Map
Map은 키(Key)와 값(Value)의 쌍으로 데이터를 저장하는 자료구조입니다.
모든 데이터는 고유한 키와 그에 해당하는 값으로 이루어집니다.
여기서 고유한 Key란 Key는 중복될 수 없지만 Value는 중복될 수 있습니다.
예를 들어 보물상자가 있다고 가정해보겠습니다.
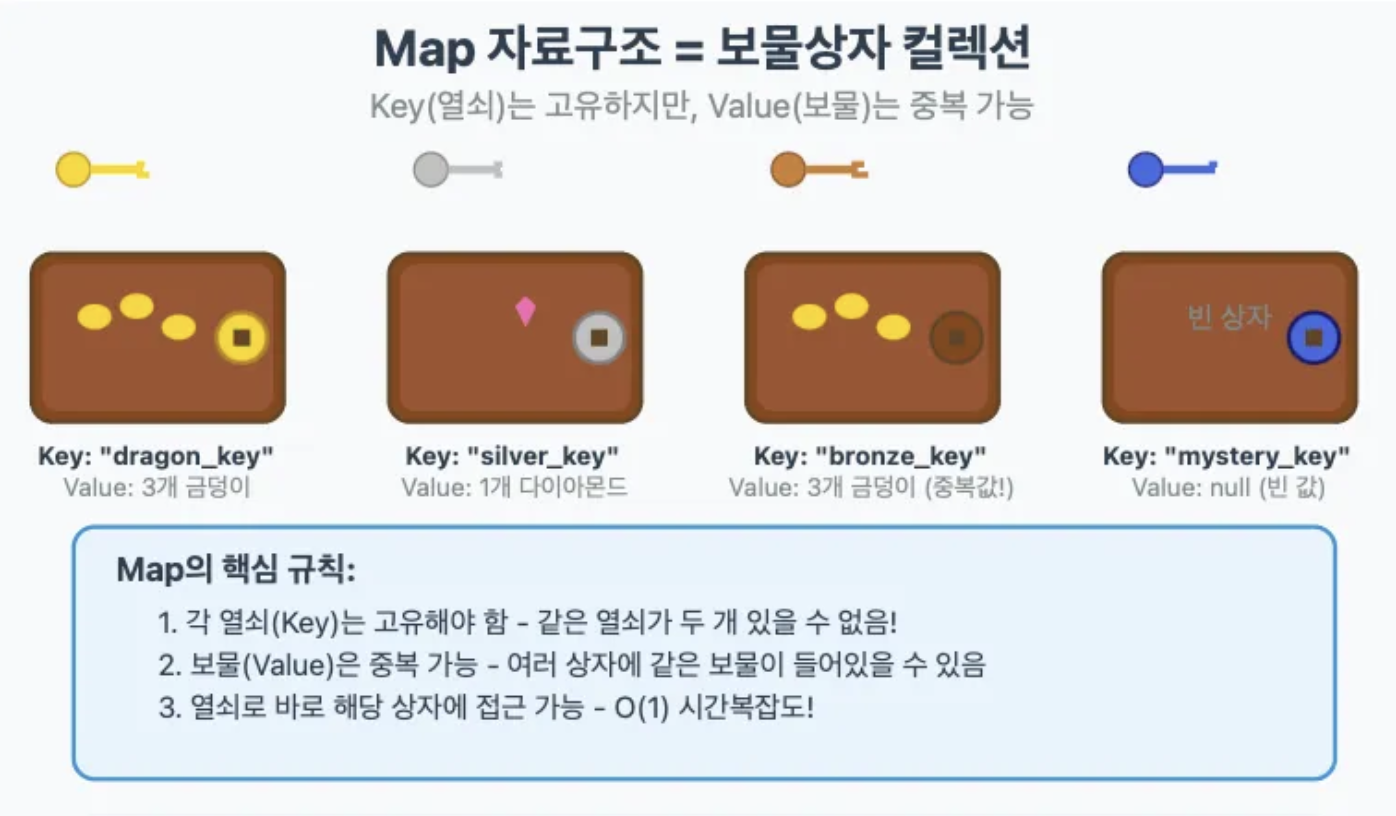
보물 상자의 Key는 고유합니다. 보물상자의 열쇠는 고유하지만 보물상자의 내용물은 황금덩이가 여러 개 들어있을 수 있고, 빈값이 존재할 수 도 있습니다.
이러한 특징을 기반으로 Map 의 특징을 알아보겠습니다.
Map은 내부적으로 키를 사용하여 데이터의 위치를 바로 계산하므로(해싱 등), 데이터 양이 많아져도 검색 속도가 매우 빠릅니다.- 대부분의
Map구현체(예:HashMap)는 데이터를 저장한 순서대로 유지하지 않습니다. 순서 유지가 필요하다면LinkedHashMap같은 특정 구현체를 사용해야 합니다(추후 설명).
