
03-Infrastructure & Virtualization
🟡 Learing Objective
▪ On-premises vs. Cloud computing
▪ IT infrastructure
▪ How to make infrastructure (인프라 구축 방법)
▪ Mutable and immutable infrastructure (변경가능 & 변경 불가능한 인프라)
On-premises자체적으로 컴퓨터를 확보하고, SW를 운영하는 것 (스스로 데이터 센터를 만듦, 서버구축)
infrastructureGPU, CPU, 네트워크
🔹 On-premises vs. Cloud Computing

🔹 On-premises vs. Cloud Servers
➡ 서버에 접속하기 위해, 사람은 domain name, 컴퓨터는 ip address를 사용함
➡ 서버가 100만대면 이름을 다 지을 수 없음
😍 서버를 생물처럼 애정스럽게 바라보는 것은 위험한 발상임
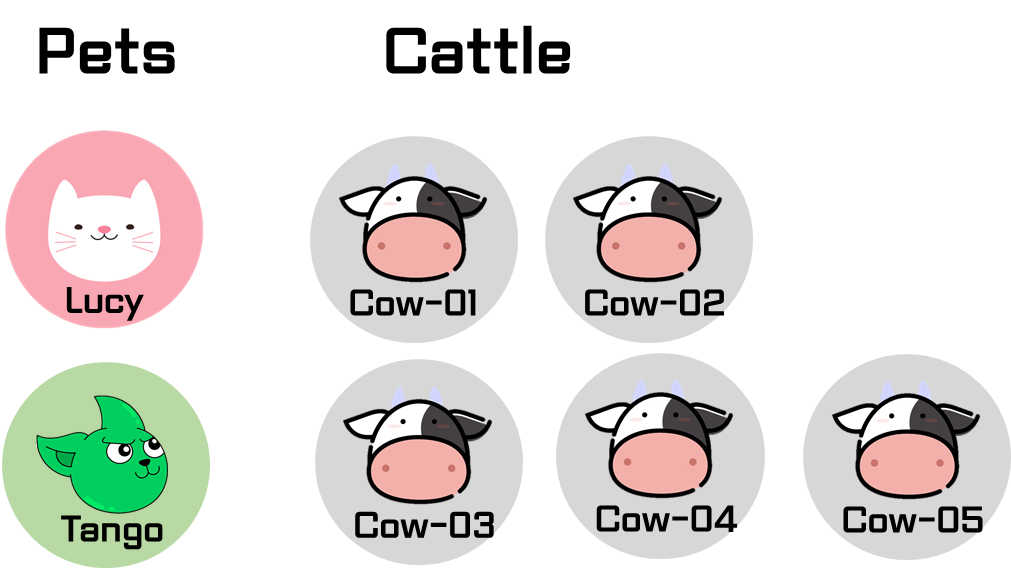
🤜 Cattle Model
: 나중에는 같은 서버로 바라봄
ex. 서버1, 서버2 처럼 이름을 지음
➡ 즉, 컴퓨터들을 일꾼으로 바라봐야 함
ex. 어떤 서버는 불쌍해.. 이런모습으로 보이지 않고, 비슷한 것끼리 그룹화해서 사용하자
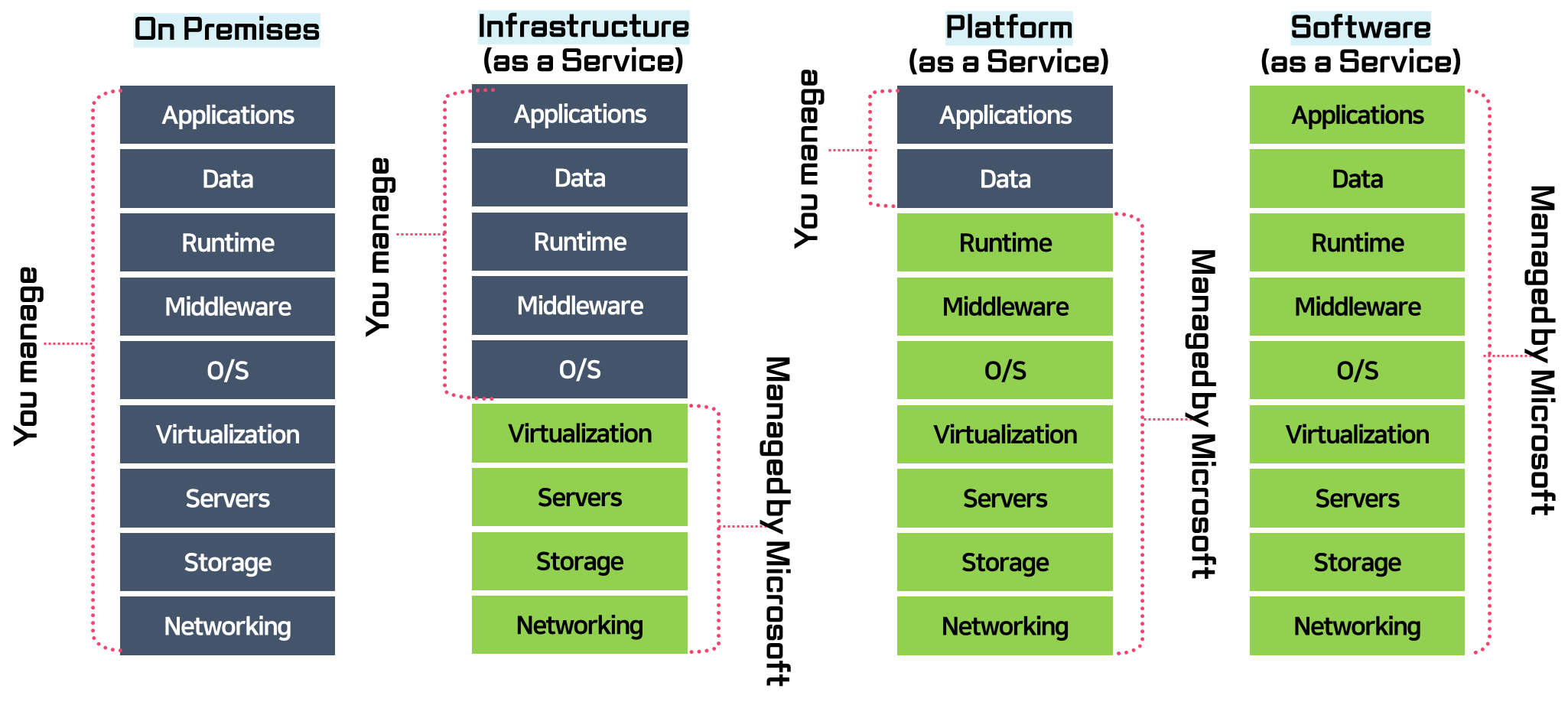
🤜 Cloud Models
➡ 초록색 부분 : 빌려쓰는 것
➡ 파란색 부분 : 직접 만듦
