근황

저를 기다리신 분이 계신지 모르겠지만.. 오랜만입니다! 세상이 시끄러운데 잘 지내셨는지 모르겠네요 ㅎㅎ.. 저는 바쁘게 살아가고 있습니다! 저번 달부터 운이 좋게도 인턴십을 진행하고 있어서 회사 적응과 과제를 동시에 진행하며 정신없이 살아가고 있습니다!
인턴십을 하면서 정말 많은 것들을 배우고 있습니다. 단순 기술 습득뿐만이 아니라 현재 마주한 상황에서 최적의 기술을 선택하고 왜 그 기술을 선택했는지 근거를 찾아가며 가장 효율적인 기술을 선택하는 방법에 대해서 배우고 있습니다. 사실 이게 제일 쉽지 않아요. 열정과 도전으로 어려운 기술을 멘토님들 앞에서 열심히 설명했지만, 멘토님들의 날카로운 지적에 낯부끄러웠던 적이 한 두번이 아닙니다 ㅎㅎ.. 정말 개발은 끝이 없는 거 같습니다.. ㅠ
인턴 동기도 너무 좋은 분을 만났습니다. 저보다 형이신데 정말 친절하시고, 서로에게 도움이 되고자 노력하고 있습니다. 좋은 멘토님들도 만났고, 인턴 동기도 만나서 힘든 과제 속에서도 즐겁게 살아가고 있습니다.
아마도.. 이 글을 보시는 많은 분들이 저와 같은 취준생이실 것이라고 생각이 드는데요. 우리 모두 화이팅입니다! 이만 각설하고! 본론을 시작해보도록 하겠습니다!
WebFlux를 쓰게 된 계기
사내 RAG 구축하기
Spring WebFlux는 이번 인턴 과제 중 인턴 동기와 함께 두 명이서 사내 RAG 구축 프로젝트를 진행하면서 적용해보았습니다. 왜 spring webflux를 선택했는지 구체적으로 설명하기 전에 프로젝트의 요구사항부터 간단하게 짚고 넘어가겠습니다.
사내 RAG 프로젝트 요구사항
- 데이터는 제공, 전처리, 임베딩 등을 적용하여 RAG 프로젝트 구축하기
- OpenAI API를 활용
- 기술 스택 자유(Spring 추천)
- 실제 배포까지 올라가야 하며, 실제 회사에서 사용 가능성도 염두에 두기
- 참고 사이트: oo.ai
RAG는 검색 증강 엔진의 약자로, LLM을 통해서 응답을 얻지만 신뢰할 수 있는 데이터를 기반으로 응답을 생성하는 기술입니다. 전문성이 필요하거나, 보다 정확한 정보가 필요한 부분에서 유용한 기술이라고 생각합니다. 특히, 회사에서 유용할 것이라고 생각합니다. 회사의 내부 데이터를 통해서 업무 친화적인 챗봇을 만들 수 있으니까요!
RAG의 흐름 속에서 찾은 논블로킹의 필요성
RAG는 다음과 같은 흐름을 갖고 있습니다.
RAG의 흐름
- 신뢰할 수 있는 데이터를 임베딩하여 벡터 DB에 저장
- 사용자의 질문
- 질문 임베딩을 통한 벡터화
- 벡터화된 질문을 통한 벡터 DB 검색, 유사도 높은 데이터 조회
- 질문과 검색한 데이터를 기반으로 LLM을 통한 응답 생성
프로젝트의 요구사항 중 OpenAI API를 사용하는 것이 있기 때문에 임베딩과 응답 생성의 경우에는 OpenAI API를 사용했습니다.
또한, 벡터 DB의 경우에는 다양한 벡터 DB 중, Docker로 쉽게 배포가 가능하며, RestAPI를 통해서 데이터 읽기 쓰기가 가능한 Qdrant를 선택하게 되었습니다.
RAG의 흐름을 잘 보시면, 0번의 경우에는 사람들이 잘 사용하지 않는 새벽시간이나 batch 혹은 스케줄러를 통해서 작업을 하면 되기 때문에 제외한다고 하더라도, 1,2,3,4번 모두 이전 작업에 굉장히 의존적인 작업입니다. 1번이 실패한다면, 2번도 실패하는 것인거죠.
저는 이러한 이유 때문에 당연히 로직을 동기로 작업을 해야겠다고 생각했었습니다. 하지만, 조금 더 생각을 해보니 동기와 비동기를 고민하는 것보다 동기를 적용하면서 자연스레 발생하는 블로킹에 대해서 고민하게 되었습니다.
