🔴 멀티모달 학습과 transformers 관련 논문을 볼 것이다
- 2023년, IEEE TPAMI, (IF, 24.314)에서 발표된 논문임

🟠 트랜스포머 모델
- 자연어처리에서 효과적인 성능을 보인 모델이지만, 비전, 멀티모달에도 최근에 많이 사용되고 있음
- 트렌스포머 모델을 활용하여 멀티모달 즉, 다양한 데이터를 어떻게 통합시킬지에 대한 고민을 하고 있다면... 이 논문을 추천!!
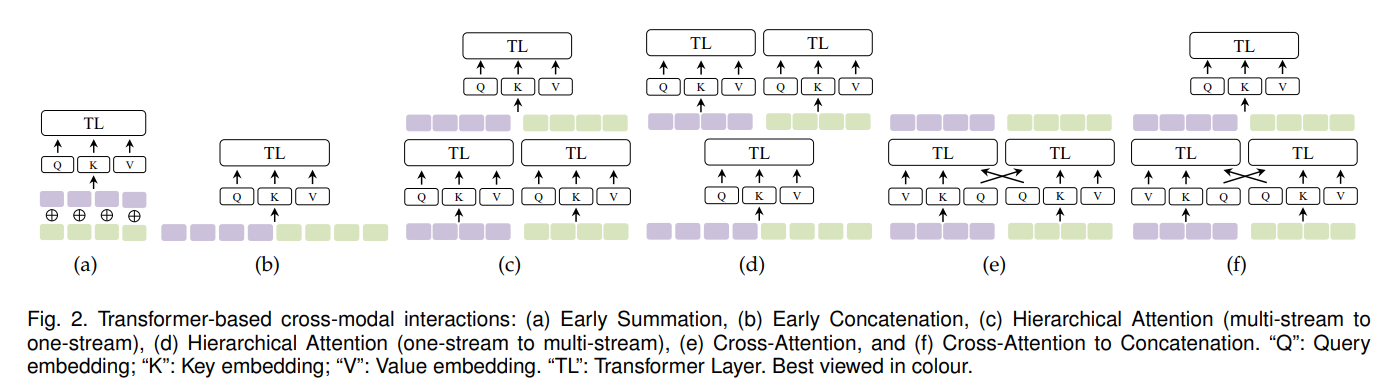
- 아래의 그림 6가지를 기반으로 멀티모달을 통합할 수 있는데... 구체적으로 살펴보자
- (a)
Early Summation
: 간단하고, 효과적인 multimodal interaction 방법
: 여러 modalities의 token embeddings를 각 token position에서 가중치를 합산후, Transformer layers에서 처리
: 장점) 계산이 복잡하지 않음
: 단점) 수동으로 가중치 설정- (b)
Early Concatenation(=all-attention/CoTransformer)
: 여러 modalities의 token embedding sequences가 트렌스포머 레이어에 연결되고 입력됨
: 모든 multimodal token positions은 전체 시퀀스가 되며, 각 모달의 위치는 다른 모달의 context를 조정하여 인코딩함
ex. VideoBERT
: 장점) 초기에 연결하여 융합된 모달을 사용할 수 있음
: 단점) 연결 후, 시퀀스가 길어질수록, 계산량이 늘어남- (c)
Hierarchical Attention (multi-stream --> one-stream)
: Transformer layers는 cross-modal interactions에 attend를 기울이기 위해 계층적으로 결합될 수 있음
: multimodal inputs이 독립적인 Transformer streams으로 인코딩되고, 해당 outputs이 다른 Transformer에 의해 연결되고, 융합됨- (d)
Hierarchical Attention (one-stream --> multi-stream)
: concatenated (연결된) multimodal inputs이 두개의 개별 트랜스포머 streams이 뒤따르는 공유 단일 streams 트랜스포머에 의해 인코딩되는 hierarchical attention
: 이 방법은 cross-modal interactions과 동시에 uni-modal representation의 독립성 유지
ex. InterBERT- (e)
Cross-Attention (=coattention)
: 2-stream 트랜스포머의 경우 Q(Query) 임베딩이 cross-tream 방식으로 교환(exchanged)/swapped되면 cross-modal interactions도 감지할 수 있음
: 이 방법은 VilBERT에서 처음 제안되었음
: 장점) cross-attention 각 모달을 서로 attention 하고, 계산 복잡도가 비교적 적음
: 단점) cross-modal attention을 수행하지 못하므로, 전체 context를 잃음
: two-stream cross-attention은 cross-modal interaction을 학습할 수 있지만, 각 모달 내부의 self-attention은 없음- (f)
Cross-Attention to Concatenation
: cross-attention의 two streams은 global context를 모델링하기 위해 또 다른 트랜스포머에 의해 더 연결되고 처리될 수 있음
: 이러한 종류의 계층적 cross-modal interaction은 cross-attention의 단점을 보완할 수 있음

best of best