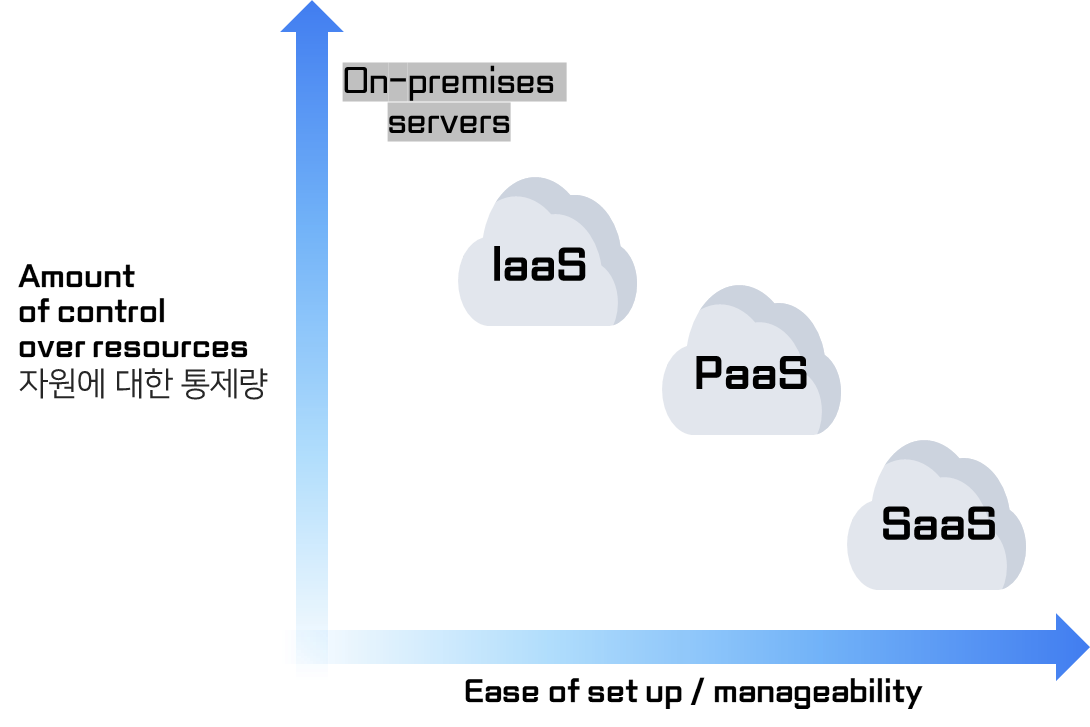
🤜 Cloud Models Comparison
➡ x축 : set-up, 관리에 대한 부담이 늘어남
➡ y축 : 얼마나 본인이 자원들(CPU, GPU, 네트워크)에 대해서 컨트롤을 어디까지 할 수 있을까?
➡ laaS : 관리할 것과 부담이 높음 but, 컨트롤을 모두 본인이 할 수 있음
➡ PasS : 서비스정도 개발하는 경우에 사용
🔹 IT infrastructure Evolution
: IT 일을 하는 사람들의 환경변화, 클라우드 컴퓨팅이 사회적 요구에 맞춰 적자생존, 방향선택이 이루어짐
: 데이터센터에 CPU, GPU가 모여있고, 필요시에 사용하는 클라우드컴퓨팅 모델임
🤜 Server의 3가지
: 가장 아래인 서버에는 3가지가 있는데, 아래의 3가지가 기본적인 하드웨어임
(1) Central processing unit(CPU; 중앙처리장치)
: SW가 돌아가기 위해 만든 프로세서가 첫번째 SW의 하드웨어
(2) Memory(렘; 주격장치)
: 컴퓨터가 동작을 할 때, 운영체제와 SW가 돌아가거나, 빠르게 처리해야 할 데이터들이 들어가는 것
(3) Storage(보조기억장치)
: 데이터를 읽고 저장함
: 디스크라고도 불림
🤜 Server
: 클라이언트가 요청하고, 서비스를 해주는 서버가 있음
: 데이터센터, 클라우드컴퓨팅으로 구글에서 웹서비스를 제공함 (즉, 웹서버가 많이 있음)
: 이메일 서버, 데이터베이스 서버들이 있음
