
[문제 바로가기] https://programmers.co.kr/learn/courses/30/lessons/17677
📌문제 설명
(앞 내용 생략...)
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는 자카드 유사도라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 1을 3개 가지고 있고, 다중집합 B는 원소 1을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 1을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 1을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
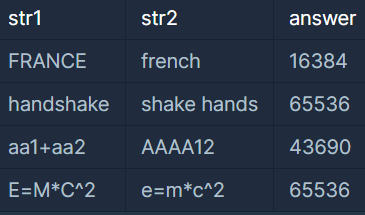
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 FRANCE와 FRENCH가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
입력 형식 )
입력으로는 str1과 str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어 ab+가 입력으로 들어오면, ab만 다중집합의 원소로 삼고, b+는 버린다.
다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다. AB와 Ab, ab는 같은 원소로 취급한다.출력 형식 )
입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.예제 입 출력 )
💡 문제 풀이
자카드 유사도에 대해서 처음 들어보았지만 교집합, 합집합만 알면 풀 수 있는 문제다. (문제 길이에 현혹되지 말자...😂)
교집합, 합집합과 해당 원소가 몇 번 나오는지 파악하기 위해 딕셔너리 자료구조를 사용하였다.
step1)
str1, str2 각 문자열에 대해서 반복문을 사용하여 두 글자씩 끊는다. 소문자로 변환한뒤 알파벳여부를 확인한다.
※ 조건 - 대소문자 차이는 무시한다. / 영문자로 된 글자 쌍만 유효하다.
if 딕셔너리에 존재하지 않으면
→ 키(영문자로 된 글자 쌍) : 값(1) 추가
else 딕셔너리에 존재하면
→ 해당 키의 값 + 1
step2)
step1에서 생성한 두 개의 딕셔너리를 각각 반복한다.
if 공통으로 존재하는 '키(=영문자로 된 글자 쌍)'가 존재하면
→ 교집합(son)은 최소값을, 합집합(mother)은 최대값을 더한다.
else 공통으로 존재하는 '키'가 존재하지 않으면
→ 합집합(mother)에만 해당 키의 값을 더한다.
def solution(str1, str2):
son = mother = 0
str1_dict = dict()
str2_dict = dict()
for i in range(len(str1)-1):
string1 = str1[i:i+2].lower()
if string1.isalpha():
if string1 not in str1_dict.keys():
str1_dict[string1] = 1
else:
str1_dict[string1] += 1
for i in range(len(str2)-1):
string2 = str2[i:i+2].lower()
if string2.isalpha():
if string2 not in str2_dict.keys():
str2_dict[string2] = 1
else:
str2_dict[string2] += 1
used = []
for idx, value in str1_dict.items():
if idx not in used:
if idx in str2_dict.keys():
son += min(str1_dict[idx], str2_dict[idx])
mother += max(str1_dict[idx], str2_dict[idx])
else:
mother += str1_dict[idx]
used.append(idx)
for idx, value in str2_dict.items():
if idx not in used:
mother += str2_dict[idx]
return 65536 if mother == 0 else int(son/mother * 65536)풀고난 후 교집합, 합집합과 같은 집합 문제를 풀 때 활용하기 좋은 자료구조 set이 생각나서 다시풀어보았다.
step1)
먼저 str1, str2 문자열을 반복하면서 나올 수 있는 모든 글자 쌍을 리스트에 담는다.
step2)
set을 이용하여 교집합(intersection), 합집합(union)을 만든다.
※ 교집합의 경우 '&', 합집합의 경우 '|' 기호를 사용한다.
step3)
step2에서 만든 교집합, 합집합을 토대로 교집합은 최소값을 합집합은 최대값을 더하여 계산한다.
def solution(str1, str2):
str1_list = []
str2_list = []
for i in range(len(str1)-1):
string1 = str1[i:i+2].lower()
if string1.isalpha():
str1_list.append(string1)
for i in range(len(str2)-1):
string2 = str2[i:i+2].lower()
if string2.isalpha():
str2_list.append(string2)
intersection = set(str1_list) & set(str2_list)
union = set(str1_list) | set(str2_list)
son = [min(str1_list.count(i), str2_list.count(i)) for i in intersection]
mother = [max(str1_list.count(i), str2_list.count(i)) for i in union]
return int(sum(son)/sum(mother) * 65536) if len(mother) else 65536