정규표현식이란
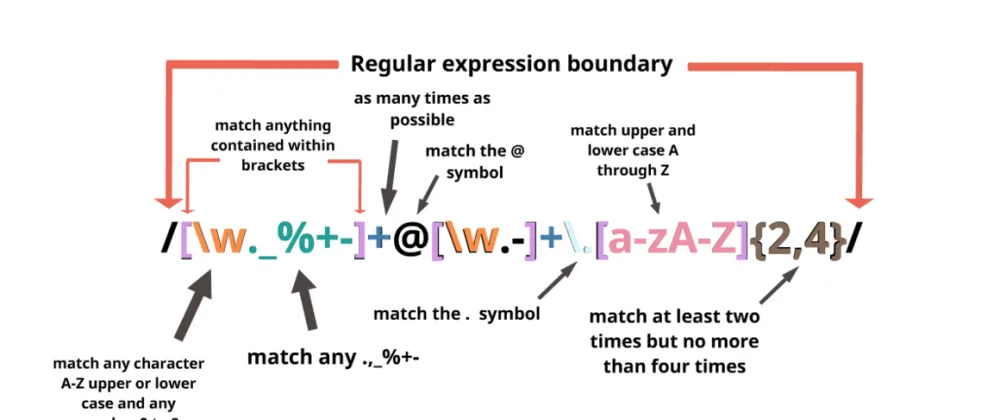
정규표현식의 사전적 정의는 '특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어' 입니다.
간단하게 말하자면, '문자열의 패턴을 표현한 식' 입니다.
어떠한 규칙을 만족하는 문자열을 찾거나, 만족하는지 확인하거나, 대체하거나, 치환하는 등의 경우는 생각보다 많습니다.
비밀번호, 이메일, 휴대폰 번호, IP 주소, 이름 (영문 / 국문), 특정 조건의 숫자 (자릿수, 소수점 자릿수, 특정 문자 포함 여부 등)
잠깐 생각해봐도 이 정도 경우의 수가 나오는데 실무에서는 더 다양하고 까다로운 조건의 문자열 패턴들을 다뤄야 하기 때문에 이번 포스팅에서는 정규표현식을 자세히 들여다보려고 합니다.
정규표현식은 프로그래밍 언어 별로 정규표현식 엔진이 다르게 구현되어 있기 때문에 문법이 다를 수 있습니다.
여기서는 Javascript (이하 JS) 엔진의 정규표현식을 기준으로 합니다.
정규표현식 생성 방법
JS에서는 정규표현식을 생성하는 2가지 방법이 존재합니다.
1. 리터럴
const regExp = /qwerty/;리터럴 방식은 문자열을 /로 감싸는 방식입니다. 정규식이 스크립트가 로드될 때 컴파일되기 때문에 한 번 선언한 뒤 변하지 않을 때 성능상 이점이 있습니다.
2. RegExp 생성자
const regExp = new RegExp('qwerty');생성자를 선언하는 방식은 매개변수로 패턴을 전달하는 방식입니다. 정규식이 런타임 시점에 컴파일되기 때문에 동적으로 변화시켜야 할 때 유용합니다.
여기서부터는 암기가 필요한 영역입니다. 말 그대로 특정 패턴을 약속한 방식이 정규식이기 때문에 이 패턴을 알아야지만 (= 외워야지만) 어떤 문자열을 표현하는지 알 수 있습니다.
불행히도 이러한 패턴들은 매우 함축적이라 바로 파악이 어렵습니다.
플래그
JS에서는 고급 검색을 위해 플래그를 지원합니다.
플래그는 정규표현식 생성 방식에 따라 선언 방식이 다릅니다.
const regex1 = /abc/flags;
const regex2 = new Regex(/abcd/, flags);리터럴 방식에서는 마지막 / 뒤에 들어가고 생성자 방식에서는 2번째 매개변수로 들어갑니다.
g (global): 전역 검색
g가 없는 경우에는 최초 검색 결과만을 반환하지만, g가 있는 경우에는 모든 검색 결과를 배열로 반환합니다.
