최근 회사에서 프로젝트를 진행하면서 재밌는? 현상을 발견했다.
어떤 프로그램에서 어떤 데이터를 조회하는 로직만 실행되면 DB Connection이 자꾸 끊어지는 현상이 발생했다. 이유는 간단했다. 사용자 정보 테이블들을 전화번호 컬럼 데이터와 조인해서 조회해 오는 쿼리였는데, 개발 당시에 썼던 개발 테스트 디비에 모든 전화번호 컬럼이 같은 번호로 저장되어 있어서 그 쿼리만 실행 수만은 데이터를 조인하게 되면서 디비와의 연결이 끊어지는 것이였다. (마치 쿼리를 실행시킨 나에게 디비가 살려달라고 하는것 같았다. ㅎㅎ; ...)
이런 경험을 하면서 한 가지 의문이 들었다. 지금은 테스트 디비라 상관이 없고 운영디비에서도 번호가 중복될 일이 거의 없다고 보는게 맞으니 지금처럼 오류는 발생하지 않겠지만 만약, 실제로도 이렇게 많은 데이터를 조합해서 조회하는 쿼리가 존재하고, 로직상 꼭 필요로 한다면 어떤식으로 해결해 나가야 할까?
머리속에 당장 스쳐가는 아이디어는 이러했다.
- 쿼리를 효율적으로 작성하면 되지 않을까?
- 테이블들을 join할때 어떻게 해야 더 효율적으로 join할 수 있을까?
- 성능 개선을 할 수 있는 서브쿼리는 어떤 식으로 작성해야하는 걸까?
- 애초에 설계 부분에서 개선할 수 있는 방법이 있지 않을까?
마지막 생각에서 INDEX 개념을 찾아 보게 되었고 인덱스를 가지고도 조회 성능을 향상 시킬 수 있는 방법이 존재한다는 것을 알았다. 간단한 쿼리만 작성할 줄 알았던 나에게 인덱스란 개념은 새롭고 재밌는 부분이 아닐 수 없었다. 그러면서 나는 DB의 D자도 모르는 개발자라는 것을 새삼 깨달았다.
DB INDEX 란?
인덱스 개념은 코딩팩토리 블로그 글을 참고하여 정리해보자.
-
https://coding-factory.tistory.com/419?category=758273
인덱스는 데이터베이스 테이블에 있는 데이터를 빨리 찾기 위한 용도의 데이터베이스 객체이며 일종의 색인 기술이다. 테이블에 index를 생성하게 되면 index Table을 생성해 관리하고 인덱스는 테이블에 있는 하나이상의 컬럼으로 만들 수 있다. 가장 일반적인 B-tree 인덱스는 인덱스 키(인덱스로 만들 테이블의 컬럼 값)와 이 키에 해당하는 컬럼 값을 가진 테이블의 로우가 저장된 주소 값으로 구성된다.
인덱스 생성
-- 문법
CREATE INDEX [인덱스명] ON [테이블명](컬럼1, 컬럼2, 컬럼3 ... );
--예시
CREATE INDEX INDEX_SAMPLE ON BOOKS(TITLE, CATEGORY, CONTENT);
--컬럼 중복X 예시
CREATE UNIQUE INDEX INDEX_SAMPLE ON BOOKS(TITLE, CATEGORY, CONTENT);인덱스 삭제
--문법
DROP INDEX [인덱스명];
--예시
DROP INDEX INDEX_SAMPLE;인덱스 리빌드 할 대상 조회쿼리
SELECT I.TABLESPACE_NAME,I.TABLE_NAME,I.INDEX_NAME, I.BLEVEL,
DECODE(SIGN(NVL(I.BLEVEL,99)-3),1,DECODE(NVL(I.BLEVEL,99),99,'?','Rebuild'),'Check') CNF
FROM USER_INDEXES I
WHERE I.BLEVEL > 4
ORDER BY I.BLEVEL DESC인덱스 리빌드
--문법
ALTER INDEX [인덱스명] REBUILD;
--예제
ALTER INDEX INDEX_SAMPLE REBUILD;전체 인덱스 리빌드 쿼리문 만들기
SELECT 'ALTER INDEX '||INDEX_NAME||' REBUILD; 'FROM USER_INDEXES;고려해야 할 점
내가 찾아본 거의 대부분의 블로그 글에서는 Index를 남발하지 말라는 주의를 항상 하고 있고 인덱스를 생성하기 전에 꼭 먼저 SQL문을 더 효율적으로 작성기를 권장하고 있다. 그렇다면 인덱스를 사용해야한다면 어떤 점을 고려해야 할까?
