08. 문자열 검색
08-1. 문자열의 기본
문자열이란?
문자열(string): 프로그램에서 문자의 '나열'을 나타내는 것
문자열 리터럴
문자열 리터럴(string literal): 문자의 나열을 2개의 큰따옴표("")로 묶은 것 - C언어
- 문자열 안의 문자는 메모리 공간에 연속으로 배치됨
- 컴퓨터는 문자열 리터럴의 끝을 나타내기 위해 null 문자를 자동으로 추가함(비트값 0)
/* 문자열 안의 문자를 16진수와 2진수로 출력합니다. */
#include <stdio.h>
#include <limits.h>
/*--- 문자열 안의 문자를 16진수와 2진수로 출력 ---*/
void str_dump(const char *s)
{
do {
int i;
printf("%c %0*X ", *s, (CHAR_BIT + 3) / 4, *s);
for (i = CHAR_BIT - 1; i >= 0; i--)
putchar(((*s >> i) & 1U) ? '1' : '0');
putchar('\n');
} while (*s++ != '\0');
}
int main(void)
{
str_dump("STRING");
return 0;
}보충수업_문자열 리터럴
- 문자열 리터럴의 자료형
문자열 리터럴의 자료형은 char형 배열
문자열 리터럴의 표현식을 평가하여 얻는 자료형은 char*형,
그 값은 첫번째 문자에 대한 포인터
ex) "STRING"을 평가하면 첫 번째 글자인 'S'에 대한 포인터를 얻음 - 문자열 리터럴의 메모리 영역 기간
문자열 리터럴의 메모리 영역 기간 = 정적 메모리 영역의 기간
프로그램의 시작부터 끝까지 메모리 영역이 유지됨 - 같은 문자열 리터럴이 여러 개 있는 경우 컴퓨터에서 처리하는 방법
1) 각각 다른 메모리 영역에 넣어 두는 컴퓨터 환경
2) 같은 영역에 넣어두고 공유하는 컴퓨터 환경 - 상수의 성질을 갖는 문자열 리터럴
문자열 리터를은 변수가 아니라 상수의 성질을 가짐
즉, 문자열 리터럴이 저장된 메모리 영역에 값을 대입할 수 없음
배열에 문자열 저장하기
- 문자열 리터럴은 내용을 자유롭게 바꿀 수 없음
- 문자열 값을 char형 배열에 저장하면 자유롭게 값을 꺼내고 쓸 수 있음
/* 저장한 문자열을 출력합니다. */
#include <stdio.h>
int main(void)
{
char st[10];
st[0] = 'A';
st[1] = 'B';
st[2] = 'C';
st[3] = 'D';
st[4] = '\0';
printf("문자열 st에는 \"%s\"가 들어있습니다.\n", st);
return 0;
}문자열 초기화
문자열을 선언하면서 동시에 초기화할 수 있음
/* 방법 1 */
char st[10] = { 'A', 'B', 'C', 'D', '\0'}
/* 방법 2 */
char st[10] = "ABCD";요소의 개수를 생략하고 문자열을 선언하면 초기화할 때 입력한 문자열의 요소 개수가 배열의 요소 개수가 됨
char st[] = "ABCD" /* 배열 st의 요소 개수는 5개 */포인터와 문자열
/* 문자열 출력(포인터 사용) */
#include <stdio.h>
int main(void)
{
char *pt = "12345";
printf("포인터 pt는 \"%s\"를(을) 가리킵니다.\n", pt);
return 0;
}
