LOL 밴픽 페이지를 구현하기 위해 필요한 정보로는 모든 챔피언의 이름과 이미지가 있다.
단순 검색을 통해서 챔피언들의 이름을 구할 수 있지만, Riot API를 활용하는 것이 목표였기에, Riot API에서 JSON으로 주어진 데이터들에서 챔피언 이름과 이미지들을 파싱하는 것을 진행해보았다.
구현
챔피언 이름
과정
- 먼저 챔피언에 대한 데이터를 가지고 있는 JSON 파일을 찾아야 한다.
해당 파일은 League of Legends Docs에서 제공하고 있다.
League of Legends Docs를 보면 Champions 부분이 있다. 여기에 JSON파일을 확인할 수 있다.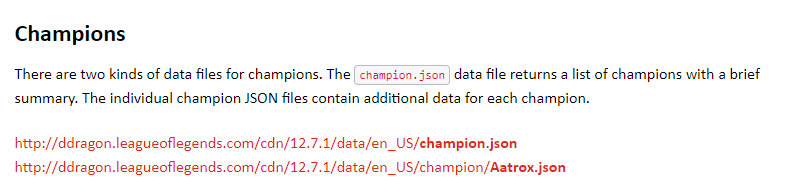
위의 사진의 URL 클릭해서 들어가면 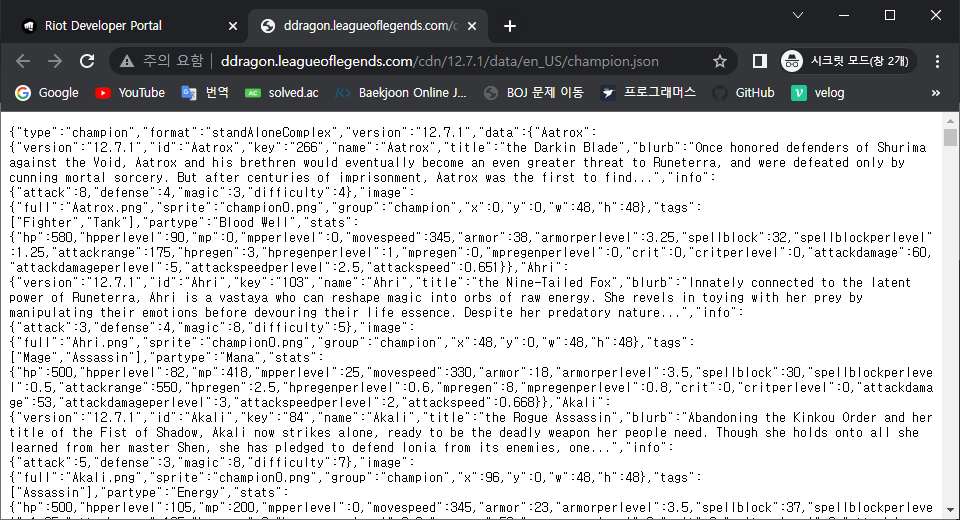
이런 JSON 파일을 확인할 수 있다.
- 이제 해당 JSON 파일을 Python을 이용하여 다루고자 한다. 이 때 Python에서 requests 모듈을 이용했다. 해당 모듈에는 json() 메소드를 통해 JSON 데이터 형식으로 변환이 가능하기 때문이다.
import requests
# get Json File
datas = requests.get('https://ddragon.leagueoflegends.com/cdn/12.6.1/data/ko_KR/champion.json')
datas = datas.json()-
JSON 데이터의 구조는 아래와 같다.


-
챔피언 이름만 필요하기 때문에 해당 JSON 파일에서 data라는 key의 value들을 가져온다.
import requests
champion = []
# get Json File
datas = requests.get('https://ddragon.leagueoflegends.com/cdn/12.6.1/data/ko_KR/champion.json')
datas = datas.json()
# champion Name parsing
for data in datas["data"]:
champion.append(data)- 해당 champion을 출력해보면 champion 이름들을 모두 가져왔음을 알 수 있다.
챔피언 이미지
과정
-
챔피언 이미지 역시 League of Legends Docs에서 찾아볼 수 있다.
