
과릿 운영 중 발생한 Redis 스냅샷 오류의 재발을 방지하기 위한 주기적인 Docker Log 삭제를 도입하는 과정을 정리한다.
목적
Redis 스냅샷 오류의 원인은 Docker Log가 많이 쌓여 발생한 docker no space left on device 때문이다. 이 문제는 log 파일을 삭제해주지 않는다면 지속적으로 발생할 수 밖에 없는 문제기에 해결이 필요하다고 판단했다.
Q. Log를 지워서 발생할 수 있는 문제는 없을까?
A. Log를 지속적으로 가지고 있으면서 활용할 수 있는 포인트는 크게 3가지라고 생각한다.
- 로그 기반 시스템 성능 모니터링
- 에러 발생 시, 로그 기반 디버깅(= 문제 해결)
- 사용자 행동 분석
과릿은 모니터링 시스템으로 Sentry를 활용하고 있다.
성능 모니터링에서는 우선순위로 두고 있는 것은 API Latency인데, 이는 AOP를 통해 1초 이상의 API Latency가 발생 시 Sentry에 이벤트로 발송하도록 설정하고, 슬로우 쿼리에 대해서는 MySQL Slow Query 설정하여 커버할 수 있다고 판단했다.
에러 발생은 Sentry에서 이벤트로 확인할 수 있고, 관련 정보들도 다 모아 볼 수 있기에 문제 해결 과정에서 로그의 활용도는 상대적으로 낮다고 판단했다.
마지막은 사용자 행동 분석인데, 이는 Amplitude를 활용하여 클라이언트에서 트래킹을 하고 있으므로 일정 기간이 지난 로그는 삭제해도 괜찮다고 판단했다.
Q. 지우고자 하는 로그의 기간은 어떻게 설정했는가?
A. 최근 "가상 면접 사례로 배우는 대규모 시스템 설계 기초 2"를 기반으로 스터디를 진행하고 있는데, 해당 책에서는 오래된 로그를 냉동 저장소로 옮겨서 저장한다고 얘기한다. 그러면서, 로그를 다양하게 활용한다는 관점에서 한달 지난 로그는 분 단위로/1년이 지난 로그는 시간 단위 등으로 로그를 묶어 최적화를 한다고 표현한다.
냉동저장소에 저장할 필요가 없으며, 한달 이상의 장기 로그의 필요성은 더더욱 없다는 점과 프리티더라는 서버 특성상 로그 파일의 규모를 최대한 줄이는 것이 서버의 안정성을 높일 수 있을 것이라 생각해 최종적으로 3일이 지난 로그들을 삭제하는 것으로 결정했다.
방법
Log를 주기적으로 지우기 위한 방법은 크게 3가지가 있다.
- 수동으로 서버 재시작 (stop이 아닌 rm)
- 수동으로 *.log 파일 삭제
- Logrotate + crontab
서버의 중단을 발생시키지 않으며, 편리함이 가장 높은 3번을 도입하는 것으로 결정했다.
Logroate + Crontab 도입
과릿은 AWS EC2에 배포되어 있으며, ubuntu 22.04 버전이다.
1. logrotate 설치 여부 확인
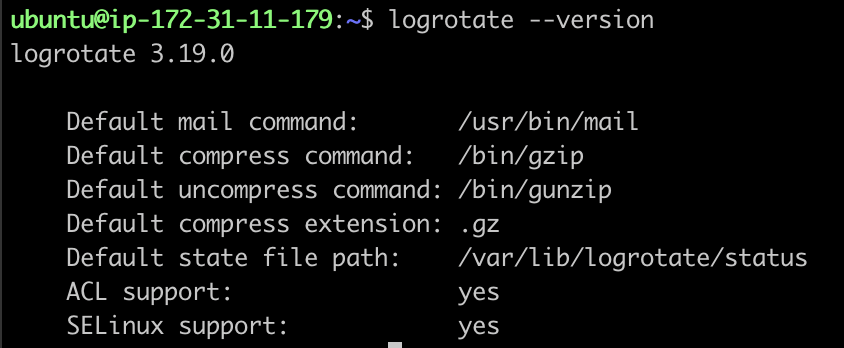
2. logrotate.conf 경로
linux die 페이지에서 logrotate에 대하여 정리되어 있다. Files 목차로 가보면, configuration options는 /etc/logrotate.conf에 위치해있음을 알 수 있다.