문자열 리터럴을 평가하여 얻는 값은 그 문자열 리터럴의 첫 번째 문자에 대한 포인터
pt는 "12345"가 들어 있는 메모리 영역의 첫 번째 문자 '1'을 가리키며 초기화
char st[] = "12345"; /* 배열에 의한 문자열의 크기는 6바이트 */
char *pt = "12345"; /* 포인터에 의한 문자열의 크기는 sizeof(char*) + 6바이트 */포인터로 표현한 문자열은 배열에 저장한 문자열보다 더 많은 메모리 영역을 차지함
/* 두 포인터 값을 서로 바꾸는 함수가 있는 프로그램 */
#include <stdio.h>
/*--- 두 포인터를 서로 바꾸는 함수 ---*/
void swap_ptr(char **x, char **y)
{
char *tmp = *x;
*x = *y;
*y = tmp;
}
int main(void)
{
char *s1 = "ABCD"; /* s1은 "ABCD"의 첫 글자 'A'를 가리킵니다. */
char *s2 = "EFGH"; /* s2는 "EFGH"의 첫 글자 'E'를 가리킵니다. */
printf("포인터 s1은 \"%s\"를 가리킵니다.\n", s1);
printf("포인터 s2는 \"%s\"를 가리킵니다.\n", s2);
swap_ptr(&s1, &s2);
puts("\n포인터 s1과 s2의 값을 서로 바꾸었습니다.\n");
printf("포인터 s1은 \"%s\"를 가리킵니다.\n", s1);
printf("포인터 s2는 \"%s\"를 가리킵니다.\n", s2);
return 0;
}문자열 리터럴을 가리키는 두 포인터의 값을 서로 교환하는 프로그램

문자열의 길이
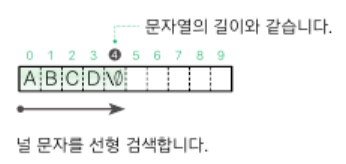
컴퓨터는 배열에 저장된 문자열의 경우 null 문자까지 문자열로 인식함
즉, 배열에 들어 있는 요소의 개수가 항상 문자열의 길이를 의미하는 것은 아님
/* 문자열 길이를 구하는 프로그램 */
#include <stdio.h>
/*--- 문자열 s의 길이를 구하는 함수(버전 1) ---*/
int str_len(const char *s)
{
int len = 0;
while (s[len])
len++;
return len;
}
int main(void)
{
char str[256];
printf("문자열 : ");
scanf("%s", str);
printf("이 문자열의 길이는 %d입니다.\n", str_len(str));
return 0;
}문자열의 길이를 구하기 위해서는 문자열의 첫 문자부터 null 문자까지 선형 검색
* 문자열의 길이는 null 문자를 제외한 문자의 개수를 의미함
보초법에 의한 선형 검색: 검색에 실패할 가능성을 고려할 필요가 없는 알고리즘
- 문자열의 끝에는 반드시 null 문자가 있으므로 검색에 실패하는 경우가 없음
/*--- 문자열 s의 길이를 구합니다.(버전 2) ---*/
int str_len(const char * s)
{
int len = 0;
while (*s++)
len++;
return len;
}
/*--- 문자열 s의 길이를 구합니다.(버전 3) ---*/
int str_len(const char * s)
{
const char * p = s;
while (*s)
s++;
return s - p;
}
문자열에서 문자 검색하기
/* 문자열에서 문자 검색하는 프로그램 */
#include <stdio.h>
