컴파일러 Scanner 기능 구현
#코드(dong_kyu_Scanner.java)
package Automata_Scanner;
import java.io.*;
public class dong_kyu_Scanner {
static public final char EOF = '\255'; // 파일의 끝을 의미하는 EOF 문자 상수
static public final String SPECIAL_CHARS = "!=%&*+-/<>|‘’";
// 두 글자 이상이 하나의 토큰일 수 있는 특수문자들
static public final int ID_LENGTH = 12;
// 컴파일러를 구현할 때에는 명칭의 길이에 제한을 두는 것이 좋다
private String src; // Source Code의 전체 내용을 String으로 저장하기 위한 변수
private Integer idx; // Source Code를 읽을 때 cursor 역할을 하는 변수
/**
* Token을 추출해낼 때 어떤 토큰을 인식하고 있는지 나타내기 위한 State
*/
private enum State {
Initial, Dec, Oct, Hex, IDorKeyword, Operator,
Zero, PreHex, SingleOperator, ConstOperator, Float, Const, Floating,Constant
}
/**
* Mini C Scanner 생성자
* 소스 코드의 파일 경로를 입력받아 src 변수에 String으로 저장하고,
커서를 맨 처음으로 이동
* @param filePath - 소스 코드의 파일 경로
*/
public dong_kyu_Scanner(String filePath) {
src = parseFile(filePath);
idx = 0;
}
/**
* 소스코드 경로를 통해 소스코드 파일을 String으로 읽어 들이는 Method
*
* @param filePath - 읽어올 소스코드 경로
* @return 소스코드 파일의 내용 (String)
*/
private String parseFile(String filePath) {
String src = "", readedString = "";
// src: 소스코드를 저장해놓을 String 변수,
// readedString: 소스코드의 한줄을 담아놓을 String 변수
FileReader fileReader = null; // 소스코드를 읽을 File Reader
try {
fileReader = new FileReader(new File(filePath));
// 파일 경로를 이용해 File Reader 생성
} catch (IOException e) {
// 파일을 읽을 수 없음
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.CannotOpenFile));
return "";
}
BufferedReader reader = new BufferedReader(fileReader);
// BufferedReader 객체를 만들어 소스코드 파일을 읽음
try {
while ((readedString = reader.readLine()) != null) // 파일로부터 한줄 읽음
src += readedString + "\n"; // 한줄 맨뒤에 개행문자 추가
src += EOF; // 파일의 끝을 의미하는 EOF 문자 추가
reader.close();
} catch (IOException e) {
// 파일을 읽을 수 없음
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.CannotOpenFile));
return "";
}
return src;
}
/**
* Core Method
* Source code에서 Token 단위로 String을 나누고 Token 객체를 만들어 반환하는 처리를 한다
*
* @return 인식된 토큰 객체 반환
*/
public Token getToken() {
Token token = new Token();
Token.SymbolType symType = Token.SymbolType.NULL; // Symbol Type을 NULL로 설정
String tokenString = "";
State state = State.Initial;
// 현재 커서로부터 Comment 제거
if (exceptComment()) {
// Comment를 지우는 도중에 ERROR가 발생했을 경우
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.InvalidComment));
return token;
}
while (!isEOF(idx)) { // 소스코드를 전부 읽을때 까지 계속
char c = src.charAt(idx++); // 커서로부터 글자 하나를 읽고 커서를 한칸 이동
**if(state == state.SingleOperator)
state = state.Const;**
if (Character.isWhitespace(c)) { // white space (needs trimming)
if(state != State.Initial)
break; // 만약 글자들을 인식하고 있었다면 그대로 종결
else
continue;
} else if (isSingleSpecialToken(c)) {
// single operator ( '(', ')', '{', '}', ',', '[', ']', ';', EOF )
if (state == State.Initial) { // 처음부터 1글자짜리
state = State.SingleOperator;
tokenString = String.valueOf(c);
} else {
--idx;
}
break;
} **else if (isConstOperator(c)){
state = state.SingleOperator;
}**
else if (isSpecialChar(c)) {
// 1글자짜리 연산자가 아닌 2글자 이상의 연산자가 될 수 있는 연산자일 경우
if (state != State.Initial && state != State.Operator) {
--idx;
break;
}
state = State.Operator;
} else if (state == State.Initial && c == '0') { // Zero를 인식할 경우
state = State.Zero;
} else if (Character.isDigit(c)) { // 숫자를 인식한 경우
if (state == State.Initial) // 아무것도 인식하지 않았을 경우, 10진수로 취급
state = State.Dec;
else if (state == State.Zero) // 숫자 0을 인식하고 있었을 경우, 8진수로 취급
state = State.Oct;
else if (state == State.PreHex) // 0x 까지 인식하고 있었을 경우, 16진수로 취급
state = State.Hex;
**else if (state == state.Floating)
state = state.Float;