Map과 HashMap
위에서 Map의 개념에 대해 알아보았습니다.
Map
Map은 키(Key)와 값(Value)을 하나의 쌍으로 묶어 저장하는 데이터 구조로 interface 입니다.
인터페이스로 주요 기능을 정의하는 설계도 역할을 합니다. 즉, “위와같은 데이터 구조를 다루기 위해서
이런 기능들이 반드시 있어야 해!” 라고 정의할 수 있습니다.
주요 인터페이스 메서드
public actual fun isEmpty(): Boolea
public actual fun containsKey(key: K): Boolean
public actual fun containsValue(value: @UnsafeVariance V): Boolean
public actual operator fun get(key: K): V?Map 인터페이스를 구현하는 클래스로는 HashMap , TreeMap , LinkedHashMap 등이 있습니다.
인터페이스이므로 자체를 객체로 생성할 수 없습니다.
HashMap
HashMap은 Map이라는 설계도(인터페이스)에 따라 실제로 만들어진 구현체 중 하나입니다. Map이 정의한 기능들을 모두 가지고 있으며, 실제 데이터를 저장하고 관리하는 데 사용됩니다.
구현체이므로 Map 인터페이스를 구현하는 객체를 생성할 수 있습니다.
특징
- 해시(Hash) 기술을 사용하여 데이터를 관리하므로, 많은 양의 데이터를 추가, 삭제, 조회할 때 매우 빠른 속도를 보입니다.
- 데이터의 순서를 보장하지 않습니다. 즉, 저장한 순서와 다르게 데이터가 출력될 수 있습니다.
해시함수
HashMap에 본격적으로 알아보기 전 해시함수에 대해 먼저 알아보겠습니다.
해시함수는 임의의 크기를 가진 데이터를 고정된 크기의 값으로 매핑하는 함수입니다
h(k) = v
k는 키(임의 크기), v는 해시값(고정 크기)
Map을 사용하는 이유로 Map은 내부적으로 키를 사용하여 데이터의 위치를 바로 계산하므로(해싱 등), 데이터 양이 많아져도 검색 속도가 매우 빠릅기 때문입니다.
어떻게 검색 속도가 빠를 수 있을가요?
컴퓨터는 데이터를 찾을 때, 보통 처음부터 하나씩 비교하며 찾습니다 (선형 검색). 데이터가 1억 개라면 최악의 경우 1억 번을 비교해야 합니다.
하지만 해시 함수를 사용하면 이 과정이 완전히 달라집니다.
- 저장할 때: '어떤 데이터(Key)'를 해시 함수에 넣어 '고유한 숫자(해시 값)'를 만듭니다. 그리고 그 숫자에 해당하는 위치에 데이터를 저장합니다.
- 찾을 때: 찾고 싶은 '어떤 데이터(Key)'를 다시 해시 함수에 넣어 '고유한 숫자(해시 값)'를 얻습니다. 그리고 그 숫자에 해당하는 위치로 바로 찾아갑니다.
이 과정은 마치 우리가 물건을 보관함에 맡기고 받은 '보관증 번호'와 같습니다. 수많은 보관함 중에서 내 물건을 찾기 위해 모든 문을 열어볼 필요 없이, 보관증 번호에 해당하는 문만 열면 바로 찾을 수 있는 것과 같은 원리입니다.
HashMap의 원리
transient Node<K,V>[] table; // 메인 배열!
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; // 연결리스트를 위한 포인터
}HashMap은 배열 + 연결리스트 구조로 구현되어 있습니다.
우선 HashMap의 putVal 함수가 어떻게 구현되어 있는지 직접 확인해보고 예시를 들어 설명해보겠습니다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}위에서 HashMap은 기본적으로 배열 + 연결리스트로 구현되어있음을 확인했습니다.
- 테이블 초기화 확인
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;HashMap이 처음 사용되거나 비어있는지 확인입니다.
