 결과는 이렇습니다.
2 4 6 8 1 3 5 7 9
이렇게 함수 포인터를 사용하면 내가 미리 만들어 둔 튼튼한 코드 뼈대 사이에 다른 사람이 자기만의 코드를 쏙 끼워 넣게(hook) 만들어 줄 수 있습니다. 덕분에 코드를 여러 번 다시 쓸 수 있어서 프로그래머의 퇴근 시간을 아주 앞당겨주죠!
참고로, 매개변수 자리에 그냥 함수의 원형 모양을 써도 C++이 알아서 함수 포인터로 찰떡같이 이해하고 바꿔줍니다. 즉 아래 두 코드는 완전히 같은 의미입니다.
void selectionSort(int* array, int size, bool (*comparisonFcn)(int, int))
void selectionSort(int* array, int size, bool comparisonFcn(int, int))
다만 이 편리함은 '매개변수' 자리에서만 통합니다. 일반적인 곳에서 두 번째 방식처럼 쓰면 그냥 함수를 선언하는 걸로 알아들으니 주의하세요.
기본 함수 제공하기
사용자한테 "매번 비교 함수 만들어서 넣어!"라고 하면 귀찮아하겠죠? 이럴 땐 우리가 미리 사람들이 자주 쓸 법한 ascending()이나 descending() 같은 편의점용 함수를 준비해두면 아주 좋습니다.
심지어 "아무 함수도 안 넣으면 그냥 오름차순으로 해줄게"라고 기본값을 설정할 수도 있습니다.
// 함수를 안 넣으면 기본으로 ascending(오름차순) 함수를 쓰도록 설정합니다
void selectionSort(int* array, int size, bool (*comparisonFcn)(int, int) = ascending);
이렇게 해두면 사용자가 함수 포인터 없이 그냥 정렬 함수만 부를 경우 자동으로 오름차순 정렬이 됩니다. (물론 컴퓨터가 알아먹을 수 있게 이 코드 이전에 ascending 함수가 먼저 만들어져 있어야 합니다.)
타입 별명으로 함수 포인터를 예쁘게 만들기
솔직히 인정합시다. 함수 포인터 문법은 별표에 괄호에 진짜 너무 못생겼고 복잡합니다. 다행히 using이라는 키워드로 예쁜 '별명'을 지어주면 일반 변수처럼 아주 깔끔하게 쓸 수 있습니다.
using ValidateFunction = bool(*)(int, int);
이 한 줄은 "이제부터 bool(*)(int, int)라는 복잡한 함수 포인터 모양을 그냥 ValidateFunction이라고 부를게!"라는 뜻입니다.
이제 아래의 복잡했던 코드가:
bool validate(int x, int y, bool (*fcnPtr)(int, int)); // 눈 아프고 복잡합니다
이렇게 변신합니다:
bool validate(int x, int y, ValidateFunction pfcn) // 아주 깔끔하죠!
std::function 사용하기 (Using std::function)
C++은 이런 지저분한 문법을 아예 싹 덮어버릴 수 있도록 표준 라이브러리 <functional>에 std::function이라는 아주 편리한 도구를 만들어 두었습니다. 최신 C++에서는 이게 함수 포인터의 끝판왕입니다.
#include <functional>
bool validate(int x, int y, std::function<bool(int, int)> fcn); // bool을 반환하고 두 개의 int를 받는 std::function
보시다시피 꺾쇠 < > 안에 반환타입(매개변수타입) 형태로 직관적으로 적어주면 끝입니다. 매개변수가 없으면 그냥 빈 괄호 ()를 쓰면 됩니다.
앞서 본 예제를 std::function으로 바꿔볼까요?
#include <functional>
#include <iostream>
int foo()
{
return 5;
}
int goo()
{
return 6;
}
int main()
{
std::function<int()> fcnPtr{ &foo }; // 매개변수가 없고 int를 반환하는 함수를 담는 상자 만들기!
fcnPtr = &goo; // 이제 fcnPtr은 goo 함수를 가리킵니다
std::cout << fcnPtr() << '\n'; // 일반 함수 부르듯 편하게 씁니다
std::function fcnPtr2{ &foo }; // C++17부터는 모양을 자동으로 유추하게 놔둘 수도 있습니다(CTAD)
return 0;
}
이것도 이름이 너무 길다 싶으면 아까 배운 별명을 지어주는 방식을 섞어 쓰면 완벽합니다.
using ValidateFunctionRaw = bool(*)(int, int); // 옛날 방식의 날것 그대로의 함수 포인터 별명
using ValidateFunction = std::function<bool(int, int)>; // 깔끔한 std::function 방식의 별명
참고로 std::function은 fcnPtr()처럼 이름만 부르는 자연스러운 방식만 허용하고, (*fcnPtr)()처럼 앞에 별표를 굳이 붙이는 옛날 방식은 허용하지 않습니다.
함수 포인터의 타입 추론
귀찮음을 덜어주는 마법의 단어 auto 기억하시죠? 일반 변수를 만들 때처럼, 함수 포인터를 만들 때도 auto를 써서 컴퓨터가 알아서 모양을 맞춰주게 할 수 있습니다.
#include <iostream>
int foo(int x)
{
return x;
}
int main()
{
auto fcnPtr{ &foo }; // 알아서 foo를 가리키는 알맞은 함수 포인터를 만들어줍니다!
std::cout << fcnPtr(5) << '\n';
return 0;
}
코드가 아주 짧고 깔끔해지죠? 물론 이 방법은 코드가 너무 짧아진 나머지, 이 함수가 매개변수를 몇 개나 받고 뭘 반환하는지가 눈에 안 보여서 코드를 읽다가 헷갈릴 수 있다는 단점이 있긴 합니다.
결론
함수 포인터는 수많은 함수들을 배열 같은 곳에 깔끔하게 모아두고 싶을 때나, 다른 함수의 재료(콜백 함수)로 함수 자체를 넘겨주고 싶을 때 아주 유용하게 쓰입니다.
다만, 옛날 방식의 (*fcnPtr) 문법은 너무 못생겼고 실수하기 딱 좋기 때문에, 최신 기능인 std::function을 사용하는 것을 강력히 추천합니다. 딱 한 번만 쓰고 말 거라면 매개변수 자리에 std::function을 바로 쓰고, 여러 번 반복해서 쓸 거라면 예쁜 별명(using)을 지어주는 것이 가장 좋은 습관입니다!
20.2 — 스택(Stack)과 힙(Heap)
컴퓨터에서 프로그램이 실행될 때, 프로그램이 사용하는 메모리(기억 공간)는 마치 집의 방들을 용도에 따라 나누듯 몇 가지 구역으로 나뉩니다. 초보자분들도 이해하기 쉽게 정리해 볼게요!
-
코드 영역 (텍스트 영역)
우리가 짠 프로그램 코드가 들어가는 곳입니다. (보통 읽기만 가능해요.) -
bss 영역
아직 값이 정해지지 않은(0으로 초기화된) 전역 변수나 정적 변수가 사는 곳입니다. -
데이터 영역
이미 값이 정해진 전역 변수나 정적 변수가 사는 곳입니다. -
힙(Heap)
프로그램이 실행되는 도중에 "나 메모리 좀 빌려줘!" 할 때 동적으로 공간을 내어주는 커다란 창고입니다. -
콜 스택(Call stack)
함수를 부를 때 필요한 재료들(매개변수)이나, 함수 안에서 잠깐 쓰는 변수들(지역 변수)이 잠시 머무는 곳입니다.
이번 강의에서는 가장 중요하고 재미있는 일들이 일어나는 힙(Heap)과 스택(Stack), 이 두 가지에만 집중해 보겠습니다.
힙(Heap) 영역
힙(Heap) 영역은 '필요할 때 언제든 메모리를 빌려 쓸 수 있는 거대한 창고'라고 생각하시면 쉽습니다. C++에서 new라는 마법의 단어(연산자)를 사용하면, 이 힙 영역에서 필요한 만큼 메모리를 빌려오게 됩니다.
만약 int형 변수 하나가 4바이트의 공간을 차지한다고 가정해 볼까요?
int* ptr { new int }; // new int는 힙 창고에서 4바이트의 공간을 빌려옵니다.
int* array { new int[10] }; // new int[10]은 힙 창고에서 40바이트의 공간을 빌려옵니다.
이렇게 빌려온 공간의 '주소'를 우리가 만든 포인터에 저장해 두고 쓰는 방식입니다.
운영체제가 빈 공간을 어떻게 찾아서 빌려주는지 그 복잡한 원리까지는 몰라도 괜찮아요!
다만 한 가지 알아둘 점은, 메모리를 연달아 빌린다고 해서 실제로 창고 안에서 나란히 붙어있는 공간을 주지는 않을 수도 있다는 것입니다.
int* ptr1 { new int };
int* ptr2 { new int };
// ptr1과 ptr2가 가리키는 주소가 창고 안에서 나란히 붙어있지 않을 수도 있습니다!
다 쓴 메모리를 delete로 삭제하면, 메모리에 있던 변수가 아예 세상에서 사라지는 게 아니라 "다 썼으니 창고에 반납할게요" 하고 운영체제에 돌려주는 것을 의미합니다. 그럼 다음에 다른 누군가가 그 공간을 다시 빌려 쓸 수 있겠죠.
힙 영역은 다음과 같은 장단점이 있습니다:
- 단점: 스택에 비해 메모리를 빌려오는 속도가 조금 느립니다.
- 주의점: 직접 반납(
delete)하거나 프로그램이 완전히 끝날 때까지 메모리 공간을 계속 차지하고 있습니다. (다 쓰고 반납 안 하면 '메모리 누수'라는 골치 아픈 문제가 생겨요!) - 단점: 포인터를 통해서만 접근해야 해서, 일반 변수를 바로 쓰는 것보다 아주 살짝 느립니다.
- 장점: 창고가 아주 넓기 때문에 엄청나게 큰 배열이나 복잡한 데이터를 저장하기에 아주 좋습니다.
콜 스택(Call stack)
콜 스택(보통 줄여서 그냥 '스택'이라고 부릅니다)은 훨씬 더 흥미로운 역할을 합니다.
스택은 프로그램이 시작된 후 지금까지 어떤 함수들이 실행 중인지 기억하고, 그 함수들이 사용하는 지역 변수들의 자리를 마련해 주는 똑똑한 비서입니다.
스택이 어떻게 일하는지 이해하려면, 먼저 '스택 자료 구조'가 무엇인지 알아야 해요.
스택(Stack) 자료 구조
'자료 구조'란 데이터를 효율적으로 쓰기 위해 정리하는 방법입니다. 여러분이 식당에 갔을 때 뷔페 한쪽에 차곡차곡 쌓여 있는 접시 더미를 떠올려 보세요. 접시가 무겁게 쌓여 있기 때문에 우리가 할 수 있는 행동은 딱 세 가지뿐입니다.
- 맨 위에 있는 접시가 뭔지 본다.
- 맨 위에 있는 접시를 꺼낸다.
- 새 접시를 맨 위에 올려놓는다.
컴퓨터 프로그래밍의 스택도 똑같습니다! 스택은 데이터를 보관하는 상자인데, 아무 곳에나 마음대로 넣고 뺄 수 있는 배열과 달리 규칙이 엄격합니다.
- 스택 맨 위(꼭대기)에 있는 항목 확인하기 (보통
top()이나peek()이라는 함수를 씁니다) - 맨 위에서 항목 꺼내기 (팝(Pop)이라고 부릅니다)
- 맨 위에 새 항목 올려놓기 (푸시(Push)라고 부릅니다)
스택은 가장 나중에 들어온 녀석이 가장 먼저 나가는 (LIFO: Last-In, First-Out) 구조입니다. 접시를 방금 맨 위에 올려두었다면, 다음 사람이 접시를 가져갈 때 바로 그 접시를 제일 먼저 가져가게 되겠죠. 넣을 때(Push)는 위로 쌓이고, 뺄 때(Pop)는 위에서부터 줄어듭니다.
간단한 예시를 볼까요?
스택: 텅 빔
푸시 1 -> 스택: 1
푸시 2 -> 스택: 1 2
푸시 3 -> 스택: 1 2 3
팝 -> 스택: 1 2 (3이 빠짐)
팝 -> 스택: 1 (2가 빠짐)
접시 비유도 좋지만, 아래에서부터 위로 차곡차곡 고정되어 쌓여 있는 우편함을 상상하면 더 정확합니다.
가장 아래쪽 빈 우편함에 포스트잇(마커)을 붙여둡니다. 새 물건(Push)을 넣으면 포스트잇이 붙은 우편함에 넣고 포스트잇을 한 칸 위로 옮깁니다. 물건을 뺄 때(Pop)는 포스트잇을 한 칸 아래로 내린 뒤 그 우편함에서 물건을 꺼냅니다. 포스트잇 아래에 있는 것만 "스택에 들어있다"고 치고, 그 위는 신경 쓰지 않는 식입니다.
콜 스택(Call stack) 영역
콜 스택 영역은 이 스택 방식을 똑같이 사용합니다.
프로그램이 켜지면 제일 먼저 main() 함수가 스택에 쏙 들어갑니다(Push).
프로그램을 실행하다가 새로운 함수를 부르면, 그 함수도 스택 맨 위에 층층이 쌓입니다(Push). 그리고 그 함수가 일을 다 마치면 스택에서 빠져나옵니다(Pop). 따라서 현재 스택에 쌓여있는 함수들을 밑에서부터 쭉 훑어보면, 지금 실행 중인 곳까지 오기 위해 어떤 함수들을 거쳐왔는지 한눈에 알 수 있습니다.
우편함 비유를 적용해 볼게요. 여기서 물건을 넣고 빼는 단위는 함수 하나의 정보가 담긴 '스택 프레임(Stack frame)'이라는 보따리입니다. 그리고 포스트잇(마커) 역할을 하는 것은 CPU 안에 있는 '스택 포인터(SP)'라는 녀석이죠. 스택 포인터는 항상 스택의 맨 꼭대기를 가리키며 "지금 여기까지 찼어!"라고 알려줍니다.
재미있는 점은, 스택에서 함수를 뺄 때(Pop) 굳이 우편함 안의 내용물을 지우개로 빡빡 지우며 청소할 필요가 없다는 것입니다. 그냥 스택 포인터(포스트잇)만 한 칸 아래로 내리면 끝납니다! 어차피 나중에 새 함수가 들어오면 그 자리에 새 정보를 덮어씌울 테니까요. 이렇게 하면 속도가 훨씬 빨라집니다.
콜 스택의 작동 방식
함수를 부를 때 내부적으로 어떤 일들이 일어나는지 순서대로 쉽게 살펴볼게요.
- 프로그램이 "어, 함수 호출이네!" 하고 알아챕니다.
- 그 함수를 위한 '스택 프레임(보따리)'을 만들어 스택 맨 위에 올립니다(Push).
이 보따리 안에는 다음 내용이 들어갑니다:
- 돌아갈 주소: 함수가 끝나고 원래 하던 일로 다시 돌아올 위치를 적어둔 메모지.
- 함수에 전달할 매개변수들.
- 함수 안에서만 쓸 지역 변수들을 위한 빈 공간.
- 이제 프로그램은 방금 부른 함수의 시작점으로 점프해서 들어갑니다.
- 함수 안의 코드들을 열심히 실행합니다.
- 함수가 끝에 도달하면 다음 일들이 벌어집니다:
- 스택 프레임을 스택에서 빼냅니다(Pop). 이러면 함수 안에서 쓰던 지역 변수들도 자연스럽게 공간을 반납하게 됩니다.
- 함수가 남긴 결과값(Return value)을 챙깁니다.
- 아까 보따리에 적어둔 '돌아갈 주소'를 보고 원래 하던 곳으로 무사히 점프해서 돌아갑니다.
참고로...