: 서버 역할하는 컴퓨터를 통해서 다양한 서버의 작업들을 하는 것이 데이터센터에서 하는 역할임
🤜 Web Server
: 클라이언트 데이터 요청-관련된 데이터를 가지고 있다가 클라이언트에게 제공
: 클라이언트 처리 요청-processing을 거쳐서 전달함
: HTTP-웹을 가능하게 하는 기술
ex. 'get'이라는 명령어를 서버에 전달하면, 필요한 것을 주거나, 업데이트 등을 할 수 있음
: HTML-네이버, 경희대 홈페이지 처럼 페이지를 구성하는 기술
ex. 소스코드에 이미지, style, 입출력 등의 기능을 포함하고 있음
➡ HTML을 실어나르는 것이 HTTP이고, HTTP를 통해 정보를 주고 받는 것이 HTTP 클라이언트 & HTTP 서버임 (웹브라우저 & 웹서버)
🤜 Database Server
: 데이터베이스-데이터를 관리하는 전용 SW
(1) SQL
: 구조가 잡혀있는 데이터를 쿼리가 필요함
: 구조화 되어있는 데이터를 질의하는 언어
: columns & row로 구성되어 있음 (table: 회계격리-엑셀과 같이)
(2) NoSQL
: SQL은 엑셀 차트와 같은데, NoSQL은 비정형 데이터를 다룰 때 사용(형태가 정해지지 않음)
ex. 블로그, 유튜브-구조화 되어있지 않음
🙂 따라서, 둘의 구조가 다름
🔹 How to make infrastructure
🤜 Infrastructure
: 서버용 운영체제는 리눅스가 대세임
: but, 퍼블릭 클라우드의 경우, 리눅스를 제공