인덱스 생성 시 고려할 점
- where절과 join, order by 등과 관련된 컬럼중 사용 빈도가 높은 것 키 값의 선별도가 좋은 컬럼
- 빈도가 낮고 T/F, M/F, 테이블이 작거나 자주 갱신될 때에도 인덱스를 사용하지 않는것이 더 좋다.
인덱스 활용법
- WHERE절에서 자주 사용하는 컬럼
- LIKE '%----...' 는 조심해서 사용(FULL SCAN 처리됨), '%'는 뒤에만 사용하기
- BETWEEN A AND B (clustered 인덱스 유리) : 범위 쿼리문에서는 클러스터 인덱스가 유리하지만 클러스터 인덱스는 테이블 당 1개만 가질 수 있다는 단점 존재
- ORDER BY에 항상 또는 자주 사용되는 컬럼
- JOIN으로 자주 사용되는 컬럼
- FOREIGN KEY(1:1 매핑)이 많을 때 : clustered, nonclustered 인덱스 둘 다 상관 없음
- FOREIGN KEY(1:N 매핑)이 많을 때 : clustered 인덱스 사용
- 100만건의 데이터 중 10건의 데이터 조회 : 찾는 건이 적은 컬럼에 인덱스를 걸어주는 것이 좋음
- 중복이 많은 컬럼에는 인덱스를 거는 것이 아님
- 조회되는 건수가 많으면 인덱스를 걸지 않고 FULL SCAN하는 편이 더 나음
- NOT 연산자는 긍정문으로 변경
- INSERT, UPDATE, DELETE 등 데이터의 변경이 많은 컬럼은 인덱스를 걸지 않는게 좋음 : 인덱스를 만드는데 시간과 저장공간이 소비되고 난 후에도 추가적인 공간이 필요하고, 데이터를 변경(INSERT, UPDATE, DELETE)를 하면 (특히 INSERT) 인덱스를 다시 조정해야하기 때문에 자원 소비가 심함.
Clustered, Nonclustered INDEX
인덱스에는 크게 clustered와 nonclustered 인덱스로 나뉘는데, clustered 인덱스는 물리적 정렬로 DB에 데이터를 입력 시 이것을 기준으로 입력이된다. 따라서 한 테이블에 오직 하나만 존재할 수 있으며 TABLE을 열었을때 ORDER BY를 사용하지 않아도 데이터가 clustered 인덱스에 따라 정렬이 되어 있는 것을 확인 할 수 있다. 물리적으로 정렬이 되어 있는 만큼 가장 빠른 처리를 한다. 즉, INDEX SCAN에 유리하다.
nonclustered 인덱스는 clustered 인덱스와 달리 중복된 값을 가지면 한 테이블에 여러 개를 생성 할 수 있다.
그 외에 UNIQUE는 중복을 허용하지 않는 값을 보호 할 때 사용되며 PRIMARY KEY의 경우에는 clustered와 UNIQUE 특성을 갖게 하는 제약키이다.
참고 [불곰] : https://brownbears.tistory.com/57
확인해보기
개념과 글만 보고 이해할 수 있다면 난 벌써 디비장인이 됐겠지만 그렇지 않으니 한 번 확인해보는 시간을 가져봤다.
일단 몇가지 확인을 위해서 먼저 3개의 테이블을 생성하고 10000개의 데이터를 넣어놨다.

첫 번째 테이블(BOOKS_SAMPLE_0)은 INDEX를 생성하지 않은 순수한 테이블을 만들었다.

두 번째 테이블(BOOKS_SAMPLE_1)은 INDEX를 생성했는데 컬럼 순서는 제목(title), 카테고리(category), 내용(content) 순이다.

세 번째 테이블(BOOKS_SAMPLE_2)도 INDEX를 생성했고 다만 컬럼 순서는 내용(content), 카테고리(category), 제목(content) 순이다.
여기서 확인하고 싶은것은 실제로 WHERE문을 통해 SCAN이 다르게 이루어지는지, 인덱스 생성시 컬럼순에 따른 실행계획 순서를 보고 싶었다.

만건의 데이터를 집어넣기 위해 프로시저도 작성해봤다. 이것을 통해 컬럼별 중복도 순서는 '내용(높음)>카테고리(중간)>제목(낮음)' 으로 볼 수 있다.