컴퓨터 종류에 따라 스택이 메모리 주소 0번지부터 점점 큰 숫자로 쌓이는 기계도 있고, 반대로 큰 숫자에서 0번지 쪽으로 거꾸로 쌓이는 기계도 있습니다. 아주 깊은 기술적인 내용이니 "그렇구나~" 하고 넘어가셔도 괜찮습니다.
간단한 콜 스택 예제
아주 간단한 코드로 콜 스택이 어떻게 변하는지 볼까요?
int foo(int x)
{
// b
return x;
} // foo 함수가 여기서 콜 스택에서 빠집니다 (pop)
int main()
{
// a
foo(5); // foo 함수가 여기서 콜 스택에 쌓입니다 (push)
// c
return 0;
}
코드 안의 a, b, c 위치에서 콜 스택의 모습은 다음과 같습니다:
a 위치:
main()
b 위치:
foo() (매개변수 x 포함)
main()
c 위치:
main()
스택 오버플로우(Stack overflow)
스택은 무한정 넓은 곳이 아니라 크기가 정해져 있습니다. 윈도우(Visual Studio)에서는 기본적으로 겨우 1MB밖에 안 되고, 유닉스 환경에서도 8MB 정도입니다. 만약 이 좁은 스택에 너무 많은 정보를 구겨 넣으려고 하면 스택 오버플로우(Stack overflow, 스택이 넘침)라는 끔찍한 에러가 발생합니다!
주로 스택에 너무 큰 배열을 만들려고 하거나, 함수가 함수를 부르고 또 부르는 과정(꼬리에 꼬리를 무는 호출)이 너무 깊어질 때 발생합니다. 스택이 넘쳐버리면 운영체제는 화를 내며 프로그램을 강제로 종료시켜 버립니다(뻗어버리는 거죠).
아래 코드는 스택을 꽉 채워 터지게 만드는 예제입니다. 직접 실행해 보면 프로그램이 어떻게 죽는지 볼 수 있어요.
#include <iostream>
int main()
{
int stack[10000000];
std::cout << "hi" << stack[0]; // 컴파일러가 배열을 맘대로 없애버리지 못하게 stack[0]을 억지로 써줍니다.
return 0;
}
이 프로그램은 스택이라는 좁은 방에 대략 40MB짜리 엄청나게 큰 배열을 우겨 넣으려고 합니다. 스택이 이걸 감당하지 못해서, 결국 허락되지 않은 다른 메모리 구역까지 침범하다가 프로그램이 강제 종료됩니다. 윈도우에서는 "접근 위반(access violation)"이라는 에러 코드를 뱉고, "hi"라는 글자는 출력조차 되지 않습니다.
스택이 터지는 또 다른 흔한 이유도 볼까요?
// h/t 카운터 추가 아이디어를 주신 독자 yellowEmu님께 감사드립니다.
#include <iostream>
int g_counter{ 0 };
void eatStack()
{
std::cout << ++g_counter << ' ';
// 컴파일러가 무한 반복이라고 경고하는 걸 막기 위해 조건문을 하나 달아줍니다.
if (g_counter > 0)
eatStack(); // 주목: eatStack() 함수가 자기 자신을 또 부릅니다!
// 컴파일러가 멋대로 코드를 최적화하는 것을 막기 위한 용도입니다.
std::cout << "hi";
}
int main()
{
eatStack();
return 0;
}
이 프로그램은 eatStack() 함수가 실행될 때마다 스택에 새로운 보따리(스택 프레임)를 올립니다. 그런데 이 함수가 자기 자신을 부르고, 불려온 애가 또 자기를 부르고... 끝없이 자기를 부르기 때문에 결국 스택 메모리가 꽉 차서 넘쳐(오버플로우) 버립니다.
참고 노트
원작자가 윈도우 10 컴퓨터에서 테스트해 보았을 때, 디버그 모드에서는eatStack()이 4,848번 불린 후 프로그램이 뻗었고, 릴리스 모드에서는 128,679번 불린 후에 뻗었다고 하네요!
관련 컨텐츠
자기 자신을 계속해서 부르는 함수에 대해서는 다음 강의인 20.3 - 재귀(Recursion)에서 더 자세히 다룰 예정입니다!
정리하자면, 스택은 다음과 같은 장단점이 있습니다:
- 장점: 메모리를 빌리고 반납하는 속도가 굉장히 빠릅니다.
- 장점: 스택에 들어간 변수는 알아서 관리됩니다. 함수가 끝나서 스택에서 빠질 때 자동으로 싹 청소됩니다.
- 장점: 컴파일할 때 크기가 다 정해져서, 변수 이름으로 빠르고 직접적으로 접근할 수 있습니다.
- 주의점: 스택은 크기가 매우 작습니다! 그래서 엄청나게 큰 배열이나 무거운 데이터를 스택에 넣는 것은 절대 권장하지 않습니다.
참고 노트
이 코멘트를 보시면 스택에 있는 변수들이 어떻게 배치되고, 실제로 어떻게 주소를 받는지에 대한 추가적이고 조금 더 쉬운 설명이 있습니다.
20.3 — 재귀 (Recursion)
C++에서 재귀 함수(recursive function)란 아주 간단히 말해 '자기 자신을 다시 부르는(호출하는) 함수'를 뜻해요. 마치 거울 속에 거울이 있는 것처럼요! 먼저, 조금 잘못 만들어진 재귀 함수 예제를 하나 살펴볼까요?
#include <iostream>
void countDown(int count)
{
std::cout << "push " << count << '\n';
countDown(count-1); // countDown() 함수가 자기 자신을 다시 부릅니다 (재귀 호출)
}
int main()
{
countDown(5);
return 0;
}
이 프로그램에서 countDown(5)가 실행되면 화면에 "push 5"가 출력되고, 함수 안에서 countDown(4)를 또 부릅니다. 그러면 countDown(4)는 "push 4"를 출력하고 countDown(3)을 부르겠죠. 이런 식으로 countDown(n)이 countDown(n-1)을 부르는 과정이 끝없이 반복됩니다. 사실상 무한 루프(영원히 끝나지 않는 반복문)와 똑같은 상태가 되는 거예요.
함수가 호출될 때마다 컴퓨터는 '콜 스택(call stack)'이라는 메모리 공간에 정보를 쌓아둡니다. 하지만 위 예제에서는 countDown() 함수가 끝을 맺지 못하고 계속 자기 자신을 부르기만 하니까, 쌓인 정보가 스택에서 빠져나갈(pop) 기회가 전혀 없게 됩니다!
결국 어느 순간 컴퓨터는 스택 메모리를 모두 다 써버리게 되고, 이를 스택 오버플로우(stack overflow)라고 부릅니다. 이 상태가 되면 프로그램은 에러를 내며 튕기거나 강제로 종료돼요. 원본 글의 작성자 컴퓨터에서는 프로그램이 종료되기 전까지 무려 -11732까지 카운트다운을 했다고 하네요!
참고 노트
테일 콜(Tail call, 꼬리 호출)이란 함수의 맨 끝(꼬리 부분)에서 일어나는 함수 호출을 말합니다. 컴파일러(코드를 컴퓨터 언어로 번역해 주는 프로그램)는 이런 재귀적인 테일 콜을 반복문(재귀가 아닌 형태)으로 쉽게 최적화할 수 있어요. 만약 최적화가 적용되었다면 위 예제에서도 시스템 메모리가 부족해지는 일이 발생하지 않았을 겁니다. 위 코드를 직접 실행해 봤는데 에러 없이 영원히 실행된다면, 컴파일러가 똑똑하게 코드를 최적화했기 때문일 가능성이 높습니다.
재귀 종료 조건
재귀 함수는 일반적인 함수와 거의 똑같이 작동해요. 하지만 방금 본 예제에서 알 수 있듯, 재귀 함수를 쓸 때 가장 중요하게 기억해야 할 차이점이 있습니다. 바로 재귀 종료 조건을 반드시 만들어 주어야 한다는 점이에요. 그렇지 않으면 메모리가 바닥날 때까지 영원히 실행되니까요.
종료 조건이란 쉽게 말해 "특정 상황이 되면 자기 자신을 그만 부르고 멈춰라!"라고 알려주는 규칙입니다.
종료 조건은 보통 if 문을 사용해서 만듭니다. 아까 보았던 함수에 종료 조건을 추가해서 새롭게 고쳐볼게요 (출력 내용도 조금 추가했습니다).
#include <iostream>
void countDown(int count)
{
std::cout << "push " << count << '\n';
if (count > 1) // 종료 조건: count가 1보다 클 때만 자기 자신을 부릅니다.
countDown(count-1);
std::cout << "pop " << count << '\n';
}
int main()
{
countDown(5);
return 0;
}
이제 이 프로그램을 실행하면, 제일 먼저 다음과 같이 출력됩니다.
push 5
push 4
push 3
push 2
push 1
이 순간, 컴퓨터의 콜 스택(메모리가 쌓여 있는 모습)을 들여다본다면 다음과 같이 함수들이 차곡차곡 쌓여 있을 거예요.
countDown(1)
countDown(2)
countDown(3)
countDown(4)
countDown(5)
main()
이번에는 종료 조건(if (count > 1))이 있기 때문에, countDown(1)은 countDown(0)을 부르지 않아요! 조건에 맞지 않아 if 문 안의 코드가 실행되지 않고, 바로 "pop 1"을 출력한 뒤 함수가 성공적으로 끝납니다.
함수가 끝났으니 countDown(1)은 스택에서 빠져나가고(pop), 프로그램의 흐름은 자신을 불렀던 countDown(2)로 돌아갑니다. countDown(2)는 멈췄던 지점부터 다시 실행되어 "pop 2"를 출력하고 또 끝이 납니다. 이렇게 차례대로 스택에서 빠져나가면서 모든 countDown 함수가 메모리에서 지워질 때까지 이 과정이 반복돼요.
결과적으로 이 프로그램은 다음과 같은 전체 결과를 출력합니다.
push 5
push 4
push 3
push 2
push 1
pop 1
pop 2
pop 3
pop 4
pop 5
여기서 "push"는 자기 자신을 부르기 전에 실행되니까 숫자가 정방향(5부터 1)으로 나오고, "pop"은 함수가 끝나고 스택에서 빠져나올 때(들어간 순서의 역순으로 빠져나옴) 실행되니까 숫자가 역방향(1부터 5)으로 나온다는 점을 눈여겨보세요!
조금 더 쓸만한 예제
재귀 호출이 어떻게 작동하는지 기본 원리를 알아봤으니, 이번에는 조금 더 흔하게 쓰이는 실용적인 재귀 함수를 살펴볼까요?
// 1부터 sumto까지의 모든 정수를 더한 값을 반환합니다 (1과 sumto 포함)
// 음수를 넣으면 0을 반환합니다.
int sumTo(int sumto)
{
if (sumto <= 0)
return 0; // 기본 케이스 (종료 조건): 사용자가 0이나 음수 같은 예상치 못한 값을 넣었을 때
if (sumto == 1)
return 1; // 일반적인 기본 케이스 (종료 조건)
return sumTo(sumto - 1) + sumto; // 재귀 함수 호출
}
재귀 프로그램은 코드만 눈으로 딱 보고 어떻게 돌아가는지 이해하기가 꽤 어려워요. 이럴 때는 특정 숫자를 직접 넣었을 때 어떤 일이 일어나는지 차근차근 따라가 보는 것이 가장 좋습니다. sumto에 5를 넣었다고 상상해 볼까요?
sumTo(5)호출: 5 <= 1은 거짓이므로,sumTo(4) + 5를 반환하려고 합니다.sumTo(4)호출: 4 <= 1은 거짓이므로,sumTo(3) + 4를 반환하려고 합니다.sumTo(3)호출: 3 <= 1은 거짓이므로,sumTo(2) + 3을 반환하려고 합니다.sumTo(2)호출: 2 <= 1은 거짓이므로,sumTo(1) + 2를 반환하려고 합니다.sumTo(1)호출: 1 <= 1은 참이므로, 1을 반환합니다. 드디어 종료 조건을 만났네요!
이제 함수가 차례대로 결과를 돌려주며 콜 스택에서 하나씩 빠져나옵니다(unwind).
sumTo(1)은 1을 반환합니다.sumTo(2)는sumTo(1) + 2를 계산하니까, 1 + 2 = 3을 반환합니다.sumTo(3)은sumTo(2) + 3을 계산하니까, 3 + 3 = 6을 반환합니다.sumTo(4)는sumTo(3) + 4를 계산하니까, 6 + 4 = 10을 반환합니다.sumTo(5)는sumTo(4) + 5를 계산하니까, 10 + 5 = 15를 반환합니다.
이렇게 풀어놓고 보니 1부터 넘겨받은 숫자 5까지 모든 수를 더한다는 게 훨씬 이해하기 쉽죠?
재귀 함수는 직관적으로 이해하기 어렵기 때문에, 좋은 주석(설명글)을 달아두는 것이 아주 중요합니다.
참고로 위 코드에서는 --sumto 대신 sumto - 1이라는 값을 사용해 재귀 호출을 했어요. 왜냐하면 -- 기호(값을 1 줄이는 연산자)는 변수의 실제 값 자체를 바꿔버리는 '부작용(side effect)'이 있기 때문이에요. 하나의 수식 안에서 값이 변하는 변수를 여러 번 쓰면 프로그램이 예측 불가능한 이상한 행동(정의되지 않은 동작)을 할 수 있습니다. sumto - 1을 쓰면 변수의 원래 값은 그대로 둔 채 1을 뺀 새로운 값만 전달할 수 있어서 안전하답니다.
재귀 알고리즘
재귀 함수는 보통 큰 문제를 먼저 작게 쪼개서 푼 다음(재귀적으로), 그 작은 해답들을 조합해서 전체의 정답을 찾아내는 방식으로 작동합니다. 위에서 본 알고리즘에서도 sumTo(value)를 구하기 위해, 먼저 더 작은 문제인 sumTo(value-1)을 풀고 거기에 value를 더해서 정답을 알아냈죠.
이런 재귀 알고리즘들 중에는 너무 쉬워서 계산할 필요도 없는 입력값들이 있습니다. 예를 들어 sumTo(1)은 그냥 1이죠 (머릿속으로 1초 만에 알 수 있잖아요!). 이렇게 더 이상 재귀를 할 필요 없이 바로 정답이 나오는 단순한 입력값을 기본 케이스(base case)라고 부릅니다. 이 기본 케이스들이 바로 재귀를 멈춰주는 '종료 조건' 역할을 한답니다. 기본 케이스는 보통 입력값이 0, 1, 빈 문자열(""), 혹은 데이터가 없는 상태(null)일 때 나타나는 경우가 많아요.
피보나치 수열
수학에서 가장 유명한 재귀 알고리즘 중 하나가 바로 '피보나치 수열'입니다. 피보나치 수열은 나뭇가지가 뻗어나가는 모양, 조개껍데기의 나선형, 파인애플 껍질의 무늬, 솔방울의 구조 등 자연 속 아주 많은 곳에서 발견할 수 있어요.
피보나치 나선형의 그림은 다음과 같습니다.
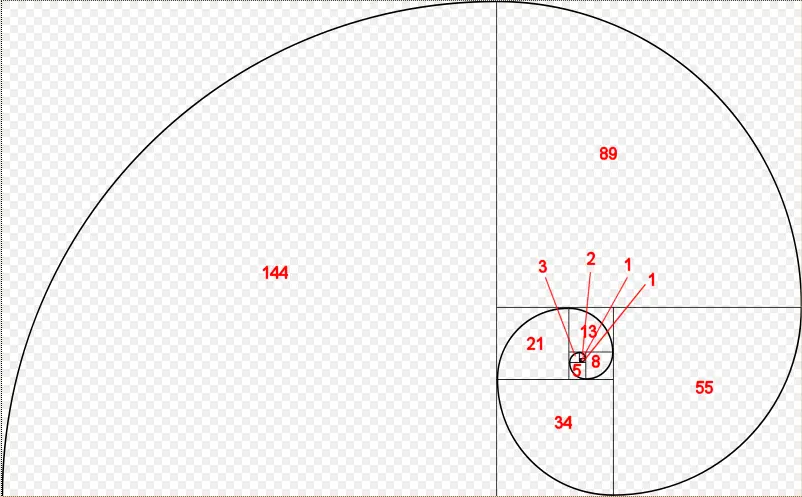
나선형 안에 그려진 사각형들의 한 변의 길이를 보면 피보나치 수열의 숫자들과 정확히 일치합니다.
