MySQL 실행계획 이란
MySQL 은 클라이언트가 요청을 하게 되면 SQL 엔진이 4가지 과정을 거쳐서 응답을 주게 된다
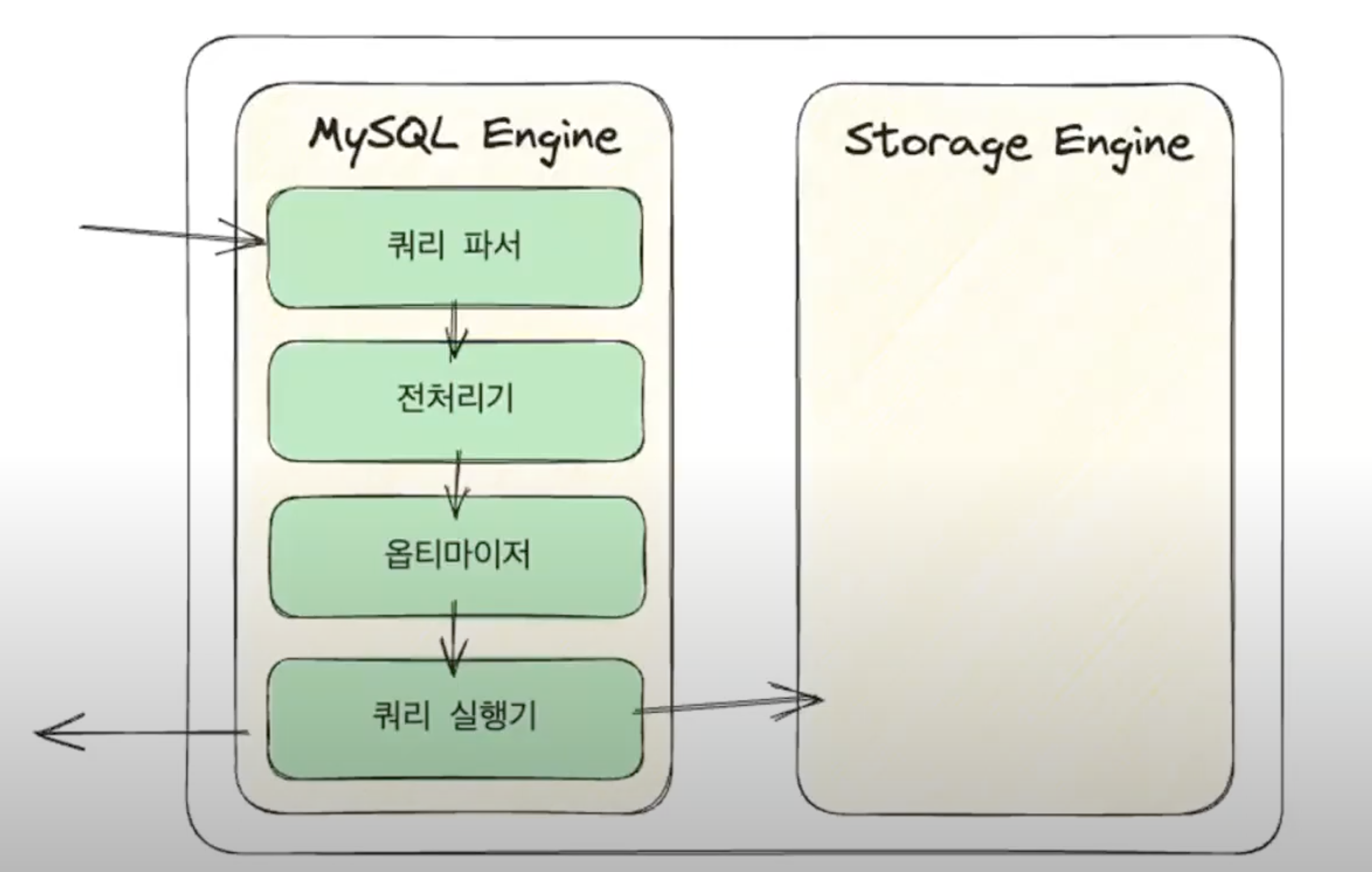
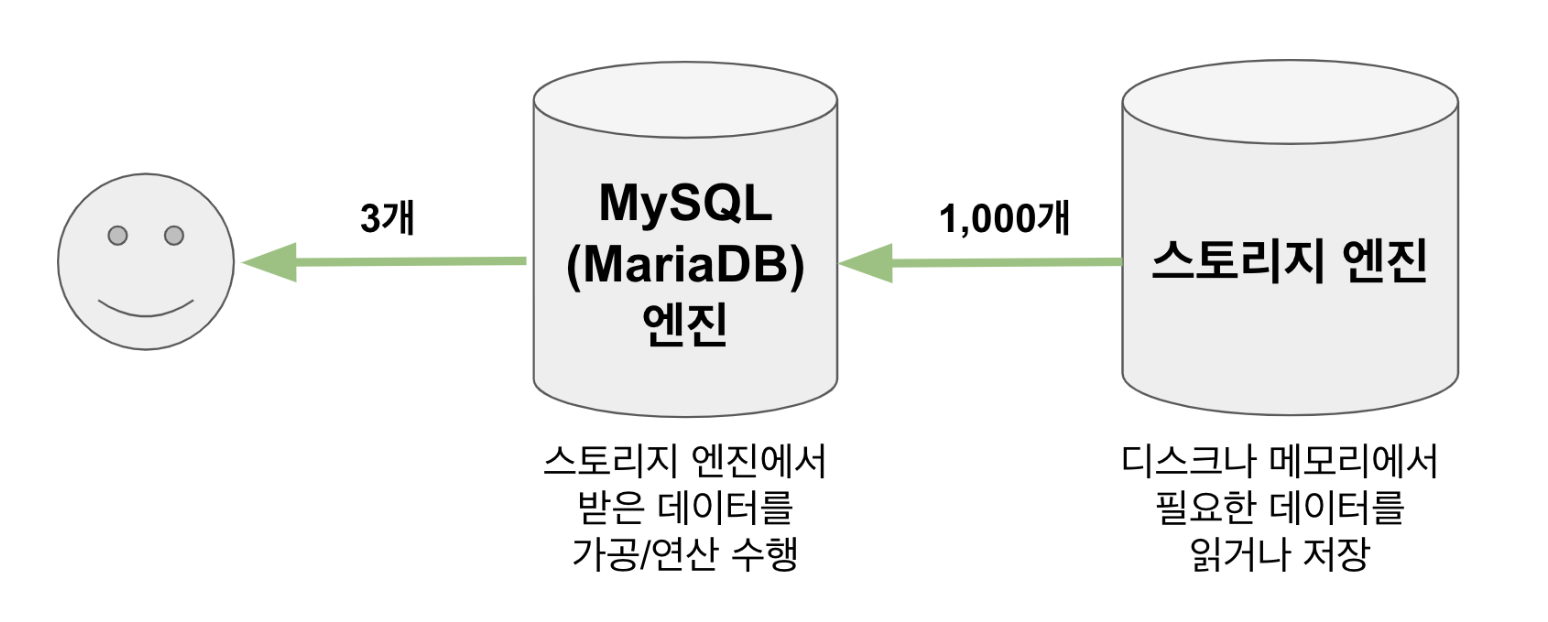
그 중 실행계획은 옵티마이저 와 관련이 있다
- 옵티마이저는 통계 정보를 기반으로 여러 방법의 비용을 계산한다
- 가장 비용이 적은 처리 방식을 최종적으로 선택한다
즉, 실행계획은 옵티마이저가 쿼리를 어떻게 처리할 것인지 계산해낸 결과
실행계획을 왜 알아야하는가 ?
- 우리의 의도에 맞게 MySQL 이 동작하는가를 검증
- 병목이 생기는 부분을 확인 하는 등
먼저 실습하기 앞서 EXPLAIN 으로 실행 계획을 확인하는 정보들은 아주 많다
그러므로 type / key / Extra 한정해서 확인해보겠다
type
- MySQL 이 어떻게 ROW 를 찾아내는지 를 나타낸다
- 각 종류에 따라 성능에 최적화된 순서가 존재한다
key
- 해당 쿼리에서 실제로 사용된 인덱스 이름을 보여준다
Extra
- MySQL 이 쿼리를 어떻게 처리했는지에 대한 부가 설명
- 성능 비교시 직접적인 힌트 를 제공하며 의도에 맞게 동작하는지 등을 확인 할 수 있음
예제 데이터
- 사원 (30만개)
- 부서 (9개)
- 사원_부서 테이블 (30만개)
테이블 생성
CREATE TABLE departments (
dept_no CHAR(4) PRIMARY KEY,
name VARCHAR(40) NOT NULL
);
CREATE TABLE employees (
emp_no INT PRIMARY KEY,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM('M', 'F') NOT NULL,
hire_date DATE NOT NULL
);
CREATE TABLE dept_emp (
emp_no INT,
dept_no CHAR(4),
from_date DATE NOT NULL,
to_date DATE NOT NULL,
PRIMARY KEY (emp_no, dept_no),
FOREIGN KEY (emp_no) REFERENCES employees(emp_no),
FOREIGN KEY (dept_no) REFERENCES departments(dept_no)
);부서 추가
INSERT INTO departments (dept_no, name) VALUES
('D001', 'Engineering'),
('D002', 'Tool Design'),
('D003', 'Marketing'),
('D004', 'Finance'),
('D005', 'Human Resources'),