처음 사용되거나 비어있다면 tab = resize() 가 호출되고 첫 번째 put 호출 시 기본 크기 16으로 배열 생성됩니다. (table = new Node[16])
- 배열 인덱스 계산 및 빈 슬롯 확인
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] =
newNode(hash, key, value, null);- (n - 1) & hash: 해시값을 배열 크기로 나눈 나머지 계산 (비트 연산)
- tab[i] = 계산된 인덱스의 배열 슬롯 확인
- null인 경우: 새 노드를 직접 생성하여 저장
| 단계 | 값 | 설명 |
|---|---|---|
| hash | 12345 | key.hashCode() 결과 |
| n | 16 | 배열 크기 |
| n - 1 | 15 | 비트마스크 (1111) |
| hash & 15 | 9 | 최종 인덱스 |
- 충돌 처리 - 첫 번째 노드 확인
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
...- p.hash == hash: 해시값이 같은지 확인
- key.equals(k): 실제 키가 같은지 확인
- 둘 다 같으면: 기존 키를 찾음! → 값만 업데이트
- 예시: 같은 키 재삽입
- 트리 노드 처리
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);- 충돌이 많아서 연결리스트가 트리로 변환된 상태
- putTreeVal(): 트리에 삽입/검색
- 성능: O(log n) 보장
트리 보장 조건
static final int TREEIFY_THRESHOLD = 8; // 8개 이상시 트리화 static final int UNTREEIFY_THRESHOLD = 6; // 6개 이하시 리스트화
- 연결리스트 순회
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}- 연결리스트를 따라가며 탐색
- p.next == null: 리스트 끝에 도달
- 새 노드를 리스트 마지막에 추가
- binCount >= 7: 8개 이상이면 트리로 변환
- 중간에 같은 키 발견시 즉시 중단
- 기존 키 발견시 값 업데이트
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}- 기존 키가 발견된 경우 처리
예시 상황
HashMap 이라는 아파트가 있다고 가정해보겠습니다.
배열(Node[] table) = 아파트의 각 층이라고 생각할 수 있습니다.
HashMap의 뼈대인Node배열은 아파트의 각 층에 해당합니다. 이 배열의 각 칸을 버킷(bucket)이라고 부릅니다.HashMap은 기본적으로 16층짜리 아파트로 시작합니다.
즉, 처음 16층의 아파트가 있다고 생각하시면 됩니다.
아파트에는 당연히 엘리베이터가 있겠죠?
hash(key) = 엘리베이터
- 내가 가진 키(key)를 해시 함수에 넣으면, 내가 몇 층으로 가야 할지 알려줍니다. (예: "너는 7층으로 가!")
- 이 영역이 바로 2번 설명의 역할을 하는 조건입니다.
Node = 각 층의 집 (세대)
- 충돌이 없을 때: 7층에 도착했는데 아무도 살고 있지 않다면, 701호에 입주하면 됩니다. 이 경우 버킷에는 노드가 딱 하나만 있습니다.
- 충돌이 발생할 때 (연결 리스트): 7층에 도착했는데 이미 701호에 다른 사람(Node)이 살고 있습니다. 그러면 나는 그 옆집인 702호에 입주하고, 701호 집에는 '옆집에 702호가 있다'는 표시(
next포인터)를 남깁니다. 또 다른 사람이 7층에 오면 703호에 입주하고, 702호는 703호를 가리킵니다. - 이렇게 같은 층(버킷)에 여러 세대(노드)가 복도(연결 리스트)를 따라 쭉 늘어서는 구조가 됩니다.
그렇다면 현재 7층에 2세대가 살고 있다고 가정해보겠습니다.
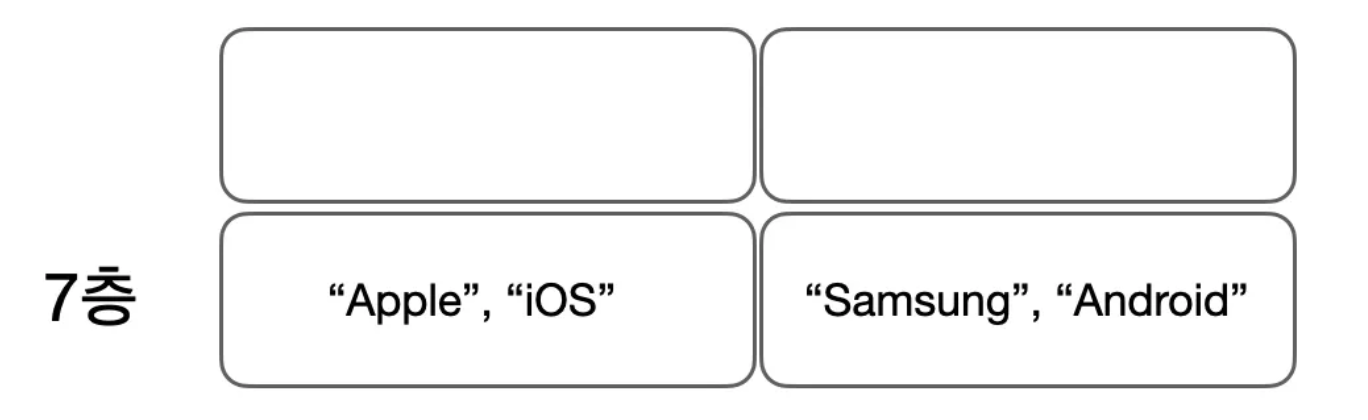
그렇다면 Samsung을 키로 가지는 Android 값은 어떻게 찾을 수 있을가요?