: but, 아마존의 에이저, 윈도우 SW도 제공함
🙂 따라서, 인프라를 구축할 때, 데이터센터에 올리는 OS에 대한 이야기를 할 필요가 있음
🤜 Linux
: 구글, 페이스북, 안드로이드 등이 모두 다 리눅스임
: 리눅스는 슈퍼컴퓨터 500개 모두 다 사용함
: 마이크로소프트를 제외한 데이터센터들이 OS로 사용되고 있음
🤜 Linux Kernel
: 운영체제 중에서 가장 핵심, CPU, 디스크 등 하이웨어 제어, 어플이 요구하는 것에 맞춰 요구함
: 리눅스 사용시) 터미널, Shell 많이 사용
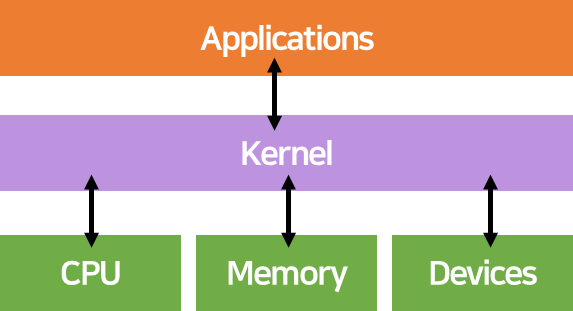
🤜 Middleware
: 중간에 있는 SW, platform에 해당
: User가 사용하는 어플리케이션과 운영체제의 가운데 있음
: 어플리케이션이 필요로 하지만, 운영체제가 제공하지 않는 기능들을 중간에서 제공하는 기능
ex. 개발자-라이브러리
: 운영체제를 보완함
🤜 Deploying at Scale
-서버를 직접 구축한다면, 어떤 작업을 할지 알아보자
ex. 컴퓨터 100대가 하던 일을 만대로 해볼까?
🤜 How to set up Infrastructure?
: 서버를 증설한다면..
(1) 물건을 가져와야 함
(2) 수동으로 하드웨어 구성
(3) 하드웨어에 애플리케이션 배포
🤜 Drawbakcs to this Process (프로세스의 단점)
➡ 나에게 필요한 컴퓨터가 어떤 것일까?
: 우리 데이터센터에 있는 렉에 꽂치는지?
: 인터렉션에 맞는 것인지?