('D006', 'Production'),
('D007', 'Development'),
('D008', 'Research'),
('D009', 'Customer Service');사원 추가
DELIMITER $$
CREATE PROCEDURE populate_employees()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 300000 DO
INSERT INTO employees (
emp_no, birth_date, first_name, last_name, gender, hire_date
)
VALUES (
i,
DATE_SUB(CURDATE(), INTERVAL FLOOR(RAND() * 15000 + 8000) DAY),
CONCAT('First', i),
CONCAT('Last', i),
IF(RAND() > 0.5, 'M', 'F'),
DATE_SUB(CURDATE(), INTERVAL FLOOR(RAND() * 5000) DAY)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL populate_employees();사원_부서 추가
DELIMITER $$
CREATE PROCEDURE populate_dept_emp()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 330000 DO
INSERT IGNORE INTO dept_emp (
emp_no, dept_no, from_date, to_date
)
VALUES (
FLOOR(RAND() * 300000) + 1,
CONCAT('D00', FLOOR(RAND() * 9 + 1)),
DATE_SUB(CURDATE(), INTERVAL FLOOR(RAND() * 5000 + 5000) DAY),
DATE_SUB(CURDATE(), INTERVAL FLOOR(RAND() * 2000) DAY)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL populate_dept_emp();전체 테이블 스캔 (풀 테이블 스캔)
EXPLAIN SELECT * FROM employees;
type: ALL
- 풀 테이블 스캔 (Full Table Scan)
- MySQL 이 해당 테이블의 모든 row 를 순차적으로 읽고 있다는 의미
- 일반적으로 가장 성능이 좋지 않은 접근 방식으로 간주된다
- 조건 (
WHERE) 이 인덱스와 무관하거나, 있어도 활용할 수 없는 등
key: Null
- 사용된 인덱스의 이름을 나타내는 컬럼으로 해당 쿼리에 대한 어떠한 인덱스도 사용하지 않았다 라는 의미
Extra: Null
