 INDEED채용/구직 사이트 Scraping
INDEED채용/구직 사이트 Scraping
Example of Scrapping Process
- html이 포함된 객체를 불러오기
- Parsing html in indeed_result object
- Find "div" which have pagination className
- Extract title, company_name, location, link for company card included in each page
코드
indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT=50
URL = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?q=python&limit={LIMIT}"
def extract_indeed_pages():
# html이 포함된 객체를 불러오기
result = requests.get(URL)
# print(indeed_result)
# Parsing html in indeed_result object
soup = BeautifulSoup(result.text,"html.parser")
# print(indeed_soup)
# find "div" which have pagination className
paginations = soup.find("div",class_='pagination')
# print(indeed_soup("div",class_='pagination'))
# find all a tag
links = paginations.find_all("a")
# print(pages)
# make page_list except last one
pages = []
for link in links[:-1]:
pages.append(int(link.string))
# print(pages)
max_page = pages[-1]
# print(max_page)
return max_page
def extract_job(html):
title = html.find("h2",{"class" : "title"}).find("a")["title"]
comp = html.find("span",{"class" : "company"})
comp_anchor = comp.find("a")
comp_name = ""
if comp_anchor is not None :
comp_name = str(comp_anchor.string).strip("\n ")
else:
comp_name = str(comp.string).strip("\n ")
# location = html.find("span",{"class" : "location"}).string
location = html.find("div",{"class" : "recJobLoc"})["data-rc-loc"]
job_id = html.find("h2",{"class":"title"}).find("a")["href"]
return {"title" : title, "company" : comp_name, "location" : location, "link" : f"https://kr.indeed.com{job_id}"}
# print(title, comp_name)
# 5개의 페이지를 request하기
def extract_indeed_jobs(max_page):
jobs = []
for page in range(max_page):
print(f"scrapping page {page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
job_cards = soup.find_all("div",{"class" : "jobsearch-SerpJobCard" })
for job_card in job_cards:
job = extract_job(job_card)
jobs.append(job)
return jobs
main.py
from indeed import extract_indeed_pages,extract_indeed_jobs
max_page = extract_indeed_pages()
indeed_jobs = extract_indeed_jobs(max_page)
print(indeed_jobs)
결과
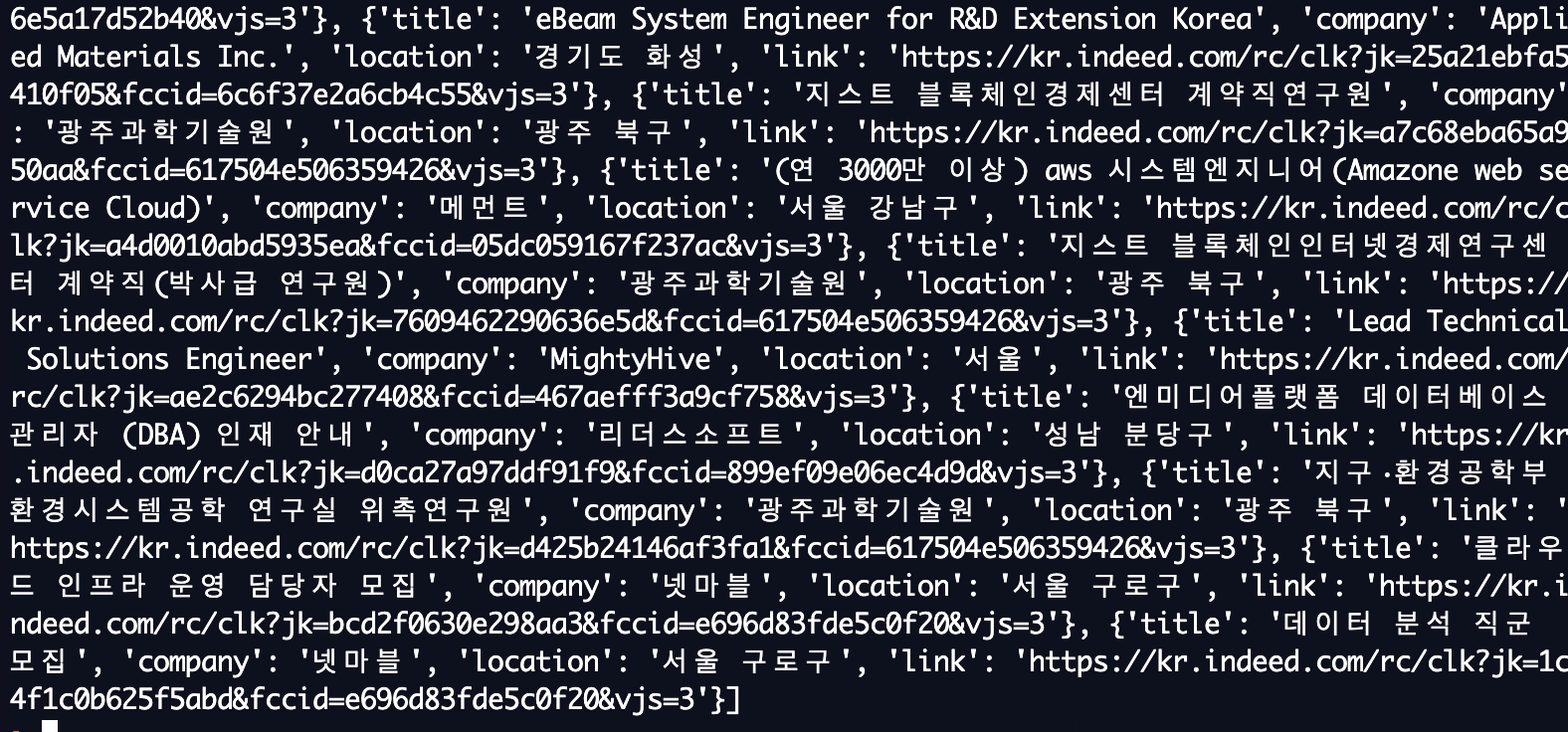
print문을 단 곳은?
원래 유닛 테스트를 해야하는 부분이지만, 현재는 예제이기 때문에 print로 확인하는 것으로 대체합니다.

쫓다.