피보나치 수는 수학적으로 이렇게 정의돼요.
규칙이 수학적으로 정해져 있다 보니, n번째 피보나치 수를 계산하는 재귀 함수를 코드(효율적이지는 않지만)로 짜는 것은 무척 쉽습니다.
#include <iostream>
int fibonacci(int count)
{
if (count == 0)
return 0; // 기본 케이스 (종료 조건)
if (count == 1)
return 1; // 기본 케이스 (종료 조건)
return fibonacci(count-1) + fibonacci(count-2);
}
// 처음 13개의 피보나치 수를 보여주는 메인 프로그램
int main()
{
for (int count { 0 }; count < 13; ++count)
std::cout << fibonacci(count) << ' ';
return 0;
}
이 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
0 1 1 2 3 5 8 13 21 34 55 89 144
방금 그림에서 본 피보나치 나선형 다이어그램의 숫자들과 완전히 똑같죠?
메모이제이션 알고리즘
방금 본 피보나치 재귀 알고리즘은 사실 효율이 썩 좋지 않아요. 기본 케이스가 아닐 때마다 함수 안에서 피보나치 함수를 '두 번씩'이나 더 부르기 때문이죠. 이렇게 되면 함수 호출 횟수가 기하급수적으로 늘어납니다 (실제로 위 코드는 fibonacci() 함수를 무려 1205번이나 불렀답니다!).
이런 불필요한 호출을 줄이는 멋진 기술이 있는데, 그중 하나가 바로
메모이제이션(memoization)이에요. 메모이제이션은 복잡하고 오래 걸리는 계산 결과를 '캐시(메모리장)'에 슬쩍 저장해 두었다가, 똑같은 입력값이 다시 들어오면 귀찮게 또 계산하지 않고 저장해 둔 정답을 바로 꺼내주는 기법입니다.
캐시를 적용한(메모이즈된) 피보나치 코드를 살펴볼까요?
#include <iostream>
#include <vector>
// 이 코드의 변형을 제공해준 potterman28wxcv에게 감사를 표합니다 (h/t)
// std::vector를 좀 더 쉽게 다루기 위해 count를 std::size_t 타입으로 바꿨습니다.
int fibonacci(std::size_t count)
{
// 계산된 결과를 저장(캐시)해 둘 static std::vector를 만듭니다.
static std::vector results{ 0, 1 };
// 만약 이미 계산해 본 적 있는 count라면, 저장해둔 결과를 그대로 씁니다!
if (count < std::size(results))
return results[count];
// 계산해 본 적이 없다면 새로 결과를 계산해서 목록에 추가합니다.
results.push_back(fibonacci(count - 1) + fibonacci(count - 2));
return results[count];
}
// 처음 13개의 피보나치 수를 보여주는 메인 프로그램
int main()
{
for (int count { 0 }; count < 13; ++count)
std::cout << fibonacci(static_cast<std::size_t>(count)) << ' ';
return 0;
}
이렇게 메모이제이션을 적용하면 함수를 딱 35번만 부르고도 똑같은 결과를 낼 수 있어요.
원래 1205번 불렀던 것에 비하면 엄청난 발전이죠!
재귀 vs 반복
초보자분들이 재귀 함수를 배울 때 가장 많이 하는 질문이 있어요. "for 문이나 while 문 같은 반복문(iterative)을 쓰면 다 똑같이 할 수 있는데, 왜 굳이 어렵게 재귀 함수를 쓰나요?"
맞아요, 재귀로 풀 수 있는 문제는 항상 반복문으로도 풀 수 있습니다. 하지만 복잡하고 까다로운 문제일수록 재귀를 쓰는 쪽이 코드를 작성하기도, 읽기도 훨씬 간결하고 쉬운 경우가 많습니다. 예를 들어, 피보나치수열을 반복문으로 만들 수는 있지만 재귀로 만드는 것보다는 조금 더 골치가 아픕니다! (직접 한 번 시도해 보세요!)
속도 면에서는 반복문(for 루프나 while 루프)이 거의 항상 재귀 함수보다 빠르고 효율적입니다. 함수를 새로 부를 때마다 메모리(스택)를 쌓았다 지웠다 하는 숨은 작업(오버헤드)이 필요한데, 반복문은 그런 과정을 겪지 않기 때문이에요.
그렇다고 반복문이 언제나 정답이라는 뜻은 아닙니다. 코드를 읽기 쉽고 관리하기 편하게(유지 보수) 만드는 게 더 중요할 때가 있거든요. 재귀를 쓰면 코드가 훨씬 깔끔해져서, 약간의 성능을 희생하더라도 이득을 볼 때가 많습니다. (물론 정답을 찾기 위해 함수가 수만 번씩 불려야 하는 극단적인 상황이 아니라면요!)
보통 다음 조건들 중 대부분이 맞을 때 재귀를 사용하는 것이 좋습니다.
- 재귀로 코드를 짜는 게 (반복문보다) 훨씬 간단할 때.
- 재귀가 너무 깊이 들어가지 않을 거라는 보장이 있을 때 (예: 함수가 10만 번씩 연달아 자기 자신을 부를 일이 없을 때).
- 반복문으로 만들 경우 데이터를 저장할 복잡한 스택 구조를 직접 만들어 관리해야 할 때.
- 성능이 0.001초 단위로 중요한 핵심 코드가 아닐 때.
하지만 재귀로 짜는 게 더 쉽다면, 일단 재귀로 먼저 코드를 완성한 다음 나중에 성능을 위해 반복문으로 최적화하는 것도 좋은 방법입니다.
권장 사항
재귀가 정말로 딱 들어맞는 상황이 아니라면, 일반적으로는 재귀보다는 반복문을 우선적으로 사용하는 것이 좋습니다.
20.4 — 명령줄 인수
명령줄 인수가 필요한 이유
이전 레슨(0.5 컴파일러, 링커, 라이브러리 소개)에서 배웠듯이, 코드를 컴파일하고 링크하면 실제로 실행할 수 있는 파일이 하나 만들어집니다. 이 프로그램 파일이 실행되면 언제나 main()이라는 이름의 함수부터 코드가 시작되죠. 우리는 지금까지 main 함수를 다음과 같은 모양으로 써왔습니다.
int main()
여기서 괄호 () 안이 텅 비어 있다는 점에 주목해 보세요. 이 main() 함수는 시작할 때 아무런 입력값(매개변수)도 받지 않겠다는 뜻입니다. 하지만 많은 프로그램은 일을 시작하기 위해 어떤 재료(입력값)를 필요로 합니다.
예를 들어, 큰 이미지 파일을 읽어서 작고 귀여운 썸네일(미리보기 이미지)로 만들어 주는 Thumbnail이라는 프로그램을 만든다고 가정해 볼게요. 이 프로그램은 도대체 '어떤 이미지 파일'을 열어봐야 할지 어떻게 알 수 있을까요? 당연히 사용자가 프로그램에게 어떤 파일을 열지 알려줄 수 있는 방법이 있어야 합니다. 이를 위해 보통은 다음과 같은 방식으로 코드를 짭니다.
// Program: Thumbnail
#include <iostream>
#include <string>
int main()
{
std::cout << "Please enter an image filename to create a thumbnail for: "; // 썸네일을 만들 이미지 파일 이름을 입력하세요:
std::string filename{};
std::cin >> filename;
// open image file (이미지 파일 열기)
// create thumbnail (썸네일 생성하기)
// output thumbnail (썸네일 출력하기)
}
하지만 이 방식에는 큰 단점이 숨어 있습니다. 프로그램을 실행할 때마다 사용자가 직접 키보드로 파일 이름을 타이핑할 때까지 프로그램이 멍하니 멈춰서 기다린다는 것입니다.
물론 여러분이 까만 명령창(터미널)에서 손으로 딱 한 번만 실행한다면 별문제가 아닐 겁니다. 하지만 여러 개의 파일을 한꺼번에 처리하고 싶거나, 내가 만든 프로그램이 아닌 다른 프로그램이 이 프로그램을 자동으로 실행하게 만들고 싶을 때는 아주 불편해집니다.
이 상황들을 조금 더 자세히 파헤쳐 볼까요?
어떤 폴더 안에 있는 모든 이미지 파일의 썸네일을 한꺼번에 다 만들고 싶다고 생각해 봅시다. 방금 짠 코드대로라면 폴더 안의 이미지 개수만큼 프로그램을 여러 번 실행하고, 매번 파일 이름을 일일이 타이핑해야 합니다. 이미지가 수백 개라면 하루 종일 키보드만 두드려야 할지도 몰라요! 이럴 때는 폴더 안의 모든 파일 이름을 확인해서, 각 파일마다 Thumbnail 프로그램을 한 번씩 자동으로 실행해 주는 프로그램을 만드는 것이 훨씬 현명한 해결책입니다.
이번에는 웹사이트를 운영하는 경우를 생각해 봅시다. 사용자가 웹사이트에 이미지를 올릴 때마다 웹사이트가 자동으로 썸네일을 만들게 하고 싶습니다. 그런데 우리가 만든 프로그램은 인터넷에서 입력을 받도록 만들어지지 않았죠. 그렇다면 사용자가 업로드할 때 프로그램에 파일 이름을 어떻게 전달할 수 있을까요? 이럴 때는 웹 서버가 이미지 업로드가 끝나면 자동으로 Thumbnail 프로그램을 켜주는 것이 좋습니다.
결국 위 두 가지 경우 모두, 프로그램이 일단 켜진 후에 사용자가 직접 파일 이름을 쳐주기를 기다리는 방식은 좋지 않습니다. 그보다는 외부 프로그램이 Thumbnail을 처음 켜는 바로 그 순간에 파일 이름이라는 재료(입력 데이터)를 한 번에 쏙 넣어주는 방법이 필요합니다.
명령줄 인수(Command line arguments)란, 프로그램이 처음 시작될 때 운영체제(윈도우, 맥 등)가 프로그램 안으로 쏙 던져주는 추가적인 '문자열(글자) 정보'를 말합니다. 프로그램은 이 정보를 입력값으로 받아서 쓸 수도 있고, 필요 없으면 무시할 수도 있습니다. 마치 함수가 다른 함수에게 매개변수를 넘겨주듯이, 명령줄 인수는 사람이나 다른 프로그램이 어떤 프로그램에게 시작부터 입력값을 쥐여주는 방법이라고 생각하면 이해하기 쉽습니다.
명령줄 인수 전달하기
우리가 만든 실행 프로그램은 까만 명령창(터미널)에서 파일 이름을 타이핑해서 직접 실행할 수 있습니다. 예를 들어, 윈도우 컴퓨터의 현재 폴더에 있는 WordCount라는 실행 파일을 켜려면 이렇게 입력합니다.
WordCount
리눅스나 맥(Unix 기반 OS)에서는 보통 이렇게 입력하죠.
./WordCount
이 WordCount 프로그램에 명령줄 인수를 전달하는 방법은 아주 간단합니다.
그냥 프로그램 이름 뒤에 띄어쓰기를 하고 원하는 인수를 쭉 적어주면 됩니다.
WordCount Myfile.txt
이제 WordCount 프로그램이 실행될 때, Myfile.txt라는 글자가 명령줄 인수로서 프로그램에 쏙 들어갑니다. 스페이스바(띄어쓰기)를 기준으로 여러 개의 인수를 전달하는 것도 가능합니다.
WordCount Myfile.txt Myotherfile.txt
만약 명령창이 아니라 코드를 짜는 프로그램(IDE)에서 실행 버튼을 눌러 테스트하고 있다면, IDE 안에도 명령줄 인수를 입력할 수 있는 설정 창이 따로 있습니다.
- Microsoft Visual Studio의 경우: 솔루션 탐색기에서 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭한 뒤,
속성(Properties)을 선택하세요.구성 속성(Configuration Properties)아래의디버깅(Debugging)메뉴를 엽니다. 오른쪽 화면을 보면명령 인수(Command Arguments)라는 칸이 있습니다. 거기에 테스트할 인수를 적어두면, 실행 버튼을 누를 때마다 그 인수가 자동으로 프로그램에 전달됩니다. - Code::Blocks의 경우: 위쪽 메뉴에서
Project(프로젝트) -> Set program’s arguments(프로그램 인수 설정)를 선택하면 됩니다.
명령줄 인수 사용하기
자, 밖에서 프로그램 안으로 인수를 어떻게 던져주는지는 알게 되었습니다. 이제 해야 할 일은 C++ 코드 안에서 그 인수를 잘 받아서 사용하는 것이겠죠? 그러기 위해서 우리는 지금까지 썼던 텅 빈 main()과는 조금 다른 모양의 main() 함수를 써야 합니다. 이 새로운 main() 함수는 두 개의 매개변수를 받는데, C++ 세상의 관습에 따라 보통 argc와 argv라는 이름을 씁니다.
int main(int argc, char* argv[])
가끔 코드를 보다 보면 다음과 같이 쓰인 것도 볼 수 있습니다.
int main(int argc, char** argv)
컴퓨터 입장에서는 이 두 가지 코드가 완전히 똑같이 작동합니다. 하지만 첫 번째 방식이 눈으로 볼 때 배열(목록)이라는 느낌이 확 들어서 초보자가 직관적으로 이해하기 훨씬 쉽습니다.
그래서 보통 첫 번째 방식을 더 많이 사용합니다.
argc: 이 프로그램에 전달된 인수의 총 개수를 담고 있는 정수입니다. (쉽게 외우는 꿀팁: argument count의 줄임말입니다.) 사용자가 아무런 인수를 안 줬더라도argc는 무조건 최소 1입니다. 왜냐하면 '실행되는 프로그램의 이름 자기 자신'이 항상 첫 번째 인수로 들어가기 때문입니다. 사용자가 뒤에 인수를 하나씩 추가해서 적어줄 때마다 이argc숫자도 1씩 늘어납니다.argv: 실제로 전달된 인수 값(글자들)이 들어 있는 곳입니다. (꿀팁: argument values의 줄임말이라고 생각하세요. 정확한 명칭은 'argument vectors'입니다.)char* argv[]라는 선언 부분이 초보자에게는 살짝 무시무시하게 생겼지만, 전혀 겁먹을 필요 없습니다.argv는 그냥 여러 개의 글자 뭉치(문자열)를 줄지어 담아놓은 배열(목록)일 뿐입니다.
이 목록에 몇 개의 글자 뭉치가 들어있는지가 바로argc인 것이죠.
전달받은 모든 명령줄 인수를 화면에 출력해 주는 MyArgs라는 짧은 프로그램을 직접 만들어 봅시다.
// Program: MyArgs
#include <iostream>
int main(int argc, char* argv[])
{
std::cout << "There are " << argc << " arguments:\n"; // 인수가 총 argc개 있습니다:
// Loop through each argument and print its number and value
// (각 인수를 하나씩 차례대로 확인하면서 번호와 실제 값을 출력합니다)
for (int count{ 0 }; count < argc; ++count)
{
std::cout << count << ' ' << argv[count] << '\n';
}
return 0;
}
이제 명령창에서 Myfile.txt와 100이라는 인수를 달아서 프로그램(MyArgs)을 실행해 보면, 화면에 다음과 같이 출력됩니다.
