Time Series Encodings with Temporal Convolutional Networks
Motivation: Anomaly Detection in Time Series
Anomaly란?
-표준적이고, 일반적이고, 기대되는 값에서 벗어나는 event
-Context-based/Temporal Anomaly: 현재의 시간적 맥락에서 비정상적인 값
-Concept Change: 특정 (타겟) 변수들의 통계적 특성이 시간에 따라 변화함
Anomaly Detection Algorithms : 이상치 탐지 알고리즘
-사기 탐지, 이커머스, 산업공정, 네트워크 모니터링
-예측 유지보수, 결함 탐지
-심전도 판독
우리 눈에는 보이지 않는 이상치 존재 -> 알고리즘이 시계열 전체 구조를 학습하고 특이값을 식별
Novel Temporal Convolution Autoencoder (TCN-AE)
-TNCs에 기반한 시계열 AutoEncoder
-시계열 응용: Representation Learning, Anomaly Detection
Mackey-Glass Anomaly Benchmark (MGAB)
-chaotic Mackey-Glass 시계열에 기반한 Synthetic benchmark
-잘 정의되었지만 다소 발견하기 어려운 이상치들
-맞춤형 benchmark를 생성하기 위해 조정 가능한 parameters
General Idea of TCN-AE Architecture
- sequence of length T를 아주 짧은 sequence of T/K에 인코딩
- 압축된 sequence로 부터 원본 sequence를 디코딩(reconstruct)
=> 디코더의 reconstruction error는 anomalous behavior의 지표 -> 고전적인 autoencoder의 방식과 유사
=> 차이점: Dilated convolutional layer를 사용 (입력 크기가 유연하고 더 큰 receptive field)
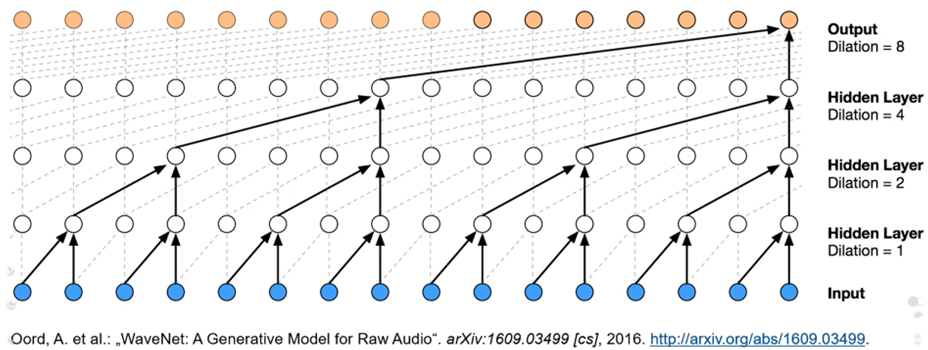
Dilated Convolutions
input signals are skipped between to filter tabs
wavenet paper
첫번째 layer : 확장률 1
-> 길이 2인 필터 사용
-> 두번째 layer : 확장률 2
-> 세번째 layer: 확장률 4
-> 네번째 layer: 확장률 8
=> dilation rate 증가하면서 큰 receptive field를 가지는 architecture 만들 수 있음
Temporal Convolutional Networks(TCNs)
TCN: Dilated Convolutions + Residual Connections + Weight Norm. + Dropout
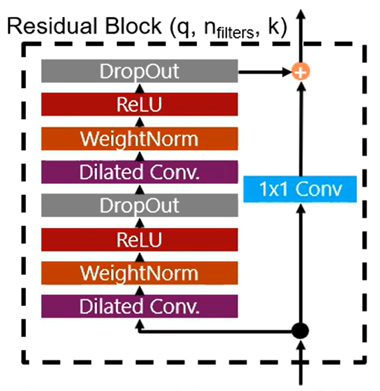
TCN architecture를 생성하기 위해 Residual Block을 쌓는다
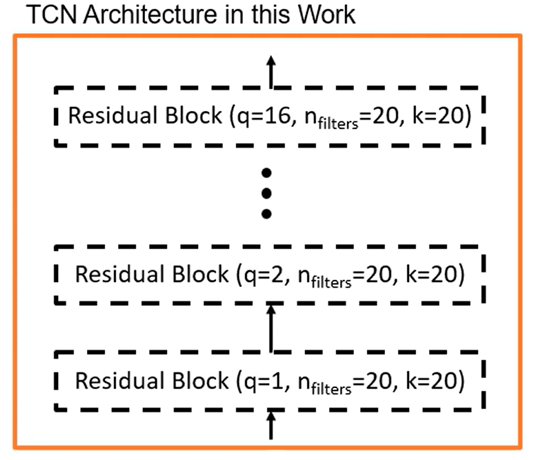
(q: dilation rate, n: filters, k: kernel size)
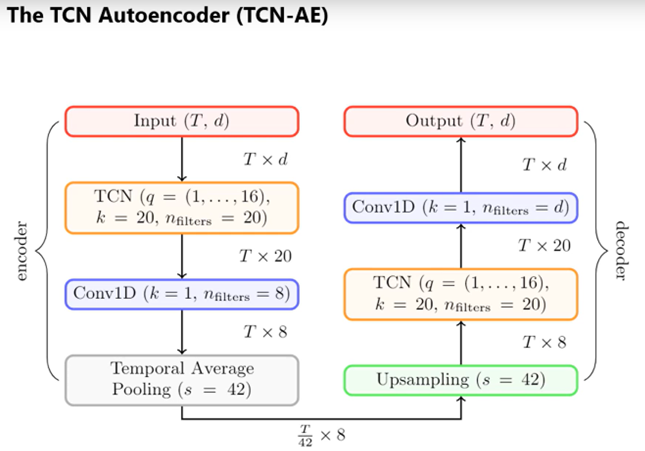
autoencoder 모델 만들기 위해 TCN 사용
autoencoder에 길이 T, 차원 d의 input
=> 1~16의 dilation rate 가지는 tcn 통과
=> 기본적으로 5개의 residual block
=> resulting signal은 d개의 layer를 가진 convolution으로 구성되는 bottleneck을 통해 통과(sequence의 차원 감소시키는 역할)
=> temporal average pooling layer : 시간에 따라 signal을 down sampling.
