문제
https://school.programmers.co.kr/learn/courses/30/lessons/42628
다 맞고 나서도 이렇게 찝찝하긴 처음이다 ,,
다른 후기들 보니 테케는 부족하고 효율성 체크도 안 해서 나름대로 최적화에 대해 고민해봤다.
전략 1.
🤔 통과한 코드, BUT 논리적 오류가 존재하지 않을까 ?
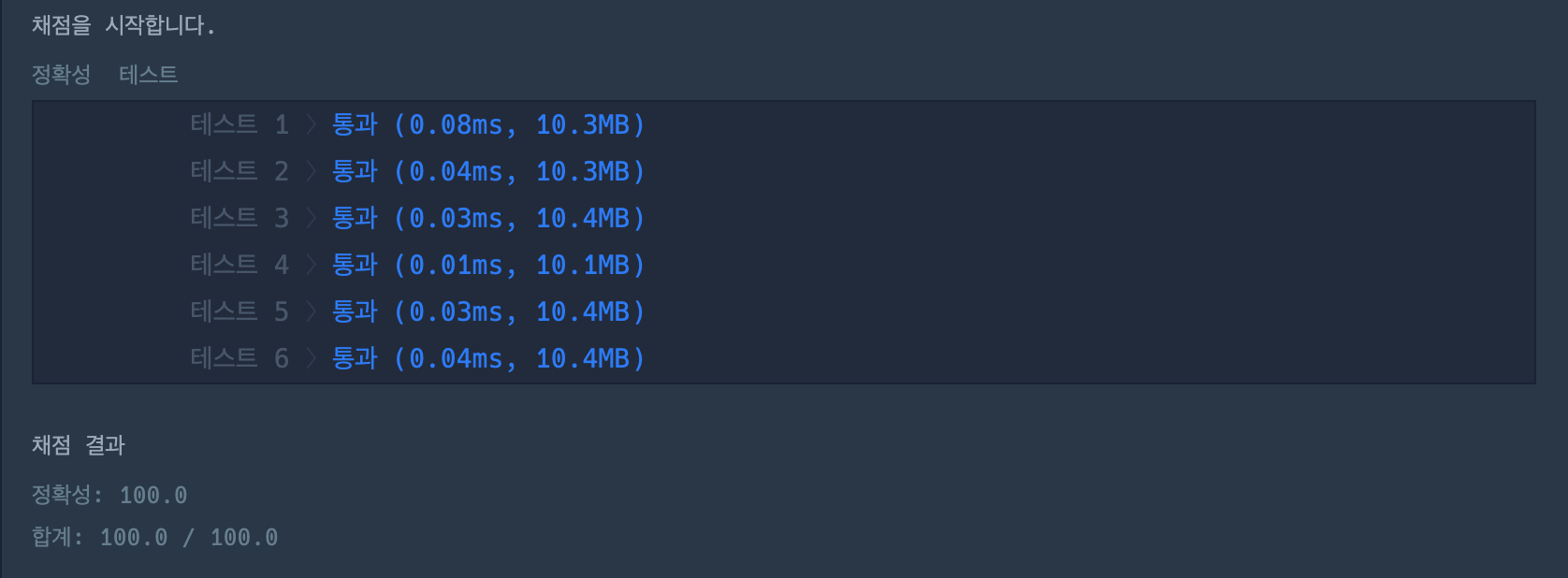
heap 자료구조 두개(min heap, max heap)와 size 변수를 통해 "적당히" 데이터 동기화 고려하면 주어진 테케는 다 통과할 수 있다.
코드
from heapq import heappush, heappop
def solution(operations):
min_q, max_q = [], []
size = 0 # 데이터 정합성 때문
for operation in operations:
op, num = operation.split()
if op == 'I':
num = int(num)
heappush(min_q, num)
heappush(max_q, (-num, num))
size += 1
else: # op == 'D'
if size == 0: # 무시
continue
if num == '1':
heappop(max_q)
else:
heappop(min_q)
size -= 1
if size == 0:
return [0, 0]
# 동기화 문제 -> 교집합 처리 (없으면 TC1 통과 X)
'''
ex.
input : ["I 4", "I 3", "I 2", "I 1", "D 1", "D 1", "D -1", "D -1", "I 5", "I 6"]
output : [6, 5]
'''
max_qs = set(map(lambda x: x[1], max_q))
min_qs = set(min_q)
datas = sorted(list(max_qs & min_qs))
return [datas[-1], datas[0]]여기서 논리적 오류를 유추하기 쉬울 것이다.
바로 이 부분인데,
if num == '1':
heappop(max_q)
else:
heappop(min_q)
size -= 1여기서 size 변수는 사실상 최소한의 동기화 처리에 관여하기 때문에 .. 구체적인 예외 테케는 생각 안 나지만 이미 하나의 큐에서 삭제한 요소를 또 삭제하는 경우가 발생할 수 있을 거 같다.