There are 3 arguments:
0 C:\MyArgs
1 Myfile.txt
2 100
보시다시피 0번 인수는 현재 실행 중인 프로그램의 전체 경로와 이름입니다. 1번과 2번 인수가 바로 우리가 직접 뒤에 적어서 넘겨준 두 개의 명령줄 인수입니다.
참고로...
여기서argv배열을 하나씩 꺼내 볼 때 C++의 편리한 기능인 '범위 기반 for문(range-based for-loop)'을 사용할 수 없습니다.argv는 크기 정보가 깎여나간 옛날 C언어 스타일의 배열이기 때문에 작동하지 않거든요. 따라서 위 코드처럼 숫자를 세며 도는 고전적인for문을 사용해야 합니다.
숫자로 된 인수 다루기
아주 중요한 사실이 하나 있습니다. 명령줄 인수는 우리가 100처럼 숫자 형태를 적어서 넘겨주더라도, 프로그램 안으로는 무조건 '문자열(글자)' 형태로 들어옵니다. 즉 계산기처럼 숫자 100으로 인식하는 게 아니라 글자 "100"으로 인식한다는 뜻입니다.
그래서 명령줄 인수를 진짜 숫자처럼 계산에 쓰고 싶다면, 이 글자를 숫자로 바꿔주는 변환 과정이 반드시 필요합니다. 안타깝게도 C++에서는 이 과정이 초보자가 느끼기에 조금 복잡하게 느껴질 수 있습니다.
C++에서 글자를 숫자로 변환하는 대표적인 방법은 다음과 같습니다.
#include <iostream>
#include <sstream> // for std::stringstream (std::stringstream 기능을 사용하기 위해 필요합니다)
#include <string>
int main(int argc, char* argv[])
{
if (argc <= 1)
{
// On some operating systems, argv[0] can end up as an empty string instead of the program's name.
// We'll conditionalize our response on whether argv[0] is empty or not.
// (일부 운영체제에서는 프로그램 이름이 들어와야 할 argv[0]이 빈칸으로 들어올 수도 있습니다.
// 따라서 argv[0]이 비어있는지 아닌지에 따라 화면에 보여줄 안내문을 다르게 만듭니다.)
if (argv[0])
std::cout << "Usage: " << argv[0] << " <number>" << '\n'; // 올바른 사용법: (프로그램 이름) <숫자>
else
std::cout << "Usage: <program name> <number>" << '\n'; // 올바른 사용법: <프로그램 이름> <숫자>
return 1;
}
std::stringstream convert{ argv[1] }; // set up a stringstream variable named convert, initialized with the input from argv[1]
// (첫 번째 인수로 들어온 글자 argv[1]을 집어넣어, 'convert'라는 이름의 stringstream 변수를 만듭니다.)
int myint{};
if (!(convert >> myint)) // do the conversion (변환을 시도해 봅니다)
myint = 0; // if conversion fails, set myint to a default value (만약 숫자가 아닌 글자라서 변환에 실패하면, 기본값인 0으로 설정합니다)
std::cout << "Got integer: " << myint << '\n'; // 정수 획득 성공: (숫자)
return 0;
}
이 프로그램에 567이라는 입력을 같이 주어 실행하면 다음과 같이 나옵니다.
Got integer: 567
여기서 사용된 std::stringstream이라는 마법의 도구는 우리가 키보드로 입력을 받을 때 쓰는 std::cin과 작동 방식이 거의 똑같습니다. std::cin이 키보드 입력을 쭉 빨아들여서 숫자로 바꿔주듯이, 여기서는 argv[1]에 들어있는 글자("567")를 가져다 놓고 >> 기호를 사용해 쏙 뽑아내어 정수형 변수인 myint에 진짜 숫자로 저장하는 원리입니다.
std::stringstream에 대해서는 뒤에 나오는 챕터에서 훨씬 더 자세히 다룰 예정이니, 지금은 '아, 글자를 숫자로 바꿀 때 쓰는 도구구나' 정도로만 이해하셔도 충분합니다.
운영체제가 명령줄 인수를 먼저 분석합니다
명령창에 무언가를 타이핑해서 엔터를 치거나 IDE에서 프로그램을 실행할 때, 여러분의 명령을 제일 먼저 받아서 처리하는 것은 바로 운영체제(윈도우, 맥, 리눅스 등)입니다. 운영체제는 단순히 실행 파일을 더블클릭해서 켜주는 역할만 하는 게 아닙니다. 여러분이 띄어쓰기로 적어놓은 인수들을 어떻게 잘라서 프로그램에 넘겨줄지 먼저 분석(파싱)하는 아주 중요한 역할을 합니다.
일반적으로 운영체제들은 큰따옴표(")나 역슬래시(\) 같은 특수 문자를 만나면 자기만의 특별한 규칙을 적용합니다.
예를 들어 다음과 같이 띄어쓰기를 해서 입력하면:
MyArgs Hello world!
운영체제는 띄어쓰기를 기준으로 싹둑싹둑 자르기 때문에 아래처럼 두 개의 다른 인수로 들어갑니다.
There are 3 arguments:
0 C:\MyArgs
1 Hello
2 world!
하지만, 띄어쓰기가 있더라도 큰따옴표(")로 묶어주면 운영체제는 '아, 이건 떨어져 있어도 하나의 덩어리구나!'라고 똑똑하게 인식합니다.
MyArgs "Hello world!"
결과는 다음과 같이 띄어쓰기가 포함된 하나의 덩어리로 잘 나옵니다.
There are 2 arguments:
0 C:\MyArgs
1 Hello world!
그렇다면 큰따옴표 기호(") 그 자체를 글자로 넘겨주고 싶을 때는 어떻게 할까요? 대부분의 운영체제에서는 큰따옴표 앞에 역슬래시(\)를 붙여서 '이건 특수 기능이 아니라 그냥 일반 글자 큰따옴표야!'라고 알려줄 수 있습니다.
MyArgs \"Hello world!\"
이렇게 치면 앞뒤에 큰따옴표가 고스란히 달린 채로 글자가 잘 전달됩니다.
There are 3 arguments:
0 C:\MyArgs
1 "Hello
2 world!"
이 밖에도 여러분이 어떤 운영체제를 쓰느냐에 따라 특수문자를 일반 글자처럼 전달하기 위해(이스케이프 처리) 역슬래시를 붙여야 하는 문자가 더 있을 수 있습니다.
결론
명령줄 인수는 프로그램이 딱 켜지는 바로 그 순간에 사용자나 다른 프로그램이 아주 간편하게 입력 데이터를 던져줄 수 있는 훌륭한 방법입니다.
여러분이 앞으로 프로그램을 만들 때 시작하자마자 꼭 필요한 재료(데이터)가 있다면, 그것을 명령줄 인수로 받도록 설계해 보세요. 그리고 만약 깜빡하고 명령줄 인수를 안 넣고 실행했다면? 그땐 프로그램 안에서 스스로 알아채고 "파일 이름을 입력해주세요~"라고 물어보게끔 코드를 짜면 됩니다. 이렇게 두 가지 방식을 잘 섞어 쓰면, 수백 개 파일을 자동으로 돌릴 때도 편하고 직접 하나씩 실행할 때도 친절한 일석이조의 프로그램을 만들 수 있습니다.
20.5 — 생략 부호(Ellipsis)와 이를 피해야 하는 이유
지금까지 우리가 배운 모든 함수들은, 함수가 받을 '재료(매개변수)'의 개수를 미리 정확히 알고 있어야 했습니다. (기본값을 설정해 두었더라도 말이죠.) 하지만, 상황에 따라 함수에 원하는 개수만큼 마음대로 재료를 넘겨주고 싶을 때가 있습니다. C++에서는 이를 가능하게 해주는 특별한 기능인 생략 부호(ellipsis, ...)를 제공합니다.
생략 부호는 실제로 잘 사용되지 않으며, 잠재적으로 위험할 수 있어서 가급적 사용하지 않는 것을 권장합니다. 따라서 이 섹션의 내용은 가볍게 읽고 넘어가셔도 좋습니다.
생략 부호를 사용하는 함수는 다음과 같이 생겼습니다.
반환_타입 함수_이름(매개변수_목록, ...)
여기서 매개변수_목록은 우리가 평소에 쓰는 일반적인 매개변수들입니다. 중요한 점은, 생략 부호를 쓰려면 반드시 한 개 이상의 일반 매개변수가 앞에 있어야 한다는 것입니다. 함수에 전달된 값들은 먼저 일반 매개변수들의 자리를 채우게 됩니다.
점 세 개(...)로 표현되는 생략 부호는 반드시 함수의 맨 마지막 매개변수로 적어야 합니다. 이 생략 부호는 앞의 일반 매개변수들이 다 채워지고 남은 '추가 재료'들을 모두 쓸어 담는 역할을 합니다. 정확한 표현은 아니지만, 초보자분들은 이 생략 부호를 남은 매개변수들을 몽땅 담아두는 하나의 바구니(배열)라고 생각하시면 이해하기 쉽습니다.
생략 부호(Ellipsis) 예제
생략 부호를 배우는 가장 좋은 방법은 직접 코드를 보는 것입니다! 여러 개의 정수를 받아서 평균을 구해주는 간단한 프로그램을 만들어 보겠습니다. 코드는 다음과 같습니다:
#include <iostream>
#include <cstdarg> // 생략 부호를 사용하기 위해 꼭 필요합니다!
// 생략 부호(...)는 반드시 마지막 매개변수여야 합니다.
// count는 우리가 뒤에 추가로 몇 개의 숫자를 더 넘겨줄 것인지 알려줍니다.
double findAverage(int count, ...)
{
int sum{ 0 };
// 생략 부호에 담긴 값들을 꺼내 보려면 va_list라는 특별한 도구가 필요합니다.
std::va_list list;
// va_start를 사용해 va_list를 준비시킵니다.
// 첫 번째 인자는 방금 만든 list이고,
// 두 번째 인자는 생략 부호 바로 앞에 있던 마지막 일반 매개변수(여기선 count)입니다.
va_start(list, count);
// 생략 부호에 담긴 값의 개수만큼 반복문을 돌립니다.
for (int arg{ 0 }; arg < count; ++arg)
{
// va_arg를 사용해 생략 부호 바구니에서 값을 하나씩 꺼냅니다.
// 첫 번째 인자는 우리가 사용하는 list이고,
// 두 번째 인자는 우리가 꺼낼 값의 '타입(자료형)'입니다.
sum += va_arg(list, int);
}
// 작업이 다 끝났으면 va_list를 정리(청소)해 줍니다.
va_end(list);
return static_cast<double>(sum) / count;
}
int main()
{
// 5개의 숫자를 추가로 넘깁니다: 1, 2, 3, 4, 5
std::cout << findAverage(5, 1, 2, 3, 4, 5) << '\n';
// 6개의 숫자를 추가로 넘깁니다: 1, 2, 3, 4, 5, 6
std::cout << findAverage(6, 1, 2, 3, 4, 5, 6) << '\n';
return 0;
}
이 코드를 실행하면 다음과 같이 출력됩니다:
3
3.5
보시다시피, 이 함수는 매번 다른 개수의 숫자들을 받아들일 수 있습니다! 자, 이제 이 마법 같은 일이 어떻게 일어나는지 하나씩 뜯어볼까요?
- 가장 먼저
<cstdarg>헤더 파일을 포함해야 합니다. 이 파일 안에는 생략 부호에 숨겨진 값들을 꺼내 쓰는 데 필요한 핵심 도구들(va_list,va_arg,va_start,va_end)이 들어있습니다. - 그런 다음 함수를 선언합니다. 일반 매개변수가 최소 하나는 있어야 하죠. 여기서는
count라는 정수를 받아서, 뒤에 몇 개의 숫자가 더 따라올지 미리 알려줍니다. 그리고 맨 마지막에...을 적습니다. - 주의할 점은 생략 부호 매개변수에는 이름이 없다는 것입니다! 대신, 우리는
va_list라는 특별한 타입을 사용해 그 안의 값들에 접근합니다. 초보자분들은va_list를 생략 부호 바구니 안의 숫자들을 차례대로 가리키는 요술 손가락(포인터)이라고 생각하시면 좋습니다. 우리는 이 손가락의 이름을 간단히list라고 지었습니다. - 이제
va_start()를 불러서 이 요술 손가락이 첫 번째 추가 숫자를 가리키게 준비시킵니다. - 현재 손가락이 가리키는 값을 실제로 꺼내오려면
va_arg()를 씁니다. 이때 어떤 타입(예:int)으로 꺼낼지 알려줘야 합니다. 재미있는 점은,va_arg()로 값을 하나 꺼내면, 요술 손가락이 알아서 다음 숫자를 가리키도록 옆으로 이동한다는 것입니다! - 모든 작업이 끝나면
va_end()를 불러서 사용했던 도구를 깔끔하게 정리해 줍니다.
참고로, 처음부터 다시 값들을 읽고 싶다면 언제든지 va_start()를 다시 불러서 손가락을 맨 처음 위치로 되돌릴 수 있습니다.
생략 부호가 위험한 이유 첫 번째: 타입 검사(Type checking)가 무시됩니다
생략 부호는 매개변수 개수를 마음대로 조절할 수 있는 엄청난 자유를 줍니다. 하지만, 큰 자유에는 큰 책임이 따르는 법이죠.
일반적으로 C++ 컴파일러는 아주 꼼꼼한 선생님 같습니다. 함수가 정수(int)를 원하는데 여러분이 문자열(string)을 넘겨주면, "타입이 안 맞잖아!"라며 경고를 주고 실행을 막아줍니다. 이를 '타입 검사'라고 합니다.
하지만 생략 부호 안으로 들어가는 값들에 대해서는 컴파일러가 이 검사를 아예 포기해 버립니다. 즉, 아무 타입이나 막 집어넣을 수 있다는 뜻입니다. 문제는, 여러분이 실수로 말도 안 되는 값을 넣어도 컴파일러가 아무런 경고를 해주지 않는다는 것입니다. 오직 함수를 호출하는 사람(여러분)이 알아서 올바른 값을 넣었기를 기도해야 합니다. 당연히 실수가 발생하기 아주 쉽겠죠?
아주 미묘하지만 치명적인 실수 예시를 보겠습니다:
// 두 번째 숫자(첫 번째 추가 숫자)로 정수 1이 아니라 소수점 1.0(double)을 넣었습니다!
std::cout << findAverage(6, 1.0, 2, 3, 4, 5, 6) << '\n';
언뜻 보면 별문제가 없어 보입니다. 컴파일도 완벽하게 됩니다. 하지만 결과는 아주 충격적입니다:
1.78782e+008
무려 1억 7천만이 넘는 엄청나게 큰 쓰레기 값이 나왔습니다. 도대체 무슨 일이 일어난 걸까요?
컴퓨터는 모든 데이터를 0과 1의 조합(비트)으로 저장합니다. 변수의 '타입'은 컴퓨터에게 이 0과 1들을 어떻게 해석할지 알려주는 설명서와 같습니다. 그런데 앞서 말했듯, 생략 부호는 이 '타입 설명서'를 갖다 버립니다! 그래서 값을 제대로 꺼내려면 va_arg()에게 "이번에 꺼낼 값은 int야!"라고 수동으로 알려줘야 합니다.
위 코드에서 우리는 함수 안에서 va_arg(list, int)를 쓰며 모든 값이 int(정수)일 것이라고 찰떡같이 믿고 있었습니다. 그런데 우리가 넣은 1.0은 double(실수) 타입이고 크기가 8바이트입니다. 반면 int는 4바이트죠.
결과적으로 va_arg는 8바이트짜리 실수 데이터의 절반(4바이트)만 뚝 잘라서 정수로 잘못 해석해 버리고, 다음번엔 나머지 절반을 또 정수로 해석합니다. 데이터가 완전히 꼬여버려서 '쓰레기 값'이 나오게 된 것입니다.