- 쿼리 수행에 있어서 특별한 최적화 사항이 없다는 의미
- 아무런 조건이 없으므로 특별한 접근 방식 없이 테이블 전체를 스캔
PK 값을 통한 조회
EXPLAIN SELECT * FROM employees WHERE employees.emp_no = 1;
type: const
PK또는UK조건으로 ROW 가 유일하게 결정될 때 사용- 정확히 하나의 ROW 만 읽음 (실행 이전에 결과가 한 건 이하임을 무조건 예측할 수 있는 쿼리)
key: PRIMARY
- 실제 사용된 인덱스는 PRIMARY KEY (PK)
Extra: Null
- 쿼리 수행에 있어서 특별한 최적화 사항이 없다는 의미
부서-사원 테이블 에서 부서 조회
- 부서 “D005” 에 소속된 사원을 조회해보자
EXPLAIN SELECT * FROM dept_emp WHERE dept_no = 'D005';
type: ref
- 인덱스 컬럼을 사용한 비교에서 사용
- 동등 비교 (
=) 를 사용할때 보임 - 비 유니크 인덱스 나 외래키 등을 조건으로 여러 개의 ROW 를 가져오는 경우 사용 (PK, UNIQUE NOT NULL 아님)
- 동등 비교 (
dept_no = "D005"조건으로 인덱스를 타고 여러 ROW 를 가져오는 상황
key: dept_no
- 실제 사용된 인덱스의 이름
dept_no에 대해 인덱스가 걸려있다는 의미- 실행 시 해당 인덱스를 타고 조건에 맞는 ROW 를 탐색
Extra = Using index condition
- ICP (Index Condition Pushdown) 최적화가 사용되었음을 나타냄
즉, 인덱스를 통해 조회할 때 필터 조건을 스토리지 레벨까지 내려보내서 처리하는 최적화 방식을 의미한다
단순히 인덱스를 타고 ROW 를 찾은 후 MySQL 서버단에서 필터링하는 것이 아닌,
인덱스 조건을 스토리지 엔진에서 먼저 처리하므로 속도가 빨라진다
(InnoDB 스토리지 엔진이 ICP 를 지원할 경우 자동으로 활용됨)
참고
왜 “Index Condition Pushdown” 이라는 이름인 걸까 ?
간단히 이야기하면 MySQL 이 인덱스 조건을 “더 아래로 밀어 넣는다” 라는 의미의 최적화 기법을 설명한 용어
Index Condition
- WHERE 조건 절에서 인덱스 컬럼에 걸린 조건 (ex. dept_no = "D005")
Pushdown
- 이 조건을 MySQL 의 스토리지 엔진 레벨까지 내려보내서 먼저 평가하는 동작
즉, 조건을 인덱스에서 판단 가능한 건 미리 판단해서 필요 없는 ROW 는 아예 읽지도 않음 → 성능 향상
MySQL 5.5 버전까지는 조건이 인덱스에 포함된 필드라도 인덱스 범위 조건으로 사용할 수 없는 경우에는 스토리지 엔진 조건 자체를 전달 조차 못함 (ex.