else if (state == state.Const)
state = state.Const;**
else if (state == State.Operator) {
// 연산자가 나온 뒤 숫자가 나올경우 while문 탈출
--idx;
break;
}
}
else if (state == State.Zero && c == 'x') { // 0x까지 인식 했을 경우
state = State.PreHex;
} **else if (c == '.'){
state = state.Floating;**
} else if (Character.isAlphabetic(c) || c == '_') {
// underscore 혹은 알파벳을 인식했을 경우
if (state != State.Initial && state != State.IDorKeyword) {
// 명칭 혹은 키워드가 아닌 토큰을 인식하는 중일 경우 while문 탈출
--idx;
break;
}
**if(state == State.Const)
state = state.Const;**
else
state = State.IDorKeyword; // 명칭 혹은 키워드 인식
}
tokenString += String.valueOf(c); // 토큰 String에 글자 추가
}
symType = getSymbolType(state);
// 인식한 state로부터 토큰이 어떤 값을 의미하는지 대분류
if (symType == Token.SymbolType.IDorKeyword && tokenString.length() > ID_LENGTH) {
// 명칭의 길이가 제한을 넘어갈 경우 에러로 처리
// ERROR : 명칭의 길이 초과
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.AboveIDLimit));
return token;
}
token.setSymbol(tokenString, symType);
// tokenString과 함께 대분류한 타입을 전달하여 token을 세팅
return token; // 인식한 token을 반환
}
/**
* 커서가 파일의 끝을 가리키고 있는지 확인하는 Method
* 즉, 더이상 읽을 문자가 없는지 확인하는 Method
*
* @param idx - 확인할 위치
* @return 더이상 읽을 문자가 없으면 true, 아니면 false
*/
private boolean isEOF(int idx) {
return idx >= src.length();
}
/**
* 문자가 특수문자(1글자 연산자 제외)인지 확인하는 Method
*
* @param c - 확인의 대상 문자
* @return 특수문자(1글자 연산자 제외)일 경우 true 반환, 아닐경우 false 반환
*/
private boolean isSpecialChar(char c) {
for (int i = 0; i < SPECIAL_CHARS.length(); ++i)
if (SPECIAL_CHARS.charAt(i) == c)
return true;
return false;
}
/**
* 문자가 1글자 연산자인지 확인하는 Method
*
* @param c - 확인의 대상 문자
* @return 1글자 연산자일 경우 true 반환, 아닐경우 false 반환
*/
private boolean isSingleSpecialToken(char c) {
switch (c) {
case '(': case ')': case ',': case ';':
case '[': case ']': case '{': case '}':
case EOF:
return true;
default:
return false;
}
}
**private boolean isConstOperator(char c){
switch(c){
case '‘': case '’':
return true;
default:
return false;
}
}**
/**
* 추출한 token의 타입이 어떤 타입인지 state에 따라 분류
*
* @param s - 인식된 state
* @return state에 해당하는 심볼 타입
*/
private Token.SymbolType getSymbolType(State s) {
switch (s) {
// 숫자일 경우 (10진수, 8진수, 16진수, 0)
case Dec:
case Oct:
case Hex:
case Zero:
return Token.SymbolType.Digit;
// 명칭 혹은 키워드일 경우
case IDorKeyword:
return Token.SymbolType.IDorKeyword;
// 연산자일 경우
case Operator:
case SingleOperator:
return Token.SymbolType.Operator;
// 종결상태가 아닌 State의 경우 NULL Type을 반환 (인식실패)
case Initial:
case PreHex:
**case Floating:**
default:
return Token.SymbolType.NULL;
**case Float:
return Token.SymbolType.Float;
case Const:
return Token.SymbolType.Const;**
}
}
/**
* 현재 소스코드 파일에 대한 커서(idx)로부터 유효한 토큰이 나올 때까지
주석을 무시하는 Method
* @return block comment에 에러가 있을 경우 true, 아니면 false 반환
*/
**private boolean exceptComment() {
char c;
// 커서로부터 whitespace 문자들 모두 무시
while (!isEOF(idx) && Character.isWhitespace(src.charAt(idx))) idx++;
if (isEOF(idx)) return false;
// whitespace 문자들을 모두 무시했는데 파일의 끝일 경우 성공적으로 주석 제거를 했다고 반환
if (src.charAt(idx) == '/') { // '/'가 나올 경우
if (src.charAt(idx+1) == '/') { // Line Comment
idx += 2; // "//" 다음 문자로 커서 이동
while (!isEOF(idx) && src.charAt(idx) != '\n') idx++;
// 개행문자 혹은 EOF 문자가 나올 때까지 커서 이동
if (!isEOF(idx)) idx += 1;
// 개행문자 다음에 문자가 있을 경우, 그 문자로 커서 이동
} else if (src.charAt(idx+1) == '?') { // Block Comment
idx += 2; // "/?" 다음 문자로 커서 이동
while (src.charAt(idx) != '?' && src.charAt(idx+1) != '/') {
// ?/가 나올때 까지
if (isEOF(idx+1)) return true;
// 불완전한 block comment이므로 에러가 있다고 반화
idx++;
}
idx += 2; // "?/" 다음 문자로 커서 이동
}
}