심지어 아래처럼 말도 안 되는 코드를 짜도 컴파일러는 불평 한마디 안 합니다:
int value{ 7 };
// 소수점, 문자열, 문자, 변수의 주소, 함수의 주소 등 온갖 잡동사니를 다 넣었습니다.
std::cout << findAverage(6, 1.0, 2, "Hello, world!", 'G', &value, &findAverage) << '\n';
믿기 어렵겠지만, 이 코드도 정상적으로 컴파일되며 작성자의 컴퓨터에서는 1.79766e+008이라는 쓰레기 값을 내뱉었습니다.
컴퓨터 공학에는 "쓰레기가 들어가면 쓰레기가 나온다 (Garbage in, garbage out)"라는 유명한 말이 있습니다. 컴퓨터는 바보 같아서, 사람이 아무리 터무니없는 데이터를 줘도 의심 없이 처리하고 터무니없는 결과를 돌려준다는 뜻이죠. 생략 부호가 딱 이렇습니다.
생략 부호가 위험한 이유 두 번째: 매개변수가 몇 개나 전달되었는지 모릅니다
생략 부호는 값의 '타입'만 버리는 게 아니라, 값이 '몇 개'나 들어왔는지도 잊어버립니다. 그래서 우리가 직접 몇 개의 값이 들어왔는지 추적하는 방법을 만들어내야 합니다. 보통 다음 3가지 방법 중 하나를 사용합니다.
방법 1: 길이(개수)를 매개변수로 전달하기
첫 번째 방법은, 우리가 앞서 findAverage() 예제에서 했던 것처럼 앞쪽 일반 매개변수로 "내가 추가로 O개의 값을 더 줄게!"라고 미리 개수를 알려주는 것입니다.
하지만 이 방법도 완벽하진 않습니다. 아래 코드를 볼까요?
// "6개 줄게!" 라고 해놓고 실제로는 5개(1, 2, 3, 4, 5)만 줬습니다.
std::cout << findAverage(6, 1, 2, 3, 4, 5) << '\n';
이 코드를 실행하면 699773 같은 이상한 값이 나옵니다. 왜 그럴까요?
우리는 함수에게 6개를 달라고 했지만 5개밖에 주지 않았습니다. 함수는 5개까지는 잘 꺼내지만, 6번째 값을 찾기 위해 컴퓨터 메모리의 엉뚱한 공간(스택)을 뒤져서 아무 쓰레기 값이나 가져와 버렸기 때문입니다.
더 잡기 힘든 실수도 있습니다:
// "6개 줄게!" 라고 해놓고 실수로 7개(1, 2, 3, 4, 5, 6, 7)를 줬습니다.
std::cout << findAverage(6, 1, 2, 3, 4, 5, 6, 7) << '\n';
이 결과는 3.5가 나옵니다. 얼핏 맞게 나온 것 같지만, 사실 함수는 6번째 숫자인 6까지만 계산하고 맨 마지막에 있는 7은 완전히 무시해 버렸습니다. 이런 종류의 실수는 버그를 찾아내기가 정말 힘듭니다.
방법 2: 보초값(Sentinel value) 사용하기
두 번째 방법은 끝을 알리는 특별한 표지판, 즉 '보초값'을 사용하는 것입니다. 문자열의 끝을 알리는 널 종료 문자(\0)를 생각하시면 됩니다. 생략 부호에서는 보통 맨 마지막 값으로 이 보초값을 줍니다. 끝을 알리는 표지판으로 -1을 사용하는 예제를 살펴봅시다:
#include <iostream>
#include <cstdarg>
// 생략 부호는 마지막에 와야 합니다.
double findAverage(int first, ...)
{
// 첫 번째 숫자는 따로 처리해 줍니다.
int sum{ first };
std::va_list list;
// 첫 번째 매개변수(first)를 기준으로 va_list를 초기화합니다.
va_start(list, first);
int count{ 1 };
// 무한 반복을 돕니다.
while (true)
{
// 값을 하나 꺼냅니다.
int arg{ va_arg(list, int) };
// 만약 꺼낸 값이 우리가 정한 보초값(-1)이라면 반복문을 탈출합니다!
if (arg == -1)
break;
sum += arg;
++count;
}
va_end(list);
return static_cast<double>(sum) / count;
}
int main()
{
// 맨 마지막에 끝을 알리는 -1을 꼭 넣어줍니다.
std::cout << findAverage(1, 2, 3, 4, 5, -1) << '\n';
std::cout << findAverage(1, 2, 3, 4, 5, 6, -1) << '\n';
return 0;
}
이제 첫 번째 매개변수로 "몇 개를 줄 건지" 미리 말하지 않아도 됩니다. 대신 끝에 보초값만 잘 꽂아주면 되죠.
하지만 여기에도 단점이 있습니다.
첫째, C++ 규칙상 생략 부호 앞에는 일반 매개변수가 꼭 하나 있어야 합니다. 그래서 평균을 낼 첫 번째 숫자를 일반 매개변수(first)로 억지로 빼내어 따로 처리해야 하는 번거로움이 생겼습니다.
둘째, 사용자가 맨 끝에 보초값 넣는 것을 깜빡하면 함수는 -1이 우연히 나올 때까지 메모리를 끝없이 헤집고 다니며 무한 루프를 돌거나 프로그램이 팅겨버립니다.
셋째, 만약 우리가 음수(-1)까지 포함해서 평균을 내고 싶다면 어떻게 될까요? -1을 더 이상 끝을 알리는 신호로 쓸 수 없게 됩니다. 보초값은 '내가 계산하려는 실제 데이터 중에는 절대 나올 수 없는 값'으로 정해야만 안전합니다.
방법 3: 해독 문자열(Decoder string) 사용하기
세 번째 방법은, 마치 암호문 같은 "해독 문자열"을 넘겨주어 프로그램에게 매개변수의 개수와 타입을 친절하게 알려주는 방식입니다.
#include <iostream>
#include <string_view>
#include <cstdarg>
// 첫 번째 매개변수로 해독 문자열(decoder)을 받습니다.
double findAverage(std::string_view decoder, ...)
{
double sum{ 0 };
std::va_list list;
va_start(list, decoder);
// 해독 문자열의 글자를 하나씩 확인합니다.
for (auto codetype: decoder)
{
switch (codetype)
{
case 'i': // 글자가 'i'이면 정수(int)로 꺼냅니다.
sum += va_arg(list, int);
break;
case 'd': // 글자가 'd'이면 실수(double)로 꺼냅니다.
sum += va_arg(list, double);
break;
}
}
va_end(list);
// 해독 문자열의 길이(std::size)가 곧 매개변수의 개수입니다.
return sum / std::size(decoder);
}
int main()
{
// "iiiii" -> 5개의 정수(i)가 뒤따라온다는 뜻입니다.
std::cout << findAverage("iiiii", 1, 2, 3, 4, 5) << '\n';
// "iiiiii" -> 6개의 정수(i)가 뒤따라옵니다.
std::cout << findAverage("iiiiii", 1, 2, 3, 4, 5, 6) << '\n';
// "iiddi" -> 정수, 정수, 실수, 실수, 정수 순서로 온다는 뜻입니다!
std::cout << findAverage("iiddi", 1, 2, 3.5, 4.5, 5) << '\n';
return 0;
}
이 방식의 가장 큰 장점은 여러 가지 다양한 타입(정수, 실수 등)을 섞어서 받을 수 있다는 것입니다. 하지만 암호문 문자열을 작성하는 게 조금 복잡해 보일 수 있고, 만약 여러분이 실수로 암호문과 실제 데이터를 다르게 적는다면 여전히 끔찍한 에러가 발생합니다.
(C 언어를 배워보신 분이라면 눈치채셨겠지만, 여러분이 흔히 쓰던 printf 함수가 정확히 이 방식(%d, %f 등)을 사용합니다!)
생략 부호를 더 안전하게 사용하는 권장 사항
- 가장 좋은 방법은 생략 부호를 아예 쓰지 않는 것입니다! 조금 번거롭더라도 더 안전한 다른 대안들이 많습니다. 예를 들어, 위의 평균 구하기 예제라면 개수를 마음대로 늘렸다 줄일 수 있는 동적 배열(
std::vector같은 것)을 넘겨주는 것이 훨씬 좋습니다. 그러면 컴파일러가 강력한 타입 검사를 해줘서 이상한 값이 들어오는 걸 막아주면서도, 원하는 개수만큼 데이터를 넘길 수 있습니다. - 부득이하게 생략 부호를 꼭 써야 한다면, 모든 추가 매개변수의 타입을 똑같이 통일하는 것이 좋습니다. (전부 다
int로 하거나 전부 다double로 하는 식으로요.) 정수와 실수를 막 섞어 쓰면 타입이 꼬여서 쓰레기 값이 나올 확률이 폭발적으로 늘어납니다. - 개수를 직접 알려주거나 해독 문자열을 쓰는 방식(방법 1, 3)이 보초값을 쓰는 방식(방법 2)보다 그나마 안전합니다. 적어도 사용자가 횟수를 명확히 정해주기 때문에, 잘못된 값이 들어가더라도 무한 루프에 빠지는 대참사는 막을 수 있기 때문입니다.
고급 학습자를 위한 내용
기존 생략 부호의 단점을 개선하기 위해, C++11에서는 매개변수 팩(parameter packs)과 가변 인자 템플릿(variadic templates)이라는 기능을 도입했습니다. 이는 생략 부호처럼 개수가 자유로우면서도 강력한 타입 검사를 지원합니다. 하지만 사용법이 너무 어려워 널리 쓰이지는 못했습니다.
이후 C++17에서 폴드 표현식(fold expressions)이 추가되면서 매개변수 팩의 사용성이 크게 개선되었고, 현재는 생략 부호를 대체할 아주 실용적인 선택지가 되었습니다.
이 사이트의 향후 업데이트에서 이 멋진 주제들에 대한 강의를 추가할 예정입니다.
20.6 — 람다(익명 함수) 소개
18.3 레슨(표준 라이브러리 알고리즘 소개)에서 다루었던 다음 코드를 한번 살펴볼까요?
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
// 요소가 일치하면 이 함수는 true를 반환합니다.
bool containsNut(std::string_view str)
{
// std::string_view::find는 부분 문자열을 찾지 못하면 std::string_view::npos를 반환합니다.
// 찾았다면 str 안에서 해당 부분 문자열이 시작하는 인덱스(위치)를 반환합니다.
return str.find("nut") != std::string_view::npos;
}
int main()
{
constexpr std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
// 배열을 훑어보면서 "nut"이라는 글자가 포함된 요소가 있는지 확인합니다.
auto found{ std::find_if(arr.begin(), arr.end(), containsNut) };
if (found == arr.end())
{
std::cout << "No nuts\n";
}
else
{
std::cout << "Found " << *found << '\n';
}
return 0;
}
이 코드는 문자열 배열을 검색해서 "nut"이라는 글자가 들어간 첫 번째 단어를 찾습니다. 실행하면 다음과 같은 결과가 나옵니다.
Found walnut
코드가 잘 작동하긴 하지만, 좀 더 깔끔하게 고칠 수 있습니다.
가장 큰 문제는 std::find_if 함수를 사용할 때 함수 포인터를 넘겨주어야 한다는 점입니다. 겨우 딱 한 번 쓰고 말 함수인데도 굳이 이름을 지어줘야 하고, 함수 안에 함수를 만들 수 없으니 코드 맨 바깥쪽(전역 범위)에 덩그러니 만들어야 하죠. 게다가 함수 내용이 너무 짧아서, 함수 이름이나 주석을 읽는 것보다 그냥 코드 한 줄을 보는 게 이해하기 더 빠를 정도입니다.
람다는 이름이 없는 익명 함수입니다
람다 표현식(간단히 람다 또는 클로저라고도 부릅니다)을 사용하면 함수 안에서 '이름이 없는 함수'를 뚝딱 만들 수 있습니다. 이렇게 함수 안에 함수를 중첩해서 만들면 이름이 겹쳐서 코드가 지저분해지는 것(이름 공간 오염)을 막을 수 있고, 함수를 실제로 사용하는 곳 바로 옆에 정의할 수 있어서 코드를 읽기 훨씬 편해집니다.
C++에서 람다 문법은 처음 보면 굉장히 특이하게 생겨서 적응할 시간이 조금 필요합니다. 람다는 다음과 같은 모양을 가집니다.
[ 캡처_블록 ] ( 매개변수 ) -> 반환_타입
{
실행할_코드;
}
- 캡처 블록 (Capture clause): 바깥쪽 변수를 가져다 쓸 필요가 없다면 비워두어도 됩니다
[]. - 매개변수 (Parameters): 함수에 전달할 값이 없다면 비워둘 수 있습니다
(). 반환 타입을 따로 적지 않는다면 괄호 자체를 아예 생략할 수도 있습니다. - 반환 타입 (Return type): 생략 가능합니다. 생략하면 컴파일러가
auto처럼 알아서 결과값을 보고 타입을 유추해 줍니다. 일반 함수에서는 반환 타입을 컴파일러에게 맡기는 것을 피하라고 했지만, 람다는 보통 코드가 아주 짧고 단순하기 때문에 컴파일러에게 맡겨도 괜찮습니다.
그리고 람다는 이름이 없는(익명) 함수이므로 이름을 지어줄 필요가 전혀 없습니다.
참고로...
가장 단순한 형태의 람다는 다음과 같이 생겼습니다.#include <iostream> int main() { [] {}; // 반환 타입 생략, 캡처 없음, 매개변수 생략된 가장 단순한 람다입니다. return 0; }이제 처음 보았던 예제를 람다를 사용해서 다시 써보겠습니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
// 함수가 필요한 바로 그 자리에 함수를 직접 정의합니다.
auto found{ std::find_if(arr.begin(), arr.end(),
[](std::string_view str) // 여기가 람다입니다. 캡처 블록은 비어있습니다.
{
return str.find("nut") != std::string_view::npos;
}) };
if (found == arr.end())
{
std::cout << "No nuts\n";
}
else
{
std::cout << "Found " << *found << '\n';
}
return 0;
}
함수 포인터를 사용했을 때와 완벽하게 똑같이 작동하며, 결과도 동일합니다.
새로 만든 람다를 원래 있던 containsNut 함수와 비교해 보세요. 매개변수와 안의 내용이 완전히 똑같죠? 외부 변수를 쓸 일이 없으니 캡처 블록([])은 비워두었고(캡처 블록에 대해서는 다음 레슨에서 자세히 배웁니다), 코드를 짧게 쓰기 위해 반환 타입(-> bool)도 생략했습니다. != 연산자가 어차피 bool(참/거짓)을 반환하기 때문에 람다도 알아서 bool을 반환하게 됩니다.
권장 사항
코드는 항상 가장 좁은 범위에서, 그리고 처음 사용하는 곳과 가장 가까운 곳에 정의하는 것이 좋습니다. 다른 함수에 인자로 넘겨주기 위해 딱 한 번만 사용할 아주 단순한 함수가 필요하다면, 일반 함수를 만드는 것보다 람다를 사용하는 것이 훨씬 좋습니다.
람다의 타입
위 예제에서는 람다가 필요한 자리에 곧바로 람다를 적어 넣었습니다. 이렇게 사용하는 것을 함수 리터럴(function literal)이라고 부르기도 합니다.
하지만 함수를 호출하는 줄에 람다를 통째로 길게 적으면 코드가 읽기 힘들어질 때가 있습니다. 숫자나 문자를 변수에 미리 저장해두고 나중에 꺼내 쓰는 것처럼, 람다도 변수에 저장해두었다가 나중에 사용할 수 있습니다. 람다에 뜻을 알기 쉬운 이름을 붙여서 변수에 저장해두면 코드를 읽기가 훨씬 편해집니다.