블로킹이 고민된 이유
동기로 로직을 사용하게 되면 자연스레 블로킹이 따라옵니다.(물론 논블로킹을 적용할 수 있다고는 알고 있습니다. 다만, 굉장히 어색하기 때문에 잘 쓰지 않는다고 알고 있습니다.) 동기는 특정 작업의 결과를 기다려야하기 때문에 어떤 작업에 결과를 요청하고 요청한 스레드는 블로킹되어 대기상태에 들어가거나 IDLE한 상태로 유지되게 됩니다.
그러면 여기서 제가 하는 프로젝트의 특징을 확인해야 합니다. 저는 이번 RAG를 OpenAI API와 벡터 DB를 통해서 구현해야 합니다. OpenAI API를 써보신 분들은 아시겠지만, 아무래도 AI를 통해서 응답을 생성하다보니 응답시간이 꽤 긴 편입니다. 상황에 따라 다르지만, 보통의 API 응답시간이 ms 단위로 끝나는 반면 OpenAI API는 초 단위로 끝나기 때문에 상당히 느리다는 것을 알 수 있습니다.
또한 사용자의 질문에 응답하기 위해서 필요한 I/O 작업이 무려 4개나 있습니다. 그 중 OpenAI API를 사용해야 하는 부분은 3개가 있습니다. 따라서 모든 요청에 블로킹이 작동하는 동기로 로직을 작성한다면 상당히 느린 응답속도가 나올 것이라는 것은 어느정도 자명한 사실이었습니다.
논블로킹이 합리적이라고 생각한 이유
논블로킹이 합리적이라고 생각한 이유는 블로킹에서 발생하는 단점을 상쇄할 수 있다고 생각했기 때문입니다.
- 네트워크 I/O를 필요로 하는 로직이 많고, 하나의 네트워크 I/O의 응답시간이 굉장히 느리다.
이런 상황에서 블로킹을 적용하게 되면, 느린 응답시간을 모두 리소스를 점유한 스레드가 wait상태로 유지되게 됩니다. 이는 리소스가 낭비되는 원인이 되며 요청이 몰릴 경우에 성능 저하로 이어질 수 있습니다. - 논블로킹을 적용하게 되면, 처리량이 올라갈 뿐만 아니라 동일한 개수의 요청을 처리하기 위해 필요한 스레드의 수가 적어진다.
논블로킹은 I/O 작업을 만나는 경우에 요청을 전달한 뒤에 스레드의 점유를 해제합니다. I/O 작업이 종료된 이후에는 이전에 지정한 콜백을 통해서 본래 요청에 결과가 전달되게 되며, 이때 요청은 기존 스레드 혹은 다른 스레드가 이어 받아 남은 요청을 처리할 수 있습니다.
얼핏 보면, 스레드의 사용이 더 많이 발생하는 거 아닌가 싶지만, 작업 10개를 동기 & 블로킹으로 처리한다면 필요한 스레드는 10개입니다. 하지만, 비동기 & 논블로킹으로 처리하게 되면 앞선 요청을 완료한 스레드가 뒷선 요청을 처리할 수 있기 때문에 10개 이하의 스레드가 사용됩니다.
이렇게 RAG 프로젝트의 특징과 상황을 고려했을 때, 논블로킹을 적용하게 된다면 동일한 리소스에서 더 높은 처리량을 갖는 서버를 구축할 수 있다고 생각하여 Spring Webflux를 사용 기술로 결정하게 되었습니다.
💡 동기(Synchronous) vs 비동기(Asynchronous)
동기와 비동기의 차이는 작업의 결과를 대하는 방식에 있습니다.
- 동기는 작업의 결과가 궁금하기 때문에, 결과가 나올 때까지 기다립니다.
- 비동기는 결과보다 전체 흐름이 더 중요하기 때문에, 작업을 위임한 뒤 본인의 일을 먼저 진행합니다.
💡 블로킹(Blocking) vs 논블로킹(Non-Blocking)
블로킹과 논블로킹은 자원(I/O 등)을 사용하는 방식의 차이입니다.
- 블로킹은 I/O 같은 작업을 요청한 뒤에도 스레드가 자원을 계속 점유하며 대기합니다.
- 논블로킹은 작업을 요청한 뒤 자원을 릴리즈하고 다른 작업을 수행합니다.
