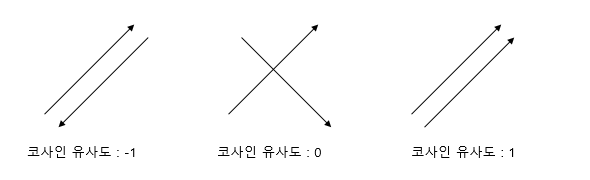
코사인 유사도(Cosine Similarity)
- 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
- 두 벡터의 방향이 완전히 동일한 경우 : 1
- 90°의 각 : 0
- 180°로 반대의 방향 : -1
- 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다.
유사도를 이용한 챗봇 시스템 구현
Library Import
import pandas as pd
from sentence_transformers import SentenceTransformer #사전학습 모델을 가져오는 것
from sklearn.metrics.pairwise import cosine_similaritysentence-BERT 모델 가져오기
model = SentenceTransformer('jhgan/ko-sroberta-multitask') # embedding을 하기위해 encoder를 가져온 것.- jhgan/ko-sroberta-multitask 모델
- 한국어 문장 임베딩에 활용하기 위해 만들어진 한국어 사전학습 모델
- KorNLU 데이터셋으로 한국어 사전학습 모델을 파인튜닝하고, 파인튜닝된 모델을 sentence-transformers에서 다운로드받아 활용할 수 있다.
모델 테스트
sentences=["안녕하세요?", "테스트를 위한 문장입니다."]
embeddings=model.encode(sentences)
print(embeddings)[[-0.37510455 -0.7733845 0.5927711 ... 0.57923514 0.32683447
-0.6508966 ]
[-0.17084298 -0.6179124 -0.53709316 ... 0.3774292 0.75107646
-0.19669947]]- 인코딩 한 것을 embeddings라는 변수에 저장하고 벡터값들을 print를 통해 확인할 수 있다.
data import
df=pd.read_csv('wellness_dataset_original.csv')
df.head()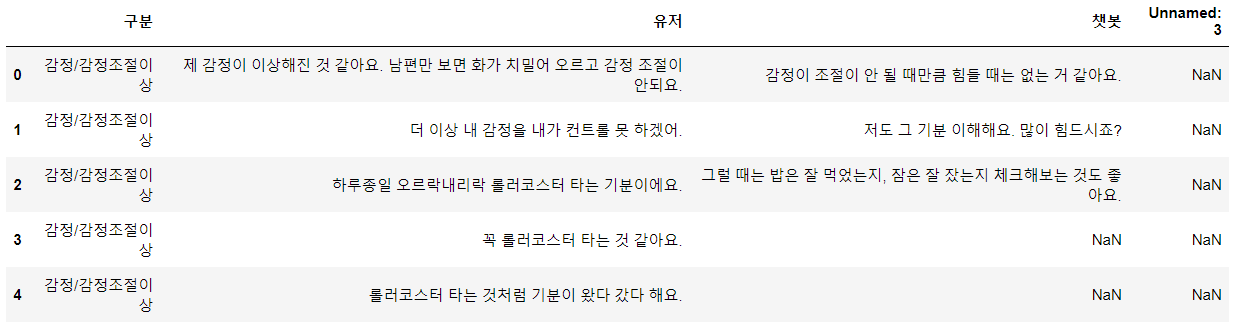
- mental healthcare data는 CSV형식의 데이터이며, 유저의 감정에 대한 문장 및 상태, 챗봇의 답변에 대하여 서술되어 있다.
- 전처리가 필요함을 확인 (ex. NaN, 'Unnamed: 3')
df=df[~df['챗봇'].isna()]
df=df.drop(columns=['Unnamed: 3'])
df.head()
- isna()를 이용해 결측값을 확인하고 NaN을 제거
- drop()을 이용해 변수 'Unnamed: 3'를 제거
sentence embedding
df['embedding']=pd.Series([[]]*len(df)) # 길이를 맞춰주기 위해서 곱함
df['embedding']=df['유저'].map(lambda x : list(model.encode(x)))
df.head()
- 'embedding'이라는 변수를 만들어 샘플 개수만큼 빈칸을 만든 후 임베딩한 값을 빈칸에 하나씩 대입해 넣었다.