LIKE "%TEST%")
범위 검색
- 사원일자 (
hire_date) 컬럼에 대한 범위 검색 - 아직 사원일자 (
hire_date) 컬럼에 대한 인덱스는 없음
EXPLAIN SELECT * FROM employees WHERE hire_date > '2022-01-01'
type: ALL
- 풀 테이블 스캔 (Full Table Scan)
- MySQL 이 해당 테이블의 모든 row 를 순차적으로 읽고 있다는 의미
- 조건 (
WHERE) 이 인덱스와 무관하거나, 있어도 활용할 수 없는 등
key: Null
- 사용된 인덱스의 이름을 나타내는 컬럼으로 해당 쿼리에 대한 어떠한 인덱스도 사용하지 않았다 라는 의미
Extra: Using where
- 조건을 통한 접근 방법을 사용하여 쿼리 실행
- 범위 검색 조건을 통한 쿼리이므로 당연하다
이제 사원일자 (hire_date) 컬럼에 대해 인덱스를 생성 후 범위 검색 실행
인덱스를 통한 범위 검색
CREATE index IX_employees_hire_date ON employees (hire_date);
EXPLAIN SELECT * FROM employees WHERE hire_date > '2022-01-01'
이 실행 결과를 보면 여전히 풀 테이블 스캔 (Full Table Scan) 을 한 걸로 보여진다
인덱스가 생성되지 않았나?
라고 생각할 수 있는데 possible_keys = IX_employees_hire_date 인 것을 보면 인덱스가 생성 되어 있고 키로 사용할 가능성이 있는 것으로 판단하고 있긴 하다
왜 풀 테이블 스캔을 처리하는걸까?
- MySQL 옵티마이저는 아래 여러 상황을 고려하여 최종 결정을 함
- 풀 테이블 스캔 vs 인덱스
- 조건절 - 필터링 비율
- 커버링 인덱스 여부 - 인덱스만으로 해결 가능한가
- 읽어야할 ROW 수
- I/O 비용
- 통계 정보 - 데이터의 실제 분포
여러가지 추측을 할 수 있는데 우선
- 커버링 인덱스
- 인덱스를 사용하더라도 결국에는 모든 컬럼을 조회해야 하므로 데이터 ROW 를 읽어야 한다
- MySQL 은 오히려 인덱스를 거치지 않고 바로 테이블을 읽는 것이 빠르다고 판단할 수 있다
- 인덱스 사용시
- 인덱스 → 일치하는 ROW 찾기
- 다시 테이블 접근 (ROW lookup) → 비용 증가
- 반면 풀 테이블 스캔 사용시
- 그냥 처음부터 다 읽고 조건으로 필터링 → I/O 단순화
- 통계 정보 기반
- MySQL 은 테이블 과 인덱스에 대해 통계 정보를 유지한다
- 시스템 테이블
information_schema.tables/information_schema.statistics을 통해 통계 정보를 볼 수 있다
- 시스템 테이블
- 이걸 기반으로 실행 계획을 세우고, 예상되는 비용(cost)이 더 적은 쪽을 선택
- 하지만 이 통계 정보가 오래되었거나, 실제 데이터 분포와 다르다면,
- 풀 테이블 스캔이 더 빠르다고 오판할 수 있다 → 이럴땐 ex.
ANALYZE TABLE employees로 통계를 갱신하는 것도 방법
- MySQL 은 테이블 과 인덱스에 대해 통계 정보를 유지한다
- 순차 I/O vs 랜덤 I/O 차이로 인해 인덱스를 사용하지 않을 수 있음
- 풀 테이블 스캔 = 순차 I/O
- 테이블은 디스크에서 데이터 페이지를 순서대로 읽을 수 있음 → 순차 I/O
- 디스크 또는 버퍼 풀에서 한 번에 블록 단위로 읽을 수 있으므로 매우 빠르다
- MySQL 은 read-ahead 를 통해 최적화 → 처음에는 페이지를 1개 씩 들고 오다가 나중에는 2개 씩, 4개 씩 데이터 페이지를 들고오는 방식
- 인덱스 사용 시 = 랜덤 I/O
- 인덱스로 조건을 만족하는 ROW 의 주소를 찾은 후,
- 다시 테이블의 실제 데이터 위치를 랜덤하게 탐색 → 랜덤 I/O
- 풀 테이블 스캔 = 순차 I/O
혹은 인덱스를 활용해도 전체 레코드의 너무 많은 부분을 탐색하는 경우
인덱스가 걸린 컬럼의 유니크 정도가 낮은 경우 등 (카디널리티가 작은 경우)
참고
커버링 인덱스 란 ?
