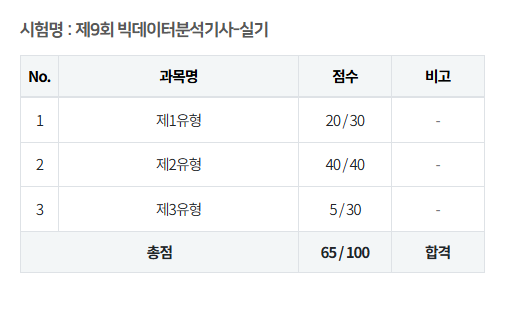
해당 풀이방법은 9회차 실기 시험에서 만점을 취득했던 풀이 방법이지만,
결과가 꼭 같다는 보장은 없으니까 다들 참고만 하시길 바랍니다~~~
또한, 이건 가장 간단한 방법이고 성능을 점차 개선시키는 방법은 따로 포함이 안되어있으니까
추가적으로 공부 하실분은 다른 유튜브나 블로그 참고하셔서 꼭 만점 받으세용😋
📝 사전지식
- 실제 시험 환경에서는
train과test총 2개의 csv 파일이 제공됨
(편의를 위해 X_train, X_test 라고 부름)
- 성능측정을 위해서는 하나의 train 파일이 추가로 필요함
(편의를 위해 Y_train 이라고 부름 => pop으로 데이터 분리)
- 3개의 데이터 중 두개의 train 데이터는 로우수가 같아야함, test는 로우수 다름
(why? 기존 X_train 파일에서 성능측정의 지표를 pop한것이므로 로우수가 같아야함)
📝 2유형 풀이 방법
📌 첫번째, 어떤 모델을 쓸지 결정하기
모델은 분류모델과 회귀모델로 구분되는데
분류모델: 결과가 이분법적으로 확실하게 나뉘는것 (예를들어, 성별)
회귀모델: 결과가 확실하게 나뉘지 않는 것 (예를들어, 가격이나 양)
현재까지 대부분 시험문제는 분류모델로 출제되었으나 회귀모델도 연습을 해 볼 필요가 있음
여기서, 문제에 제시된 성능검증 모델에 따라 분류/회귀를 나누는 사람도 있다고 함!
(아래 예시는 확실하지 않으니 더 서치가 필요합니당)
분류모델 : f1 Score, roc auc
회귀모델 : RMSE, MSE
참고로, 9회차 실기 2유형의 경우 성능검증 모델이 f1 Score 였음
여기서,
분류모델은 RandomForestClassifier를, 회귀모델은 RandomForestRegressor을 사용 할 예정!
📌 두번째, 모델 데이터 불러오기
X_train = pd.read_csv("data/customer_train.csv")
X_test = pd.read_csv("data/customer_test.csv")위 코드는 시험장에서 이미 작성되어있으므로 외워갈 필요는 없음.
X_ 부분은 실제로 붙어있진 않지만 편리하게 구분하기 위해 내가 붙인것이므로 필수 X
📌 세번째, 데이터 파악 및 성능측정을 위한 데이터 분리하기
info 메서드를 사용해서 데이터 형식을 파악
여기서, 파악이 필요한 부분은 결측치와 문자형(object) 데이터
이 두개는 별도로 처리가 필요함

위 사진은 X_train 데이터를 info()문으로 확인한 내용인데,
대부분의 데이터가 3500개의 행으로 구성되어있으나 환불금액이 1205행인것을 확인 할 수 있음
따라서, 위 데이터에서 "환불금액"은 결측치라고 판단 가능
그 외에 object형으로 표시되어있는 "주구매상품, 주구매지점" 또한 별도 처리가 필요한것을 확인 가능
이제 데이터가 파악이 되었으면 성능 측정을 위한 데이터를 따로 빼줘야하는데,
체험환경 문제의 경우 "성별"을 예측해서 제출하라고 했으니 성별 데이터만 따로 뽑아서 Y_train 파일로 만들어주면 된다.
Y_train = X_train.pop('성별')
print(Y_train)이렇게 하면 X_train 파일에서 성별만 똑 띠어둘수있당
참고로 성별은 X_train 파일내에만 있음~
📌 네번째, 데이터 전처리 - 불필요한 컬럼 없애주기, 결측치 없애주기, object 전처리
위 세번째 단계에서 확인한 데이터를 처리 해 줄 필요가 있음
여기서, 불필요한 컬럼 제거 => 결측치 없애기 => object 처리 순서로 진행
단, 전처리는 X_train과 X_test에 동일하게 적용
1) 불필요한 컬럼 제거하기
성능측정에 영향을 주지 않을 것 같은 불필요한 컬럼 제거 필요
여기서 불필요한 컬럼을 골라내는 방식이 서로 말이 다르긴한데..