3. logrotate 옵션
- daily : 매일 로테이트 진행
- weekly : 매주 로테이트 진행
- monthly : 매달 로테이트 진행
- yearly : 매년 로테이트 진행
- rotate [파일갯수] : 로테이트 진행될 파일갯수 ex) rotate 5
- compress : 로테이트 진행된 로그파일 압축(gzip)
- create [권한][유저] [그룹] : 로테이트 되는 로그파일 권한 지정 ex) create 644 root root
- nocompress : 로테이트 진행된 로그파일을 압축하지 않는다(기본값)
- compresscmd [압축명] : gzip 이외의 압축프로그램 지정
- uncompresscmd : 압축해제 명령 지정(기본값 : gunzip)
- compressext [확장자명] : 압축된 백업 로그파일에 지정할 확장자 설정
- compressoptions [옵션] : 압축 프로그램에 대한 옵션 설정(-9 : 압축률 최대)
- dateext : 로그파일에 YYYYMMDD형식의 확장자 추가 백업 파일의 이름에 날짜가 들어가도록 함
- errors [메일주소] : 에러 발생시 지정된 메일주소로 메일발송
- extention 확장자명 : 로테이트 진행된 로그파일의 확장자 지정
- ifempty : 로그파일이 비어있는 경우 로테이트 진행 (기본값)
- noifempty : 로그파일이 비어있는 경우 순환하지 않는다
- mail [메일주소] : 순환후 이전 로그파일을 지정된 메일주소로 발송
- maxage : count로 지정된 날수가 지난 백업 파일 삭제 ex) maxage 30 30dl
- missingok : 로그파일이 없을 경우에도 에러 처리하지 않는다
- prerotate / endscript : 로테이트 진행작업 전에 실행할 작업 설정
- postrotate / endscript : 로테이트 진행작업 후에 실행할 작업 설정
- sharedscripts : prerotate, postrotate 스크립트를 한번만 실행
- size [사이즈] : 로테이트 진행 결과 파일사이즈가 지정한 크기를 넘지않도록 설정 / 지정된 용량보다 클 경우 로테이트 실행 ex) size +100k
- copytruncate : 현재 로그파일의 내용을 복사하여 원본 로그파일의 크기를 0으로 생성
(정리된 옵션 출처: IT/보안 블로그 / 2024-06-06)
4. logrotate 파일 생성
logrotate를 통해 처리하고자 하는 작업은 아래와 같다.
- 일 단위로 로그를 관리
- 로그 파일은 최대 3개까지 관리(= 3일 이내의 로그만 보존)
- 파일 이름에 날짜 명시
- 회전된 이후, 불필요한 로그 삭제(= 일주일 이상된 로그 삭제)
/var/lib/docker/containers/*/*.log {
daily
rotate 3
compress
missingok
copytruncate
notifempty
create
dateext
postrotate
find /var/lib/docker/containers/ -name "*.log.*" -type f -mtime +3 -delete
endscript
}5. logrotate 실행 확인
지우기 전 컨테이너 로그의 양은 아래와 같다.

명령어를 통해서, logrotate를 실행시키고 그 결과를 확인할 수 있다.
sudo /usr/sbin/logrotate -f /etc/logrotate.d/docker
위 명령어를 실행했으나, 또 No space left on device가 발생해서, docker image prune -a로 미사용 이미지를 지워, logrotate가 실행될 수 있도록 했다. (이제, 로그가 주기적으로 지워질 것이므로 큰 문제가 없지 않을까 예상한다.)
아래 명령어를 통해, logrotate가 정상적으로 잘 동작했는지 확인할 수 있다.
sudo cat /var/lib/logrotate/status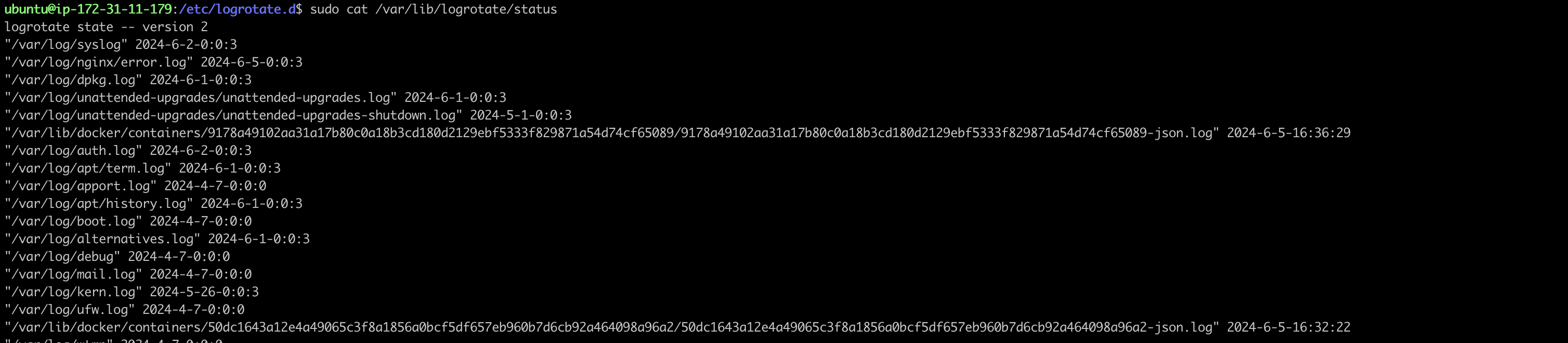
지운 후, 컨테이너 로그 양은 이렇게 변화했다.