결과가 준비되면 콜백 등을 통해 결과를 전달받습니다.
Spring Webflux, 시작부터 알아봅시다
Reactive Stream
Reactitve Stream은 비동기적으로 데이터 스트림을 처리할 때, 소비자가 감당할 수 있는 만큼만 데이터를 생산하도록 표준화한 명세입니다.
Reactive Stream의 두 가지의 특징
- 비동기 스트림 처리(Asynchronous Stream Processing)
- 백 프레셔(Back-pressure)
비동기 스트림 처리
Reactive Stream은 데이터를 비동기적으로 처리합니다. 네트워크, 파일, 데이터베이스 I/O 작업의 종료를 기다리지 않고, 콜백을 지정한 뒤, 해당 요청을 완료합니다. I/O 작업이 끝나면, 지정된 콜백을 통해서 스트림 데이터를 수신하게 됩니다. 이때 스트림 데이터의 끝을 알기 위해 onNext()와 onComplete()를 활용하여 적절하게 처리합니다.
Back-pressure
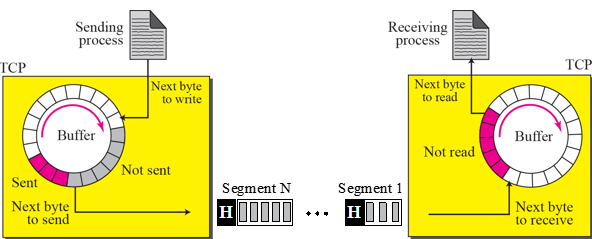
컴퓨터 네트워크를 아시는 분들은 이해가 빠르실 것 같습니다. 서로 다른 두 노드가 통신을 할 때, send buffer와 receive buffer를 통해서 데이터를 송수신합니다. 이때, 송신측의 데이터 생산(전송) 속도가 더 빨라서 수신측의 데이터 소비(수용) 속도를 추월하는 경우에 수신 측의 receive buffer가 가득 차 overflow가 발생하게 됩니다.
백프레셔는 이러한 문제점을 해결하기 위해서 수신 측의 데이터 소비 속도에 맞춰 송신 측이 데이터를 전송합니다. 이를 통해 receive buffer의 오버플로우를 방지할 수 있습니다.
핵심 구성 요소 (Reactive Streams API)
Reactive Streams는 아래 4가지 표준 인터페이스로 구성됩니다:
Publisher<T>: 데이터를 발행하는 주체.subscribe()메서드로 구독자를 등록합니다.Subscriber<T>: 데이터를 소비하는 주체.onNext(),onError(),onComplete()등의 콜백을 가집니다.Subscription: Publisher와 Subscriber 간의 계약.request(n)으로 백프레셔를 구현합니다.Processor<T, R>: 중간 처리자. Publisher이면서 동시에 Subscriber 역할도 합니다.
Reactor
Reactor는 Reactive Streams 사양을 구현한 Java 기반 비동기 스트림 처리 라이브러리이자, Spring WebFlux의 핵심 엔진입니다. Reactor에서는 데이터를 Mono<T>와 Flux<T>를 통해 다루고 있습니다.
Mono vs Flux
Mono
Mono<T>는 0개 또는 1개의 데이터를 비동기로 처리하는 타입입니다. 비동기적으로 단일 결과를 반환할 때 사용합니다.
Mono<String> mono = Mono.just("Hello Mono");
mono.subscribe(System.out::println); // 출력: Hello MonoFlux
Flux<T>는 0개 이상의 데이터를 비동기로 처리하는 타입입니다. 비동기적으로 복수 개의 결과를 반환할 때 사용합니다.
Flux<Integer> flux = Flux.just(1, 2, 3, 4);
flux.subscribe(System.out::println); // 출력: 1 2 3 4
Mono<List<T>>는 가능할까?
- List<>를 하나의 객체로 바라보기 때문에 가능합니다.
- 하지만, Flux를 적용하게 되면, subscriber의 request(n)의 크기 만큼 생성할 때 데이터를 전송하여 효율적이지만,
Mono<List<T>>는 그와 상관없이 전체 리스트가 생성이 되야 전송할 수 있습니다.
(backpressure가 적용되지 않습니다.)- 따라서, 해당 데이터 전체를 보내야 유의미한 로직에서는 사용하겠지만, 그 외 경우에는 무의미하다고 생각합니다.
