- 표 형식의 자료구조
- 열(col)은 각기 다른 종류의 data
- row, column 각각 index를 가짐
- dataframe 생성 (값 다 지정)
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data)
frame state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
- index와 열(col) 명칭 지정
frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five'])
frame2 year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
- 전체 열(col) 이름 출력
frame2.columns Index(['year', 'state', 'pop', 'debt'], dtype='object')
- 특정 열 data 출력
frame2.yearone 2000
two 2001
three 2002
four 2001
five 2002
- 전체 행(index) 이름 출력
frame2.index- 특정 행(index) data 출력
frame2.loc['three'] #열 이름year 2002
state Ohio
pop 3.6
debt NaN
- 특정 열(col) 전체 행(index)에 값(scalar) 대입
동일한 값 대입
frame2['debt'] = 16.5
frame2 year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
0부터 4까지 대입
frame2['debt'] = np.arange(5.)
frame2 year state pop debt
one 2000 Ohio 1.5 0.0
two 2001 Ohio 1.7 1.0
three 2002 Ohio 3.6 2.0
four 2001 Nevada 2.4 3.0
five 2002 Nevada 2.9 4.0
- 특정 열(col)에 Series 대입
val = Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five']) #나머지 index는 NaN
frame2['debt'] = val
frame2 year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
- 새로운 열(col) 대입 : 어떤 값이 있는 행(index)만 True 삽입
frame2['eastern'] = frame2.state == 'Ohio'
frame2 year state pop debt eastern
one 2000 Ohio 1.5 NaN True
two 2001 Ohio 1.7 -1.2 True
three 2002 Ohio 3.6 NaN True
four 2001 Nevada 2.4 -1.5 False
five 2002 Nevada 2.9 -1.7 False
- del 함수 : 특정 열(col)만 삭제
del frame2['eastern'] #'eastern' 열 통채로 삭제- drop() : 특정 행(index) or 열(col) 삭제
frame3 = frame2.drop('five') #'five' index 통채로 삭제frame4 = frame2.drop('debt', axis=1) #axis = 1 : 열을 삭제 ('debt' 열 삭제)- 특정 column, row 삭제
- drop 함수
- 행(col) 삭제 : axis=1 or axis='columns'
data = DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.drop(['Colorado', 'Ohio']) #index(행) 삭제
data.drop('two', axis=1) #col(열) 삭제. axis=1
data.drop(['two', 'four'], axis='columns') # #col(열) 삭제. axis='columns'- 이중 dictionary를 이용한 DataFrame 생성
바깥쪽 dictionary key : 열 index / 안쪽 dictionary key : 행 index
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = DataFrame(pop)
frame3 Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5
- 열과 행을 뒤바꿈.
frame3.T- 다른 frame의 data를 가져와서 새 frame에 재배치
pdata = {'Ohio': frame3['Ohio'][:-1], #처음 index 값부터 마지막 전 index 값까지
'Nevada': frame3['Nevada'][:2]} #'Ohio', 'Nevada'는 열
DataFrame(pdata) Ohio Nevada
2001 1.7 2.4
2002 3.6 2.9
- dataframe의 index와 col에 전체 name 지정
frame3.index.name = 'year'
frame3.columns.name = 'state'
frame3- dataframe의 data 출력
frame3.values- 재색인(reindexing)
- 데이터를 새로운 index에 맞게 row, colummn 재배열
- 없는 index는 NaN 혹은 fill_value option
# 기존 frame (값은 1부터 8까지 순서대로 채워라.)
frame = DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'],
columns=['Ohio', 'Texas', 'California']) Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
frame2 = frame.reindex(['a', 'b', 'c', 'd']) #으로 reindexing (b는 NaN) Ohio Texas California
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
- col(열) reindexing
states = ['Texas', 'Utah', 'California']
frame.reindex(columns=states) Texas Utah California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8
- NaN 부분을 기존 값으로 랜덤하게 채움.
frame.reindex(index=['a', 'b', 'c', 'd']).ffill() #index b의 값을 랜덤으로 채움.- 다른 데이터프레임의 열을 사용. NaN 부분을 0으로 채움.