- 인덱스만 보고도 쿼리를 처리할 수 있는 상황을 말한다
즉, 테이블까지 랜덤 I/O 하지 않고도 인덱스만으로 결과를 낼 수 있는 경우
예시로 사원번호(emp_no) 에 대한 인덱스를 걸고 조회할 때 사원번호만 조회한다면
SELECT emp_no FROM employees WHERE emp_no > 10
- 인덱스에 필터 조건 + SELECT 대상 컬럼 모두 포함됨
- 테이블 접근 생략 (랜덤 I/O X)
- 인덱스만으로 빠르게 처리 가능
추가로 PK 혹은 커버링 인덱스 접근 방식은 랜덤 I/O 를 줄이거나 순차 I/O 로 조회할 수 있다
(DB 의 인덱스 구조, 디스크 형식에 따라 다를 수 있음)
그러면 이제 사원(employees) 테이블에 10만건의 데이터를 넣고 실행해보자
데이터를 더 추가해서 아주 데이터 많은 경우에도 인덱스를 사용하지 않고 풀 테이블 스캔을 하는지
사원 데이터 60만건 추가
DELIMITER $$
DROP PROCEDURE IF EXISTS populate_more_employees$$
CREATE PROCEDURE populate_more_employees()
BEGIN
DECLARE i INT DEFAULT 300001;
WHILE i <= 859999 DO
INSERT INTO employees (
emp_no, birth_date, first_name, last_name, gender, hire_date
) VALUES (
i,
DATE_ADD('1970-01-01', INTERVAL FLOOR(RAND() * 15000) DAY),
CONCAT('First', i),
CONCAT('Last', i),
IF(RAND() > 0.5, 'M', 'F'),
DATE_ADD('1995-01-01', INTERVAL FLOOR(RAND() * 10000) DAY)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 실행
CALL populate_more_employees();EXPLAIN SELECT * FROM employees WHERE hire_date > '2022-01-01'
type: range
- 인덱스 범위 스캔이 발생했다는 의미
- 인덱스를 사용하여 특정 범위만 스캔한 경우
- 아래 조건인 경우 발생
>/</BETWEEN/IN(…)등의 조건에서 발생
key: IX_employees_hire_date
- 실제 사용된 인덱스
- 사원 일자(
hire_date) 에 대해 생성한 인덱스를 활용
Extra: Using index condition
- ICP (Index Condition Pushdown) 이 적용되었다는 의미
- 스토리지 레벨에서 인덱스만 보고도 조건을 필터링함
Join
- 각 사원이 속한 부서 조회
- 부서 사원 테이블 (
dept_emp) 테이블 과 사원 (employees) 를 Join
EXPLAIN SELECT * FROM dept_emp JOIN employees ON dept_emp.emp_no = employees.emp_no AND dept_emp.dept_no = 'D005';
부서 사원 테이블 (dept_emp)
type: ref- 인덱스 컬럼을 사용한 비교에서 사용
- 동등 비교 (
=) 를 사용할때 보임 - 비 유니크 인덱스 나 외래키 등을 조건으로 여러 개의 ROW 를 가져오는 경우 사용 (PK, UNIQUE NOT NULL 아님)
- 동등 비교 (
- 인덱스 컬럼을 사용한 비교에서 사용
key: dept_no- 실제 사용된 인덱스는
dept_no인덱스
- 실제 사용된 인덱스는
Extra: Using index condition- ICP 적용됨
사원 테이블 (employees)
-
type: eq_ref- 테이블의 PK 혹은 UNIQUE NOT NULL 컬럼 과 동등 비교로 JOIN 되는 경우 사용
- 인덱스를 통해 ROW 가 하나로 특정되는
- 즉,
PRIMAY_KEY조인을 의미하며 하나의 레코드만 매칭된다
- 테이블의 PK 혹은 UNIQUE NOT NULL 컬럼 과 동등 비교로 JOIN 되는 경우 사용
-
key: PRIMARY- employees 테이블의 PK 를 사용한 것
-
Extra: Null- 추가 최적화가 없다는 의미
동작 방식
- 부서 사원 테이블에서 부서 번호를 통해 조회 및 필터링 (
Index lookup on dept_emp using dept_no)
- 한 번의 루프로 쭉 순회를 하면서 34,218 개의 결과물을 가져옴
- `dept_emp.dept_no='D005' 조건으로 인덱스 검색
- 사용 인덱스:
dept_no - cost: 9542 (예상 비용)
- rows=86994: 옵티마이저가 잘못 추정함 (실제는 34,218개인데 두 배로 추정)
- actual time=0.838..69.6: 인덱스 시작 시간 ~ 종료 시간 (총 69ms)
- rows=34218: 실제 결과 row 수
- loops=1: 1회 인덱스 조회로 모든 조건 row 가져옴
dept_emp테이블에서dept_no='D005'조건을 인덱스로 빠르게 가져옴.
- 사원 테이블에 대한 PK 조회 (
Single-row index lookup on employees using PRIMARY)
- PK 를 통한 참조를 하므로 한 번의 검색해서 하나의 결과를 가져온다
- 위 동작과정을 앞에서 나왔던 결과를 기준으로 34,218 번의 반복 수행을 하게된다
- 참고로 cost 는 MySQL 에서 버퍼 풀 (인메모리) 에 저장된 데이터 페이지에 한 번 접근할때 MySQL 이 추산하는 비용을 의미한다
- employees.emp_no로 PK(primary key) 인덱스 조회 (빠름)
- 각 emp_no마다 한 건씩 조회됨
- cost=0.25: 한 건 조회 예상 비용
- actual time=0.00153..0.00155: 한 건 조회 평균 0.00002ms (20 ns 나노초)
- rows=1: 1건씩만 나옴 (PK니까 당연)
- loops=34218: 위에서 나온 34,218건에 대해 반복 조회
dept_emp테이블에서dept_no='D005'조건을 인덱스로 빠르게 가져옴.