/*--- 문자열 s에서 문자 c를 검색하는 함수 ---*/
int str_chr(const char *s, int c)
{
int i = 0;
c = (char)c;
while (s[i] != c) {
if (s[i] == '\0') /* 검색 실패 */
return -1;
i++;
}
return i; /* 검색 성공 */
}
int main(void)
{
char str[64]; /* 이 문자열에서 검색*/
char tmp[64];
int ch; /* 검색할 문자 */
int idx;
printf("문자열 : ");
scanf("%s", str);
printf("검색할 문자 : ");
scanf("%s", tmp); /* 먼저 문자열로 검색할 문자를 읽어 들입니다. */
ch = tmp[0]; /* 첫 번째 문자를 검색할 문자로 지정합니다. */
if ((idx = str_chr(str, ch)) == -1) /* 처음 나오는 문자를 검색합니다. */
printf("문자 '%c'는 문자열에 없습니다.\n", ch);
else
printf("문자 '%c'는(은) %d 번째에 있습니다.\n", ch, idx + 1);
return 0;
}
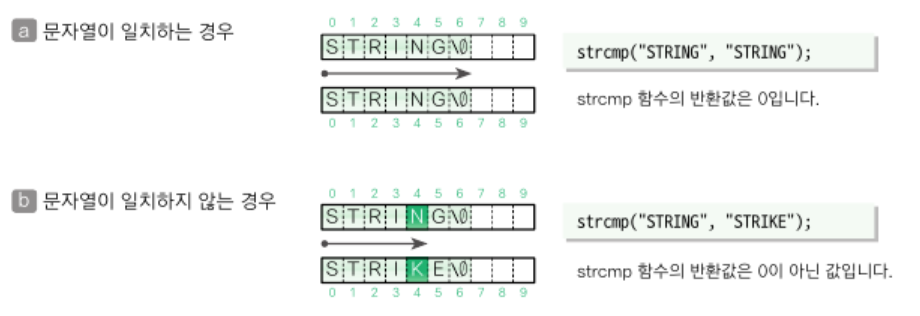
문자열 비교
strcmp 함수
두 문자열을 처음부터 순서대로 비교함
/* 문자열을 비교하는 프로그램 */
#include <stdio.h>
/*--- 두 문자열 s1과 s2를 비교하는 함수 ---*/
int str_cmp(const char *s1, const char *s2)
{
while (*s1 == *s2) {
if (*s1 == '\0') /* 같음 */
return 0;
s1++;
s2++;
}
return (unsigned char)*s1 - (unsigned char)*s2;
}
int main(void)
{
char st[128];
puts("\"ABCD\"와 비교합니다.");
puts("\"XXXX\"면 마칩니다.");
while (1) {
printf("문자열 st : ");
scanf("%s", st);
if (str_cmp("XXXX", st) == 0)
break;
printf("str_cmp(\"ABCD\", st) = %d\n", str_cmp("ABCD", st));
}
return 0;
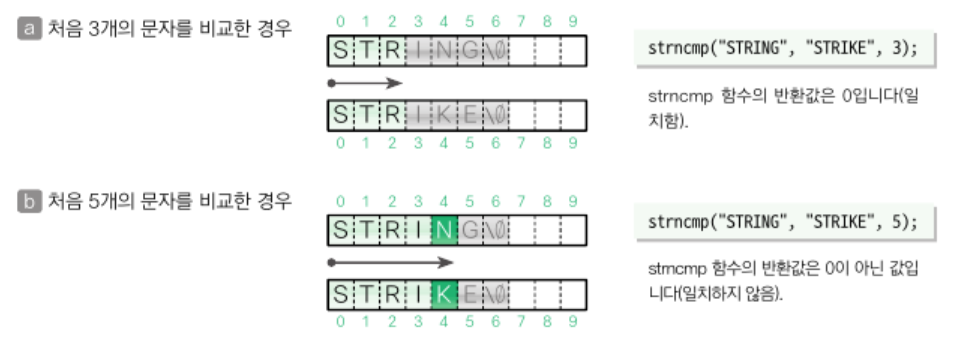
}strncmp 함수
3번째 인수로 지정한 문자열의 길이만큼만 비교함
null 문자가 없는 '문자 배열' 간의 비교도 가능함
/* 문자열 비교하는 프로그램 (strncmp 함수 사용) */
#include <stdio.h>
#include <string.h>
int main(void)
{
char st[128];
puts("\"STRING\"의 처음 3개의 문자와 비교합니다.");
puts("\"XXXX\"를 입력하면 마칩니다.");
while (1) {
printf("문자열 st : ");
scanf("%s", st);
if (strncmp("XXXX", st, 3) == 0)
break;
printf("strncmp(\"STRING\", st, 3) = %d\n", strncmp("STRING", st, 3));
}
return 0;
}08-2. 브루트-포스법
문자열에서 문자열을 검색하는 알고리즘
문자열 검색이란?