: 범용(돈 주고 살수 없는 물건)할 수 없는 것이라면, 맞춰서 주문제작해야 함
: 하드웨어를 구매한다는 행위 자체가 오랜시간이 걸리고, 어려움이 있음
: 컴퓨터 연결할 사람, 시간, 돈이 많이 필요함
: 물건을 보관할 수 있는 공간도 필요함
: 가장 큰 문제) 설치 전까지는 아무것도 할 수 없음 (서비스 지연상태 발생)
: 결과적으로, 소프트웨어를 올려야 하는데, 설치한 스트로리지, 운영체제 등 버전(환경)이 전부다, 자신의 프로그램에 올리기 전에 동일해야 함
: 필요한 만큼 사용하기 위해 캐틀모델이 필요
🤜 Maintain Infrastructure in Cloud Computing
-
(1) Infrastructure as Code
: SW/어플 관점에서 나의 관점은 100개가 필요하면, 같은 것이 복제가 되어도 문제없이 하는 것
: 어플관점에서 어플이 돌아갈 때 필요한만큼, 요청한 것을 동일한 환경으로 제공하도록 만들어준다는 의미
: 서버 위에 올릴 것인데, 작은 것을 올릴 것임
: 컴퓨터 한대 위에 SW 하나의 역할을 하였음
: CPU를 사용한다면, 수천, 수만개가 있다고 가정하고, CPU에 작은 일만 돌리게 됨
🙂 즉, 작은 일을 하는 애들을 늘리면 됨
➡ 데이터센터 위에 클라우드컴퓨팅의 개념이 뒤덮이고, 필요할 때, 필요한 만큼 사용하는 철학이 나오면서 SW를 어떻게 개발할 것인지에 대한 방법이 달라짐
➡ 수천, 수만개가 있으므로, 작은 함수 여러개가 CPU 위에서 돌아가고, 그 함수가 불려 쓸일이 많아지면, 그 CPU를 많이 늘리면 되지 않을까?
➡ 하나의 컴퓨터 위에서 돌아가는 일은 굉장히 작은 서비스 즉, Microservices임
➡ Continuous delivery : 한 컴퓨터 위에서 올라가는 것이 작은 일인데, 그것을 개발하고 유지 및 보수하는 사람은 많지 않음/ 거대한 프로그램을 만들어서 수만명이 일할 때는 날짜, test 등을 정해야 함
🙂 위의 사항들을 자동화 되도록 하는 것이 가장 중요함
➡ SW 개발 : 운영체제/디바이스에 요구해서 결과를 가져오는 것
➡ 데이터센터에 물어보는 것임