Nested loop inner join- 조인 방식: Nested Loop Join (중첩 반복)
- cost: MySQL 옵티마이저가 추정한 총 실행 비용
- rows=86994: 추정 결과 건수 (조인 결과 예상)
- actual time=2.6..714: 실제 실행 시간 (시작 ~ 끝까지 2.6ms ~ 714ms)
- rows=64433: 실제 반환된 row 수
- loops=1: 루프 1번 → 조인 전체를 대표하는 연산, 한 번만 실행되었다는 의미 (조인 연산을 한번 시작해서 한 세트 완성, 그 하위는 여러번 반복)
type
위 컬럼에는 각 종류에 따라 성능에 최적화된 순서가 존재한다
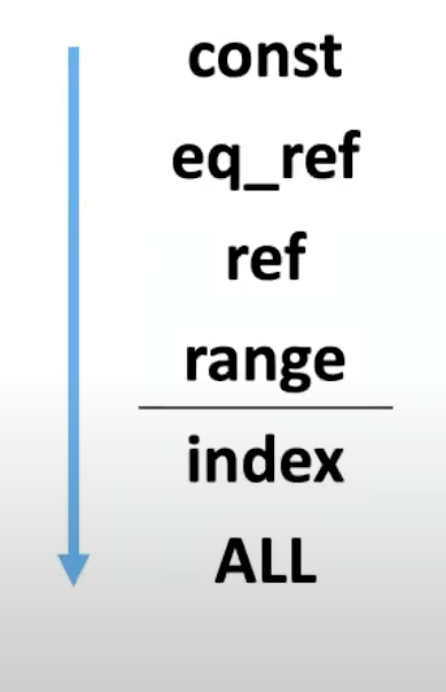
위 그림이 각 type 에 대한 종류인데
아래로 갈수록 성능에 안좋은 영향이 생기는 type 이다
index와ALL에 대해서는 주의깊게 사용해야 한다
type: index
- 인덱스 테이블 풀 스캔
- 인덱스를 사용하므로 말만 들으면 인덱스를 잘 활용하는 구나 라고 생각할 수 있다