어떤 문자열 안에 다른 문자열이 들어 있는지 조사하고, 들어 있다면 그 위치를 찾아내는 것
브루트-포스법
선형 검색을 확장한 알고리즘
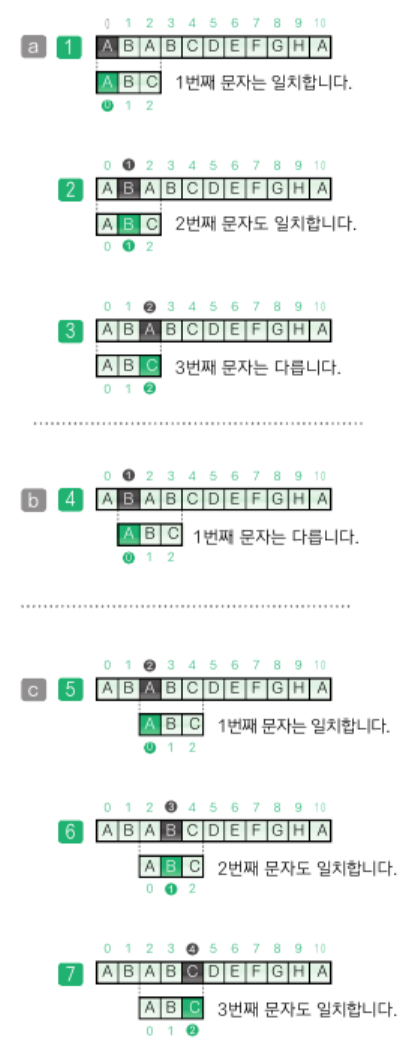
이미 검사를 진행한 위치를 기억하지 못하므로 효율이 좋지 않음
/* 브루트-포스법으로 문자열을 검색하는 프로그램 */
#include <stdio.h>
/*--- 브루트-포스법으로 문자열을 검색하는 함수 ---*/
int bf_match(const char txt[], const char pat[])
{
int pt = 0; /* 텍스트 커서 */
int pp = 0; /* 패턴 커서 */
while (txt[pt] != '\0' && pat[pp] != '\0') {
if(txt[pt] == pat[pp]){
pt++;
pp++;
}
else {
pt = pt - pp + 1;
pp = 0;
}
}
if (pat[pp] == '\0')
return pt - pp;
return -1;
}
int main(void)
{
int idx;
char s1[256]; /* 텍스트 */
char s2[256]; /* 패턴 */
puts("브루트-포스법");
printf("텍스트 : ");
scanf("%s", s1);
printf("패턴 : ");
scanf("%s", s2);
/* 텍스트(s1)에서 패턴(s2)을 브루트-포스법으로 검색합니다. */
idx = bf_match(s1, s2);
if (idx == -1)
puts("텍스트에 패턴이 없습니다.");
else
printf("%d번째 문자부터 match합니다.\n", idx + 1);
return 0;
}08-3. KMP법
브루트-포스법
다른 문자를 만나면 패턴에서 문자를 검사했던 위치 결과를 버리고 다음 텍스트의 위치로 1칸 이동한 다음 다시 패턴의 첫 번째 문자부터 검사
처음에 찾았던 패턴의 시작부터 다시 검사하기 때문에 비효율적
KMP법
검사했던 위치 결과를 버리지 않고 이를 효율적으로 활용하는 알고리즘
텍스트와 패턴의 겹치는 부분을 찾아내어 검사를 다시 시작할 위치를 구하는 방법으로 패턴을 최소의 횟수로 옮겨 알고리즘의 효율을 높임

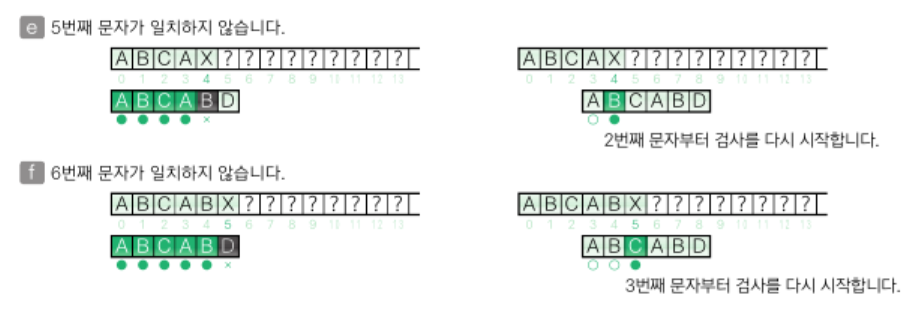
'몇 번째 문자부터 다시 검색할지'에 대한 값을 미리 '표'로 만들어 효율을 높임
- 패턴 안에서 중복되는 문자의 나열을 찾기 위해 KMP법 사용


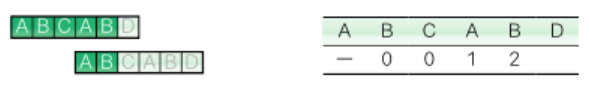

#include <stdio.h>
/*--- kmp법으로 문자열을 검색하는 프로그램 ---*/
int kmp_match(const char txt[], const char pat[])
{
int pt = 1; /* txt 커서 */
int pp = 0; /* pat 커서 */
int skip[1024];
/* 표 만들기 */
skip[pt] = 0;
while (pat[pt] != '\0') {
if (pat[pt] == pat[pp])