const str = "abcabc";
str.match(/a/); // ["a", index: 0, input: "abcabc", groups: undefined]
str.match(/a/g); // (2) ["a", "a"]m (multi-line): 줄바꿈 검색
여러 줄의 정규식이 줄마다 개별의 정규식으로 다루어져야 할 때 사용되며, 밑에서 소개할 시작(^) 앵커와 종료($) 앵커가 전체 문자열이 아닌 각 줄 별로 검색합니다.
const str = `abc
abc`;
str.match(/$/g); // [""]
str.match(/$/gm); // ["", ""]i (Case Insensitive): 대소문자 구분 없음
정규식은 기본적으로 대소문자를 구분합니다.
i 플래그를 통해 대소문자를 구분하지 않게 검색할 수 있습니다.
const str = "abcABC";
str.match(/b/gi); // (2) ["b", "B"]정규식 패턴
문자 집합 (Character set): [], [^]
1. []: 긍정 문자 집합
대괄호 ([])로 묶인 부분은 긍정을 의미하며 내부의 문자열 중 하나라도 일치하는 패턴을 말합니다.
const str = 'gray or grey';
str.match(/gr[ae]y/g); // ["gray", "grey"]
const specialStr = '!@#$%';
specialStr.match(/[@#$]/g); // ["@", "#", "$"]
[]안에 있는 특수문자는 메타 문자로 취급되지 않고 리터럴 특수문자로 취급되기 때문에 별도로 escape (문자 앞에 \) 할 필요가 없습니다.
연속된 문자열을 나타내고 싶을 때는 -로 범위를 지정할 수 있습니다.
const regExp1 = /[A-Z]/;
const regExp2 = /[ABCDEFGHIJKLMNOPQRSTUVWXYZ]/;
// 위의 두 정규식은 같은 패턴입니다.A-Z, a-z, 0-9, ㄱ-ㅎ, 가-힣도 가능합니다.
2. [^]: 부정 문자 집합
긍정 문자 집합과는 반대로 대괄호 안에서 ^로 시작한다면 해당 문자열이 아닌 문자열만을 매칭합니다.
const mixedStr = 'a!b@c#d$';
mixedStr.match(/[a-z]/g); // ["a", "b", "c", "d"]
mixedStr.match(/[^a-z]/g); // ["!", "@", "#", "$"]10진수: \d
\d는 숫자를 의미하며 [0-9]와 동일한 역할을 하는 단축어입니다.
대문자인 \D는 역집합 (숫자가 아닌 것) 을 나타냅니다.
const str = 'this year is 2022.';
str.match(/\d/g); // ["2", "0", "2", "2"]
str.match(/\D/g); // ["t", "h", "i", "s", " ", "y", "e", ...]
정규식에서 대문자는 소문자가 나타내는 패턴의 역집합을 의미합니다.
단어: \w
\w는 영어 대소문자, 숫자, _를 포함하는 집합 [A-Za-z0-9_]과 동일한 역할을 하는 단축어입니다.
\W는 그 역집합 (영어 대소문자, 숫자, _이 아닌 것) 을 나타냅니다.
const str = 'this year is 2022.';
str.match(/\w/g); // ["t", "h", "i", "s", "y", "e", "a", ...]
str.match(/\W/g); // [" ", " ", " ", "."]공백: \s
\s는 스페이스, 탭, 줄 바꿈 등을 포함한 공백 문자에 해당합니다.
\S는 그 역집합 (공백 문자가 아닌 것) 을 나타냅니다.
const str = 'this year is 2022.';
str.match(/\s/g); // [" ", " ", " "]
str.match(/\S/g); // ["t", "h", "i", "s", "y", "e", "a", ...]임의의 문자: .
.은 개행 문자를 제외한 모든 단일 문자에 해당합니다.
const str = 'this year is 2022.';
str.match(/./g); // ["t", "h", "i", "s", " ", "y", "e", ...]앵커: ^, $
앵커는 입력된 정규식이 어떤 위치에서 있어야 동작할지 제한하는 역할을 합니다.
위치만 특정할 뿐 패턴에는 포함되지 않습니다.
^는 패턴의 시작 부분을 확인합니다.
$는 패턴의 종료 부분을 확인합니다.
const str = 'this year is 2022.';
str.match(/^t/); // ["t", index: 0, input: "this year is 2022.", groups: undefined]
str.match(/.$/); // [".", index: 17, input: "this year is 2022.", groups: undefined]
^와[^]은 완전히 다른 의미입니다. 이 둘의 차이점은[]안에 있느냐 없느냐 입니다.