- 323M -> 31M
- 400k -> 76k
- 323M -> 31M
꽤나 괜찮은 수치의 감소량이라고 생각한다.
6. Crontab 설정
sudo crontab -e명령어를 통해 들어가 0 0 * * * /usr/sbin/logrotate -f /etc/logrotate.d/docker를 등록해주었다. 아래와 같이 정상적으로 등록된 것을 확인할 수 있다.
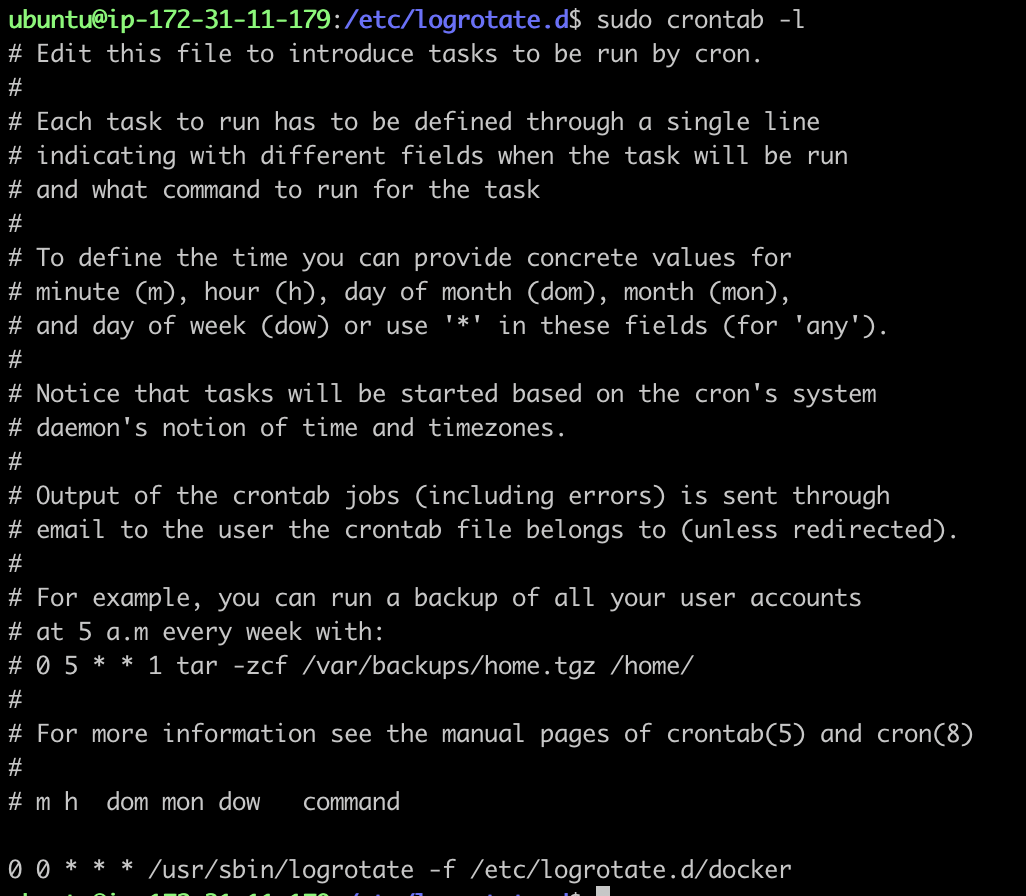
이전 글에서 Redis의 옵션을 no로 설정해놓았던 것 또한 yes로 복구시켰다.
프리티어이기에 다시 메모리가 터진다면 no로 또 돌릴 수도 있을 것 같다는 생각도 든다.
그렇지만, 여유 공간이 없어 서비스 장애가 발생하는 경우를 최소화시킬 수 있게 되었다는 점과 logrotate를 통한 용량 최적화 방식을 적용해볼 수 있었던 좋은 기회였다.
