Backchannel Prediction

오늘은 내 연구실에서 하는 분야를 소개해보고자 한다.
Backchannel 이란?
백채널(이하 BC)은 대화에서 짧고 빠른 반응을 의미한다.
청자의 BC를 통해 화자는 청자가 잘 이해하고있는지, 공감되는지의 여부를 확인할 수 있다.
대화에서 적절한 타이밍에 적절한 BC를 사용하는 것은 대화를 조금 더 풍부하게 만들어준다.
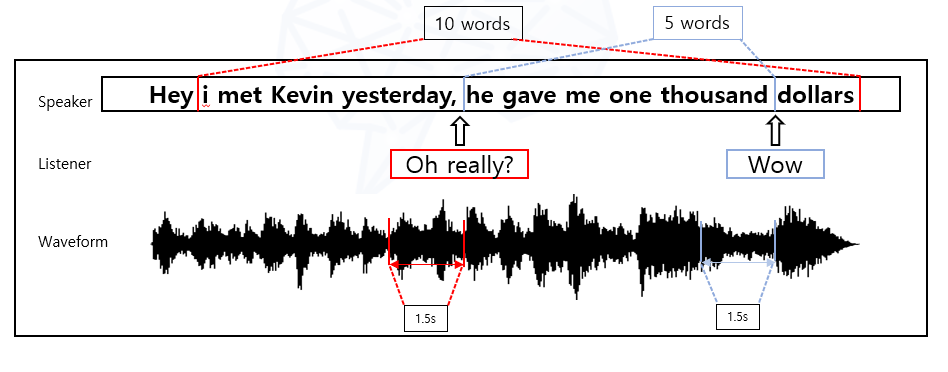
위의 예시는 현재 모델을 학습시키는데에 사용하는 방식을 의미한 것이다.
음성은 BC발생 직전 1.5초를 사용하며 텍스트 정보의 경우엔 5, 10, 20등 다양한 길이를 사용한다.
실증에서 사용하기 위하여 AI가 적절한 BC를 생성해내기 위한 학습을 하고자한다.
현재 이 Task의 문제점은 다음과 같다.
1. 현재 대화에 중요한 시각적인 정보를 사용하지 않는다는 점
2. 음성과 텍스트간의 연관성을 찾지 않고 별개의 feature들을 통해 학습을 한다.
따라서 위 두가지를 해결하여 실증에서 AI가 적절한 BC를 생성해내기 위한 분류 및 생성을 하고자한다.
이 Task에서 다뤄지는 논문은 2개가 있다
1. BPM_MT
MFCC와 KoBERT를 사용하여 Concat을 통한 Loss와, Sentiment dictionary와 대조를 시켜 만든 Sentiment Loss를 9:1의 비율로 Sum하여 학습시킨다. 이 논문은 Sentiment를 사용하여 성능을 높히고, text의 길이를 늘릴수록 성능이 좋다는 것을 보였다2. Ortega
Ortega는 단순한 CNN 모델로써, Audio, text CNN을 통하고, listener embedding 총 3개의 feature를 concat한 후 Linear-Softmax를 통하여 Classifier를 한다. 이 논문은 BC 생성에 음성데이터의 중요도와 음성/텍스트의 길이에 따른 성능의 변화 추이를 보였다.

work0ut