- 그러나 아래 처럼 여러가지 경우에 따라 성능에 안좋은 영향을 끼친다!
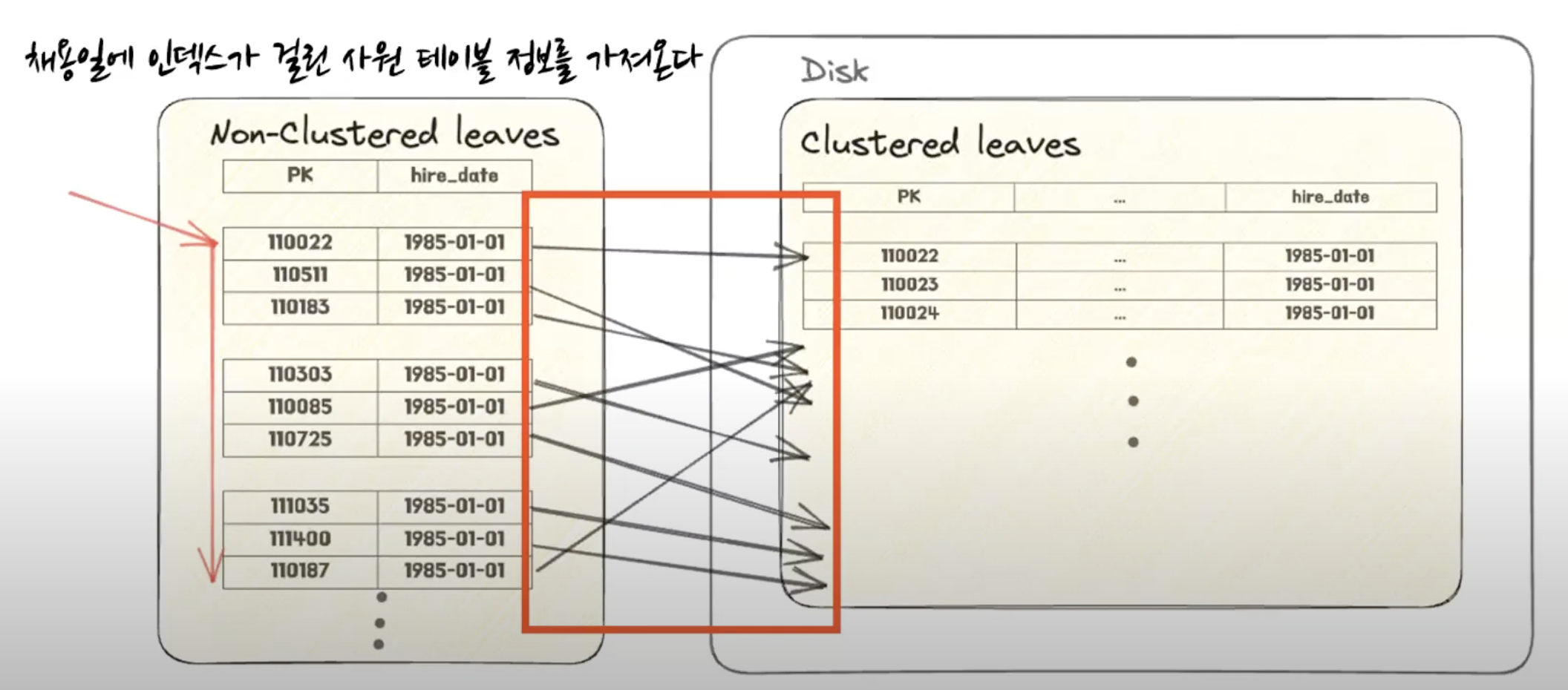{kind=link}
위 그림은 인덱스 (Non-Clustered) 테이블에 대한 풀 스캔을 의미한다
인덱스 테이블 (Non-Clustered Leaf) 들을 순차적으로 쭉 순회한다 → 사실 이 행동 자체는 크게 문제되지 않는다
그러나 인덱스 테이블 (Non-Clustered) 에 없는 컬럼을 조회한다고 한다면 실제 데이터 레코드까지 찾아가서 참조해야하는 경우 중간에 Disk I/O 가 발생한다
그러므로 인덱스 테이블 풀 스캔을 할때는
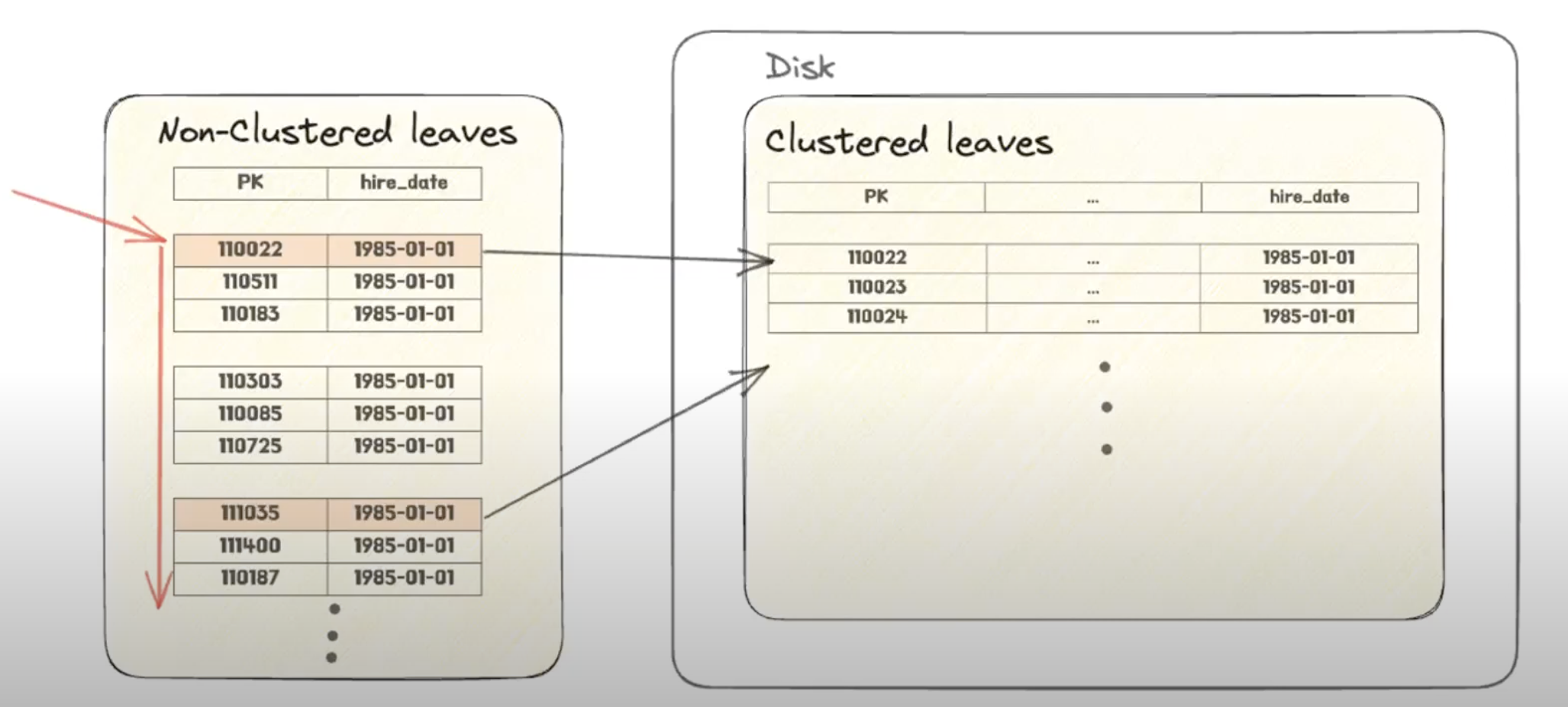
위 그림처럼 인덱스 테이블을 순차적으로 쭉 순회하지만 필터링 조건에 의해 몇개만 데이터 레코드까지 참조하는 경우
혹은
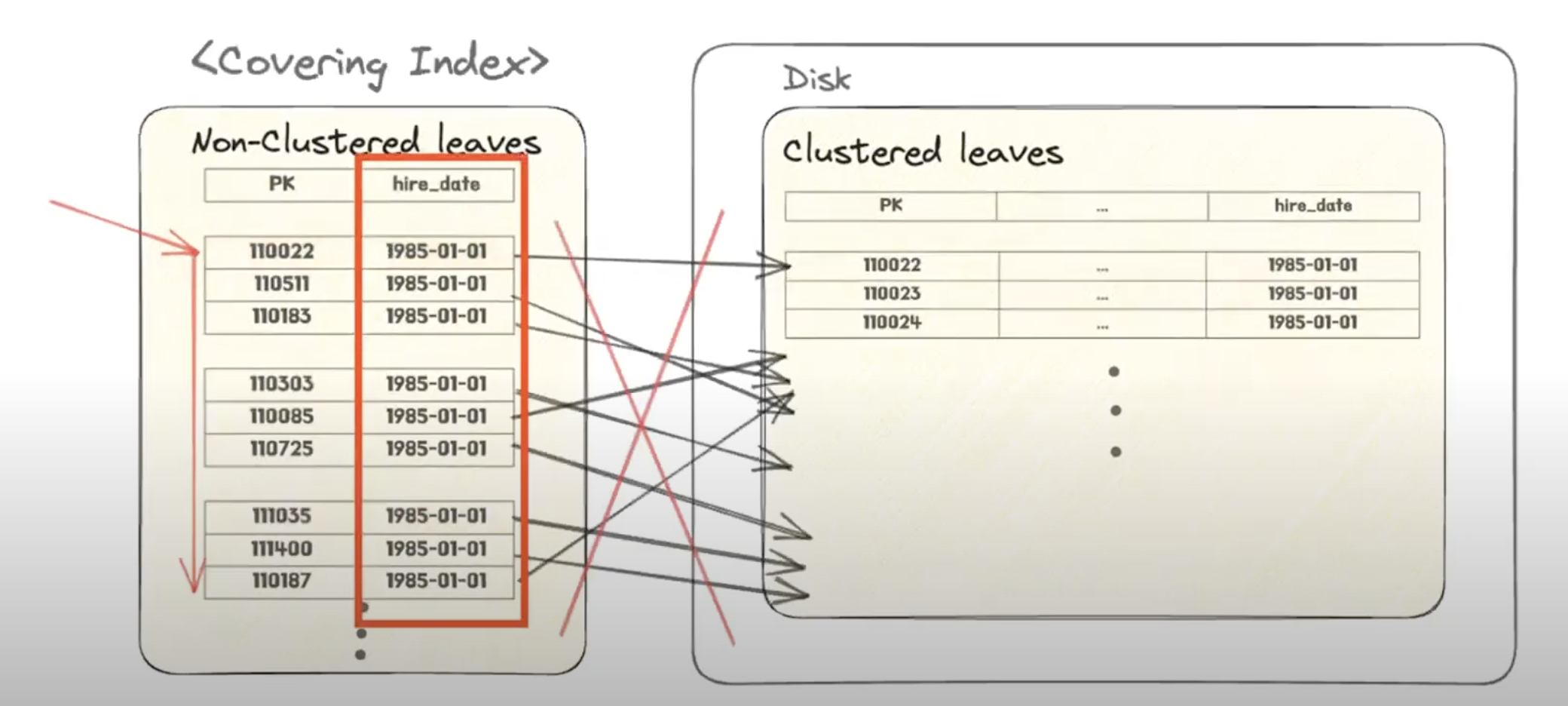
