
Hbase란?
HDFS으로 구현한 컬림 기반 분산 NoSQL '데이터저장소'로 여러 가지의 NoSQL중 Column-Family model에 속한다. 구글의 BigTable을 기반으로 설계되었으며, HDFS위에서 동작한다.
비정형/반정형 대량 데이터에 대한 분석 처리 지원에 적합하며, 강력한 일관성을 보장한다.
Hbase의 용도
이벤트 로깅, 대규모 sns서비스의 주 스토리지(페이스북 메시지 플랫폼, 라인 메시지 플랫폼)
Hbase의 특징
- NoSQL(Column Family)
NoSQL의 종류
- Key-value: Redis, Memcached, AWS DynamoDB
- Document: MongoDB, CouchDB
- Graph: Neo4J
- Column Family: Cassandra, Hbase
- HDFS/Map reduce 기반
- 자동 샤딩(region 분리)
- HDFS, mapreduce 기반으로 대량의 데이터 분석 처리 지원에 적합
Hbase의 구조
-
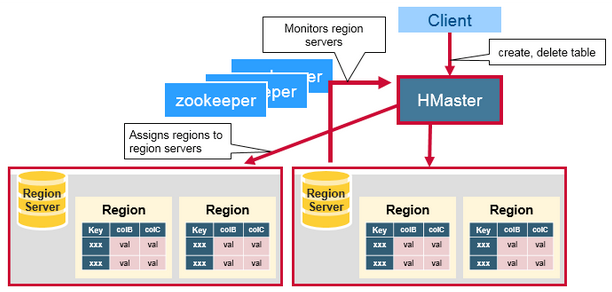
Master Server: RegionSever의 모니터링 및 정보 관리. 클라이언트의 읽기/쓰기 요청 처리. 리전 서버에 리전 할당.
-
Region Server: 수평 확장의 기본 단위. Region서버마다 n개의 Region을 가질 수 있으며, 하나의 Region은 일정 크기 이상 커지면 분리된다. 실제 데이터 저장을 담당하는 서버.
- Region: 정렬된 데이터를 저장한 큰 테이블을 정렬키 범위로 나눈 것. 자신이 속한 테이블, 첫번째 로우, 마지막 로우로 정의된다.
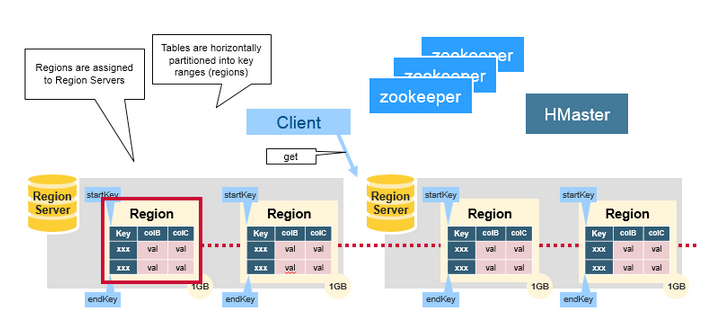
- Region: 정렬된 데이터를 저장한 큰 테이블을 정렬키 범위로 나눈 것. 자신이 속한 테이블, 첫번째 로우, 마지막 로우로 정의된다.
-
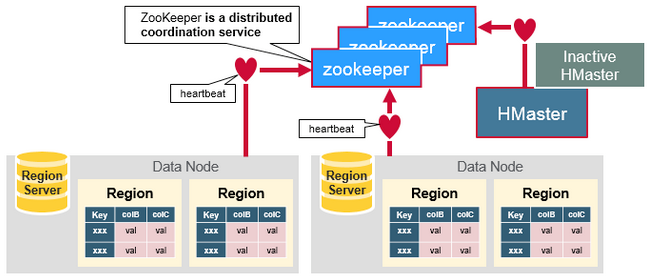
Zookeeper: 클러스터 코디네이터. 활성화된 region과 master서버들과 연결되어 하트비트를 통해서 각 서버의 상태를 관리한다. hbase:meta 카탈로그 테이블(리전 정보 메타 테이블) 위치 관리.