=> encoder의 output은 42배로 down sampled된 차원이 8인 signal.
=> decoder에서 이 sequence가 다시 upsampling[nearest neighbor interpolation]
=> TCN 통과해 CONV 1D LAYER로 전달
=> 길이 T, 차원 d인 output
Anomaly detection 위해 Reconstruction 과정 거치고 원본 signal과 비교
시계열 데이터의 anomalous behavior를 찾기 위해 reconstruction error 이용
Mackey-Glass Equation
-비선형 시간 지연 미분 방정식(non-linear time delay differential equation; DDE)
-chaotic, periodic dynamics의 다양한 패턴을 develop
-chaos를 시각화하기 위해 time delay 임베딩
-Maximum Lyapunov Exponent: λ_mle > 0 -> chaotic behavior을 의미
-Time series 생성 위해 파이썬에서는 JiTCDDE 패키지와 통합
Anomaly Insertion Process
-
충분히 긴 MG 시계열 x(t) 생성
-
처음 3가지의 도함수 계산
-
무작위로 시간 t_i 선택
-
t_m 찾기
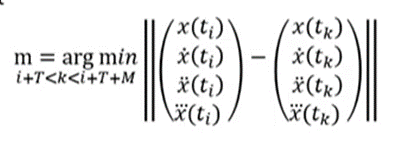
-
시계열을 두 지점으로 분리하고(t_i와 t_m 사이의 segment 제거) 시계열의 두 끝을 다시 붙임
-
이상치가 삽입될 때까지 3~ 과정 반복
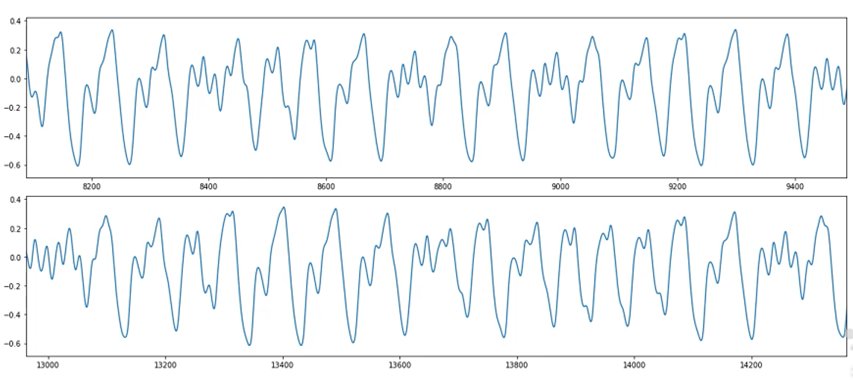
파란색 곡선: 원본 시계열
주황색 곡선: anomaly를 포함하는 조정된 곡선
=> 육안으로 anomaly 찾기 어려움
TCN-AE: Learning Time Series Representations
-시계열의 표현을 학습하기 위한 TCN-AE architecture의 능력을 평가
-TCN-AE 모델 학습: 다양한 시간 지연 parameter τ로 MG 시계열 사용
-10^5의 다양한 Mackey-Glass 시계열 (τ=11~20의 범위에서 각 τ 당 10^4)
-256 길이의 각 시계열은 2차원의 압축된 표현으로 인코딩
-> 압축률: 128
결과
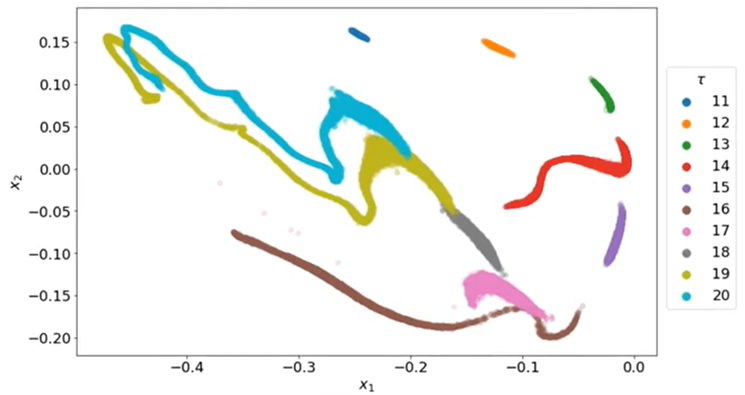
=>τ 증가함에 따라 클러스터도 확장됨
autoencoder가 서로 다른 시계열을 잘 분류함