위에서 이야기했던 커버링 인덱스를 통해 실제 데이터 레코드까지 조회하지 않고 인덱스 테이블만으로 결과물을 도출할 수 있는 경우에는 Disk I/O 가 많이 발생하지 않으므로 괜찮은 성능을 보인다
참고 - 실행 계획 수립은 싼 작업이 아니다
MySQL 은 수립한 실행 계획을 커넥션 내에서만 캐싱하며 재사용한다
그래서 다른 커넥션으로 똑같은 쿼리를 보내도 MySQL 은 새로운 실행 계획을 계산해야한다
이 과정에서 옵티마이저는 직접 인덱스 몇개를 탐색해 샘플링하는 작업을 하게되는데 이를 Index Dive 라고 한다
그렇지만 실제로 보내는 쿼리들은 조합이 아주 다양하고 많은 인덱스를 사용해야하는 경우에는 실행 계획을 수립하는 과정에서 굉장히 많은 비용이 소모된다
심지어는 쿼리 자체를 수행하는 것 보다 실행 계획을 수립하는데 리소스가 더 많이 들기도 하는 경우가 있다
혹은
실행 계획 수립에는 할당된 시스템 메모리 비용이 정해져 있는데 해당 메모리를 초과해서 실행 계획을 수립하다가 실행 계획 자체를 포기하고 풀 테이블 스캔을 하기도 한다고 함
참조)