// Flux<T> -> Mono<List<T>> Flux<Integer> flux = Flux.just(1, 2, 3); Mono<List<Integer>> monoList = flux.collectList(); // Mono -> Flux Mono<String> mono = Mono.just("Hello"); Flux<String> fluxFromMono = mono.flux();
Netty
Tomcat vs Netty
많은 사람들의 대다수의 프로젝트가 Spring MVC에 기반한 프로젝트일 것이라고 생각합니다. Spring MVC는 서블릿을 활용하고, 서블릿은 Tomcat을 통해 사용할 수 있습니다.
Netty는 Tomcat과 비슷한 역할을 하는 네트워크 애플리케이션 프레임워크입니다. 하지만 Tomcat과 다른 점은 비동기 이벤트 기반의 네트워크 애플리케이션 프레임워크라는 점이 다릅니다.
Tomcat은 기본적으로 요청마다 스레드를 하나씩 할당하는 반면,
Netty는 이벤트 루프 기반의 적은 수의 스레드로 수천 개의 연결을 효율적으로 처리할 수 있습니다.
| 항목 | Tomcat | Netty |
|---|---|---|
| 용도 | 서블릿 컨테이너 (HTTP 전용) | 범용 네트워크 프레임워크 (HTTP, TCP 등) |
| I/O 모델 | 블로킹 기반 (기본 설정) | 비동기 논블로킹 (Java NIO 기반) |
| 처리 방식 | 요청마다 스레드 할당 | 이벤트 루프 기반 처리 |
| 유연성 | 서블릿 API에 종속 | 저수준에서 자유롭게 설계 가능 |
Event Loop 구조
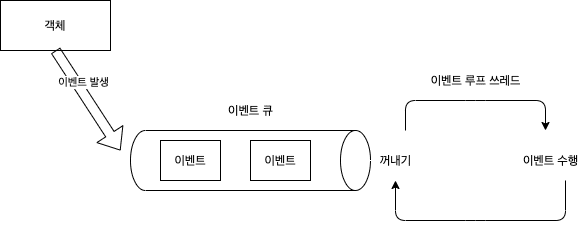
이벤트 루프(Event Loop)는 적은 수의 스레드로 수많은 클라이언트 연결을 감시하고, 이벤트가 발생한 채널만 선택적으로 처리하는 구조입니다.
주요 구성
- EventLoop: 하나의 스레드. Selector를 통해 여러 채널(SocketChannel)을 감시
- Channel: 클라이언트와의 연결을 나타내는 객체. 데이터 수신/송신이 이 채널을 통해 일어남
- Event: 채널에서 발생하는 활동 (데이터 수신, 연결 완료, 연결 종료 등)
처리 흐름
- 클라이언트가 서버에 요청을 보냄 (예: HTTP 요청, TCP 데이터 등)
- 이 요청은 서버의 소켓 채널에 도착하고, 이벤트(읽기/쓰기 등) 가 발생함
- 이벤트 루프는 루프를 돌며 Selector.select()를 호출해 이벤트가 발생한 채널을 감지
- 해당 이벤트에 등록된 핸들러(ChannelHandler) 를 통해 로직을 비동기적으로 실행함
- 이벤트 처리가 끝나면 다시 루프 대기 상태로 돌아감
Spring Webflux
Spring WebFlux는 Spring 5부터 도입된, 비동기 논블로킹 기반의 웹 프레임워크입니다. 기존의 Spring MVC가 서블릿 기반 + 블로킹 처리였다면,
WebFlux는 Reactive Streams 기반 + 논블로킹 처리를 지향합니다.