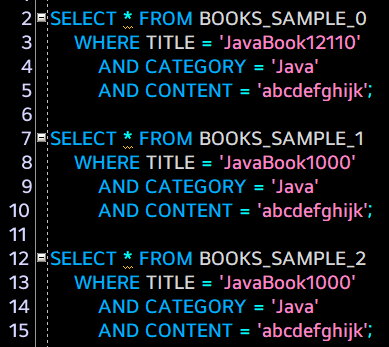
그러고 나서 위의 SQL문을 각각 계획설명을 통해 비교해보았다. 한 건의 데이터를 조회하기 위해서 제목은 고유한 값을 비교했고 비교 순서는 모두 동일하게 TITLE -> CATEGORY -> CONTENT 순으로 통일 하였다.
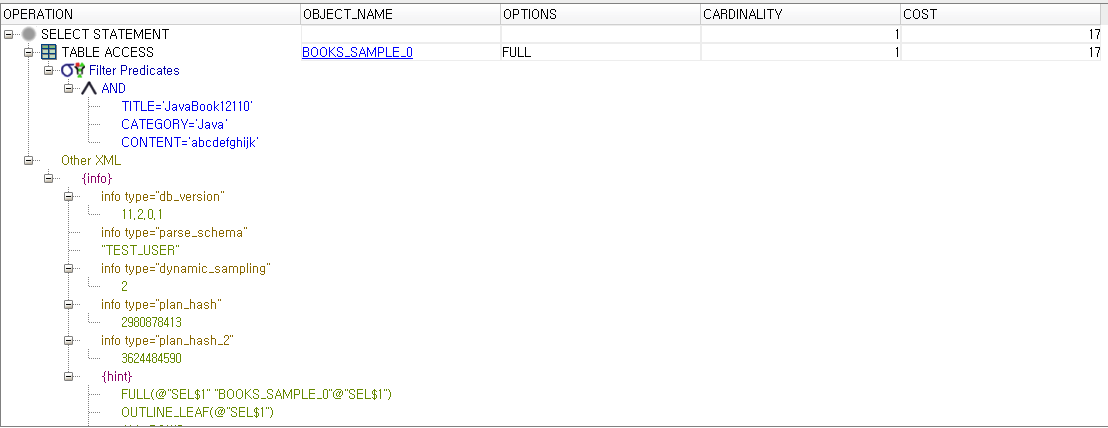
역시 예상했던대로 인덱스를 생성하지 않았던 첫번째 테이블(BOOKS_SAMPLE_0)은 FULL SCAN 된 것을 확인 할 수 있었다.
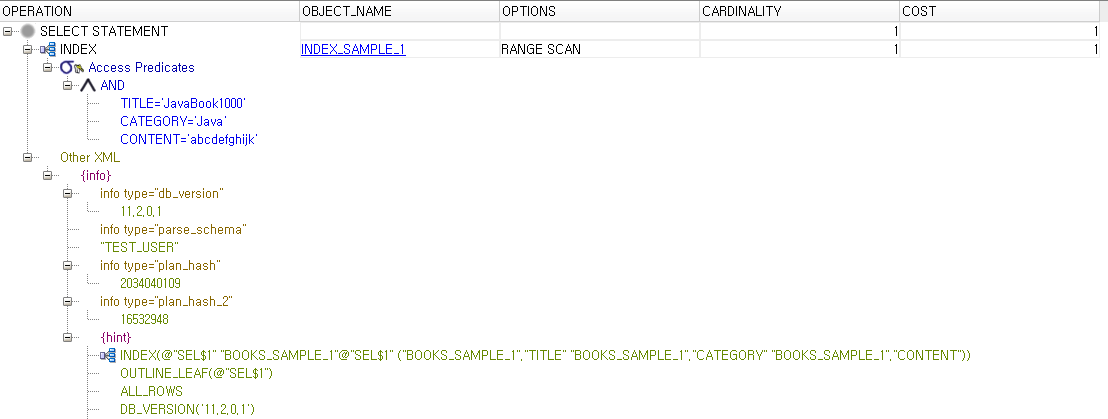
위의 실행계획은 두번째 테이블 조회에 대한 내용이다. 아까의 내용과는 다르게 RANGE SCAN이라는 값이 떠있고 OBJECT 이름은 INDEX_SAMPLE_1의 내용을 볼 수 있다. 즉, 원했던대로 DB가 생성한 INDEX를 통해 데이터를 조회한 것을 볼 수있다.