skip[++pt] = ++pp;
else if (pp == 0)
skip[++pt] = pp;
else
pp = skip[pp];
}
/* 검색 */
pt = pp = 0;
while (txt[pt] != '\0' && pat[pp] != '\0') {
if (txt[pt] == pat[pp]) {
pt++; pp++;
}
else if (pp == 0)
pt++;
else
pp = skip[pp];
}
if (pat[pp] == '\0')
return pt - pp;
return -1;
}KMP법에서 텍스트를 스캔하는 커서 pt는 다시 뒤로 돌아오지 않음
KMP법은 브루트-포스법보다 복잡하고, Boyer-Moore법과는 성능이 같거나 좋지 않아 사용 x
08-4. Boyer-Moore법
브루트-포스법을 개선한 KMP법보다 효율이 더 우수함
Boyer-Moore법
패턴의 마지막 문자부터 앞쪽으로 검사를 진행하면서 일치하지 않는 문자가 있으면 미리 준비한 표에 따라 패턴을 옮길 크기를 정해 KMP법보다 효율이 더 좋음
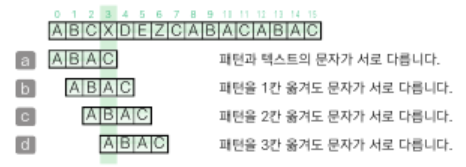

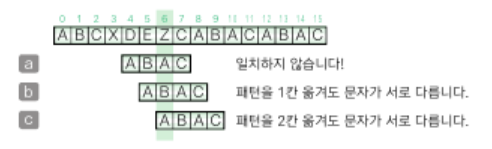
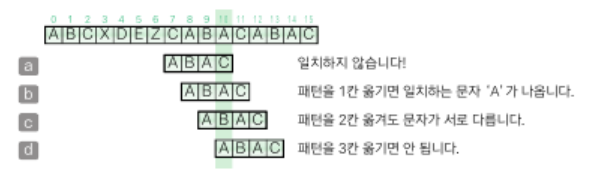
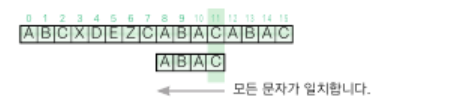
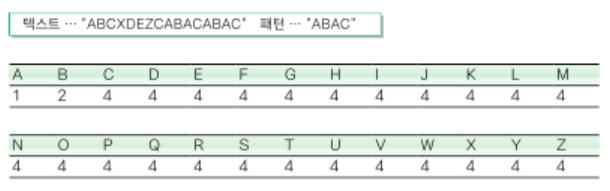
각각의 문자를 만났을 때 패턴을 옮길 크기를 저장할 표를 미리 만들어야 함
- 패턴에 들어 있지 않은 문자를 만난 경우
패턴을 옮길 크기는 n
ex) 첫 번째 그림에서 'X'는 패턴에 들어 있지 않으므로 4만큼 옮김 - 패턴에 들어 있는 문자를 만난 경우
a. 마지막에 나오는 위치의 인덱스가 k이면 패턴을 옮길 크기는 n-k-k
ex) 네 번째 그림에서 'A'는 패턴의 두 곳에 들어 있지만 마지막 인덱스를 기준으로 하여 패턴을 1만큼(4-2-1) 옮김
b. 같은 문자가 패턴 안에 중복해서 들어 있지 않다면 패턴을 옮길 크기는 n
/* Boyer-Moore법을 구현한 프로그램 */
#include <stdio.h>
#include <string.h>
#include <limits.h>
/*--- Boyer-Moore 함수 ---*/
int bm_match(const char txt[], const char pat[])
{
int pt; /* txt 커서 */
int pp; /* pat 커서 */
int txt_len = strlen(txt); /* txt 문자 개수 */
int pat_len = strlen(pat); /* pat 문자 개수 */
int skip[UCHAR_MAX + 1]; /* 건너뛰기 표 */
for (pt = 0; pt <= UCHAR_MAX; pt++) /* 건너뛰기 표 만들기 */
skip[pt] = pat_len;
for (pt = 0; pt < pat_len - 1; pt++)