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))getNode 함수에서 해쉬 함수를 비교하고 key에 대한 equals 함수를 실행하여 비교할 수 있습니다.
좋은 해시함수와 나쁜 해시함수
위에서 HashMap이 어떠한 동작원리로 이루어지는지 확인했습니다.
기본적으로 16층 아파트가 만들어지고 각 층마다 8세대까지 살 수 있으며 8세대 이후에는 연결리스트에서 → 트리 구조로 변경되게 됩니다.
그 이유로는 Map 을 사용하는 이유에서 찾을 수 있습니다.
한 층에 8세대가 입주하는 순간 "이 층은 너무 복잡해졌군. 더 효율적인 구조로 리모델링해야겠다!"라고 판단합니다.
- 연결 리스트에서 특정 집을 찾으려면 최악의 경우 8번을 다 확인해야 합니다 (O(n))
- 트리 구조에서는 훨씬 효율적으로 탐색할 수 있어, 8개의 데이터가 있어도 약 3번의 비교만으로 원하는 값을 찾을 수 있습니다 (O(log n)).
여기서 해시 충돌 이라는 단어가 등장합니다.
해시 충돌이란 해시 함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황을 의미합니다.
즉 아파트 예제에서 map에 새로운 값을 추가하였다고 가정해보겠습니다.
hash 함수를 실행한 결과 7층으로 가라는 통보를 받았습니다.
하지만 7층에는 이미 3세대나 살고 있었습니다. 즉 key에 대해 동일한 hash값이 나오는게 6개나 있다는 것을 의미합니다.

이를 해시 충돌이라고 하며 새로운 값은 704호에 입주하게 됩니다.
그럼 해시 충돌은 나쁜가?
- 해시 충돌은 어쩔 수 없습니다. 입력될 수 있는 키의 종류는 거의 무한하지만,
HashMap의 버킷(공간)은 한정되어 있기 때문에 충돌은 필연적으로 발생합니다. - 충돌 자체가 나쁜 것은 아닙니다:
HashMap은 충돌이 일어날 것을 이미 알고 있고, 이를 해결하기 위한 방법(연결 리스트, 트리 변환)을 미리 준비해두었습니다. 문제는 충돌이 얼마나 자주, 그리고 특정 위치에 집중되어 일어나느냐입니다. - 좋은 해시 함수 = 고른 분포: 좋은 해시 함수는 충돌이 일어나더라도 특정 버킷에 몰리지 않고, 전체 버킷에 골고루 흩어지게 만듭니다. 이로 인해
HashMap이 충돌을 효율적으로 관리하고 빠른 성능을 유지할 수 있습니다.
즉 나쁜 해시 함수란 데이터가 특정 층에 몰리는 것을 의미하고, 좋은 해시 함수란 여러 층에 각 세대들이 고르게 분포되는 것을 의미합니다.
해시맵의 버킷 사이즈 (Capacity)
HashMap의 버킷 사이즈는 *아파트가 총 몇 층인가를 의미하며, 용량(Capacity)이라고 부릅니다.
- 초기 용량 (Initial Capacity):
HashMap을 처음 만들면 기본적으로 16층짜리 아파트 (버킷 16개)로 지어집니다. 물론 처음부터 더 큰 아파트를 지을 수도 있습니다. - 항상 2의 거듭제곱:
HashMap의 층수(용량)는 항상 16, 32, 64, 128...처럼 2의 거듭제곱 형태를 유지합니다. 그 이유는(n-1) & hash라는 빠른 비트 연산으로 버킷 위치를 계산하기 위함입니다. - 리사이징 (Resizing): 아파트가 일정 수준 이상으로 꽉 차면 (기본적으로 75% 이상 - 이를 로드 팩터(Load Factor)라 함),
HashMap은 더 큰 아파트를 짓습니다.- 예를 들어 16층 아파트에 12세대(
16 * 0.75)가 입주하면,HashMap은 기존의 2배 크기인 32층짜리 아파트를 새로 짓고 모든 세대(데이터)를 그곳으로 이주시킵니다. 이 과정을 리사이징이라고 합니다. - 리사이징은 비용이 큰 작업이지만, 이를 통해 버킷(층)의 수를 늘려서 앞으로 발생할 해시 충돌을 줄이고 다시 빠른 속도를 유지할 수 있게 해줍니다.
- 예를 들어 16층 아파트에 12세대(