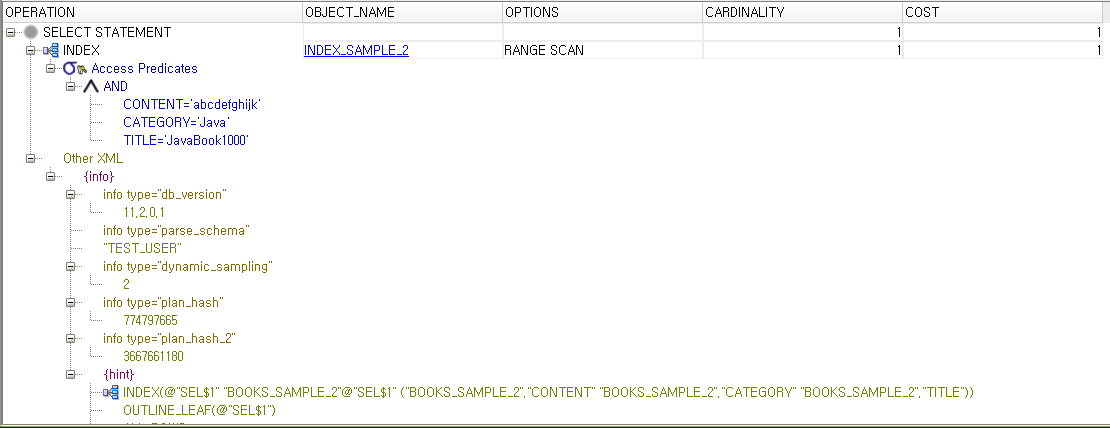
세번째 실행계획 내용은 두번째 내용과 별 다를게 없어 보이지만 WHERE문 실행 순서가 다름을 알 수 있다. 두번째(BOOKS_SAMPLE_1)에서는 제목을 먼저 비교하여 나온 결과 한 건을 카테고리 Java와 비교하고 그 결과를 또 내용과 비교하여 비교적 깔끔한 실행계획을 볼 수 있었는다.
하지만 세번째(BOOKS_SAMPLE_2)에서는 내용을 먼저 비교하고 나온 결과(총 만건, 내용은 모두 동일한 값을 넣었음)를 카테고리로 비교하고(총 2000건) 그리고 나머지 2000건에 대해서 제목을 비교해 결과적으로 두번째와 같이 한 건의 데이터를 조회했다.
인덱스 생성시 컬럼의 순서만 다르게 줬을 뿐인데 인덱스 컬럼을 통한 조회는 WHERE문의 순서와 상관없이 생성시 정해줬던 컬럼 순으로 실행한다는 것을 알았다. 인덱스 생성시 조심해서 생성해야 할 필요가 있는 부분이다.
다음은 PK와 INDEX를 비교하기 위해서 2개의 테이블을 더 만들었다.

이번엔는 BOOK_IDX 라는 컬럼을 추가해서 고유한 값을 넣고 그 컬럼 인덱스를 생성하고자 한다.

두번째 테이블(BOOKS_SAMPLE_4)는 첫번째 테이블(BOOKS_SAMPLE_3)와 동일한 컬럼으로 테이블을 생성하고 단 BOOK_IDX를 인덱스 컬럼대신에 PK로 제약조건을 걸어줬다. 그리고 테이블 정보를 확인해 보았다.
