🔴 논문제목 : 3D human pose estimation in video with temporal convolutions and semi-supervised training (CVPR, 2019, 인용수 617회 : 22.11.11 기준)
- 2D를 3D로 변환하는 관련 논문을 리뷰하고자 함
- 참고할 코드 및 사이트는 아래와 같음
® [깃허브 소스코드] https://github.com/facebookresearch/VideoPose3D
® [논문읽기 링크] https://openaccess.thecvf.com/content_CVPR_2019/papers/Pavllo_3D_Human_Pose_Estimation_in_Video_With_Temporal_Convolutions_and_CVPR_2019_paper.pdf
® [딥러닝 논문 리뷰 사이트] https://grow-up-by-coding.tistory.com/32
🟠 Abstract
- 레이블이 지정되지 않은 (semi supervised) 영상 데이터를 2D로 예측 -> 3D pose를 추정 -> 입력 2D 키포인트에 역투영 하는 방법을 제안
🟡 Introdution
- 본 연구는 2D 키포인트 감지 -> 3D 포즈 추정으로 공식화를 기준으로, 비디오에서 3D human pose estimation에 초점을 둠
- 본 연구에서 수행한 내용은 아래의 그림과 같음
: 시간 컨볼루션 모델은 2D 키포인트 시퀀스(하단)를 입력으로 사용하고 3D 포즈 추정치를 출력(상단)으로 생성
: 비디오에서 정확한 3D 포즈 예측을 위해 2D 키포인트에 대해 시간적 컨볼루션을 수행하는 완전한 컨볼루션 아키텍처를 제시
: 모든 2D 키포인트 감지기와 호환되며 확장된 컨볼루션을 통해 큰 컨텍스트를 효과적으로 처리할 수 있음
- 요약
(1) 2D 키포인트 궤적에 대한 확장된 시간 컨볼루션을 기반으로 하는 비디오에서 3D 인간 포즈 추정을 위한 간단하고 효율적인 접근 방식을 제시
(2) 레이블이 지정되지 않은 비디오를 활용하고 레이블이 지정된 데이터가 부족한 경우 효과적인 semi-supervised 접근 방식을 소개
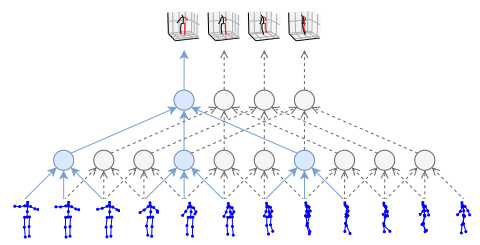
🟢 Realted work
- (2019 기준) 최근, 비디오의 2D 포즈 시퀀스를 고정 크기 벡터로 인코딩한 다음 디코딩하는 LSTM 시퀀스-투-시퀀스 학습 모델이 제안[16]
- 신체 부위 연결에 대한 사전 고려 사항을 고려하는 RNN 접근 방식에 대한 작업도 있음
- GAN(Generative Adversarial Networks)은 2D 주석만 사용할 수 있는 두 번째 데이터세트에서 현실적인 포즈와 비현실적인 포즈를 구별할 수 있으므로[58] 유용한 형식의 정규화를 제공
- 따라서, 본 연구에서는 (1) [34]에서 제안한 단일 프레임 기준선과 [16]에서 제안한 LSTM 모델과 비교하여 시간 차원에 대해 1D 컨볼루션을 수행하여 시간 정보를 활용하고 재구성 오류를 낮추는 몇 가지 최적화를 제안 (2) 2단계 모델(2D 키포인트 감지를 위해 널리 사용되는 stacked hourglass network[38]을 사용함)과 달리 Mask R-CNN[12] 및 cascaded pyramid network (CPN)[5] 탐지는 3D human pose estimation에 대해 더 강력함
🔵 본 연구에서 제안한 방법에 대한 그림
- 예측 가능한 2D 포즈의 시퀀스를 입력으로 사용하는 3D 포즈 모델을 사용한 Semi-supervised
- 사람의 3D 궤적을 회귀하고 레이블이 지정되지 않은 예측의 평균 뼈 길이를 레이블이 지정된 예측과 일치시키기 위해 소프트 제약 조건을 추가함
- 모든 것은 공동으로 훈련됨. WMPJPE는 "가중 MPJPE"를 나타냄

🔵 Result
- 이 모델은 모든 컨볼루션 커널의 너비를 W = 1로 설정한 단일 프레임 기준선에 비해 프로토콜 1에 대해 평균 약 5mm 더 높기 때문에 시간 정보를 활용함
- "Walk"(6.7mm) 및 "Walk Together"(8.8mm)와 같은 매우 역동적인 작업의 경우, 간격이 더 큼
- 인과 관계가 있는 모델의 성능은 단일 프레임 기준선과 본 연구 모델의 중간 정도임. 인과 관계 컨볼루션은 가장 오른쪽 입력 프레임에 대한 3D 포즈를 예측하여 온라인 처리를 가능하게 함
- 흥미롭게도 groundtruth bounding box는 Mask R-CNN을 사용하여 예측된 bounding box와 유사한 성능을 보여 단일 주제 시나리오에서 예측이 거의 완벽함을 나타냄
- 아래의 <그림 4>는 예측된 2D 키포인트를 포함한 예측 포즈의 예를 보여주고 있음

🟤 Conclusion
- 본 연구에서 아키텍처는 2D 키포인트 궤적에 대한 확장된 컨볼루션으로 시간 정보를 활용
- 레이블이 지정된 데이터가 부족할 때 성능을 개선하기 위한 semi supervised training method 사용
- 레이블이 지정되지 않은 비디오에서 작동하며 고유한 카메라 매개변수만 필요하므로 모션 캡처가 어려운 시나리오(예: 야외 스포츠)에서 실용적임

best of best