단어 경계: \b
\b는 다른 단어 (\w) 가 앞이나 뒤에 등장하지 않는 위치임을 나타냅니다.
\B는 그 역집합 (단어가 붙어있는 경우) 을 나타냅니다.
const str = 'wing or swing';
// 앞뒤에 단어가 없는 wing
str.match(/\bwing\b/); // ["wing", 0, "wing or swing", groups: undefined]
// 앞에는 단어가 붙어있고 뒤에는 없는 wing
str.match(/\Bwing\b/); // ["swing", 9, input: "wing or swing", groups: undefined]교체 구문: |
|은 OR 연산자와 동일하며, 연산자 우선 순위가 가장 낮습니다.
여러 정규식을 붙이고 싶을 때 사용합니다.
const str = 'apple and samsung';
str.match(/apple|samsung/g); // ["apple", "samsung"]수량자
메타 문자들이 n번 반복됨을 나타내기 위한 문자입니다. 적용하고자 하는 문자의 오른쪽에 붙입니다.
기본적으로 정규식은 탐욕적이기 때문에 다양한 경우의 패턴이 매칭될 때에는 가능한 긴 패턴을 반환합니다.
const str = "hello";
// `hell` 또는 `hello` 가 있는지 검색하는 정규식입니다
str.match(/hello?/);
// ["hello", index: 0, "hello", groups: undefined]?이라는 옵셔널 플래그로 hell or hello이라는 두 가지 경우에 일치하는지 검색하는 정규식입니다.
이 경우, 둘 다 일치하지만 정규식은 기본적으로 탐욕적이기 때문에 더 긴 값 (hello) 을 반환합니다.
게으른 수량자
그렇다면 hell이라는 단어를 반환하게 하려면 어떻게 해야 할까요?
수량자 뒤에 한 번 더 ?를 붙이면 됩니다.
str.match(/hello??/);
// ["hell", index: 0, "hello", groups: undefined]동일한 문자열을 탐색했지만 가능한 한 짧은 값을 반환 받았습니다.
?이라는 옵셔널 플래그 뿐만 아니라 앞으로 소개할 수량자에서도 똑같이?을 뒤에 붙이고 안붙이고의 차이로 탐욕적 혹은 게으른 수량자가 됩니다.
0번 혹은 1번 일치: ? or ??
const str = 'qqqqqq';
str.match(/qqq?/); // ["qqq", index: 0, input: "qqqqqq", groups: undefined]
str.match(/qqq??/); // ["qq", index: 0, input: "qqqqqq", groups: undefined]앞서 예로 든 것처럼 ?이 1번이면 탐욕적이기 때문에 qqq가 반환되고 ??이면 게으르기 때문에 qq를 반환합니다.
1번 이상 일치: +
const str = 'qqqqqq';
str.match(/q+/); // ["qqqqqq", index: 0, input: "qqqqqq", groups: undefined]
str.match(/q+?/); // ["q", index: 0, input: "qqqqqq", groups: undefined]0번 이상 일치: *
const str = 'qqqqqq';
str.match(/q*/); // ["qqqqqq", index: 0, input: "qqqqqq", groups: undefined]
str.match(/q*?/); // ["", index: 0, input: "qqqqqq", groups: undefined]정확히 n번 일치: {n}
const str = 'ababbc';
str.match(/ab{1}/); // ["ab", index: 0, "ababbc", groups: undefined]
str.match(/ab{2}/); // ["abb", index: 2, "ababbc", groups: undefined]n번 이상 m번 이하 일치: {n, m} or {n, m}?
const str = 'qqqqqq';
str.match(/q{2,4}/); // ["qqqq", index: 0, input: "qqqqqq", groups: undefined]
str.match(/q{2,4}?/); // ["qq", index: 0, input: "qqqqqq", groups: undefined]적어도 n번 이상 일치: {n,} or {n,}?
const str = 'qqqqqq';
str.match(/q{2,}/); // ["qqqqqq", index: 0, input: "qqqqqq", groups: undefined]
str.match(/q{2,}?/); // ["qq", index: 0, input: "qqqqqq", groups: undefined]그룹화와 캡처화
그룹화는 정규식 내의 특정 부분을 단일 표현식으로 구분하기 위해 사용됩니다.