# 재색인시에도 fill_value 지정할 수 있음.
df1.reindex(columns=df2.columns, fill_value=0)- Indexing - 특정 데이터(행, 렬) 출력
data = DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
# col(열) 값 하나 선택
#'two' 열의 데이터 출력
data['two']Ohio 1
Colorado 5
Utah 9
New York 13
#['three', 'one'] 열의 데이터 출력
data[['three', 'one']]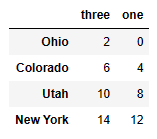
- Slicing - 특정 데이터(행, 렬) 출력
# 행 0번째, 1번째
data[:2]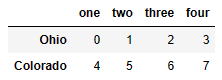
data[data['three'] > 5] #'three' 열의 값이 5 이상인 것만 출력
data[data < 5] = 0 #값이 5보다 작은 건 0으로- ioc and iloc - 특정 데이터(행, 렬) 출력
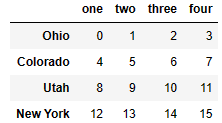
data.loc['Colorado', ['two', 'three']] #'Colorado' 행의 ['two', 'three'] 열 출력two 5
three 6
data.iloc[2, [3, 0, 1]] #'Utah'(2번째) 행에서 [3, 0, 1]번째 열 데이터 four 11
one 8
two 9
data.iloc[2] #2번째 행 데이터one 8
two 9
three 10
four 11
data.iloc[[1,2], [3,0,1]] #[1, 2]번째 행에서 [3, 0, 1]번째 열 데이터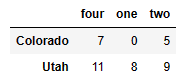
- ser.loc[:1] # 1번째 row까지 선택
- ser.iloc[:1] # 1번째 row 전까지 선택
data.loc[:'Utah', 'two'] #'Utah'행까지 'two'열 데이터Ohio 0
Colorado 5
Utah 9
data.iloc[:,:3][data.three > 5]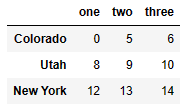
- 두 DataFrame의 산술 연산
- DataFrame에서는 row, column 모두 union됨
- 공통된 row나 column이 없으면 모두 통합(NaN 값)
df1 = DataFrame(np.arange(9.).reshape((3, 3)), columns=list('bcd'),
index=['Ohio', 'Texas', 'Colorado'])
df2 = DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
df1 df2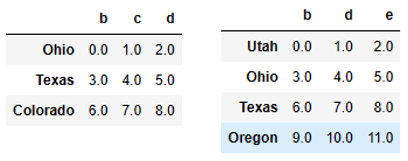
df1 + df2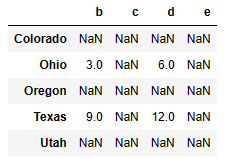
df1.add(df2, fill_value=0) #NaN 자리 애들이 0으로 채워짐.df1.rdiv(1) # reverse div- 연산 between DataFrame and Series
frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])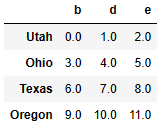
series = frame.iloc[0] #frame의 0번째 행 데이터
seriesb 0.0
d 1.0
e 2.0
frame - series
# frame.sub(series, axis=0) #axis = 0은 열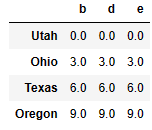
- 여러 function 적용 (절댓값/최대-최소)
- applymap: DataFrame에 함수 적용
- map: Series에 함수 적용
np.abs(frame) #절댓값f = lambda x: x.max() - x.min() # 최대 - 최소
frame.apply(f) #col에 적용
frame.apply(f, axis=1) #row에 적용def f(x):
return Series([x.min(), x.max()], index=['min', 'max'])
frame.apply(f)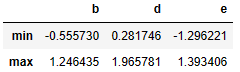
format = lambda x: '%.2f' % x
frame.applymap(format)
frame['e'].map(format) #series로 바꿔서 적용- Sorting
- sort_index() : row(axis=0), column(axis=1)의 index를 알파벳순으로 정렬하고 새로운 객체를 반환
- 내림차순 : ascending = False 옵션
- sort_values() : value를 기준으로 sort
- NaN은 value의 마지막으로 정렬됨
frame = DataFrame(np.arange(8).reshape((2, 4)), index=['three', 'one'],
columns=['d', 'a', 'b', 'c'])
frame.sort_index() #행(index)를 one, three로 정렬
frame.sort_index(axis=1) #열(col)을 a, b, c, d로 정렬
frame.sort_index(axis=1, ascending=False) #열(col)을 d, c, b, a로 정렬frame = DataFrame({'b': [4, 7, -3, 2], 'a': [0, 1, 0, 1]})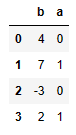
frame.sort_values(by='b') #'b' 열 값이 오름차순으로 정렬
frame.sort_values(by=['a', 'b']) #'a', 'b' 열 값이 오름차순으로 정렬- Ranking
- 1부터 배열의 유효한 데이터 개수까지의 순위를 매김.
- rank(): 오름차순으로 순위를 매김. 동점인 항목에 대해서는 평균 순위를 매김
frame = DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1],
'c': [-2, 5, 8, -2.5]})
frame.rank(axis=1)- 열(col)의 합계
df.sum()- 행의 합계
# 행의 합계: axis='columns' 혹은 axis=1
df.sum(axis=1)- 행의 평균값
# NaN 값이 있으면 skip (NaN이 하나라도 있으면 거기는 NaN)
df.mean(axis=1, skipna=False)- max값을 가진 index value 반환
df.idxmax()- 누적 합계
df.cumsum()- 여러 통계치를 요약
df.describe()