Hbase 데이터 모델
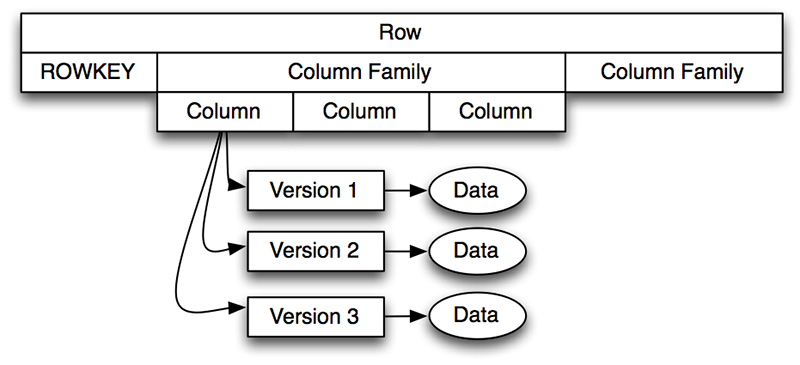
Table
Row
rowkey와 하나 이상의 컬럼으로 구성되어 있다. 정렬의 기준이 된다.
Column Family
성능 향상을 위해서 컬럼들을 물리적으로 같은 장소에 배치한 것이다.
Column
column family와 column qualifier로 구성되어 있다.
예시) employee:name
Column Qualifier
Cell
row, column-family, column qualifier의 조합.
내부적으로 값과 타임스탬프를 가지고 있다.
Timestamp
값의 버전을 위해 식별자로 활용한다. 기본적으로 데이터가 쓰여질 때 리전 서버 상의 시간을 기록한다.
Hbase 사용방법
- hbase shell
- Apache Phoenix
SQL을 통해서 Hbase 데이터에 접근하게 해주는 도구. JDBC API 사용. Join, 페이징, 여러 키워드(distinct 등) 활용 가능. - Java Client API
- Thrift/REST API
기본 명령어
- create '<테이블명>', '<CF명>', '<CF명>'
- put '<테이블명>', '', '<cf명:컬럼명>', '값'
- get '<테이블명>', ''
- delete
- scan
- drop '<테이블명>'
- list: 테이블 목록 조회
Hbase 읽기 흐름
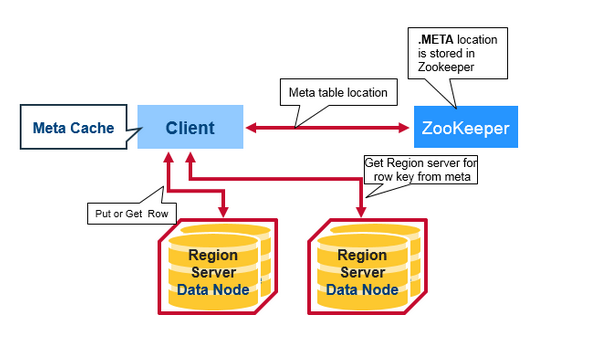
- Zookeeper에서 메타테이블의 위치 조회
1) root 테이블은 0.96 이상부터 삭제 - 메타테이블(hbase:meta)을 조회하여 찾고자 하는 region이 저장된 region server 조회
- 필요한 region을 가지고 있는 region server에 접근하여 데이터 조회.
Hbase 쓰기 흐름
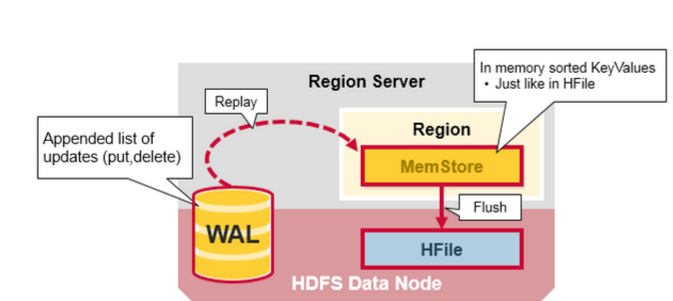
기본적으로 하나의 테이블은 하나의 리전에 저장된다. 리전이 너무 커지면, Hbase는 이 리전을 두 개의 child 리전으로 나눈다.
- WAL에 데이터 저장. RDB의 commit log와 유사한 개념.
- Zookeeper가 저장이 가능한 Region Server를 찾아서 WAL에 저장된 데이터를 memstore라고 하는 저장소(메모리)에 저장. 이때 클라이언트에 ack가 리턴된다. 하나의 column family에 하나의 memstore가 존재한다.
- Memstore에 저장된 데이터가 가득차게 되면 Zookeeper가 HFile이라고 하는 HDFS상의 파일에 memstore 데이터 flush. 하나의 column family에 하나의 Hfile이 존재한다.