➡ 필요한만큼 사용하고, 제공, 반납하는 것이 자동화 되도록 하는 것 -
(2) Benefits of Infrastructure as Code
: 사람의 개입없이 자동화가 되기에 속도가 빠름/함수로 간단하게 불러옴/환경이 바뀌더라도 쉽게하도록 함
: 에러가 발생하더라도 숨기는 기능을 제공함으로써, 개발자의 입장에서 신뢰할 수 있는 인프라인지 알 수 있음
: 서비스에 집중하는 사람의 경우) 비용&시간, 인력이 발생을 감소시키고, 비용을 줄일 수 있음
🔹 Mutable and immutable infrastructure
-
(1) Mutable Infrastructure
: 많은 CPU와 디스크가 필요함
ex. 어플1.0이 있고, 9개로 시작했는데, 버전이 1.0으로 시작하는 것이 좋다고 하여 사용하였음. 그런데 버전을 낮게 사용하는게 좋다고 함... 이런경우, 운영하는게 얼룩질 수 밖에 없음 (즉, SW 버전이 3개여서 0.9~1.1버전을 유지하기 어려움-SW의 변종모델은 바람직하지 않음)
: 1.0 -> 2.0 버전으로 갈 때, 한꺼번에 가야함
즉, 필요할 때, 늘리는 것을 가능하게 하기 위해서 Immutable을 해야함
: SW 운영시, Immutable의 원칙을 지켜야 함 -
(2) Mutable vs. Immutable
➡ Mutable : 처음 서비스를 시작할 때 OS, 어플이 1개 있고, 어떤 소프트웨어는 변종이며, 버전이 여러개일 수 있는 뒤죽박죽 상태
➡ Immutable: 필요할 때 필요한 만큼 사용하기 위해 단일화 시킴
🙂 따라서, Immutable 철학에 의해 변종이 아닌, 데이터센터 위에 클라우드를 사용함
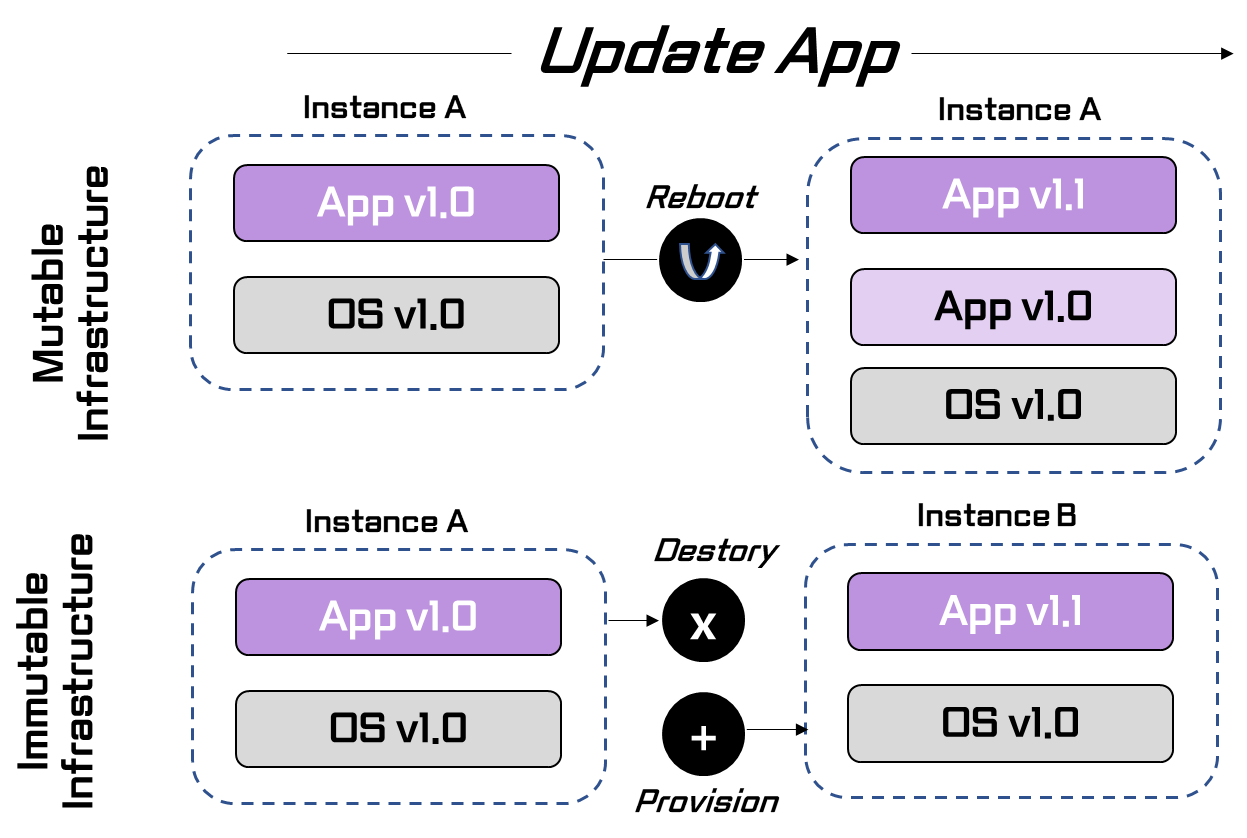
-
(3) Benefits of Immutable Infrastructure
➡ 관리할 필요 없음
: 한 서비스에 있어 하나의 이미지, 소스코드만 유지하면 되기에 만약, 복잡하게 꼬이기 시작하면 제어 불가능 상태로 가는 것을 미리 방지할 수 있음
🙂 즉,Immutable은 A는 이거해, B는 하지마~ 이런식이 아닌, 필요한 만큼 주는 것임
