
[문제 바로가기] https://programmers.co.kr/learn/courses/30/lessons/17686
📌문제 설명
세 차례의 코딩 테스트와 두 차례의 면접이라는 기나긴 블라인드 공채를 무사히 통과해 카카오에 입사한 무지는 파일 저장소 서버 관리를 맡게 되었다.
저장소 서버에는 프로그램의 과거 버전을 모두 담고 있어, 이름 순으로 정렬된 파일 목록은 보기가 불편했다. 파일을 이름 순으로 정렬하면 나중에 만들어진 ver-10.zip이 ver-9.zip보다 먼저 표시되기 때문이다.
버전 번호 외에도 숫자가 포함된 파일 목록은 여러 면에서 관리하기 불편했다. 예컨대 파일 목록이 [img12.png, img10.png, img2.png, img1.png]일 경우, 일반적인 정렬은 [img1.png, img10.png, img12.png, img2.png] 순이 되지만, 숫자 순으로 정렬된 [img1.png, img2.png, img10.png, img12.png"] 순이 훨씬 자연스럽다.
무지는 단순한 문자 코드 순이 아닌, 파일명에 포함된 숫자를 반영한 정렬 기능을 저장소 관리 프로그램에 구현하기로 했다.
소스 파일 저장소에 저장된 파일명은 100 글자 이내로, 영문 대소문자, 숫자, 공백(" ), 마침표(.), 빼기 부호(-")만으로 이루어져 있다. 파일명은 영문자로 시작하며, 숫자를 하나 이상 포함하고 있다.
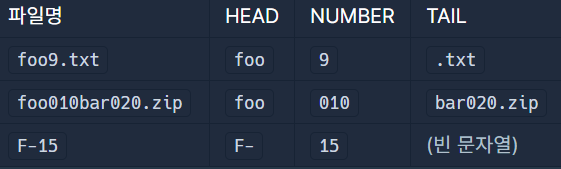
파일명은 크게 HEAD, NUMBER, TAIL의 세 부분으로 구성된다.
HEAD는 숫자가 아닌 문자로 이루어져 있으며, 최소한 한 글자 이상이다.
NUMBER는 한 글자에서 최대 다섯 글자 사이의 연속된 숫자로 이루어져 있으며, 앞쪽에 0이 올 수 있다. 0부터 99999 사이의 숫자로, 00000이나 0101 등도 가능하다.
TAIL은 그 나머지 부분으로, 여기에는 숫자가 다시 나타날 수도 있으며, 아무 글자도 없을 수 있다.
파일명을 세 부분으로 나눈 후, 다음 기준에 따라 파일명을 정렬한다.파일명은 우선 HEAD 부분을 기준으로 사전 순으로 정렬한다. 이때, 문자열 비교 시 대소문자 구분을 하지 않는다. MUZI와 muzi, MuZi는 정렬 시에 같은 순서로 취급된다.
파일명의 HEAD 부분이 대소문자 차이 외에는 같을 경우, NUMBER의 숫자 순으로 정렬한다. 9 < 10 < 0011 < 012 < 13 < 014 순으로 정렬된다. 숫자 앞의 0은 무시되며, 012와 12는 정렬 시에 같은 같은 값으로 처리된다.
두 파일의 HEAD 부분과, NUMBER의 숫자도 같을 경우, 원래 입력에 주어진 순서를 유지한다. MUZI01.zip과 muzi1.png가 입력으로 들어오면, 정렬 후에도 입력 시 주어진 두 파일의 순서가 바뀌어서는 안 된다.
무지를 도와 파일명 정렬 프로그램을 구현하라.입력 형식
입력으로 배열 files가 주어진다.files는 1000 개 이하의 파일명을 포함하는 문자열 배열이다.
각 파일명은 100 글자 이하 길이로, 영문 대소문자, 숫자, 공백(" ), 마침표(.), 빼기 부호(-")만으로 이루어져 있다. 파일명은 영문자로 시작하며, 숫자를 하나 이상 포함하고 있다.
중복된 파일명은 없으나, 대소문자나 숫자 앞부분의 0 차이가 있는 경우는 함께 주어질 수 있다. (muzi1.txt, MUZI1.txt, muzi001.txt, muzi1.TXT는 함께 입력으로 주어질 수 있다.)출력 형식
위 기준에 따라 정렬된 배열을 출력한다.입출력 예제
입력: ["img12.png", "img10.png", "img02.png", "img1.png", "IMG01.GIF", "img2.JPG"]
출력: ["img1.png", "IMG01.GIF", "img02.png", "img2.JPG", "img10.png", "img12.png"]입력: ["F-5 Freedom Fighter", "B-50 Superfortress", "A-10 Thunderbolt II", "F-14 Tomcat"]
출력: ["A-10 Thunderbolt II", "B-50 Superfortress", "F-5 Freedom Fighter", "F-14 Tomcat"]
💡 문제 풀이
- 파일명을 head, number, tail로 분리시키기
- 문자, 숫자 순으로 정렬하기
두 가지를 순서대로 진행하면 되는 문제
나의 경우 정렬해야하는 부분이 HEAD와 NUMBER이기 때문에 TAIL은 신경쓰지 않았다.
따라서, 파일명에서 HEAD와 TAIL만 분리시키고 반복문을 끝냈다.
step 1)
files에 있는 file들의 HEAD와 NUMBER를 분리시킨다
HEAD는 숫자가 아닌 문자, NUMBER는 숫자(0 ~ 99999)이므로 isnumeric 함수를 이용하여 HEAD와 NUMBER를 구분하였다.
step 2)
HEAD와 NUMBER를 분리시킨 후 반복문을 마친다.(TAIL 사용X)
이 때 분리시킨 결과값과 file의 위치인 인덱스(i)를 빈 리스트에 담아 candidate에 순서대로 넣는다.
step 3)
lambda를 이용해서 HEAD, NUMBER 순으로 정렬시킨다.
HEAD : 대소문자 구분없이 사전순으로 정렬 - lower함수를 이용하여 소문자 기준으로 정렬
NUMBER : 숫자 크기 순 - int 자료형으로 바꾸어 정렬
step 4)
정렬을 마친 candidate 리스트의 3번째 값(인덱스)이 file의 순서이므로 순서대로 answer에 담는다.
def solution(files):
answer = []
candidate = []
for i in range(len(files)):
head = ''
number = ''
for word in files[i]:
if not word.isnumeric() and not number:
head += word
if word.isnumeric():
number += word
if not word.isnumeric() and number:
break
candidate.append([head, number, i])
arrange = sorted(candidate, key = lambda x : (x[0].lower(), int(x[1])))
for arr in arrange: answer.append(files[arr[2]])
return answer다른 사람의 풀이
import re
def solution(files):
a = sorted(files, key=lambda file : int(re.findall('\d+', file)[0]))
b = sorted(a, key=lambda file : re.split('\d+', file.lower())[0])
return bre모듈의 findall 함수를 사용한 코드
search가 최초로 매칭되는 패턴만 반환한다면, findall은 매칭되는 전체의 패턴을 반환한다.
또한 매칭되는 모든 결과를 리스트 형태로 반환해주기 때문에 추가적인 리스트를 만들 필요가 없다.(내 코드의 경우 candidate 리스트를 만들 필요가 없게된다.)
findall 예시 )
re.findall(r'[\w-]+@[\w.]+', 'algorithm@gmail.com trash algorithm2@gmail.com love house')결과 : ['algorithm@gmail.com', 'algorithm2@gmail.com' ]