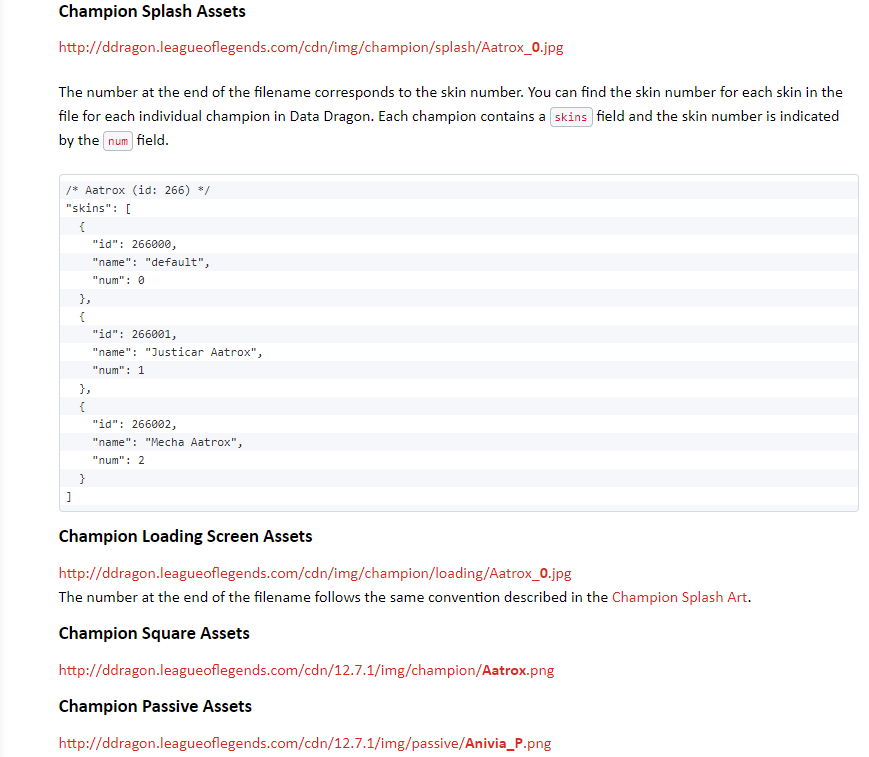
위의 이미지에서 보이는 URL들을 클릭해보면 관련 챔피언의 이미지를 확인할 수 있다. -
밴픽에서 필요한 것은 사각형의 챔피언 이미지이므로 Champion Square Assets의 URL을 통해 이미지를 다운받아야 한다.
이 때 파일명이 챔피언 이름 + .png 확장자이므로, 위의 파싱한 챔피언 이름 배열을 이용해서 진행하면 된다. -
python의 requests 모듈을 이용하여 구현한다.
import requests
champion = []
# get Json File
datas = requests.get('https://ddragon.leagueoflegends.com/cdn/12.6.1/data/ko_KR/champion.json')
datas = datas.json()
# champion Name parsing
for data in datas["data"]:
champion.append(data)
for champ in champion:
save_path = "D:\Web\lol_banpick\championImage\ " + champ + ".png"
image_url = "http://ddragon.leagueoflegends.com/cdn/12.7.1/img/champion/" + champ + ".png"
download_image = requests.get(image_url)
with open(save_path, 'wb') as file:
file.write(download_image.content)- 해당 스크립트를 실행한 결과, 아래와 같이 모든 챔피언 이미지를 다운받았다.
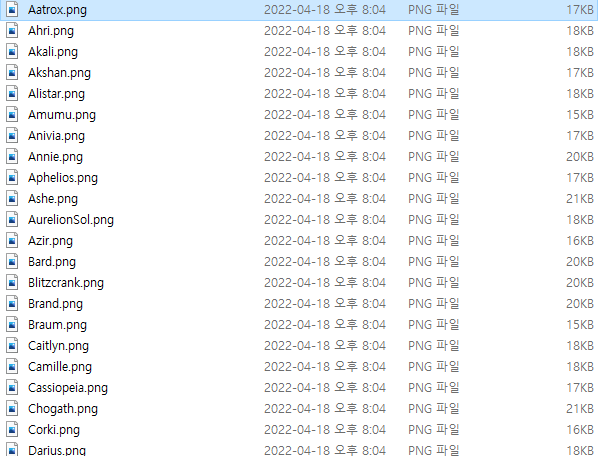
- 이 과정에서 주의해야할 점은 파일을 여는 과정이다. 파이썬으로 파일을 열 때, 이미지 파일이기에 t가 아닌 b로 파일을 열고 작성하여야 한다. download_image.content에서 .content는 해당 파일의 바이너리 원문이기 때문이다.