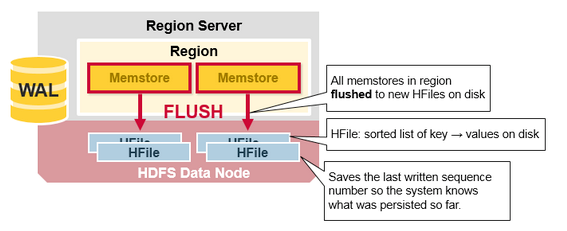
- Compaction
1) Minor Compaction: 여러 개의 HFile을 좀 더 큰 몇 개의 HFile로 압축.
2) Major Compaction: 모든 HFile들을 모아서 컬럼당 하나의 HFile로 만든다.
장애발생 시 복구
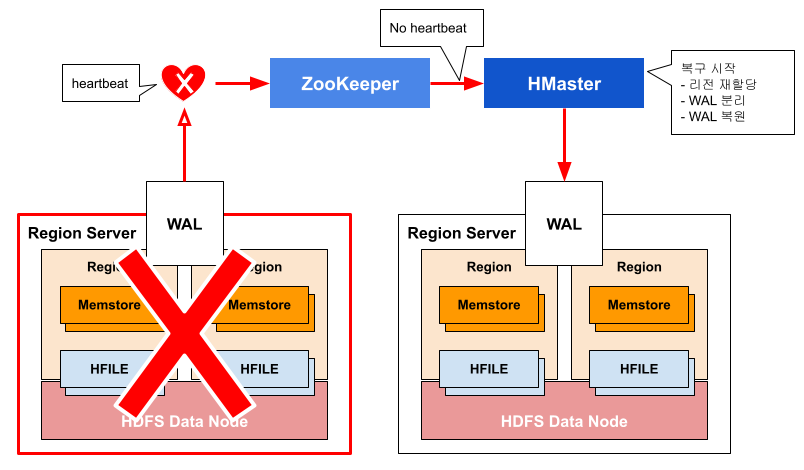
- HMaster가 Zookeeper를 통해서 장애를 감지하고, 장애서버의 Region을 다른 Region Server가 대체하여 서비스하도록 알린다.
- 알림을 받은 Region Server가 먼저 WAL을 읽어서 memstore를 복구한다.
- memstore복구가 완료되면 HMaster는 region의 위치정보를 저장하고 있는 meta region 정보를 수정하여 해당 region에 대한 서비스를 재개한다.
궁금한 점?
-
Hbase를 잘 사용하기 위해서 튜닝하는 방법
Read 성능을 증진 시키기 위해서는 HFile 수가 적을 수록 좋다. (즉, 한 개의 파일에 데이터가 많이 들어가 있을수록 좋다)
Write 성능을 증진시키려면 compaction을 적게 할 수록 좋다.
HFile은 compaction을 통해 합쳐서 파일의 수를 줄이게 된다. 따라서 이러한 구조를 이해하고 write 성능을 고려해야한다.
-
Kudu 대비 이점은?
Kudu: OLAP
Hbase: OLTP
대량의 비정형 또는 반정형 데이터를 처리할 수 있는 대기 시간이 짧고 처리량이 많은 데이터 저장소가 필요한 경우 Hbase를 고려할 수 있다.
실 사용예시)
실시간 데이터 처리: HBase는 랜덤 읽기 및 쓰기 작업에 최적화되어 있어 실시간 분석 또는 로그 처리 애플리케이션과 같이 데이터에 빠르게 액세스하고 업데이트해야 하는 사용 사례에 적합합니다.대규모 데이터: HBase는 매우 많은 양의 데이터를 처리할 수 있는 분산된 칼럼 패밀리 스토어이므로 소셜 미디어 또는 IoT 애플리케이션과 같이 많은 양의 비정형 또는 반정형 데이터를 저장하고 처리해야 하는 사용 사례에 적합합니다.
희소 데이터 처리: HBase는 희소 데이터를 처리하도록 설계되었으므로 테이블의 많은 셀이 비어 있는 경우에도 데이터를 효율적으로 저장하고 검색할 수 있습니다. 따라서 유전체학이나 재무와 같이 데이터가 균일하게 분포되지 않은 사용 사례에 적합합니다.
시계열 데이터: HBase는 타임스탬프를 기반으로 데이터를 저장 및 검색할 수 있으므로 시계열 데이터 분석 또는 모니터링과 같이 시간에 따라 데이터를 저장 및 검색해야 하는 사용 사례에 적합합니다.
-
WAL -> memstore -> HFile 순으로 write하는 이유?
1) HFile에 매번 변경사항을 바로 쓰면 I/O가 많아져 성능이 떨어지고, 파일 개수가 많아져서 효율적이지 않다.
2) memstore는 메모리 영역이기 때문에 데이터 손실위험이 있음. 그래서 recovery를 위해서 WAL이 존재.