return false; // 에러가 없이 성공적으로 주석 제거
}
}**코드(Token.java)
package Automata_Scanner;
public class Token {
/**
* Mini C Scanner 객체에서 인식한 Token의 Symbol 타입 (대분류)
*/
public enum SymbolType {
Operator, IDorKeyword, Digit, NULL, Const, Float
}
/**
* Token의 키워드나 명칭, 연산자를 식별하기 위한 Symbol (소분류)
*/
**public enum TokenSymbol {
NULL, Empty, Empty2, EOF, ID, Number3, Number, Number2, Empty3, Empty4,
empty5, Plus, Minus, Mul, Div, Mod, Assign,
Not, And, Or, Equal, NotEqu, Less, Great, Lesser, Greater,
empty6, empty7, empty8, empty9, empty10, LBracket, RBracket,
LBrace, RBrace, LParen, RParen, Comma,
Semicolon, LQuote, RQuote, If, While, For, Const, Int, Float, Else, Return,
Void, Break, Continue, Char
}**
private TokenSymbol symbol;
// Token이 가진 Symbol (Symbol에 상응하는 정수를 추출해낼 수 있다)
private String val; // 명칭 혹은 숫자일 경우 그 값을 저장
private String tokenString; // 인식한 토큰의 원시 String
/**
* 생성자
* 각각의 멤버변수들을 NULL로 초기화한다.
*/
public Token() {
symbol = TokenSymbol.NULL;
val = "0";
tokenString = "NULL";
}
**private boolean isID(String token){
if(token.startsWith("_") || Character.isUpperCase(token.charAt(0))){
return true;
}
for(int i = 0; i < token.length(); i++) {
if (Character.isLowerCase(token.charAt(i))) {
return true;
}
}
return false;
}**
/**
* 키워드나 명칭을 입력받았을 때, 그 String이 키워드인지 명칭인지 구분하는 메소드
* 키워드라면 어떤 키워드인지 Symbol을 할당
*
* @param token - Symbol을 구분할 토큰 String
* @return 구분된 토큰 Symbol
*/
private TokenSymbol getIDorKeywordSymbol(String token) {
switch (token) {
// Keyword
case "const": return TokenSymbol.Const;
case "else": return TokenSymbol.Else;
case "if": return TokenSymbol.If;
case "int": return TokenSymbol.Int;
case "return": return TokenSymbol.Return;
case "void": return TokenSymbol.Void;
case "while": return TokenSymbol.While;
case "float": return TokenSymbol.Float;
case "for": return TokenSymbol.For;
case "break": return TokenSymbol.Break;
case "continue": return TokenSymbol.Continue;
case "char": return TokenSymbol.Char;
// ID
default:
**if(isID(token))
return TokenSymbol.ID;
else
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.InvalidID));
return TokenSymbol.NULL;**
}
}
/**
* 입력받은 토큰 String이 연산자라면 어떤 연산자인지 구분하기 위한 메소드
*
* @param token - Symbol을 구분할 토큰 String
* @return 구분된 토큰 Symbol (연산자)
*/
**private TokenSymbol getOperatorSymbol(String token) {
switch (token) {
case "+": return TokenSymbol.Plus;
case "-": return TokenSymbol.Minus;
case "*": return TokenSymbol.Mul;
case "/": return TokenSymbol.Div;
case "%": return TokenSymbol.Mod;
case "=": return TokenSymbol.Assign;
case "!": return TokenSymbol.Not;
case "&&": return TokenSymbol.And;
case "||": return TokenSymbol.Or;
case "==": return TokenSymbol.Equal;
case "!=": return TokenSymbol.NotEqu;
case "<": return TokenSymbol.Less;
case ">": return TokenSymbol.Great;
case "<=": return TokenSymbol.Lesser;
case ">=": return TokenSymbol.Greater;
case "[": return TokenSymbol.LBracket;
case "]": return TokenSymbol.RBracket;
case "{": return TokenSymbol.LBrace;
case "}": return TokenSymbol.RBrace;
case "(": return TokenSymbol.LParen;
case ")": return TokenSymbol.RParen;
case ",": return TokenSymbol.Comma;
case ";": return TokenSymbol.Semicolon;
case "‘": return TokenSymbol.LQuote;
case "’": return TokenSymbol.RQuote;
case "\255": return TokenSymbol.EOF;
case "&":
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.SingleAmpersand));
break;
case "|":
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.SingleBar));
break;
default: // 인식하지 못한 TokenSymbol
System.err.print(LexicalError.
