
프로젝트 기간
- 2025-01-03 ~ 2025-02-27
- 인원은 6명
무엇을 배웠나요?
1. Jira를 사용한 프로젝트 협업스킬
JIRA란?
지라는 아틀라시안이 개발한 사유 이슈 추적 제품이다. 버그 추적, 이슈 추적, 프로젝트 관리 기능을 제공하는 소프트웨어이다.
지금까지 프로젝트를 해오면서 불편했던 점은 팀원들의 작업진행 정도를 파악하기 힘들었고 매번 어디까지 작업했는지
종합하는 시간을 가져야만 파악할 수 있다는 점이 불편했었다.
이번 프로젝트에서 JIRA를 도입하면서 팀원들의 업무량, 속도 등을 파악하기 쉬워졌고
프로젝트를 더 넓은 시야에서 볼 수 있다는 점이 좋았다
팀원들과 백로그를 작성하고 스프린트진행하며 애자일 하게 개발하는 연습을 주로 했다
2. MongoDB, Redis 적용방법
MongoDB : NoSQL 데이터베이스이며 데이터를 JSON 형태로 저장한다 특히 대용량데이터 처리에 강점을 가진다.
Redis : 인메모리 데이터베이스이고 Key-Value 구조로 저장된다.
이번 프로젝트에서는 성능을 위해 데이터베이스를 Mysql제외하고 MongoDB, Redis를 프로젝트에 적용했다.
매출로그, 판매내역 등 데이터를 이용해서 대시보드를 만들거나 데이터 분석하여 매출 예측하는 기능을 만들기 위해서
대규모 데이터를 다루기엔 MySql만으론 성능상 불리하다고 생각했다.
그래서 대규모 데이터를 읽기/추가할 때 좋은 성능을 내는 MongoDB를 사용하는 게 적절한 선택지인 것 같아서 적용했다. 레디스 또한 JWT 토큰 등 휘발성이 강한 데이터를 다룰 때 주로 사용했고. 자주 요청되는 데이터를 캐싱하는
용도로도 사용했다.
레디스 캐싱전략을 공부를 해봐야겠다고 느꼈다.
3. Docker를 이용한 배포 및 개발환경 세팅
항상 프로젝트를 하면 개발환경 세팅하는 것에 시간을 많이 사용하곤 했다. 이번에 Docker로 EC2에
DB 컨테이너를 띄우는 김에 로컬환경에서도 개발환경 세팅을 Docker로 시도했다
결과는 매우 만족했다. 버전변경에 자유롭고 설치 후 삭제를 할 필요 없이 컨테이너 종료만 하면 된다는 점이
아주 편했다. 이제 도커를 배운 것이 아쉽게 느껴질 정도로 매우 만족했다.
다음 프로젝트엔 인프라를 담당해서 도커와 더욱 가까워져야겠다.
4. Virtual Thread 적용방법
JDK 21 버전부터 정식지원 하는 기능이며, 기존 플렛폼 스레드와 달리 OS스레드와 1대1 매핑되지 않는 가벼운 스레드이다.
항상 동기처리 방식으로 개발을 해왔었던 나에게 신선한 경험을 하게 해 준 기능이다.
다건의 DB에 데이터 쓰기 작업을 할 때 주로 사용했다 쓰기작업을 병렬처리 함으로써
Blocking I/O 문제를 해결하여 성능상 이점을 보려고 했다
하지만 조회에서 일부 응답이 먼저 나가는 일이 벌어졌다 비동기 방식의 특징을 간과해서였다.
위 문제를 해결하려고 노력한 덕분에
비동기/동기 처리의 특징을 개발로서 익힐 수 있어서 좋았다.
5. 부하테스트 및 시각화작업
부하테스트는 K6, 시각화는 InfluxDB, Grafana를 사용했다.
주변 개발자 친구들에게 항상 하는 말 이 있다
이젠 기능구현은 누구나 잘한다, 경쟁력을 가지려면 다른 무언가 필요하다.
이번엔 그중에서 테스트라는 영역을 선택해서 실제 프로젝트에 적용하고 싶었다.
계획은 K6로 부하테스트를 하고 시계열 데이터를 InfluxDB에 저장 후
Grafana를 통해 테스트 결과를 실시간으로 시각화하고 싶었다.
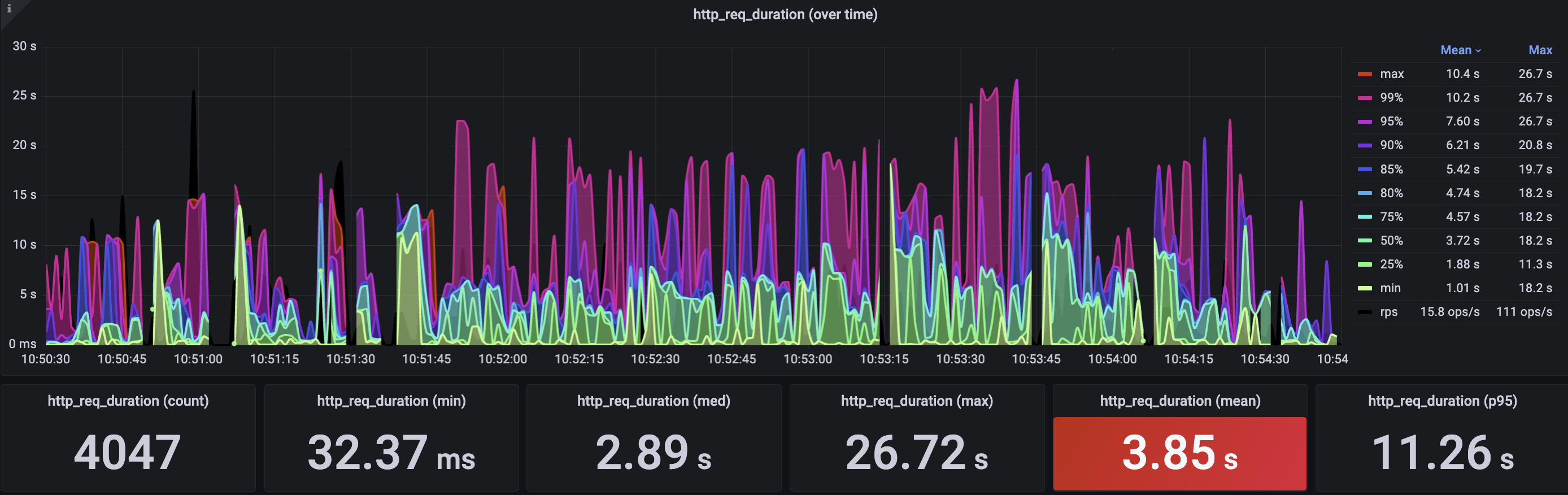
결과적으로 성공했고 앞으로 프로젝트마다 부하테스트 진행하면서 서비스의 capacity를 체크하고 성능을 최적화하는 방법을 공부해야겠다.

글 잘 읽었습니다. 좋은글이네요 근데 싸피에서는 공통프로젝트만 하신건가요? 특화나 자율 프로젝트에 대한 글은 없네요..?