skip[pat[pt]] = pat_len - pt - 1; /* pt == pat_len - 1 */
while (pt < txt_len) {
pp = pat_len - 1; /* pat의 마지막 문자부터 검사합니다. */
while (txt[pt] == pat[pp]) {
if (pp == 0)
return pt;
pp--;
pt--;
}
pt += (skip[txt[pt]] > pat_len - pp) ? skip[txt[pt]] : pat_len - pp;
}
return -1;
}
int main(void)
{
int idx;
char s1[256]; /* 텍스트 */
char s2[256]; /* 패턴 */
puts("Boyer-Moore법");
printf("텍스트 : ");
scanf("%s", s1);
printf("패턴 : ");
scanf("%s", s2);
idx = bm_match(s1, s2); /* 문자열 s1에서 문자열 s2를 Boyer-Moore법을 사용해 검색합니다. */
if (idx == -1)
puts("텍스트에 패턴이 없습니다.");
else
printf("%d번째 문자부터 match합니다.\n", idx + 1);
return 0;
}보충수업_문자열 검색 알고리즘의 시간 복잡도와 실용성
텍스트의 문자 개수가 n이고 패턴의 문자 개수가 m이라고 할 때,
브루트-포스법
시간 복잡도 O(mn), 일부러 꾸민 패턴이 아니라면 시간복잡도는 O(n)
단순한 알고리즘이지만 실제는 아주 빠르게 동작함
KMP법
시간 복잡도는 최악의 경우에도 O(n)
처리가 복잡하고 패턴 안에 반복이 없으면 효율이 좋지 않음
검색 과정에서 검사하는 위치를 앞으로 되돌릴 필요가 없다는 특징이 있어 순서 파일을 읽어 들이며 검색할 때 많이 활용
Boyer-Moore법
시간 복잡도는 최악의 경우에도 O(n), 평균적으로 O(n/m)
2개의 배열을 사용하면 KMP법과 마찬가지로 배열을 만드는 데 복잡한 처리가 필요하므로 효과가 떨어짐
1개의 배열을 사용하는 방법으로 간단하게 구현하면 충분히 빠름
가장 실용적인 문자열 검색 알고리즘은 Boyer-Moore법, 경우에 따라 브루트-포스법 사용
/* strstr 함수를 사용한 프로그램 */
#include <stdio.h>
#include <string.h>
int main(void)
{
char s1[256], s2[256];
char *p;
puts("strstr 함수");
printf("텍스트 : ");
scanf("%s", s1);
printf("패턴 : ");
scanf("%s", s2);
p = strstr(s1, s2); /* 문자열 s1에서 문자열 s2를 검색 */
if (p == NULL)
printf("텍스트에 패턴이 없습니다.\n");
else {
int ofs = p - s1;
printf("\n%s\n", s1);
printf("%*s|\n", ofs, "");
printf("%*s%s\n", ofs, "", s2);
}
return 0;
}