음식물 쓰레기 처리기 설치를 위한 음식물 쓰레기 발생량 & 처리기 대수 시각화

개요
거주중인 주택 1층에 음식물 처리장치가 설치되었다.
기존의 음식물을 전용 쓰레기 봉투에 담아 쓰레기통에 버리는 방식보다 훨씬 간편하고, 청결하며, 비닐을 사용하지 않으니 환경에도 좋은 방식인 것 같아 전국적으로 보급이 되었으면 하는 생각에 한국수자원공사에서 제공하는 환경 빅데이터 플랫폼에서 <음식물쓰레기처리장비정보목록(2021.09).csv>와 <음식물쓰레기발생량추정정보(2023년수정)>을 사용하여 발생량대비 처리장치 설치 수가 적은 지역를 추출할 것이다.
데이터출처
환경 빅데이터 플랫폼 https://www.bigdata-environment.kr/user/main.do
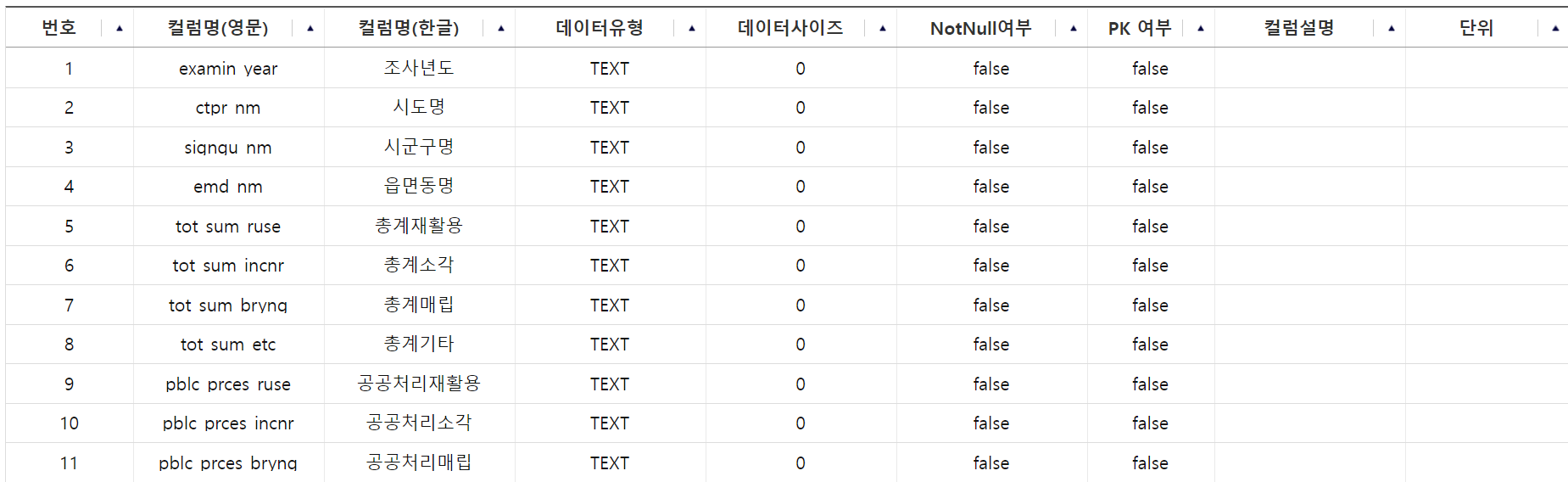
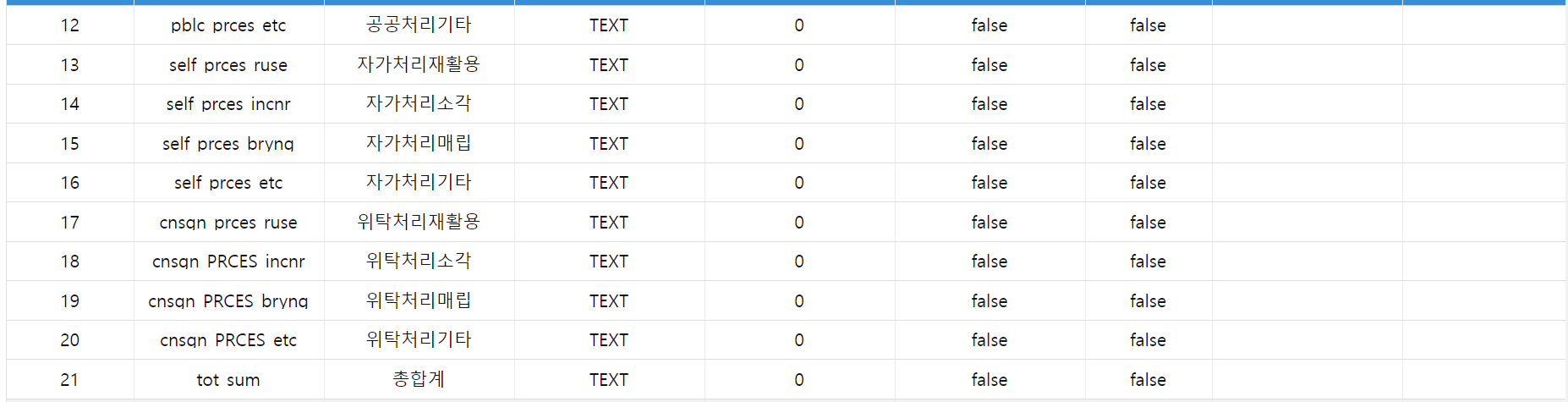
음식물쓰레기발생량추정정보(2023년수정).csv
데이터 스키마
먼저 총계 소각, 총계 매립, 총계 기타를 모두 합한 열을 새로 만든다.