예를 들어, 아래 코드는 배열의 모든 숫자가 짝수인지 확인하는 코드입니다.
// 나쁨: 이 코드가 무슨 일을 하는지 이해하려면 람다 내부 코드를 직접 읽어봐야 합니다.
return std::all_of(array.begin(), array.end(), [](int i){ return ((i % 2) == 0); });
이 코드를 변수를 활용해 읽기 쉽게 바꾸면 다음과 같습니다.
// 좋음: 대신 람다를 이름 있는 변수에 저장하고 그 변수를 함수에 전달합니다.
auto isEven{
[](int i)
{
return (i % 2) == 0;
}
};
return std::all_of(array.begin(), array.end(), isEven);
마지막 줄을 소리 내어 읽어보세요. "배열(array)의 모든(all_of) 요소가 짝수인지(isEven) 확인해서 반환하라"처럼 아주 자연스럽게 읽힙니다!
핵심 통찰
람다를 변수에 저장하면 람다에 유용한 이름을 붙여줄 수 있어서 코드가 훨씬 읽기 편해집니다. 또한, 람다를 변수에 저장해두면 똑같은 람다를 여러 번 재사용할 수도 있습니다.
그런데 여기서 질문! 변수 isEven의 데이터 타입(자료형)은 대체 무엇일까요?
놀랍게도 람다에는 우리가 직접 코드에 적을 수 있는 명확한 타입 이름이 없습니다. 우리가 람다를 만들면 컴파일러가 알아서 세상에 단 하나뿐인 고유한 비밀 타입을 만들어냅니다.
고급 학습자를 위한 내용
사실 람다는 진짜 함수가 아닙니다 (이것이 C++에서 함수 안에 함수를 못 만드는 규칙을 피해 갈 수 있는 비결이기도 합니다). 람다는 함수처럼 호출해서 쓸 수 있도록operator()가 오버로딩된 함수 객체(functor)라는 특별한 형태의 객체입니다.
우리가 람다의 진짜 타입 이름은 알 수 없지만, 만든 람다를 변수에 저장하는 방법은 여러 가지가 있습니다. 람다의 캡처 블록이 비어있다면([] 안에 아무것도 없다면) 일반적인 함수 포인터에 저장할 수 있습니다. 또는 캡처 블록이 비어있지 않더라도 std::function이나 auto 키워드를 사용해 저장할 수 있습니다.
#include <functional>
int main()
{
// 1. 일반 함수 포인터. 캡처 블록이 비어있을 때(빈 [])만 사용할 수 있습니다.
double (*addNumbers1)(double, double){
[](double a, double b) {
return a + b;
}
};
addNumbers1(1, 2);
// 2. std::function 사용. 캡처 블록이 비어있지 않아도 사용할 수 있습니다 (다음 레슨에서 다룹니다).
std::function addNumbers2{ // 참고: C++17 이전 버전에서는 std::function<double(double, double)> 라고 써야 합니다.
[](double a, double b) {
return a + b;
}
};
addNumbers2(3, 4);
// 3. auto 사용. 람다의 진짜(숨겨진) 타입 그대로 변수에 저장합니다.
auto addNumbers3{
[](double a, double b) {
return a + b;
}
};
addNumbers3(5, 6);
return 0;
}
람다의 '진짜 타입'을 그대로 살려서 저장하는 유일한 방법은 auto를 사용하는 것뿐입니다. 게다가 auto를 사용하면 std::function을 사용할 때 발생하는 미세한 성능 저하(오버헤드)도 피할 수 있습니다.
그렇다면 다른 함수에 람다를 인자로 넘겨주고 싶을 때는 어떻게 해야 할까요?
여기에는 4가지 방법이 있습니다.
#include <functional>
#include <iostream>
// 방법 1: `std::function` 매개변수 사용
void repeat1(int repetitions, const std::function<void(int)>& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// 방법 2: 타입 템플릿 매개변수를 가진 함수 템플릿 사용
template <typename T>
void repeat2(int repetitions, const T& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// 방법 3: 축약된 함수 템플릿 문법 사용 (C++20부터)
void repeat3(int repetitions, const auto& fn)
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
// 방법 4: 함수 포인터 사용 (캡처가 없는 람다에만 가능)
void repeat4(int repetitions, void (*fn)(int))
{
for (int i{ 0 }; i < repetitions; ++i)
fn(i);
}
int main()
{
auto lambda = [](int i)
{
std::cout << i << '\n';
};
repeat1(3, lambda);
repeat2(3, lambda);
repeat3(3, lambda);
repeat4(3, lambda);
return 0;
}
- 방법 1은
std::function을 사용합니다. 매개변수로 무엇을 받고 무엇을 반환하는지 명확하게 보여서 좋습니다. 하지만 함수를 호출할 때마다 람다를 은근슬쩍 변환해야 해서 미세한 성능 저하가 생깁니다. 코드를 헤더 파일과.cpp파일로 나누기 쉽다는 장점도 있습니다. - 방법 2는 템플릿(
T)을 사용합니다. 코드가 실행될 때 람다의 진짜 타입에 맞춰 가장 빠르고 효율적으로 작동하지만, 매개변수나 반환 타입을 한눈에 파악하기 어렵다는 단점이 있습니다. - 방법 3은 C++20의
auto를 사용한 방법으로, 내부적으로는 방법 2와 완전히 똑같은 템플릿을 만들어냅니다. - 방법 4는 함수 포인터를 사용합니다. 캡처가 없는 단순한 람다는 함수 포인터로 자동 변환되기 때문에 가능한 방법입니다.
권장 사항
람다를 변수에 저장할 때는 무조건auto를 사용하세요.
람다를 다른 함수로 넘겨줄 때는:
- C++20 이상을 사용 중이라면 매개변수 타입으로
auto를 사용하세요.- 그 이전 버전을 사용 중이라면 함수 템플릿이나
std::function을 사용하세요 (캡처가 없는 단순 람다라면 함수 포인터도 괜찮습니다).
제네릭 람다
기본적으로 람다의 매개변수는 일반 함수의 매개변수와 똑같이 작동합니다.
하지만 아주 중요한 차이점이 하나 있는데, C++14부터 람다의 매개변수 타입으로 auto를 사용할 수 있다는 점입니다 (참고로 C++20부터는 일반 함수도 매개변수에 auto를 쓸 수 있게 되었습니다).
매개변수에 auto를 적어두면, 람다를 호출할 때 넘겨주는 값을 보고 컴파일러가 알아서 알맞은 데이터 타입을 맞춰줍니다. 이렇게 auto 매개변수를 가져서 어떤 데이터 타입이든 유연하게 받아낼 수 있는 람다를 제네릭 람다(generic lambdas)라고 부릅니다.
고급 학습자를 위한 내용
람다에서auto를 사용하는 것은 사실 템플릿 매개변수를 짧게 줄여 쓴 것과 같습니다.
제네릭 람다를 사용하는 예제를 볼까요?
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array months{ // C++17 이전에는 std::array<const char*, 12> 라고 써야 합니다.
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
// 같은 알파벳으로 시작하는 연속된 두 달을 찾습니다.
const auto sameLetter{ std::adjacent_find(months.begin(), months.end(),
[](const auto& a, const auto& b) {
return a[0] == b[0];
}) };
// 두 달을 무사히 찾았는지 확인합니다.
if (sameLetter != months.end())
{
// std::next는 sameLetter 바로 다음 요소를 가리킵니다.
std::cout << *sameLetter << " and " << *std::next(sameLetter)
<< " start with the same letter\n";
}
return 0;
}
결과는 다음과 같습니다.
June and July start with the same letter
이 예제에서는 auto 매개변수를 사용해 문자열을 전달받았습니다. 어떤 종류의 문자열이든 대괄호([])를 사용해 첫 번째 글자를 가져올 수 있기 때문에, 사용자가 넘겨준 값이 std::string이든 그냥 옛날 방식의 문자열이든 신경 쓸 필요가 없습니다. 덕분에 나중에 months 배열의 데이터 타입을 바꾸더라도 람다 코드는 하나도 고칠 필요가 없습니다.
하지만 auto가 항상 최고의 선택인 것은 아닙니다. 다음 예제를 보세요.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
constexpr std::array months{ // C++17 이전에는 std::array<const char*, 12> 라고 써야 합니다.
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
// 알파벳 5글자로 된 달이 몇 개인지 셉니다.
const auto fiveLetterMonths{ std::count_if(months.begin(), months.end(),
[](std::string_view str) {
return str.length() == 5;
}) };
std::cout << "There are " << fiveLetterMonths << " months with 5 letters\n";
return 0;
}
결과는 다음과 같습니다.
There are 2 months with 5 letters
이 예제에서 만약 auto를 썼다면 컴파일러는 데이터 타입을 다루기 까다로운 const char*(옛날 C언어 방식 문자열)로 추론했을 것입니다. 길이를 재려면 복잡해지죠. 그래서 여기서는 명시적으로 std::string_view 타입이라고 딱 정해주는 것이 좋습니다. 그러면 사용자가 C언어 방식 문자열을 넘겨주더라도 길이를 쉽게 구할 수(str.length()) 있기 때문입니다.
Constexpr 람다
C++17부터 람다가 만들어내는 결과가 상수 표현식(항상 변하지 않는 고정된 값)의 조건을 만족하면 암묵적으로 컴파일 시간에 계산되는 constexpr로 취급됩니다.
보통 다음 두 가지 조건을 만족해야 합니다.
- 람다에 캡처가 아예 없거나, 캡처하는 모든 것이
constexpr이어야 합니다. - 람다 안에서 호출하는 함수들도 모두
constexpr이어야 합니다. 참고로 표준 라이브러리의 많은 알고리즘과 수학 함수들은 C++20이나 C++23이 되어서야constexpr로 만들어졌습니다.
위의 '5글자 달 세기' 예제는 C++17에서는 constexpr이 될 수 없지만, std::count_if 함수가 constexpr로 개선된 C++20부터는 가능해집니다. 즉, C++20부터는 다음과 같이 결과를 컴파일 시간에 미리 계산해둘 수 있습니다.
constexpr auto fiveLetterMonths{ std::count_if(months.begin(), months.end(),
[](std::string_view str) {
return str.length() == 5;
}) };
제네릭 람다와 정적(static) 변수
11.7 레슨에서 함수 템플릿 안에 정적(static) 변수가 있으면, 템플릿에서 만들어지는 각각의 함수마다 자기만의 고유한 정적 변수를 따로 가지게 된다고 배웠습니다.
제네릭 람다 안의 auto 매개변수도 원리가 똑같기 때문에 같은 일이 벌어집니다. 넘겨받는 데이터 타입이 달라질 때마다 완전히 새로운 람다가 하나씩 복제되어 만들어집니다.
아래 예제를 보면 하나의 제네릭 람다가 어떻게 두 개의 독립적인 람다로 나뉘는지 확인할 수 있습니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
// 값을 출력하고, 이 람다가 지금까지 몇 번 호출되었는지 횟수를 셉니다.
auto print{
[](auto value) {
static int callCount{ 0 };
std::cout << callCount++ << ": " << value << '\n';
}
};
print("hello"); // 0: hello
print("world"); // 1: world
print(1); // 0: 1
print(2); // 1: 2
print("ding dong"); // 2: ding dong
return 0;
}
결과는 다음과 같습니다.
0: hello
1: world
0: 1
1: 2
2: ding dong
문자열("hello", "world" 등)을 넘겨줬을 때와 숫자(1, 2)를 넘겨줬을 때 각각 다른 버전의 람다가 만들어집니다.
대부분의 경우에는 별문제가 없지만, 람다 안에 static 변수가 있다면 이야기가 달라집니다. 문자열 전용 람다와 숫자 전용 람다가 각자의 callCount 변수를 따로 관리하게 되는 것이죠! 출력 결과를 보면 문자열을 넣었을 때와 숫자를 넣었을 때 숫자가 따로 올라가는 것을 볼 수 있습니다.
모든 람다가 하나의 변수(callCount)를 같이 공유하게 만들려면 람다 바깥에 전역 변수나 정적 지역 변수를 만들어야 합니다. 하지만 이전 레슨에서 배웠듯이 이런 변수들은 버그를 만들고 코드를 복잡하게 할 수 있습니다. 이 문제는 다음 레슨에서 '람다 캡처'를 배우면 깔끔하게 해결할 수 있습니다.
반환 타입 추론과 후행 반환 타입
람다에서 반환 타입을 생략해서 컴파일러에게 추론을 맡길 경우, 람다 안에 있는 return 문장들을 보고 타입을 결정합니다. 이때 람다 안의 모든 return 문장은 반드시 똑같은 데이터 타입을 반환해야 합니다 (그렇지 않으면 컴파일러가 도대체 어느 타입에 맞춰야 할지 몰라 혼란에 빠집니다).
예를 들어볼까요:
#include <iostream>
int main()
{
auto divide{ [](int x, int y, bool intDivision) { // 참고: 반환 타입이 명시되지 않음
if (intDivision)
return x / y; // 반환 타입은 int (정수)
else
return static_cast<double>(x) / y; // 에러: 이전 반환 타입(int)과 일치하지 않음 (double)
} };
std::cout << divide(3, 2, true) << '\n';
std::cout << divide(3, 2, false) << '\n';
return 0;
}
이 코드는 에러가 납니다. 첫 번째 return은 정수(int)를 돌려주려고 하는데, 두 번째 return은 소수(double)를 돌려주려고 하기 때문입니다.
이렇게 상황에 따라 다른 타입을 반환하고 싶다면 두 가지 해결책이 있습니다.
- 모든
return값이 똑같은 타입이 되도록 직접 형태를 변환(캐스팅)해주거나, - 람다의 반환 타입을 명시적으로 딱 정해줘서 컴파일러가 알아서 알맞게 변환하도록 맡기는 것입니다.
보통은 두 번째 방법이 훨씬 깔끔하고 좋습니다.
#include <iostream>
int main()
{
// 참고: -> double을 써서 반환 값이 double 타입임을 명확히 적어줍니다.
auto divide{ [](int x, int y, bool intDivision) -> double {
if (intDivision)
return x / y; // 결과값(int)을 알아서 double로 변환해 줍니다.
else
return static_cast<double>(x) / y;
} };
std::cout << divide(3, 2, true) << '\n';
std::cout << divide(3, 2, false) << '\n';
return 0;
}
이렇게 명확하게 -> double이라고 적어두면, 나중에 반환 타입을 고치고 싶을 때 람다 내부의 복잡한 코드는 건드릴 필요 없이 저 -> double 부분만 수정하면 되어서 무척 편리합니다.
표준 라이브러리 함수 객체
덧셈, 음수 만들기, 대소 비교 같이 아주 뻔하고 자주 쓰는 기능들을 위해 매번 람다를 직접 만들 필요는 없습니다. C++ 표준 라이브러리인 <functional> 헤더에는 이미 만들어져 있는 유용한 함수 객체들이 아주 많습니다.
아래 예제를 보세요.
#include <algorithm>
#include <array>
#include <iostream>
bool greater(int a, int b)
{
// a가 b보다 크면 a를 b보다 앞에 배치합니다.
return a > b;
}
int main()
{
std::array arr{ 13, 90, 99, 5, 40, 80 };
// 정렬 함수인 std::sort에 greater 함수를 넘겨줍니다.
std::sort(arr.begin(), arr.end(), greater);
for (int i : arr)
{
std::cout << i << ' ';
}
std::cout << '\n';
return 0;
}
결과는 다음과 같습니다.