getErrorMessage(LexicalError.ErrorCode.InvalidChar));
break;
}
return TokenSymbol.NULL;
}**
/**
* Token의 Symbol과 value를 설정하는 메소드
* Mini C Scanner 객체에서 잘라낸 토큰 String을 통해 그 String에 맞는 Symbol로 설정한다
*
* @param token - 잘라낸 토큰 String
* @param type - Mini C Scanner 객체에서 분류한 타입
(키워드나 명칭, 숫자, 연산자로 대분류)
*/
public void setSymbol(String token, SymbolType type) {
tokenString = token;
switch (type) {
case IDorKeyword:
symbol = getIDorKeywordSymbol(token);
if (symbol == TokenSymbol.ID) // 명칭일 경우
val = token;
break;
case Digit:
symbol = TokenSymbol.Number;
val = Integer.toString(parseInt(token));
break;
case Operator:
symbol = getOperatorSymbol(token);
break;
**case Float:
symbol = TokenSymbol.Number2;
val = Float.toString(Float.parseFloat(token));
break;
case Const:
symbol = TokenSymbol.Number3;
val = token.substring(1, token.length() - 1);
break;**
case NULL:
default:
break;
}
}
/**
* 16진수, 8진수, 10진수에 상관없이 String을 정수형으로 추출해내는 메소드
*
* @param s - 정수로 변환할 String (eg. 0x1F, 047, 14)
* @return String의 정수
*/
private int parseInt(String s) {
int radix = 10; // default 진법은 10진수
if (s.startsWith("0x")) { // 16진수일 경우
radix = 16; // 진법을 16진수로 설정
s = s.substring(2); // prefix인 0x 제거
} else if (s.startsWith("0") && s.length() > 1) { // 8진수일 경우
radix = 8; // 진법을 8진수로 설정
}
return Integer.parseInt(s, radix); // 위에서 설정한 진법대로 진법 변환
}
/**
* Symbol에 해당하는 토큰 심볼을 숫자로 표현하는 메소드
*
* @return 토큰 심볼의 숫자 (-1 : NULL)
*/
public int getSymbolOrdinal() {
return symbol.ordinal()-1; // NULL이 -1이기 때문에 -1 해야한다.
}
/**
* 토큰이 명칭이나 숫자일 경우 그 토큰 값을 얻는 메소드
*
* @return 토큰 값 (없을 경우 0 반환)
*/
public String getSymbolValue() {
return val;
}
/**
* 출력하기 편하게 하기 위해 정의하는 toString 메소드
*
* @return 토큰을 표현하기 위한 String
*/
public String toString() {
return tokenString + "\t : (" + getSymbolOrdinal() + ", "+ getSymbolValue() + ")";
}
}코드(LexicalError.java)
package Automata_Scanner;
public class LexicalError {
public enum ErrorCode {
CannotOpenFile, AboveIDLimit, SingleAmpersand, SingleBar,