체험 환경 기준으로는 회원ID 정도를 골라낼 수 있음
해당 데이터는 csv 파일에서 볼 수 있지만 사용자의 회원 ID를 그냥 1씩 증가시킨 값으로 확인 할 수 있음!
더 자세하게 확인 해 보고 싶다면
print(len(train['회원ID'].drop_duplicates()))해당 구문으로 중복을 제거한 값이 총 몇개인지 확인 가능 //결과 : 3500
따라서, 해당값은 성능에 중요한 영향을 주는 값이 아닌것으로 판단하고 제거함!
아마 9회차 실기에서는 따로 제거한 값이 없었던 걸로 기억하는데..
이게 판단 기준이 애매해서 값을 함부로 지우지 않는걸 추천..
이전 시험에서는 지하철역명인가? 그런 데이터를 날리고 성능측정했다가 점수 까였다는말도 본 적이 있음
따라서, 회원 ID처럼 단순히 1씩 증가하는값.. 이런게 아닌 이상 신중하게 제거 하는것을 추천!
일단 체험환경 기준 회원ID는 쓸모없는 값이 맞기 때문에!
# 아래 코드는, 혹시나 회원ID를 추후 결과와 함께 제출해야 하는 경우! 이때는 drop말고 pop으로 따로 떼어놔야함
X_test_cust_id = X_test.pop('회원ID')
# X_test의 회원ID만 따로 떨어진걸 확인하고 싶으면 아래 코드로 확인
print(X_test_cust_id)
X_train = X_train.drop(columns = ['회원ID'])
X_test = X_test.drop(columns = ['회원ID'])
2) 결측치 없애주기
결측치도 사람마다 처리 방법이 다양한데, 9회차 실기의 경우 결측치 자체가 나오지 않았기 때문에 정확한 방법이 어떤건지는 모르겠음
다만, 나는 결측치가 나온다면 그 컬럼을 drop하는 것 보다는 대체값으로 대체하는 방식을 선택하려고 했음!
아래 방식 중 본인이 원하는 방식을 선택하시길..
① 결측치 컬럼 자체를 drop
X_train = X_train.drop(colums = ['환불금액'])
X_test = X_test.drop(colums = ['환불금액'])
# 아래 코드로 결측치 여부 확인 가능 -> 결과가 모두 0이면 결측치 X
print(X_train.isnull().sum())
print(X_test.isnull().sum())② 결측치를 최빈값으로 대체
X_train['환불금액'] = X_train['환불금액'].fillna(X_train['환불금액'].mode()[0])
X_test['환불금액'] = X_test['환불금액'].fillna(X_test['환불금액'].mode()[0])
# 아래 코드로 결측치 여부 확인 가능 -> 결과가 3500행이면 결측치 X
print(X_train.info())
print(X_test.info())③ 결측치의 유형에 따라 최빈값 혹은 평균값으로 대체
# 데이터가 나이/이름/요금 등 연속형일 경우 => 평균값으로 대체
X_train['환불금액'] = X_train['환불금액'].fillna(X_train['환불금액'].mean()[0])
# 데이터가 성별/직급 등 범주형일 경우 => 최빈값으로 대체
X_train['환불금액'] = X_train['환불금액'].fillna(X_train['환불금액'].mode()[0])여기서 혹시나,,
최빈값이 N/A 값일 경우 value_count 해서 가장 많은 유형의 값으로 대체하라는 말도 있으나
아직까지 최빈값이 이런 데이터인 경우는 없는 것 같음
일단 나는 위 예시 중 2번째 예시를 선택하려고 했음 ㅎㅎ
3) object 타입의 데이터를 숫자형 타입의 데이터로 바꾸기
object 형식의 데이터가 있을 경우 해당 데이터를 수치형으로 변환 해 줘야 하는데,
데이터의 처리 방식은 크게 세가지로 나뉜다고 한다
- 데이터의 개수가 너무 많은 경우 :
drop(위에 불필요한 컬럼 제거하기 항목과 연관) - 데이터의 개수가 5개 이하정도 :
one-hot 인코딩 - 데이터의 개수가 꽤 많은 경우 :
Lavel 인코딩
이 또한 애매한 기준이기 때문에..
판단이 애매한 경우에는 모두 Lavel 인코딩으로 처리 하는것이 나을 것 같다
일단 이 방식으로 모든 데이터를 처리하는게 원핫인코딩보다 다소 성능이 저하될 수 있다는 단점이 있긴 하나,
일단 9회차 시험 기준으로는 모든 데이터를 라벨인코딩 처리 해도 만점을 받을 수 있었으니
공부 시간이 부족한 분은 그냥 라벨인코딩만 외워가도 괜찮을 것 같음
단, 시간이 넉넉하신 분은 다양한 방식을 암기 해 가시길!!