이렇게 힙큐 두개를 활용하는 방식은 방어적으로 여러 edge case를 고려해서 코딩해야 할 거 같은데 내가 신은 아니니🫠 애초에 좋은 접근 방식이 아닌 거 같다.(출제자 입장에서 이걸 의도한 문제같긴하지만) 데이터 정합성 문제 자체를 없애려면, 자료구조 하나로 처리하는 게 최선이라는 설계에서 출발했다.
전략 2.
🔥 목표: 자료구조 하나로 데이터 동기화 문제는 제거하면서 "빠른" 풀이 방식 적용 !
-
이미 정렬된 리스트에서, 맨 앞을 빼거나 맨 뒤를 빼면 최대/최소값 제거 연산은 해결된다.
-
문제는 삽입 연산이다. 여기서 힙을 사용한 이유가 삽입 연산 시 개발자 입장에서 복잡한 처리없이 O(log n)의 빠른 시간복잡도로 정렬된 리스트를 보장하기 때문인데, 하나의 자료구조에 삽입할 위치를 정직하게 찾는다면 O(n)이 된다
-
그렇다면 적절한 삽입 위치를 빠르게 찾는 방법은 없을까?
👉 이분탐색을 활용해보는 건 어떨까?
bisect 라이브러리의 insort_left를 활용하면 정렬된 리스트에 해당 숫자를 삽입하는 연산을 수행한다.
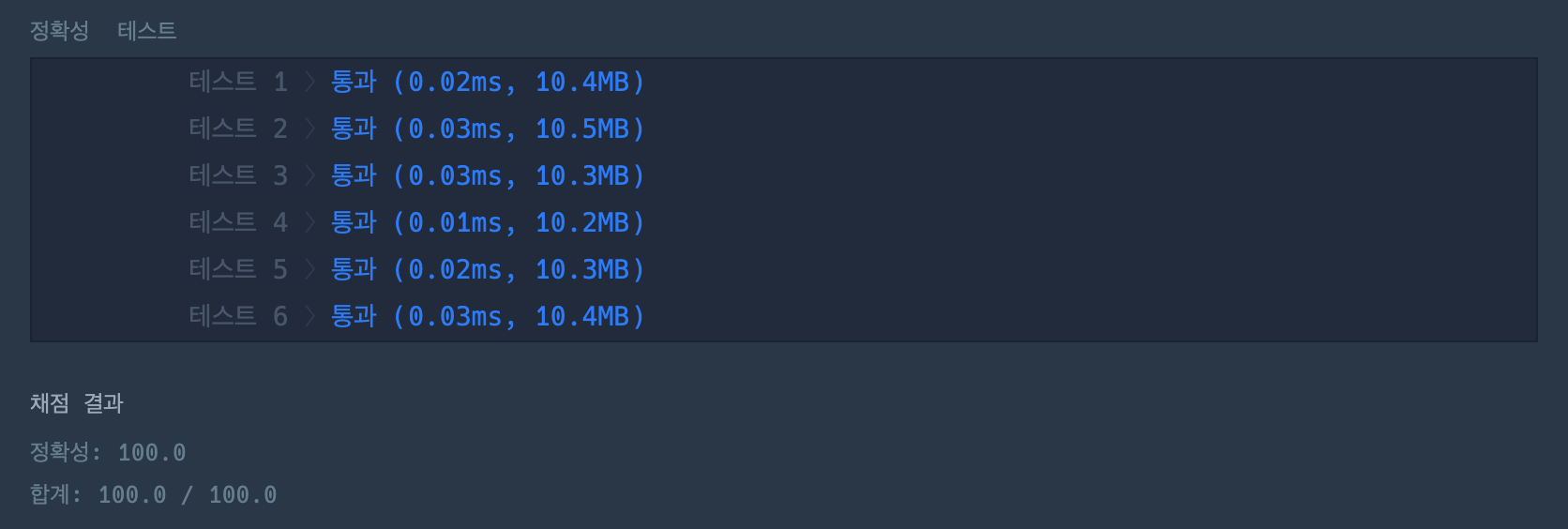
코드
from collections import deque
from bisect import insort_left
def solution(operations):
queue = deque([])
for operation in operations:
op, num = operation.split()
if op == 'I':
num = int(num)
insort_left(queue, num)
else:
if not queue:
continue
if num == '1':
queue.pop()
else:
queue.popleft()
if not queue:
return [0, 0]
return [queue[-1], queue[0]]주어진 빈약한 테케는 다 통과했다.
⚠️ 반전주의
다만.. 다 짜고 나서 여기서도 함정을 발견했는데 .. 🥹
bisect 라이브러리를 활용하니 빠른 탐색이 보장되는 건 맞지만, 리스트에 삽입하는 과정은 어쩔 수 없이 O(n)이 소요될 수밖에 없다고 한다
아 맞네,, 생각해보니 탐색 후 -> 삽입이잖아 흑흑 ..
❔ 참고 : https://stackoverflow.com/questions/53023380/bisect-insort-complexity-not-as-expected
이럴바엔 그냥 파이썬 sorted를 활용하는 게 나을 듯
작은 교훈 (?
역시 뭐든 trade-off가 존재한다 ,,