99 90 80 40 13 5
이 코드를 위해 greater라는 함수를 람다로 일일이 바꾸는 것은 귀찮은 일입니다. 대신 이미 C++에 만들어져 있는 std::greater를 가져다 쓰면 아주 간단합니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <functional> // std::greater를 사용하기 위해 포함합니다.
int main()
{
std::array arr{ 13, 90, 99, 5, 40, 80 };
// std::greater를 std::sort에 넘겨줍니다.
std::sort(arr.begin(), arr.end(), std::greater{}); // 참고: 객체를 생성하기 위해 중괄호 {} 가 필요합니다.
for (int i : arr)
{
std::cout << i << ' ';
}
std::cout << '\n';
return 0;
}
결과는 다음과 같습니다.
99 90 80 40 13 5
결론
람다와 알고리즘 라이브러리를 함께 쓰는 것이 처음에는 for나 while 같은 일반적인 반복문(loop)을 쓰는 것보다 불필요하게 복잡해 보일 수 있습니다. 하지만 이 조합을 잘 활용하면 단 몇 줄의 코드만으로도 굉장히 강력한 기능을 만들 수 있고, 나중에는 오히려 반복문보다 읽기 훨씬 편해집니다.
무엇보다도, 알고리즘 라이브러리는 일반 반복문으로는 쉽게 하기 힘든 강력하고 편리한 병렬 처리(동시에 여러 작업 처리) 기능을 제공합니다. 일반 반복문으로 짠 코드를 업그레이드하는 것보다 라이브러리를 사용한 코드를 업그레이드하는 것이 훨씬 쉽고 안전합니다.
람다는 정말 훌륭한 기능이지만, 세상 모든 일반 함수를 람다로 교체해야 한다는 뜻은 아닙니다. 코드가 길고 복잡하거나 여러 곳에서 반복해서 재사용해야 하는 기능이라면 기존처럼 일반 함수를 만드는 것이 훨씬 좋습니다.
20.7 — 람다 캡처
캡처 절과 값으로 캡처하기
이전 레슨(20.6 -- 람다(익명 함수) 소개)에서 아래와 같은 예제를 다루었습니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
int main()
{
std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
auto found{ std::find_if(arr.begin(), arr.end(),
[](std::string_view str)
{
return str.find("nut") != std::string_view::npos;
}) };
if (found == arr.end())
{
std::cout << "No nuts\n"; // 견과류 없음
}
else
{
std::cout << "Found " << *found << '\n'; // 찾음
}
return 0;
}
이제 이 "nut(견과류)" 찾기 예제를 조금 바꿔서, 사용자가 직접 검색할 단어를 입력하도록 만들어 보겠습니다. 생각보다 직관적으로 바로 동작하지는 않을 겁니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
#include <string>
int main()
{
std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
// 사용자에게 무엇을 검색할지 물어봅니다.
std::cout << "search for: ";
std::string search{};
std::cin >> search;
auto found{ std::find_if(arr.begin(), arr.end(), [](std::string_view str) {
// "nut" 대신 @search 변수를 검색합니다.
return str.find(search) != std::string_view::npos; // 에러: 이 범위에서는 search에 접근할 수 없습니다.
}) };
if (found == arr.end())
{
std::cout << "Not found\n"; // 찾지 못함
}
else
{
std::cout << "Found " << *found << '\n'; // 찾음
}
return 0;
}
이 코드는 컴파일(실행)되지 않습니다. 일반적인 중첩 블록 { } 안에서는 바깥에 있는 변수를 자유롭게 쓸 수 있지만, 람다는 다릅니다. 람다는 기본적으로 바깥에 있는 변수를 볼 수 없습니다. 예외적으로 아래와 같은 특별한 변수들만 볼 수 있죠.
- 프로그램이 끝날 때까지 살아있는 변수 (전역 변수나
static변수 등) - 컴파일할 때 값이 정해지는 상수 (
constexpr객체)
우리가 만든 search 변수는 위 조건에 해당하지 않기 때문에, 람다 안에서는 search가 무엇인지 전혀 알지 못합니다. 투명인간 취급을 하는 거죠.
팁
람다는 람다 외부에 정의된 특정 종류의 객체(예: 전역 변수, 정적 지역 변수 같은 정적 저장소 기간을 가진 객체나 constexpr 객체)에만 접근할 수 있습니다.
람다 안에서 search 변수를 사용하려면 캡처 절(capture clause) 이라는 것을 사용해야 합니다.
캡처 절
'캡처 절'은 람다가 원래는 볼 수 없는 바깥쪽 변수를 사용할 수 있게 (간접적으로) 허락해 주는 문법입니다. 방법은 아주 간단합니다. 람다의 대괄호 [] 안에 람다 안에서 쓰고 싶은 변수 이름을 적어주기만 하면 됩니다.
여기서는 search 변수의 값을 람다 안에서 쓰고 싶으니, 캡처 절에 search를 추가해 보겠습니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
#include <string>
int main()
{
std::array<std::string_view, 4> arr{ "apple", "banana", "walnut", "lemon" };
std::cout << "search for: ";
std::string search{};
std::cin >> search;
// @search 변수를 캡처합니다 vvvvvv
auto found{ std::find_if(arr.begin(), arr.end(), [search](std::string_view str) {
return str.find(search) != std::string_view::npos;
}) };
if (found == arr.end())
{
std::cout << "Not found\n"; // 찾지 못함
}
else
{
std::cout << "Found " << *found << '\n'; // 찾음
}
return 0;
}
이제 사용자가 입력한 단어로 배열 안의 요소를 성공적으로 검색할 수 있습니다!
출력 결과
search for: nana
Found banana
캡처는 실제로 어떻게 작동할까요?
위의 코드를 보면 람다가 main 함수 안에 있는 search 변수를 직접 가져다 쓰는 것처럼 보이지만, 사실은 그렇지 않습니다. 람다는 겉보기엔 그냥 괄호 블록처럼 생겼지만, 내부적으로는 조금 다르게 작동합니다(이 차이를 아는 것이 매우 중요합니다).
람다가 만들어질 때, 캡처 절에 적어둔 변수들은 람다 내부로 똑같은 이름으로 복제 됩니다. 마법처럼 원본 변수의 값을 그대로 복사해서 람다 전용 변수를 새로 하나 만드는 것입니다.
즉, 위 예제에서 람다 객체가 생성될 때, 람다는 자신만의 search라는 변수를 따로 갖게 됩니다. 이 복제된 search는 원본 search와 값만 똑같을 뿐, 완전히 다른 독립적인 변수입니다. 마치 원본을 만지는 것 같지만 실제로는 복사본을 만지고 있는 것이죠.
이렇게 이름은 같아도, 복제된 변수의 타입이 원본과 항상 똑같은 것은 아닙니다.
이에 대해서는 이어지는 내용에서 더 살펴보겠습니다.
핵심 통찰
람다가 캡처한 변수는 바깥쪽 변수의 진짜 '원본'이 아니라, 값만 똑같이 베껴온 '복사본' 입니다.
고급 학습자를 위한 내용
람다는 겉보기엔 함수 같지만, 실제로는 함수처럼 호출할 수 있는 객체(object) 입니다. (이를 함수 객체, 즉 '펑터(functor)'라고 부르며, 나중에 직접 만드는 법을 배울 것입니다.)
컴파일러가 람다를 발견하면, 람다를 위한 맞춤형 객체를 하나 몰래 만들어냅니다. 이때 캡처된 변수들은 이 객체의 '멤버 변수(데이터 멤버)'가 됩니다.
프로그램이 실행되다가 람다를 정의한 코드를 만나면 이 람다 객체가 생성(인스턴스화)되고, 그때 캡처된 변수들도 초기화됩니다.
캡처는 기본적으로 const(상수)로 취급됩니다
람다를 실행할 때 내부적으로 operator()라는 것이 호출됩니다. 그런데 기본적으로 람다는 자신이 캡처해 온 복사본들을 수정하지 못하도록 꽉 잠가버립니다(const 취급). 아래 예제에서 ammo(총알) 변수를 캡처한 뒤, 람다 안에서 총알 개수를 줄여보려고 시도해 보겠습니다.
#include <iostream>
int main()
{
int ammo{ 10 }; // 총알 10발
// 람다를 정의하고 "shoot(쏘다)"이라는 변수에 저장합니다.
auto shoot{
[ammo]() {
// 에러 발생! ammo는 수정할 수 없습니다.
--ammo;
std::cout << "Pew! " << ammo << " shot(s) left.\n"; // 빵! 총알 ~발 남음.
}
};
// 람다를 호출합니다.
shoot();
std::cout << ammo << " shot(s) left\n"; // 총알 ~발 남음.
return 0;
}
이 코드는 컴파일되지 않습니다. 람다 안에서 ammo는 값을 바꿀 수 없는 const로 취급되기 때문입니다.
변경 가능한 캡처
만약 람다가 캡처한 복사본의 값을 꼭 수정해야 한다면, 람다에 mutable(변경 가능한)이라는 마법의 키워드를 붙여주면 됩니다.
#include <iostream>
int main()
{
int ammo{ 10 }; // 총알 10발
auto shoot{
[ammo]() mutable { // 이제 변경이 가능합니다 (mutable 추가)
// 이제 ammo를 수정할 수 있습니다.
--ammo;
std::cout << "Pew! " << ammo << " shot(s) left.\n";
}
};
shoot(); // 빵!
shoot(); // 빵!
std::cout << ammo << " shot(s) left\n"; // 원본 총알 확인
return 0;
}
출력 결과:
Pew! 9 shot(s) left.
Pew! 8 shot(s) left.
10 shot(s) left
이제 에러 없이 실행은 되지만, 논리적으로 이상한 점이 있습니다. 람다 안에서는 총알이 9발, 8발로 줄어들었는데, 마지막에 원본 총알을 확인해 보니 그대로 10발입니다!
왜 그럴까요? 앞서 설명했듯이 람다는 ammo의 복사본을 가져갔기 때문입니다. 람다는 원본이 아니라 자기 주머니에 있는 '복사본 총알'만 소비한 것입니다.
그리고 한 가지 더 신기한 점은, 람다를 여러 번 호출해도 람다 안의 ammo 복사본 값이 계속 유지된다는 점입니다 (9 -> 8로 줄어듦).
주의 사항
캡처된 변수들은 람다 객체 내부의 멤버 변수로 저장되기 때문에, 람다를 여러 번 호출해도 그 값이 사라지지 않고 계속 유지됩니다!
참조로 캡처하기
일반 함수에서 원본 데이터를 바꾸기 위해 '참조(reference)'를 사용하는 것처럼, 람다에서도 변수를 참조로 캡처하면 원본 변수를 직접 수정할 수 있습니다.
변수를 참조로 캡처하려면 캡처 절의 변수 이름 앞에 & 기호를 붙이면 됩니다. 복사본(값)으로 캡처할 때와 달리, 참조로 캡처한 변수는 원본 자체가 const가 아닌 이상 람다 안에서 자유롭게 수정할 수 있습니다.
무거운 데이터(문자열, 복잡한 객체 등)를 함수에 넘길 때 복사를 피하기 위해 참조를 쓰는 것처럼, 람다에서도 특별한 이유가 없다면 값으로 캡처하는 것보다 참조로 캡처하는 것을 권장합니다.
아래는 ammo를 참조로 캡처하도록 수정한 코드입니다.
#include <iostream>
int main()
{
int ammo{ 10 };
auto shoot{
// 원본을 직접 만지므로 이제 mutable 키워드가 필요 없습니다.
[&ammo]() { // &ammo는 ammo를 참조로 캡처한다는 뜻입니다.
// 람다 안의 ammo를 바꾸면 main 함수의 원본 ammo도 바뀝니다.
--ammo;
std::cout << "Pew! " << ammo << " shot(s) left.\n";
}
};
shoot();
std::cout << ammo << " shot(s) left\n"; // 원본 총알 확인
return 0;
}
이제 우리가 기대했던 대로 작동합니다!
Pew! 9 shot(s) left.
9 shot(s) left
이번에는 배열을 정렬할 때 std::sort가 비교를 몇 번이나 수행하는지 세어보는 예제에 참조 캡처를 활용해 보겠습니다.
#include <algorithm>
#include <array>
#include <iostream>
#include <string_view>
struct Car
{
std::string_view make{}; // 제조사
std::string_view model{}; // 모델명
};
int main()
{
std::array<Car, 3> cars{ { { "Volkswagen", "Golf" },
{ "Toyota", "Corolla" },
{ "Honda", "Civic" } } };
int comparisons{ 0 }; // 비교 횟수
std::sort(cars.begin(), cars.end(),
// @comparisons 변수를 참조로 캡처합니다.
[&comparisons](const auto& a, const auto& b) {
// 참조로 캡처했기 때문에 "mutable" 없이도 값을 수정할 수 있습니다.
++comparisons;
// 자동차 제조사(make)를 기준으로 정렬합니다.
return a.make < b.make;
});
std::cout << "Comparisons: " << comparisons << '\n';
for (const auto& car : cars)
{
std::cout << car.make << ' ' << car.model << '\n';
}
return 0;
}
예상 출력 결과
Comparisons: 2
Honda Civic
Toyota Corolla
Volkswagen Golf
여러 변수 캡처하기
쉼표(,)를 사용하면 여러 개의 변수를 한 번에 캡처할 수 있습니다. 값으로 캡처하는 변수와 참조로 캡처하는 변수를 섞어서 쓰는 것도 얼마든지 가능합니다!
int health{ 33 };
int armor{ 100 };
std::vector<CEnemy> enemies{};
// health와 armor는 값으로(복사해서) 캡처하고, enemies는 참조로(원본을) 캡처합니다.
[health, armor, &enemies](){};
기본 캡처
람다 안에서 쓰는 변수가 많아지면, 캡처 절 [] 안에 일일이 변수 이름을 적어주는 것이 귀찮고 실수하기도 쉽습니다. 다행히 컴파일러에게 "내가 람다 안에서 쓰는 변수들은 알아서 다 캡처해 줘!"라고 부탁할 수 있는 기능이 있습니다.
이를 기본 캡처라고 부르며, 람다 안에서 언급된 변수들만 자동으로 캡처해 줍니다. (언급되지 않은 변수는 캡처하지 않습니다.)
- 사용된 모든 변수를 값(복사본) 으로 자동 캡처하려면
=를 씁니다. ([=]) - 사용된 모든 변수를 참조(원본) 로 자동 캡처하려면
&를 씁니다. ([&])
다음은 =를 사용해 기본 캡처를 하는 예제입니다.
#include <algorithm>
#include <array>
#include <iostream>
int main()
{
std::array areas{ 100, 25, 121, 40, 56 };
int width{};
int height{};
std::cout << "Enter width and height: ";
std::cin >> width >> height;
auto found{ std::find_if(areas.begin(), areas.end(),
[=](int knownArea) { // 람다 안에서 쓰인 width와 height를 자동으로 값으로 캡처합니다.
return width * height == knownArea; // 여기서 두 변수가 사용되었기 때문입니다.
}) };
if (found == areas.end())
{
std::cout << "I don't know this area :(\n"; // 이 면적은 없네요 :(
}
else
{
std::cout << "Area found :)\n"; // 면적을 찾았습니다 :)
}
return 0;
}
기본 캡처 기능은 일반 캡처와 섞어서 쓸 수도 있습니다.
다만, 똑같은 변수를 두 번 캡처하려고 하면 에러가 납니다.
int health{ 33 };
int armor{ 100 };
std::vector<CEnemy> enemies{};
// health와 armor는 값으로, enemies는 참조로 캡처합니다.
[health, armor, &enemies](){};
// 기본적으로 모두 값(=)으로 캡처하되, enemies만 예외적으로 참조(&)로 캡처합니다.
[=, &enemies](){};
// 기본적으로 모두 참조(&)로 캡처하되, armor만 예외적으로 값으로 캡처합니다.
[&, armor](){};
// 에러: 이미 모든 것을 참조(&)로 캡처한다고 했는데, 또 참조(&armor)로 하겠다고 중복 선언했습니다.
[&, &armor](){};
// 에러: 이미 모든 것을 값(=)으로 캡처한다고 했는데, 또 값(armor)으로 하겠다고 중복 선언했습니다.