import numpy as np
import pandas as pd
df1 = pd.read_csv('음식물쓰레기_발생량_추정_정보(2023년_수정).csv', sep = ',')
df2 = pd.read_csv('음식물_쓰레기_처리장비_정보_목록(2021.09).csv', sep = ',')
#총계소각, 총계매립, 총계 기타를 모두 합한 열을 새로 만든다.
#재활용은 제외하는 것으로 한다.
df1['Food Waste Sum']=df1['tot_sum_incnr']+df1['tot_sum_bryng']+df1['tot_sum_etc']
data_s = df1.groupby(by='signgu_nm')['Food Waste Sum' ].sum()
print(data_s)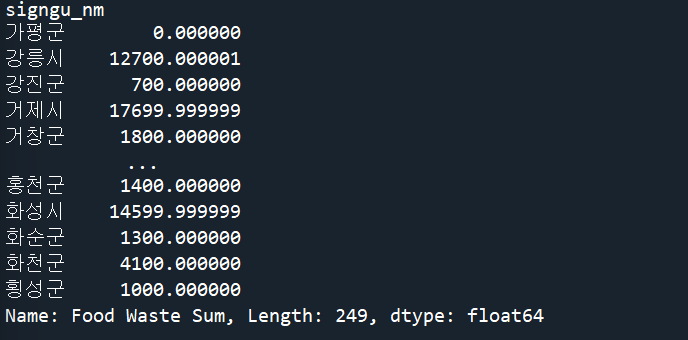
음식물쓰레기처리장비정보목록(2021.09).csv
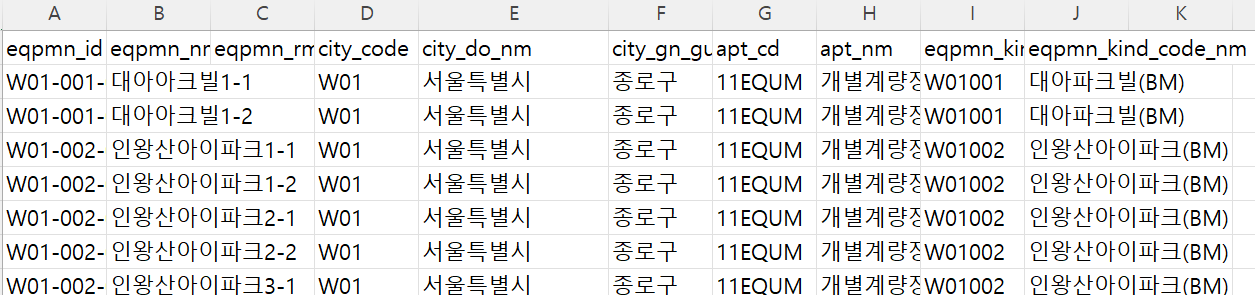
city_gn_gu_nm(시군구 이름) 열의 요소들이 발생량 데이터세트와는 다르게 앞에 어느 시인지 붙어있지가 않다.
'서울 종로구'가 아닌 '종로구', '서울 강동구'가 아닌 '강동구'
새로 함수를 짜서 분류가 가능하게끔 데이터세트를 새로 만들어야 한다.
우리가 필요한 정보는 어느 구(혹은 군)에 음식물 처리장비가 총 몇대있는 지 알 수 있는 정보이므로,
새로만든 data_s에 새로운 열을 추가한다
이 열은 각 지역의 음식물 처리장비의 갯수를 기록한다.
signgu_nm(시군구 이름)에서 장비 정보 목록.csv의 city_gn_gu_nm에 대응하는 데이터가 있다면
카운트를 1올리는 알고리즘을 작성한다.
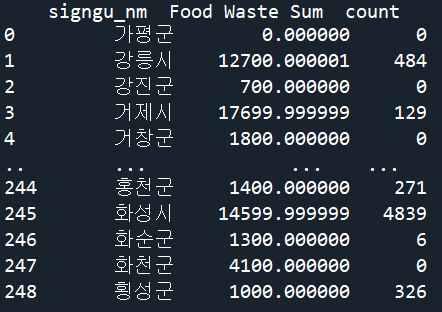
#지역별 총 음식물 쓰레기 합계량을 나타내는 새로운 데이터세트
data_s = df1.groupby(by='signgu_nm')['Food Waste Sum' ].sum().reset_index()
data_s['count'] = 0
#지역이름 부분일치시 카운트
for i, a in enumerate(data_s['signgu_nm']):
for j, b in enumerate(df2['city_gn_gu_nm']):
if a in b:
data_s['count'][i] += 1
print(data_s)
그러나 위 코드는 pandas 함수를 사용하여 아래 코드로 대체가 가능하다.
data_s['count'] = data_s['signgu_nm'].apply(lambda x: sum(df2['city_gn_gu_nm'].str.contains(x)))
위 방식이 CPU사용량도 덜하다.
