웹 스크래핑/크롤링에서 중요한 포인트는 2가지가 있다.
- 요청을 하는 것 (코드 단에서 브라우저를 키지 않고 요청하는 것)
- 요청해서 가지고 온 html 중에 내가 원하는 정보를 잘 솎아내는 것
1번을 하는 것이 Requests, 2번이 BeautifulSoup 패키지의 역할이다.
때문에 웹스크래핑/크롤링에 앞서 BeautifulSoup(bs4) 패키지를 설치한다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup)이때 결과로 링크의 Html이 들어온다.
headers는 코드에서 요청할 때 막아둔 사이트들이 많음.
브라우저에서 엔터 친 것 같이 만들려고 쓰는 것.
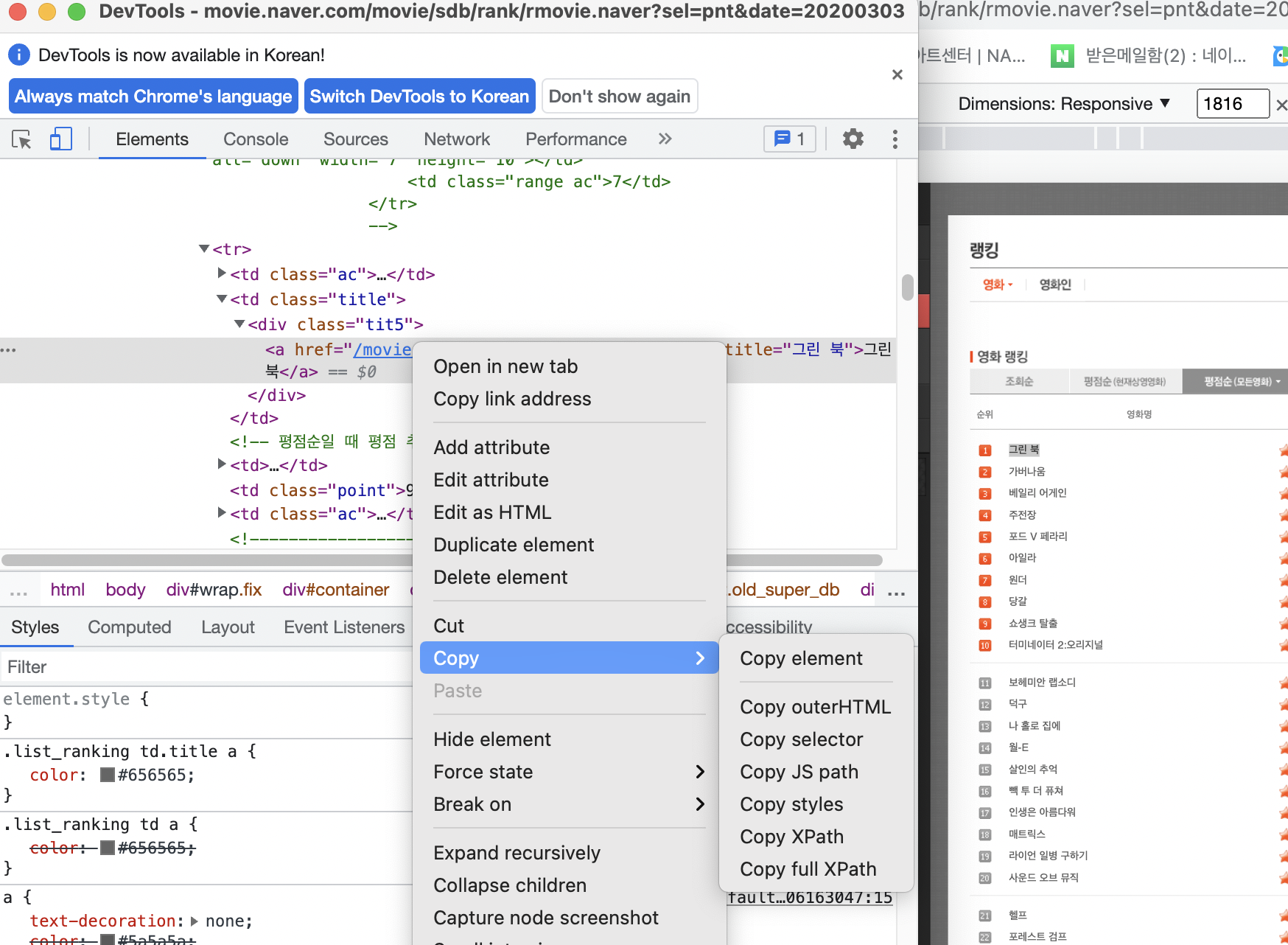
내가 긁어오기 원하는 html 검사지의 코드에서 copy-copy selector
복사한 선택자를 코드의 ('')에 삽입하면 다음과 같이 출력된다.
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')print(title)
<a href="/movie/bi/mi/basic.naver?code=171539" title="그린 북">그린 북</a>
//텍스트만 출력하고 싶을 떄
print(title.text)
그린 북
//속성을 출력하고 싶을 때
print(title['href'])
/movie/bi/mi/basic.naver?code=171539 .select()는 리스트를 가지고 오는 것
.select_one()은 리스트 중의 특정한 하나를 가지고 들어옴
tr.select_one('')= tr 중에서 특정한 하나 ''를 찾습니다
의미로 볼 수 있다.
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
print(a_tag)
이때 값 중에서 None이 출력되는 경우가 있다.
우리가 스크래핑하고 있는 네이버 영화페이지의 경우 중간에 선을 그어주기 위해 None이 생김.
이럴 경우 text만 출력하기 위해서 다음과 같은 방법을 쓸 수 있다.
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
title = a_tag.text
print(title)None이 아닌 경우만 출력하는 조건문
영화 페이지에서 순위, 이름, 별점 가져오기
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
trs = soup.select('#old_content > table > tbody > tr')
# select를 이용해서, tr들을 불러오기
for tr in trs:
# movie 안에 a 가 있으면,
name = tr.select_one('td.title > div > a')
if name is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = name.text # a 태그 사이의 텍스트를 가져오기
star = tr.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
print(rank, title, star)위의 코드로 다음과 같은 결과 값들을 뽑아낼 수 있음