InvalidChar, InvalidComment, **InvalidID**
}
public static String getErrorMessage(ErrorCode code) {
String msg;
msg = "Lexical Error(code: " + code.ordinal() + ")\n";
switch (code) {
case CannotOpenFile:
msg += "cannot open the file. please check the file path.";
break;
case AboveIDLimit:
msg += "an identifier length must be less than 12.";
break;
case SingleAmpersand:
msg += "next character must be &.";
break;
case SingleBar:
msg += "next character must be |.";
break;
case InvalidChar:
msg += "invalid character!!!";
break;
case InvalidComment:
msg += "invalid block comment!!!";
break;
**case InvalidID:
msg += "invalid ID!!!";**
default:
msg += "Unknown Error";
break;
}
return msg;
}
}코드(main.java)
package Automata_Scanner;
public class main{
/**
* Entry Point 메소드
*
* @param args - 디버그 인자 (0번째 원소로 입력 파일 경로를 받음)
*/
public static void main(String[] args) {
**String File_path =
"C:\\Users\\82109\\IdeaProjects\\Automata_Scanner\\src\\Automata_Scanner\\example";
String File_path2 =
"C:\\Users\\82109\\IdeaProjects\\Automata_Scanner\\src\\Automata_Scanner\\example2";**
if (File_path2 == null) {
// 스캐너가 분석할 파일의 경로를 받지 못했을 경우 에러 출력
System.err.print("Please enter the file path (by debug argument)");
return;
}
dong_kyu_Scanner sc = new dong_kyu_Scanner(File_path2); // Mini C Scanner 객체
Token tok = null; // Mini C Scanner에서 얻어낸 token을 저장하기 위한 Token 변수
while ((tok = sc.getToken()).getSymbolOrdinal() != -1)
// Mini C Scanner에서 다 읽을 때까지 token을 얻어 출력
System.out.println(tok);
}
}example Code 1
int a, b, sum;
float x1, y1, zoom;
char ch1;
if (a>b) sum = a+b;
else sum = a+10;
while (a == b) {
zoom = (sum + x1)/10;
ch1 = ‘123’;
}Example Code 1 - 결과
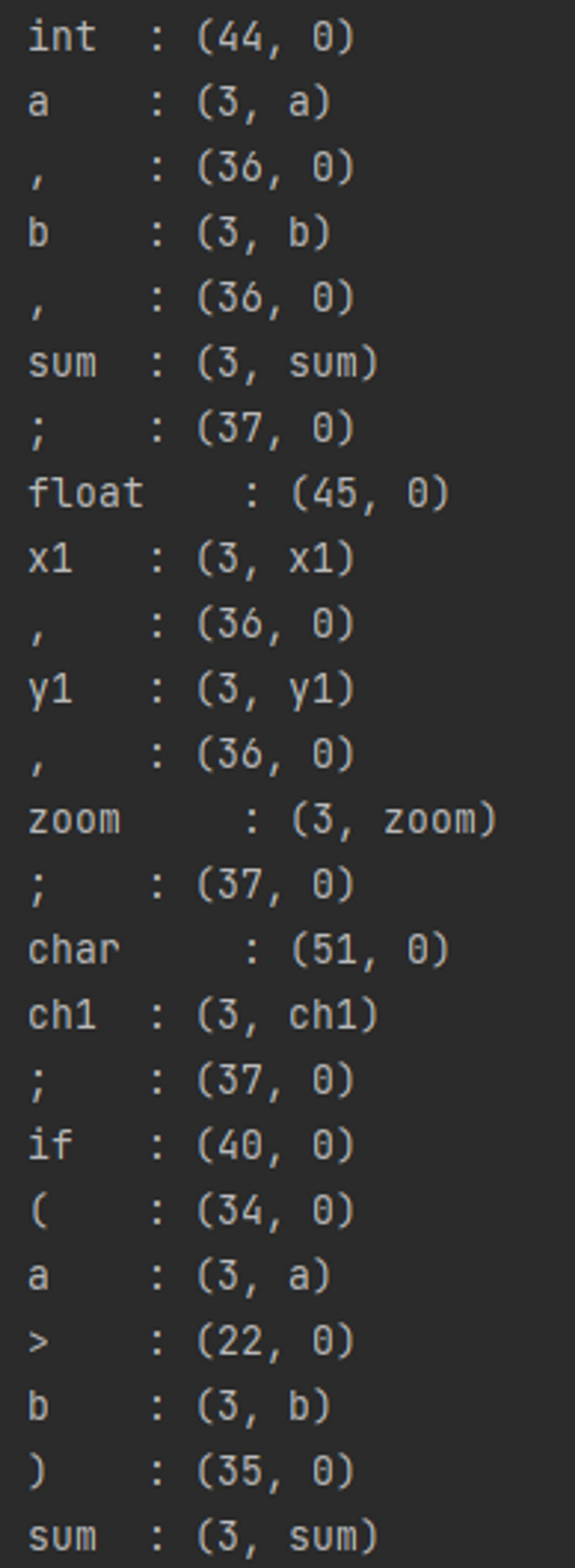
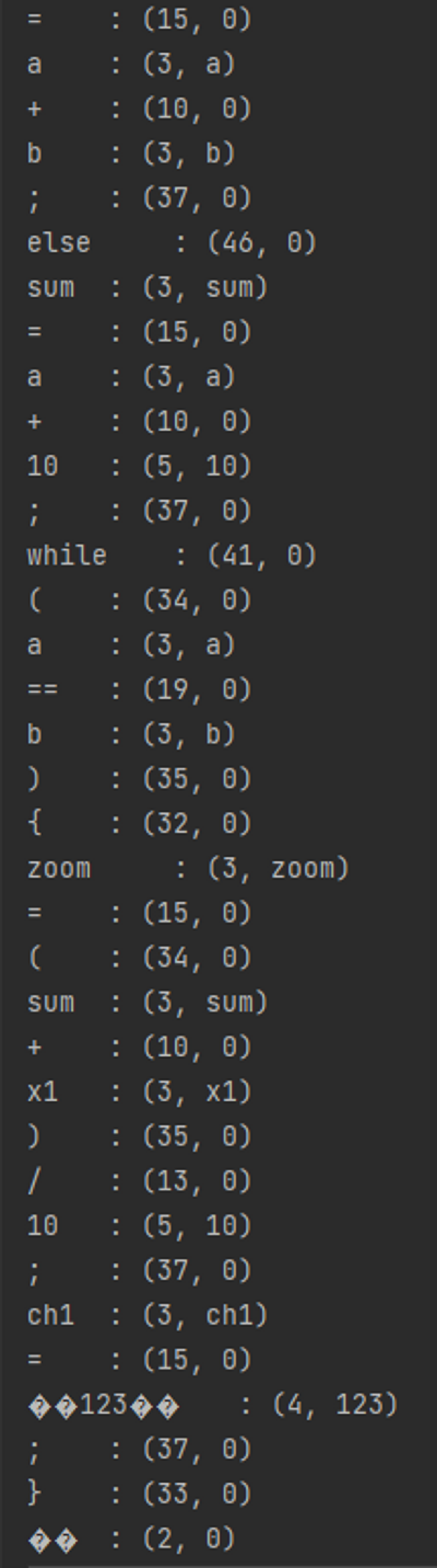
결과를 확인해 보면 예약어와 ID 의 토큰 번호가 명확하게 나눠지는 것을 확인할 수 있으며 상수, 실수, 정수, 사칙, 배정, 논리, 관계 연산자, 특수 기호 각각의 토큰 번호가 아래의 선언대로 출력되는 것을 확인할 수 있다. 토큰 번호를 아래와 맞게 지정하는 방법으로는 Token.java 파일 속 public enum TokenSymbol() 함수를 통해 순서를 지정하였다.