입력한 텍스트
test_text='요즘 외롭지 않고 기분이 좋네요'
ebd=model.encode(test_text)임베딩 값 비교
df['distance']=df['embedding'].map(lambda x : cosine_similarity([ebd], [x]).squeeze())#차원을 없애주기 위해서 squeeze를 씀.
df.head()
- 입력한 텍스트의 임베딩 값과 유저의 텍스트 임베딩 값을 전부 비교하여 나온 코사인 유사도 값을 'distance'라는 변수에 저장하였다.
챗봇 답변 나타내기
answer1 = df.loc[df['distance'].idxmax()]
answer2 = df.loc[df['distance'].idxmin()]
print('환자 상태 :', answer1['구분'])
print('유사한 질문 :', answer1['유저'])
print('챗봇 답변 :', answer1['챗봇'])
print('유사도 :', answer1['distance'])
print('\n\n')
print('환자 상태 :', answer2['구분'])
print('유사한 질문 :', answer2['유저'])
print('챗봇 답변 :', answer2['챗봇'])
print('유사도 :', answer2['distance'])- df['distance']에 저장해둔 값이 1에 가까울 수록 코사인 유사도 값이 높다.
- idmax()를 이용해 코사인 유사도 값이 가장 높은 샘플을 찾아내고, idxmin()을 통해 가장 낮은 샘플을 찾아내어 챗봇 답변을 리턴한다.
💬 챗봇 답변
환자 상태 : 감정/즐거움
유사한 질문 : 확실히 외로움도 덜 느껴지고 좋더라고요.
챗봇 답변 : 당신이 행복하다면 저도 기뻐요.
유사도 : 0.7856825590133667
환자 상태 : 배경/사업/실패
유사한 질문 : 사업을 하다가 실패해서 집안이 완전히 주저앉았어요.
챗봇 답변 : 그런 일이 있으셨군요. 마음이 쓰라리시겠어요.
유사도 : -0.03497869521379471- '요즘 외롭지 않고 기분이 좋네요'라는 텍스트에 유사도 약 0.79로 '당신이 행복하다면 저도 기뻐요.'라는 챗봇 답변이 리턴되었다.
- '그런 일이 있으셨군요. 마음이 쓰라리시겠어요.'라는 챗봇 답변은 유사도 약 -0.03으로 입력한 텍스트와 맞지 않음을 확인할 수 있다.
함수를 이용하여 한번에 나타내기
def 대화(text):
ebd=model.encode(text)
df['distance']=df['embedding'].map(lambda x : cosine_similarity([ebd], [x]).squeeze())
answer1 = df.loc[df['distance'].idxmax()]
answer2 = df.loc[df['distance'].idxmin()]
print('입력한 텍스트 :',text)
print('환자 상태 :', answer1['구분'])
print('유사한 질문 :', answer1['유저'])
print('챗봇 답변 :', answer1['챗봇'])
print('유사도 :', answer1['distance'])
print('\n\n')
print('환자 상태 :', answer2['구분'])
print('유사한 질문 :', answer2['유저'])
print('챗봇 답변 :', answer2['챗봇'])
print('유사도 :', answer2['distance'])대화('이 세상에 혼자 있는 기분이에요')입력한 텍스트 : 이 세상에 혼자 있는 기분이에요
환자 상태 : 감정/고독감
유사한 질문 : 세상에 저 혼자 있는 거 같아요.
챗봇 답변 : 제가 당신의 편이 될게요.
유사도 : 0.90902179479599
환자 상태 : 증상/식욕저하/불면
유사한 질문 : 5일 동안 밥도 제대로 못 먹고, 잠도 거의 못 잤어.
챗봇 답변 : 식사와 수면 둘 다 중요한데 정말 걱정되네요. 지금은 괜찮으신가요?
유사도 : -0.028927002102136612- 함수 사용과 print('입력한 텍스트 :',text) 를 추가하여 입력한 텍스트와 답변을 한번에 볼 수 있게 수정하였다.