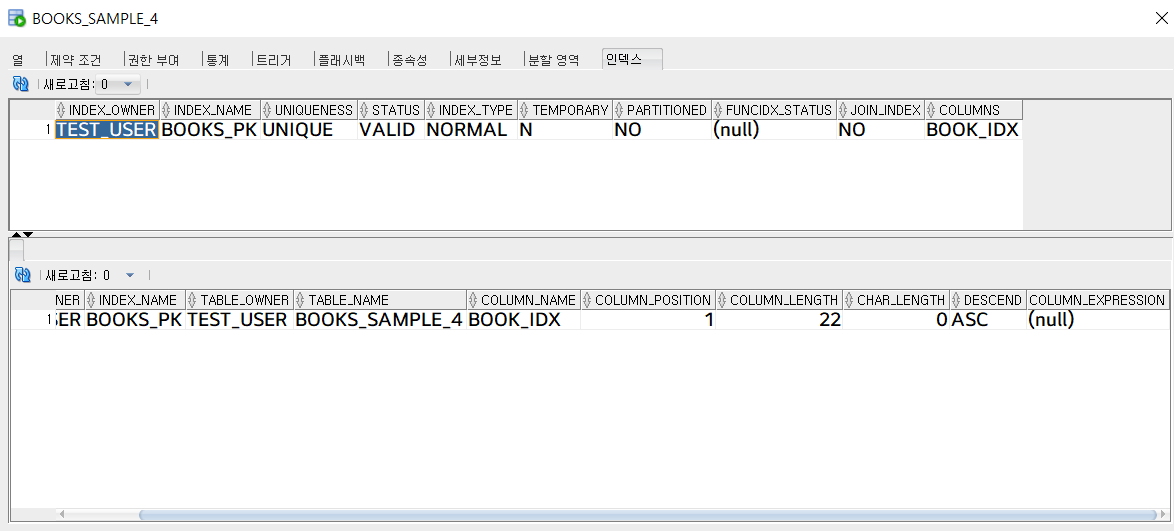
어? 신기하게도 두번째 테이블에 BOOK_IDX에 PK 제약조건만 걸어줬을 뿐인데 INDEX 컬럼이 하나 생겨졌다. 첫번째 테이블 정보와 비교해 보자.
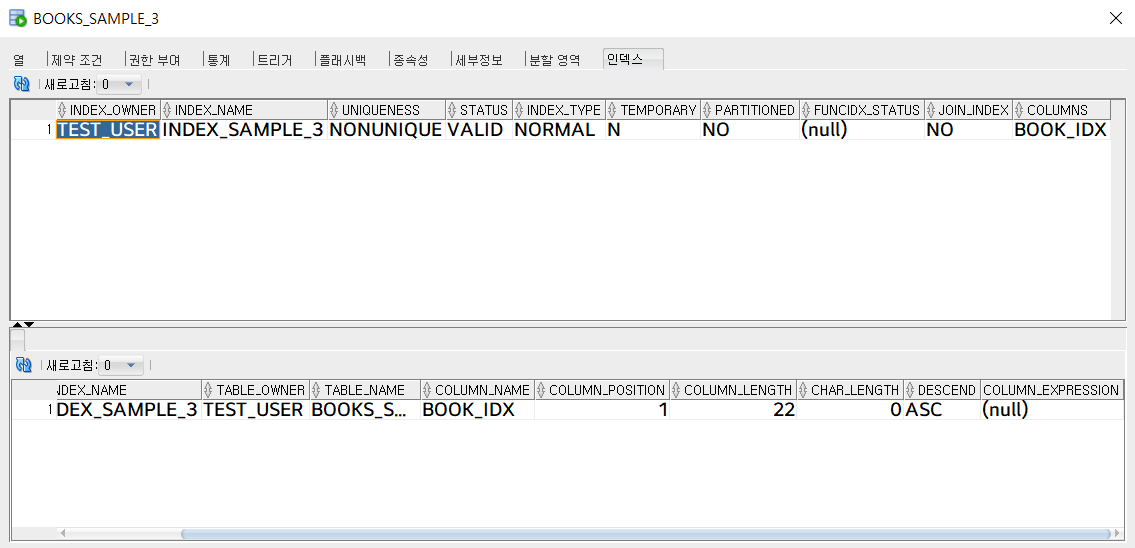
여기서 확인 할 수 있는 것은 PK제약조건으로 인해 생성된 인덱스는 UNIQUENESS의 값이 UNIQUE로 되어있고 첫번째 테이블의 인덱스를 생성할 당시 UNIQUE 옵션을 추가하지 않았기 때문에 두번째 테이블의 UNIQUE 여부는 NONUNIQUE의 값이 들어가 있는 것을 볼 수 있다. PK 제약조건을 설정하면 PK제약조건명과 동일한 명의 인덱스명으로 INDEX테이블이 생성되고 옵션은 중복불가 UNIQUE가 설정되었기 때문에 여태 나는 PK 컬럼을 고유하게 사용하고, 테이블들을 조인하고 WHERE문에서 PK컬럼의 값을 비교한 SQL문을 작성해 원하는 데이터를 추출 할 수 있었던 것이었다.
이렇게 INDEX를 공부하면서 자주 사용하던 PRIMARY KEY에 대한 내용도 알아가게 됐다.