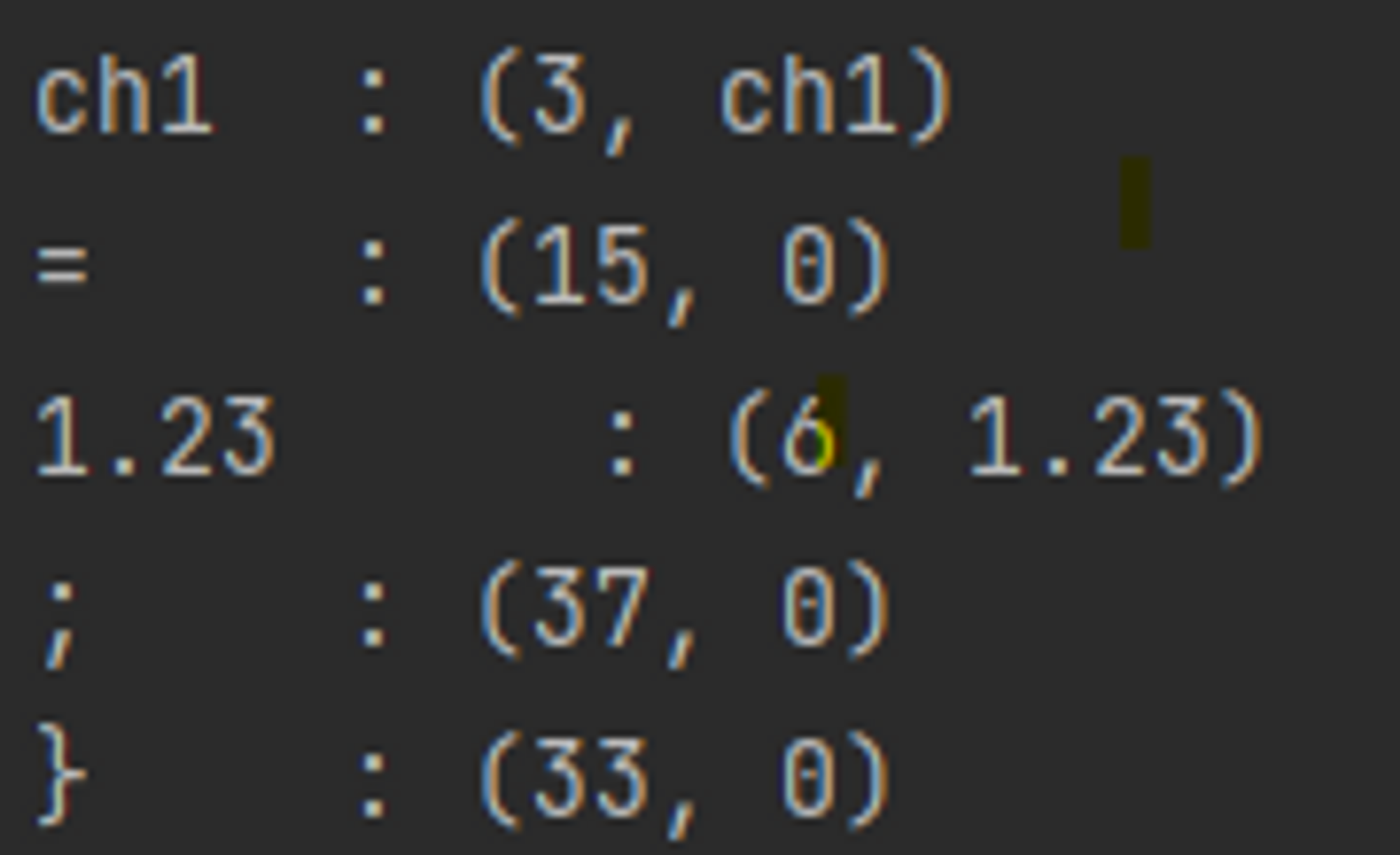
example Code 1 을 변형하여 상수형 선언 대신 소수점을 포함한 실수형을 선언해보면 아래와 같이 토큰 번호 6번에 위치해 있는 것을 확인할 수 있다.