음식물 쓰레기가 발생하지 않는(재활용하는) 지역 제거하기
for 반복문을 사용하여 행을 제거하기보다는 pandas 함수 기능을 사용하여 제거하자
#음식물 처리를 모두 재활용으로 처리하는 지역 행 제거하기
data_s = data_s[data_s['Food Waste Sum'] != 0]
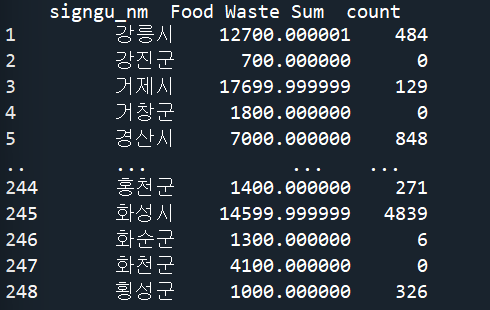
Food Waste Sum / count 값 생성
분모가 0이면 오류가 발생하므로
count가 0이면 0을 1로 대체하는 코드 작성
#0인 count 값 1로 대체
data_s = data_s.replace({'count' : 0}, 1)
#count/Food Waste Sum 열 생성
data_s['처리율'] = data_s['count']/data_s['Food Waste Sum']
print(data_s)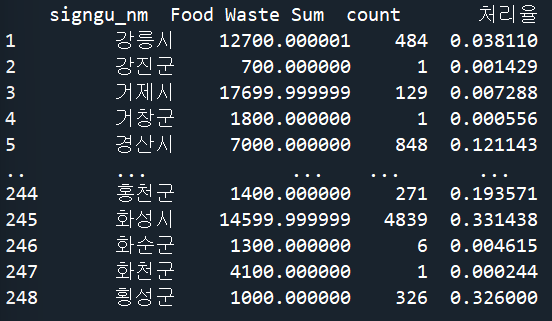
재정렬
#처리율이 적은 순으로 정렬된 데이터 세트
df_sorted_by_values = data_s.sort_values(by='처리율' ,ascending=True)
print(data_s_sorted)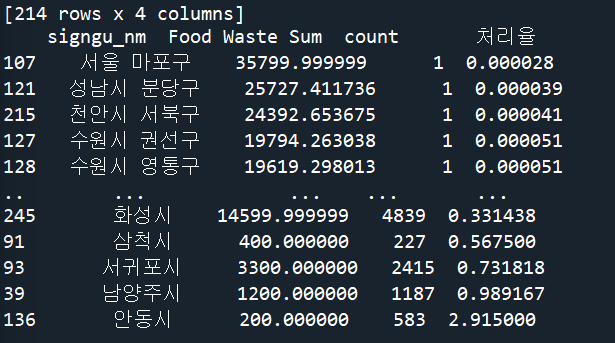
처리장비 우선보급 지역 살펴보기
20군데를 먼저 선정후 보급한다고 가정해보자.
처리율 오름차순으로 정리한 데이터 세트에서 상위 20군데만 추출하고
시각화하는 코드를 짠다.
오류 발생
#20구역 선정
data_s_sorted_20 = data_s_sorted.head(n=20)
import matplotlib.pyplot as plt
print(data_s_sorted_20)
data_s_sorted_20.plot(kind='bar', x=data_s_sorted_20['signgu_nm'], y=data_s_sorted_20['처리율'])

이미 호출한 함수를 한번 더 호출하여서 발생한 문제였다...
코드 수정
#20구역 선정
data_s_sorted_20 = data_s_sorted.head(n=20)
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'#한글 깨짐문제 해결
plt.rcParams['axes.unicode_minus'] =False
print(data_s_sorted_20)
data_s_sorted_20.plot.bar(x='signgu_nm',y='처리율')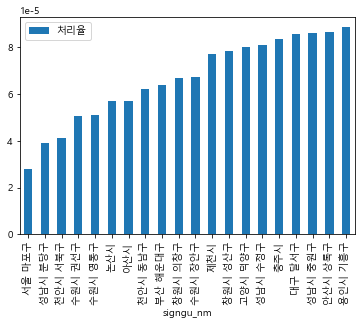
마치며
2종류의 데이터 프레임을 조사하고 병합하고 재분류 하면서 대한민국에 음식물 쓰레기 발생량 대비 처리장비 보급률이 가장 낮은곳은 서울 마포구였다.
어려웠던 점
같은곳에서 조사한 데이터가 아니다보니 지역명 표기 방식이 달라서 지역별로 쓰레기 발생량과 처리장비 보급현황을 매칭시키는 과정이 약간 어려웠고, 전반적인 데이터 처리 과정에서 코드를 잘 몰라 한참동안 구글링을 했다.
코드와 데이터셋