# 라벨인코딩 사용방법
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
X_train['주구매상품'] = encoder.fit_transform(X_train['주구매상품'])
X_test['주구매상품'] = encoder.fit_transform(X_test['주구매상품'])
X_train['주구매지점'] = encoder.fit_transform(X_train['주구매지점'])
X_test['주구매지점'] = encoder.fit_transform(X_test['주구매지점'])
# 모든 데이터가 int64 형식이면 성공
print(X_train.info())
print(X_test.info())📌 다섯번째, 모델에 학습시키기
이제 실제 분류/회귀 모델을 사용하여 학습을 시켜주면 된다.
여기서
- 분류모델 :
RandomForestClassifier,XGBClassifier - 회귀모델 :
RandomForestRegressor,XGBRegressor
이렇게 크게 네가지 모델로 분류 되기는 하나,
XGB는 사용하지 않을거다~!!!
모든 문제는 RandomForest를 사용해 학습을 시킬 예정이당
혹시 모를 상황을 대비해 XGB 방식도 공부 해 가라는 말도 있긴 한데, 일단 지금까지의 시험에서는 딱히 RandomForest 방식이 문제가 됐던적은 없어서.. 이건 개인이 선택해야 하는 부분인 것 같당
# RandomForestClassifier 사용방법(분류모델)
from sklearn.ensemble import RandomForestClassifier
model1 = RandomForestClassifier()
model1.fit(X_train, Y_train) # 여기서 fit은 학습시키겠다는 의미
model1_pred = model1.predict(X_test) # X_test를 이용해 예측값을 뽑겠다는 의미
체험환경에서는 고객의 성별을 0,1의 값으로 예측하라고 한 것이니 model1.predict를 사용했는데,
혹시 문제에서 확률을 예측 하라고 한다면 model1.predict_proba를 사용 해 주면 된다~
이걸 사용하면 결과는 0.12 이런식으로 퍼센트로 나온당
또한, 분류모델이 아닌 회귀 모델의 경우 RandomForestClassifier라고 써있는 부분만 RandomForestRegressor로 바꿔주면 됩니닷
# XGBClassifier 사용방법
from xgboost import XGBClassifier
model2 = XGBClassifier()
model2.fit(X_train, Y_train)
model2_pred = model2.predict_proba(X_test)이건 참고용으로 써둔 XGB 방식 사용법..
아 그리고 혹시나

다음과 같은 에러가 발생한다면,
해당 에러는,
Y_train의 데이터가
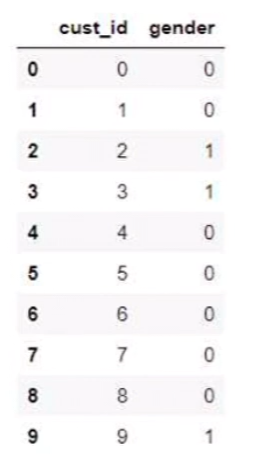
이렇게 일렬로 작성되어 있는게 아닌
[0,1,1,0 ...] 의 형식으로 작성되어 있어야 한다는 오류 메세지이당
# 형식 변경 방법
import numpy as np
from sklearn.ensemble import RandomForestClassifier
model1 = RandomForestClassifier()
model1 = fit(X_train, np.ravel(Y_train))
model1_pred = model1.predict_proba(X_test)
np.ravel 방식으로 형식을 바꿔줄 수 있으니
혹시나 이런 에러가 발생하는 상황을 대비해서 알아가면 좋을 듯 하다~
📌 여섯번째, 결과 제출하기
이제 결과를 csv 파일로 변환하여 제출 해 주면 된다.
# 파일 제출
pd.DataFrame({'gender' : model1_pred}).to_csv('result.csv',index=False)
# 제출결과 확인
result = pd.read_csv("result.csv")
print(result)체험환경 기준 다음 코드로 제출 해 주면 된다~
시험에서는
아래 코드는 예시이며 변수명 등 개인별로 변경하여 활용
pd.DataFrame변수.to_csv("result.csv", index=False)
이런식으로 예시까지는 써있었던 것 같은데,
이건 확실히 기억이 안나니까 제출 방식까지는 잘 외워가시길!!!
제출이 잘 됐는지 안됐는지 긴가민가 할 수 있는데
위 코드로 결과까지 잘 확인했다면 잘 제출 된거니까 걱정 마시길~
아 그리고 혹시나!!
result = pd.DataFrame({'gender' : model1_pred}).to_csv('result.csv',index=False)
print(result)이렇게 하면 결과를 보는 용도지 실제 제출은 아니라고 하니까
result = 이렇게 하고 결과 확인 했다면 꼭 이부분 삭제해서 실제 제출까지 잘 하길 바란당 ㅎㅎ
다들 좋은 결과 있길~🌟
👀 참고자료