[=, armor](){};
// 에러: armor를 두 번 적었습니다.
[armor, &health, &armor](){};
// 에러: 기본 캡처 기호(& 나 =)는 무조건 맨 앞에 와야 합니다.
[armor, &](){};
람다 캡처 안에서 새로운 변수 정의하기
때로는 기존 변수를 살짝 가공해서 캡처하거나, 아예 람다 안에서만 쓸 새로운 변수를 만들고 싶을 때가 있습니다. 이럴 때는 캡처 절 안에서 데이터 타입 없이 변수를 직접 정의할 수 있습니다.
#include <array>
#include <iostream>
#include <algorithm>
int main()
{
std::array areas{ 100, 25, 121, 40, 56 };
int width{};
int height{};
std::cout << "Enter width and height: ";
std::cin >> width >> height;
// 배열에는 면적(area)이 저장되어 있지만, 사용자는 너비(width)와 높이(height)를 입력했습니다.
// 따라서 검색을 하려면 먼저 너비와 높이를 곱해 면적을 계산해 두어야 합니다.
auto found{ std::find_if(areas.begin(), areas.end(),
// 람다 안에서만 볼 수 있는 새로운 변수를 선언합니다.
// userArea의 타입은 자동으로 int로 결정(추론)됩니다.
[userArea{ width * height }](int knownArea) {
return userArea == knownArea;
}) };
if (found == areas.end())
{
std::cout << "I don't know this area :(\n";
}
else
{
std::cout << "Area found :)\n";
}
return 0;
}
여기서 userArea라는 변수는 람다가 만들어질 때 단 한 번만 계산됩니다. 계산된 결과는 람다 객체 안에 잘 보관되어, 람다를 여러 번 호출해도 다시 계산할 필요 없이 똑같이 사용됩니다. 만약 람다가 mutable이고 캡처 절에서 만든 이 변수를 수정한다면, 수정된 값이 계속 덮어씌워져 유지됩니다.
권장 사항
캡처 절 안에서 변수를 초기화하는 것은 값이 짧고(단순하고) 타입이 명확할 때만 사용하세요. 코드가 길어지고 복잡해진다면, 람다 바깥에서 먼저 변수를 계산해 둔 다음 그걸 캡처하는 것이 더 좋습니다.
Dangling 캡처 변수
변수들은 람다가 만들어지는 바로 그 시점에 캡처됩니다. 만약 참조로 캡처한 변수가 람다보다 먼저 수명을 다해 파괴되어 버리면 어떻게 될까요? 람다는 허공을 가리키는,
이른바 '매달린 참조(Dangling reference)' 를 쥐고 있게 됩니다.
예를 살펴볼까요?
#include <iostream>
#include <string>
// 람다를 반환하는 함수
auto makeWalrus(const std::string& name)
{
// name을 참조로 캡처한 람다를 만들어서 반환합니다.
return [&]() {
std::cout << "I am a walrus, my name is " << name << '\n'; // 정의되지 않은 동작(위험!)
};
}
int main()
{
// 이름이 Roofus인 새로운 바다코끼리를 만듭니다.
// sayName은 makeWalrus 함수가 만들어준 람다를 담고 있습니다.
auto sayName{ makeWalrus("Roofus") };
// makeWalrus가 반환한 람다 함수를 호출해 봅니다.
sayName();
return 0;
}
이 코드에서 makeWalrus("Roofus")를 호출하면, 문자열 "Roofus"를 담은 임시 변수가 만들어집니다. 람다는 이 임시 변수를 '참조(원본 그대로)'로 캡처했습니다.
그런데 문제는 makeWalrus 함수의 실행이 끝나면 이 임시 변수는 메모리에서 완전히 파괴되어 사라진다는 겁니다! 하지만 우리의 sayName 람다는 여전히 그 파괴된 변수가 있던 자리를 기억하고 있습니다.
나중에 sayName()을 실행해서 그 자리에 접근하려고 하면, 이미 데이터가 날아간 쓰레기 메모리를 건드리게 되어 프로그램이 뻗거나 이상한 행동(정의되지 않은 동작)을 하게 됩니다.
만약 makeWalrus 함수가 name을 참조가 아니라 값(복사본)으로 받았더라도 똑같은 문제가 생깁니다. 함수가 끝나면 매개변수 name은 사라지기 때문입니다.
주의 사항
변수를 참조로 캡처할 때는 정말 조심해야 합니다! 특히[&]처럼 기본 참조 캡처를 무심코 쓸 때 위험합니다. 캡처 당하는 변수는 반드시 람다보다 오래 살아남아야 합니다.
만약 람다를 나중에 실행할 때도 name 변수를 안전하게 쓰고 싶다면, 참조가 아니라 값(복사본) 으로 캡처해야 합니다 (직접 [name]이라고 적거나 [=]를 사용). 그러면 람다가 자신만의 튼튼한 복사본을 가지게 되어 원본이 파괴되든 말든 신경 쓰지 않아도 됩니다.
변경 가능한 람다의 의도치 않은 복사
앞서 람다는 내부적으로 '객체(object)'라고 말씀드렸습니다. 객체라는 말은 곧 다른 곳으로 복사될 수 있다는 뜻입니다. 그리고 이 점이 가끔 골치 아픈 문제를 만듭니다.
#include <iostream>
int main()
{
int i{ 0 };
// count라는 이름의 람다를 만듭니다 (변경 가능)
auto count{ [i]() mutable {
std::cout << ++i << '\n';
} };
count(); // count 실행 (1 출력)
auto otherCount{ count }; // count를 그대로 복사해서 otherCount를 만듭니다
// 원본과 복사본을 각각 실행해 봅니다.
count();
otherCount();
return 0;
}
출력 결과
1
2
2
1, 2, 3이 출력될 줄 알았는데 2가 두 번 출력되었습니다!
이유는 간단합니다. otherCount를 만들 때, 그 시점에서의 count 상태를 통째로 복사(도장 찍기)했기 때문입니다. 처음 count()를 한 번 실행해서 람다 안의 i가 1이 되었죠? 그래서 복사본인 otherCount도 똑같이 i=1인 상태를 물려받고 시작한 겁니다. 둘은 복사된 이후 각자의 길을 걷기 때문에 독립적인 i를 가지고 따로따로 1씩 증가시킨 것입니다.
이제 조금 더 알아차리기 힘든 예제를 볼까요?
#include <iostream>
#include <functional>
void myInvoke(const std::function<void()>& fn)
{
fn();
}
int main()
{
int i{ 0 };
// 자신이 가진 복사본 @i를 증가시키고 출력하는 람다
auto count{ [i]() mutable {
std::cout << ++i << '\n';
} };
myInvoke(count);
myInvoke(count);
myInvoke(count);
return 0;
}
출력 결과:
1
1
1
방금 전 예제와 똑같은 문제가 아주 은밀하게 숨어 있습니다.
myInvoke(count)를 호출할 때, 컴파일러는 우리가 만든 '람다 타입'과 함수가 요구하는 std::function 타입이 다르다는 걸 눈치챕니다. 그래서 컴파일러가 알아서 람다를 std::function이라는 임시 박스에 포장(변환)해서 넘겨줍니다. 이 포장 과정에서 람다의 복사본이 만들어져 버립니다!
결국 1, 2, 3 누적 카운트는 count 원본에서 이루어지는 게 아니라, 호출할 때마다 새로 만들어지는 일회용 복사본에서만 이루어지기 때문에 계속 1만 출력되는 것입니다.
이런 끔찍한 복사 문제를 막고 싶다면 두 가지 방법이 있습니다.
첫째, 람다 안에서 복사본을 수정하는(mutable) 방식을 버리고, 차라리 클래스를 직접 만들거나 다른 구조를 사용하는 것입니다. (하지만 코드가 복잡해질 수 있습니다.)
둘째, 아예 처음부터 람다를 std::function 박스 안에 명시적으로 담아두는 것입니다. 그러면 함수로 넘길 때 추가적인 복사 포장 작업이 일어나지 않습니다.
#include <iostream>
#include <functional>
void myInvoke(const std::function<void()>& fn)
{
fn();
}
int main()
{
int i{ 0 };
// 람다 객체를 생성하자마자 바로 std::function에 담아둡니다.
std::function count{ [i]() mutable {
std::cout << ++i << '\n';
} };
myInvoke(count); // 이제 포장된 채로 넘어가므로 복사본이 생기지 않습니다!
myInvoke(count); // 복사 생기지 않음
myInvoke(count); // 복사 생기지 않음
return 0;
}
이제 원하던 출력 결과가 나옵니다:
1
2
3
또 다른 멋진 해결책으로는 참조 래퍼(reference wrapper) 를 사용하는 방법이 있습니다. C++의 <functional> 헤더에는 일반 객체를 마치 참조(reference)인 것처럼 속여서 전달하게 해주는 std::reference_wrapper라는 유용한 도구가 있습니다.
std::ref() 함수를 쓰면 람다를 아주 쉽게 참조 형태로 감쌀 수 있죠. 이렇게 람다를 한 겹 감싸주면, 누군가 람다를 복사하려고 할 때 람다 원본이 복사되는 게 아니라 껍데기(참조)만 복사되므로, 안전하게 원본 하나만 유지할 수 있습니다.
std::ref를 활용해 수정한 코드를 보겠습니다.
#include <iostream>
#include <functional> // std::reference_wrapper와 std::ref를 사용하기 위한 헤더
void myInvoke(const std::function<void()>& fn)
{
fn();
}
int main()
{
int i{ 0 };
// 자신이 가진 복사본 @i를 증가시키고 출력하는 람다
auto count{ [i]() mutable {
std::cout << ++i << '\n';
} };
// std::ref(count)는 count가 참조처럼 취급되도록 보장해 줍니다.
// 누군가 count를 복사하려고 하면 실제로는 '참조'만 복사되기 때문에,
// 결과적으로 실제 count 객체는 세상에 단 하나만 존재하게 됩니다.
myInvoke(std::ref(count));
myInvoke(std::ref(count));
myInvoke(std::ref(count));
return 0;
}
이제 원하던 출력 결과가 나옵니다:
1
2
3
이 방식이 정말 강력한 이유는, myInvoke 함수가 매개변수를 참조(&)가 아니라 값으로(복사해서) 받도록 설계되어 있어도 정상적으로 1, 2, 3을 카운트한다는 점입니다!
규칙
C++ 표준 라이브러리 함수들은 종종 함수 객체(람다 포함)를 내부적으로 복사합니다. 만약 여러분이 캡처된 변수를 수정하는mutable람다를 라이브러리 함수에 넘겨줘야 한다면, 복사 방지를 위해std::ref를 사용해서 넘겨주는 것이 좋습니다.
권장 사항
가장 좋은 방법은 애초에mutable람다를 최대한 쓰지 않는 것입니다. 데이터를 내부에서 수정하지 않는 람다가 읽기도 훨씬 쉽고, 위와 같은 골치 아픈 복사 버그나 나중에 병렬 처리(멀티 스레드)를 할 때 생기는 무서운 에러들을 피할 수 있습니다.
20.x — 20장 요약 및 퀴즈
챕터 복습
또 하나의 챕터를 무사히 마쳤네요!
함수에 데이터(인수)를 넘겨줄 때는 값(value), 참조(reference), 주소(address) 이렇게 세 가지 방법을 쓸 수 있습니다. 상황에 맞게 골라 쓰는 것이 아주 중요해요!
- 값으로 전달 (Pass by value): 기본 데이터 타입(
int,double등)이나 열거형을 넘길 때 씁니다. 원본은 놔두고 '복사본'만 함수에 던져주는 안전하고 단순한 방법입니다. - 참조로 전달 (Pass by reference): 구조체나 클래스처럼 덩치가 큰 데이터이거나, 함수 안에서 원본 데이터를 직접 수정해야 할 때 씁니다. 원본을 직접 연결해 주므로 복사하는 수고를 덜어줍니다.
- 주소로 전달 (Pass by address): 포인터나 C 스타일의 기본 배열을 넘길 때 씁니다.
- 팁: 참조나 주소로 데이터를 넘길 때, 함수 안에서 원본이 멋대로 바뀌면 안 된다면 가급적
const를 붙여서 안전하게 보호해 주세요.
함수가 결과값을 돌려줄 때(반환)도 마찬가지로 값, 참조, 주소 세 가지 방식을 쓸 수 있습니다.
- 대부분의 경우에는 그냥 '값으로 반환'하는 것으로 충분합니다.
- 하지만 동적으로 할당된 데이터(필요할 때 메모리를 빌려 쓴 데이터), 구조체, 클래스처럼 무거운 데이터를 다룰 때는 '참조나 주소로 반환'하는 것이 아주 효율적이고 유용합니다.
- 주의할 점: 참조나 주소로 결과값을 돌려줄 때는, 함수가 끝나면 메모리에서 사라져 버릴 데이터(지역 변수 등)를 가리키고 있지는 않은지 반드시 확인해야 합니다. 사라진 데이터를 가리키면 프로그램이 뻗을 수 있거든요!
함수 포인터를 사용하면 함수 자체를 다른 함수에 데이터처럼 넘겨줄 수 있습니다. 이 기능은 리스트를 정렬하는 방식처럼, 함수를 호출하는 쪽에서 함수의 세부적인 동작을 입맛대로 바꾸고 싶을 때(커스터마이징) 아주 유용합니다.
프로그램이 실행되는 도중에 필요한 만큼 메모리를 빌려 쓰는 동적 메모리는 '힙(Heap)'이라는 특별한 메모리 공간에 만들어집니다.
콜 스택(Call stack)은 프로그램이 시작된 후부터 지금까지 실행 중인 모든 함수들(호출되었지만 아직 끝나지 않은 함수들)의 목록을 차곡차곡 기록해 두는 곳입니다.
우리가 함수 안에서 만드는 일반적인 변수(지역 변수)들은 이 '스택(Stack)'이라는 공간에 만들어져요. 단, 스택은 크기가 제한되어 있어서 너무 많이 쓰면 넘쳐버릴 수 있습니다. (스택처럼 동작하는 구조를 직접 만들고 싶다면 std::vector를 활용하면 좋습니다!)
재귀 함수(Recursive function)는 자기 자신을 다시 부르는 신기한 함수입니다. 끝없이 자기 자신을 부르다 프로그램이 멈추지 않도록, 모든 재귀 함수에는 반드시 "여기까지만 하고 끝내!"라는 종료 조건(termination condition)이 있어야 합니다.
명령줄 인수(Command line arguments)를 사용하면, 프로그램을 처음 켤 때 사용자나 다른 프로그램이 우리 프로그램에 초기 데이터를 쏙 넣어줄 수 있습니다. 단, 이렇게 들어오는 데이터는 무조건 텍스트(C 스타일 문자열) 형태이기 때문에, 만약 숫자로 쓰고 싶다면 우리가 직접 숫자로 바꿔주어야(변환해야) 합니다.
생략 부호(Ellipsis, ...)를 사용하면 함수에 넘겨주는 데이터(인수)의 개수를 그때그때 다르게(가변적으로) 할 수 있습니다. 하지만 이 방법을 쓰면 컴파일러가 "이 데이터 타입이 맞나?" 하고 검사하는 기능을 꺼버리고, 데이터가 몇 개나 들어왔는지도 알 수 없게 됩니다. 그래서 이 세부 사항들을 관리하는 건 전적으로 프로그래머의 몫이 되니 주의해서 써야 합니다.
람다 함수(Lambda functions)는 다른 함수 안에 쏙 집어넣을 수 있는 함수입니다. 이름이 없어도(익명) 쓸 수 있고, C++의 알고리즘 라이브러리(데이터를 쉽게 다루는 도구들)와 함께 쓸 때 정말 무궁무진하게 활용할 수 있답니다!
