import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
name = tr.select_one('td.title > div > a')
if name is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = name.text
star = tr.select_one('td.point').text
doc = {
'rank':rank,
'title':title,
'star':star
}
db.movies.insert_one(doc)위의 코드를 통해서 네이버 영화 평점 딕셔너리 리스트가 내 서버에 안에 DB로 저장이 되어진다.
위에서 저장된 웹스크래핑 결과를 이용하는 몇가지 퀴즈를 풀어보자
1. 원하는 평점 값 파이썬에서 출력하기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
target_movie = db.movies.find_one({'title':'매트릭스'})
print(target_movie['star'])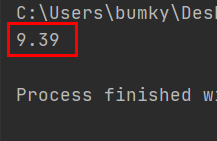
2. 매트릭스와 평점 값이 같은 다른 영화 이름 출력하기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
target_movie = db.movies.find_one({'title':'매트릭스'})
target_star = target_movie['star']
same_star = list(db.movies.find({'star': target_star}))
for movie in same_star:
print(movie['title'])
이때 마지막에 그냥 print 명령어를 쓰면 딕셔너리 형태로 출력되기 때문에
for 형태로 출력하는 것이 읽기에 편하다.
3. 매트릭스의 평점으로 0으로 만들기
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
db.movies.update_one({'title':'매트릭스'},{'$set':{'star':'0'}})
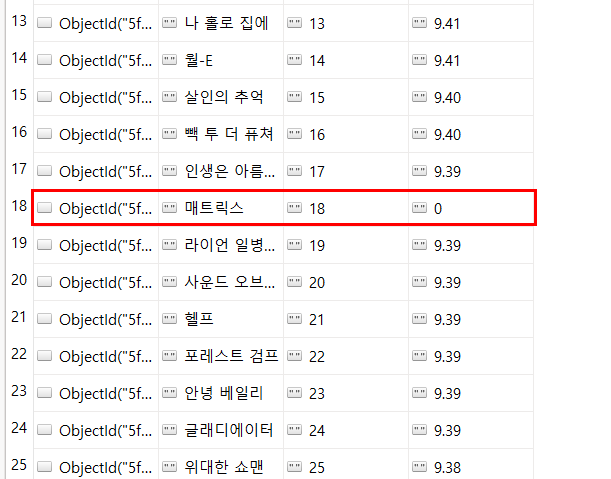

이때 0앞의 표시가 ""인지 #인지 달라지는데 이는 문자열'0'로 표기했는지 그냥 0으로 삽입했는지에 따라서 다르다. 관리에 있어서 일괄적으로 문자열인지 숫자인지가 중요하므로 맞춰주는 것이 중요하다.