마지막으로 실행계획도 살펴보자
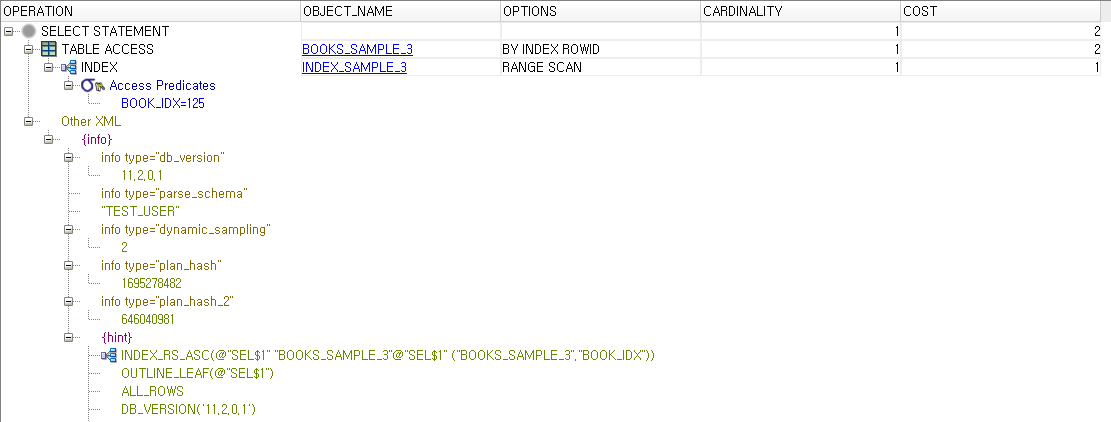
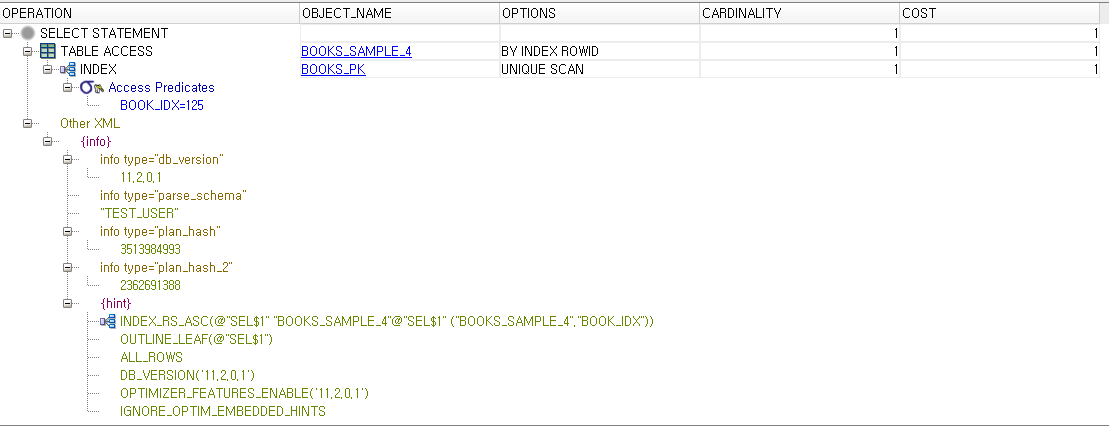
역시 탐색방식도 다른 것을 볼 수있다. 첫번째 테이블(BOOKS_SAMPLE_3)은 RANGE SCAN으로 수직 탐색 후 필요한 범위내에서 결과값을 추출했고, 두번째 테이블(BOOKS_SAMPLE_4)는 UNIQUE SCAN으로 수직으로 바로 한 건의 데이터를 찾아온 것을 알 수 있다. 당연히 PK 컬럼의 UNIQUE 인덱스는 고유하기 때문에 DB에서 탐색방식으로 UNIQUE SCAN을 선택했을 것이다.
이렇게 DB INDEX에 대해 공부하면서 아직 이해가 안가는 부분도 존재하지만 또 새로운걸 알아간다는 것에 작은 행복함을 느꼈다. 다음 글에서는 탐색방식 종류와 B-Tree구조와 B+Tree구조에 대해 알아 보도록 하자.
References
- https://coding-factory.tistory.com/419?category=758273
- https://itholic.github.io/database-index/
- https://brownbears.tistory.com/57
- https://firedev.tistory.com/entry/Oracle-DB%EC%97%90%EC%84%9C-INDEX-%EC%A0%9C%EB%8C%80%EB%A1%9C-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0
- https://yurimkoo.github.io/db/2020/03/14/db-index.html