Spring MVC vs Spring Webflux
| 항목 | Spring MVC | Spring WebFlux |
|---|---|---|
| 스레드 처리 방식 | 요청마다 스레드 하나 | 적은 스레드로 수천 요청 처리 |
| I/O 모델 | 동기 / 블로킹 | 비동기 / 논블로킹 |
| 기본 서버 | Tomcat 기반 | Netty (기본), Undertow, 서블릿 3.1도 지원 |
| 성능 | 성능 한계 있음 | 고성능 / 고동시성 요구에 대응 가능 |
Webflux의 구성 요소
| 구성 요소 | 설명 |
|---|---|
Mono<T> / Flux<T> | 비동기 데이터 처리 단위 (Reactor 기반) |
@RestController / @GetMapping | 익숙한 Spring 스타일의 선언적 컨트롤러 |
WebClient | 논블로킹 HTTP 클라이언트 |
RouterFunction, HandlerFunction | 함수형 라우팅 방식도 지원 |
Reactor Netty | 기본 서버 구현체 (Tomcat도 선택 가능하지만 논블로킹 아님) |
WebFlux의 흐름
- 클라이언트 요청
클라이언트가 HTTP 요청을 보냄 (GET /users)
요청은 TCP 소켓을 통해 서버로 도달
- Reactor Netty 서버 (논블로킹, 이벤트 루프)
WebFlux의 기본 서버는 Reactor Netty
Netty의 이벤트 루프가 요청을 감지하고, 데이터가 수신되면 WebFlux로 전달
- DispatcherHandler (Spring WebFlux 핵심, DispatcherServlet의 역할)
Spring MVC의 DispatcherServlet에 해당
요청을 받아 어떤 핸들러(컨트롤러)를 호출할지 결정
- HandlerMapping
등록된 모든 컨트롤러들을 순회하며 URI/HTTP 메서드에 맞는 핸들러를 찾음
- HandlerAdapter
찾은 컨트롤러 핸들러를 실행 가능한 형태로 감싸서 호출해줌
반환 타입이 Mono, Flux여도 걱정 없이 처리할 수 있도록 함
- @RestController
사용자가 작성한 Controller가 실제로 호출됨
메서드 결과로Mono<T>나Flux<T>를 반환
- Publisher 구독 & 데이터 흐름 시작
DispatcherHandler가 Mono 또는 Flux를 구독 (subscribe())함
내부적으로 onNext(), onComplete()를 통해 데이터가 비동기적으로 흘러감
Mono나 Flux는 lazy하기 때문에, subscribe()가 호출되기 전까지는 실제 실행 안 됨
- 응답 생성 & 전송
구독 결과를 바탕으로 HTTP 응답을 만들고, Netty가 이를 클라이언트로 전송
subscribe()? 난 저거 쓴 적이 없는데?
Reactive Stream부터 계속 나왔던 말이 publisher와 subscribe에 대한 내용입니다. 하지만, 실제로 WebFlux를 작성해본 사람은 의아한 부분이 생길 수 있습니다.
subscribe()? 난 사용한 적이 없는데?retrieve()하면 되는거 아니야?
실제로 저는 저렇게 생각했었고, 단순히 retrieve()에서 처리를 같이 하나보다 생각하고 있었습니다. 하지만 그 이유가 아니었습니다.
WebFlux Controller에서는 subscribe()는 DispatcherHandler에서 호출합니다!
@GetMapping("/proxy")
public Mono<String> callOtherService() {
return webClient.get()
.uri("/other-api")
.retrieve()
.bodyToMono(String.class);
}간단한 WebFlux로 API를 구성해봤습니다. 해당 코드 부분에서는 subscribe()를 호출하지 않았는데도 정상적으로 동작하는 것을 확인할 수 있습니다.
흐름 파악하기
- WebClient가 반환한 Mono는 아직 구독되지 않은 상태입니다. (Lazy)
- 하지만, 이 메서드를 호출한 쪽은 Spring WebFlux DispatcherHandler 입니다.
- 따라서, DispatcherHandler가 Mono을 반환값으로 받으면,
HTTP 응답을 만들기 위해 내부적으로subscribe()를 호출함
반면에, Spring 내부가 아니라 main함수나 기타 로직에서 WebFlux를 사용하게 되면
subscribe()하는 곳이 없기 때문에 의도한 대로 실행되지 않습니다!
| 사용 위치 | subscribe() 호출 주체 | 설명 |
|---|---|---|
| WebFlux Controller 내부 | Spring 내부 (DispatcherHandler) | 반환된 Mono/Flux가 HTTP 응답으로 사용되기 때문 |
| 일반 메서드, main 함수 등 | 개발자가 직접 호출 | subscribe() 없으면 실행되지 않음 |
Spring WebFlux는 완전한 논블로킹 생태계 필수
Spring WebFlux가 논블로킹을 지원하지만, 서버 내부에서 작업하는 DB, 외부 API호출도 논블로킹으로 적용해야 합니다. 아무리 WebFlux를 적용해도 DB 접근이 블로킹이라면, 사실 큰 의미가 없어지기 때문입니다. 따라서, JDBC → R2DBC, RestTemplate → WebClient 등으로 전환이 필요합니다.
다음 포스팅은 WebFlux를 직접 적용해보면서 마주했던 어려움을 어떻게 해결했는지 공유하면서 논블로킹 생태계를 구축하기 위해 했던 노력들을 공유해보겠습니다!