// 이 표현식은 [ab, abb, abbb, ...] 를 검색합니다.
str.match(/ab+/g); // ["abbb", "ab", "ab"]
// 이 표현식은 [ab, abab, abab, ...] 를 검색합니다.
str.match(/(ab)+/g); // ["ab", "abab"]괄호로 묶여진 그룹은 하나의 표현식으로 취급됩니다.
캡처화는 괄호로 묶인 단일 표현식이 정규식 안에서 \1, \2와 같은 이름의 임시 변수에 저장하여 참조할 수 있게 함을 말합니다. 이 임시 변수를 정규식 내에서 다시 호출하는 것을 역참조라고 합니다.
\1,\2와 같은 임시 변수는 순서에 기반합니다.
캡처링 그룹화: (x)\n
const str = 'aabaababbab';
str.match(/(a)(b)\1\2/); // ["abab", "a", "b", index: 4, input: "aabaababbab", groups: undefined]1번째 그룹인 a가 \1이 되고, 2번째 그룹인 b가 \2가 되기 때문에 결론적으로 str.match(/(a)(b)(a)(b)/);와 같은 의미가 되고 abab를 찾게 됩니다.
캡처 그룹이 포함된 경우에는 각 캡처 그룹을 실행한 결과가 모두 포함되어 반환됩니다.
str.match의 기본 결과값str.match의 1번 캡처 그룹의 결과값str.match의 2번 캡처 그룹의 결과값
비캡처링 그룹화: (?:x)
그룹화는 필요하지만 캡처화가 필요하지 않은 경우에는 ?:로 괄호를 시작하여 캡처화를 방지할 수 있습니다.
const str = 'aabaababbab';
str.match(/(?:ab)+/); // ["abab", "ab", index: 4, input: "aabaababbab", groups: undefined]여기에서 만약
\1와 같은 캡처된 값을 사용하려고 하면null을 반환합니다.
명시적 캡처링 그룹화: (?<name>x)...\k<name>
const str = 'aabaababbab';
str.match(/(?<foo>ab)\k<foo>/); // ["abab", "a", "b", index: 4, input: "aabaababbab", groups: undefined](?<foo>ab)로 ab를 foo라는 이름으로 캡처링하고 이를 \k<foo>로 선언하였기 때문에 이 정규식은 결국 str.match(/abab/);와 같습니다.
전후방탐색
주어진 패턴의 붙어있는 좌측 혹은 우측에 있는 문자열이 일치하는지를 탐색하는 패턴입니다.
여기에서는 괄호 안에 있는 문자는 결과값에 포함되지 않습니다.
전방 탐색: x(?=y)
y를 만족하면서 앞에 x가 있는 경우에 해당합니다.
const str = 'abcd';
str.match(/c(?=d)/); // ["c", index: 2, input: "abcd", groups: undefined]부정 전방 탐색: x(?!y)
y를 만족하면서 앞에 x가 없는 경우에 해당합니다.
const str = 'abcd';
str.match(/c(?!d)/); // null
str.match(/b(?!d)/); // ["b", index: 1, input: "abcd", groups: undefined]후방 탐색: (?<=y)x
y를 만족하면서 뒤에 x가 있는 경우를 나타냅니다.
const str = "abcd";
str.match(/(?<=b)c/); // ["c", index: 2, input: "abcd", groups: undefined]
str.match(/(?<=a)c/); // null부정 후방 탐색: (?<!y)x
y를 만족하면서 뒤에 x가 없는 경우를 나타냅니다.
const str = "abcd";
str.match(/(?<!b)c/);
// null
str.match(/(?<!a)c/);
// ["c", index: 2, input: "abcd", groups: undefined]마무리
정규식을 표현하는 특징들은 위와 같습니다.
알아두어서 절대 나쁠 내용은 아니지만 그리 간단하지는 않음을 알 수 있습니다.
또한, 언어마다 버전마다 차이가 있기 때문에 불가피한 경우가 아니라면 validator나 구글의 RE2 라이브러리 등을 사용하는 것도 추천합니다.