주어진 코드를 연구 후 변경을 통해 실수 형 Scanner을 제작하였는데 실수 중 12e+2 형태를 Scan 하는 코드는 큰 어려움을 가져서 구현은 못 시켰다.
또한 아래의 출력 결과를 확인해 보면 상수 형을 Scan 후 Symbol Table 속 4번 위치에 들어가는 것까지는 성공하였으나 작은 따옴표와 작은 따옴표 안의 상수를 분리시키는 방법은 여러 시도를 해보았으나 성공하지 못하였다. 나의 생각은 dong_kyu_Scanner.java 속 코드 속 문자를 하나씩 확인하는 코드에서 state 상태가 state.ConstOperator 상태를 만난다면 state가 state.SingleOperator 상태로 변환 후 Token.SymbolType.Operator 를 리턴하여 작은 따옴표가 해당하는 Symbol Table 들어간 후 다음 문자를 확인하러 whlile 문 처음으로 돌아가는데 이때 작은 따옴표 뒤 문자를 확인할 때는 state를 state.Const 상태로 변환하여 이후 작은 따옴표가 나오기 전 까지는 상수 Symbol Table에 들어가도록 코드를 짜보았지만 아래 결과를 보면 작은 따옴표와 상수가 모두 같이 상수 symbol Table에 들어가는 것을 확인할 수 있다. (작은 따옴표 같은 경우 시작 기호와 끝 기호를 분리하기 위해 인용 기호를 사용하였다. 그렇기에 아래와 같이 문자 출력에 오류가 생겼다.)
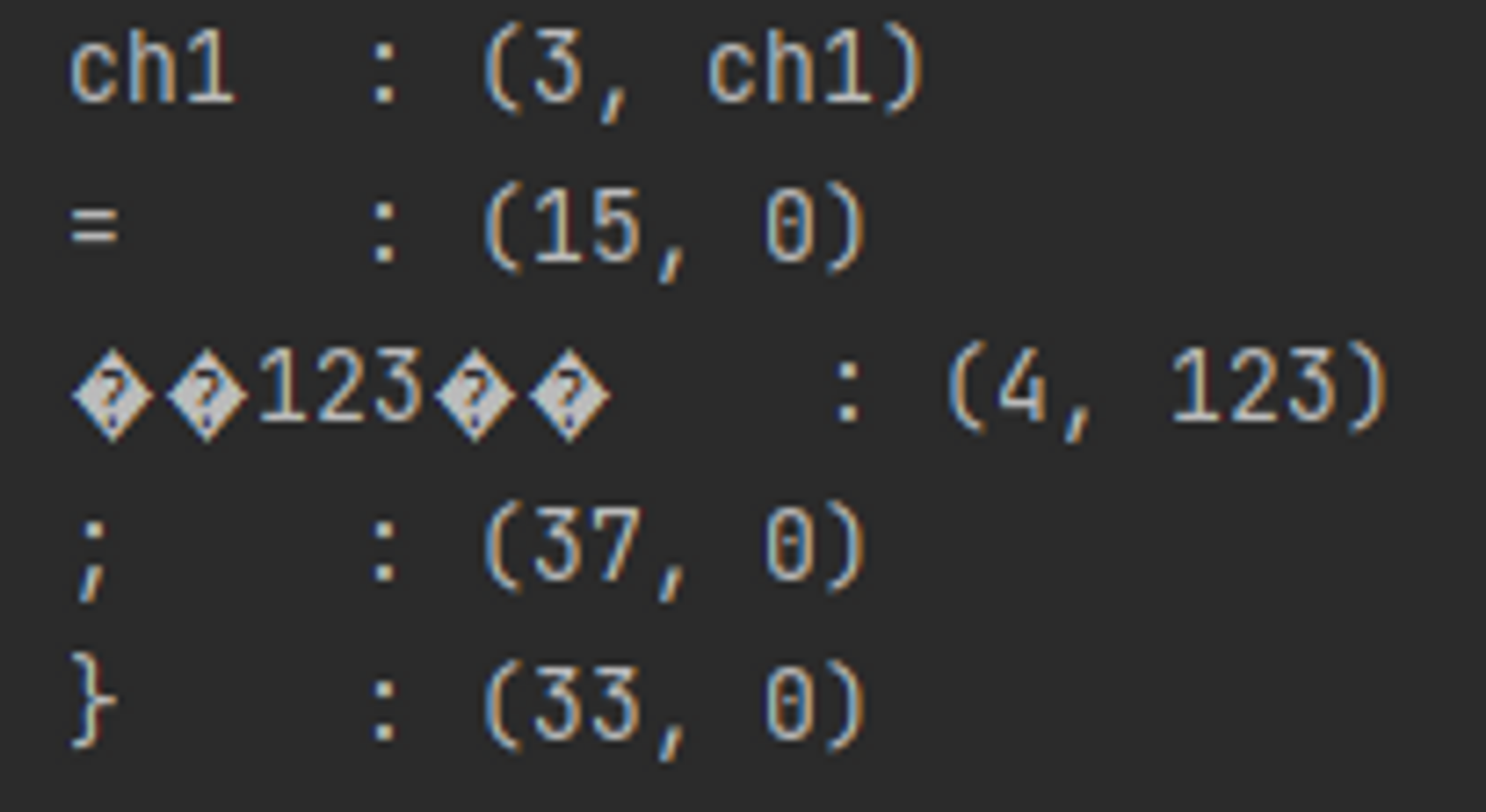
example Code 2
int a1, 2b;
float x2, y2;
a1 := 100;
x2 = 12.23e+10;example Code 2 - 결과
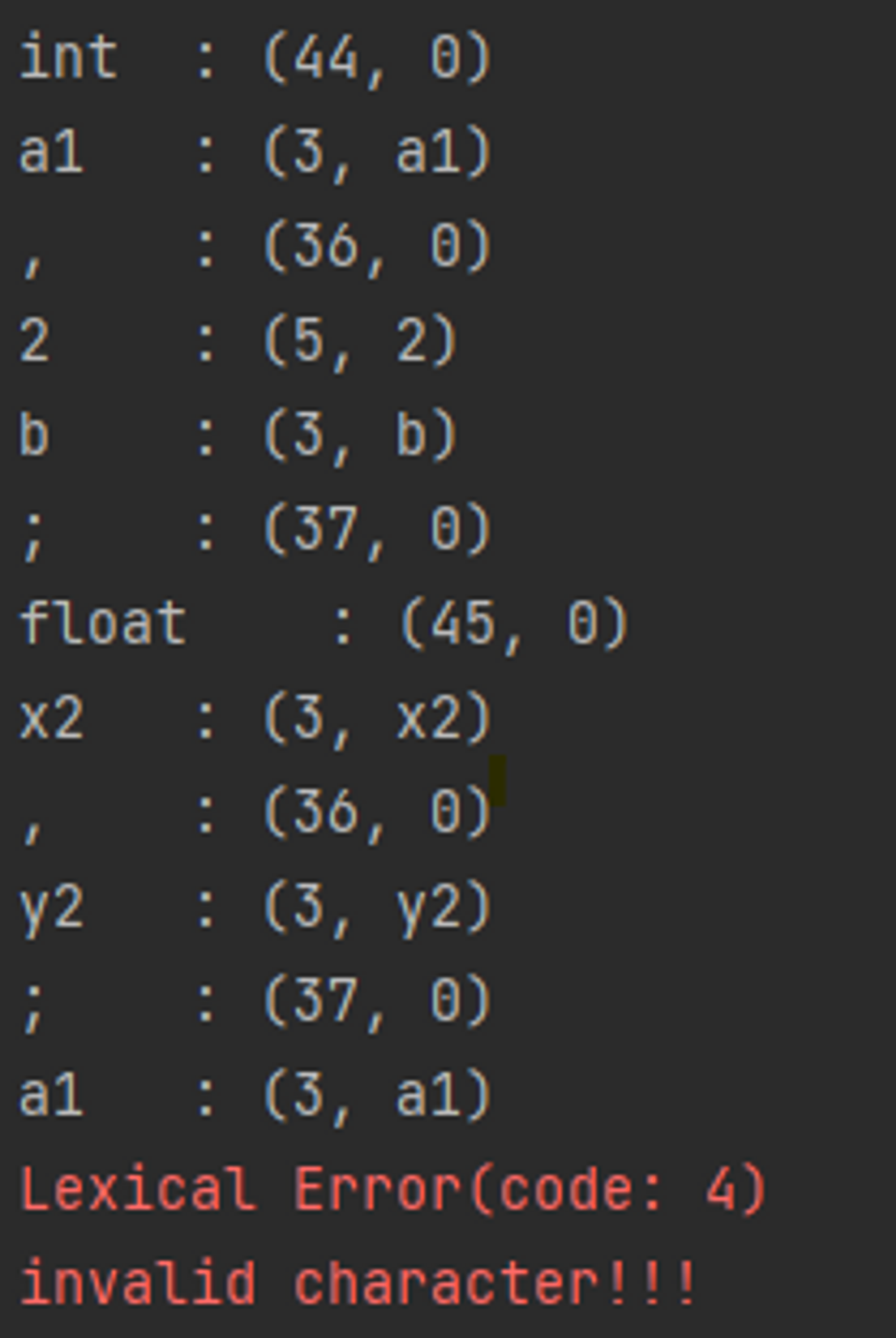
결과를 보면 예상과 같게 오류가 확인된 것을 볼 수 있다. 오류가 생기는 이유는 코드 속을 잘 보면 =(equal) 기호가 들어갈 자리에 := 기호가 들어감으로써 Scanner 가 Scan 하지 못하는 기호로 받아들여서 Invalid Character!! 오류가 뜨는 것이다.
