TIL (SUBQUERY)
SUBQUERY
SELECT 문장 안에 포함된 또 다른 SELECT 문장으로 메인 쿼리가 실행되기 전 한 번만
실행됨 비교 연산자의 오른쪽에 기술해야 하며 반드시 괄호로 묶어야 함
서브쿼리와 비교할 항목은 반드시 서브쿼리의 SELECT한 항목의 개수와 자료형을 일치시켜야 함
예시
유형
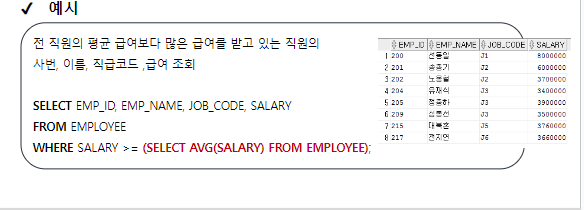
1. 단일행 서브쿼리
서브쿼리의 조회 결과 값의 개수가 1개인 서브쿼리
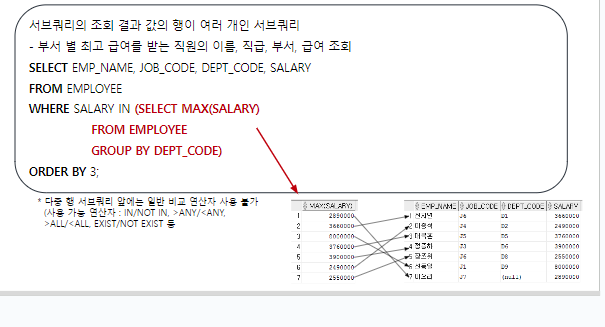
2. 다중행 서브쿼리
서브쿼리의 조회 결과 값의 행이 여러 개인 서브쿼리
3. 다중열 서브쿼리
서브쿼리의 조회 결과 컬럼의 개수가 여러 개인 서브쿼리
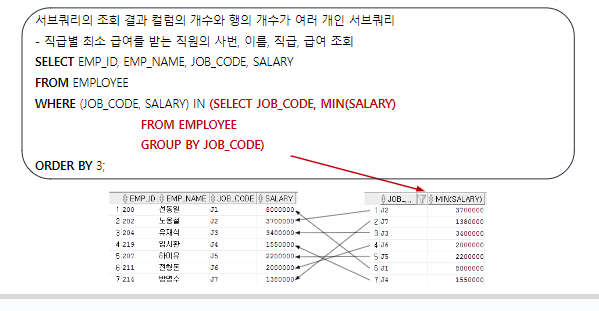
4. 다중행 다중열 서브쿼리
서브쿼리의 조회 결과 컬럼의 개수와 행의 개수가 여러 개인 서브쿼리
5. 상(호연)관 서브쿼리
서브쿼리가 만든 결과 값을 메인 쿼리가 비교 연산할 때
메인 쿼리 테이블의 값이 변경되면 서브쿼리의 결과 값도 바뀌는 서브쿼리
6. 스칼라 서브쿼리
상관쿼리이면서 결과 값이 한 개인 서브쿼리
단일 행 서브쿼리
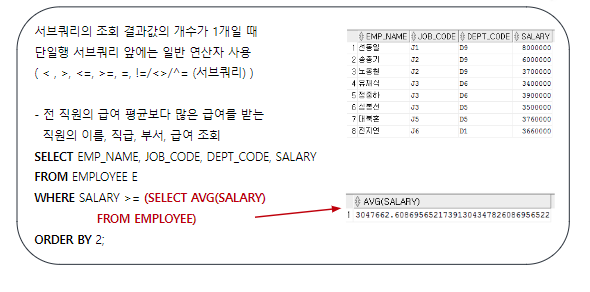
다중 행 서브쿼리
다중 열 서브쿼리

다중 행 다중 열 서브쿼리
상(호연)관 서브쿼리

스칼라 서브쿼리
SELECT절 예시

WHERE절 예시

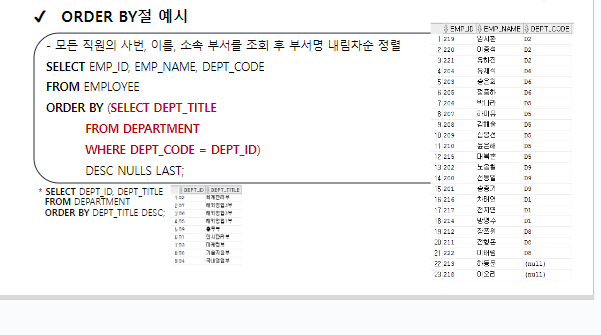
ORDER BY절 예시
인라인뷰(INLINE-VIEW) ROWNUM : 행번호를 나타내는 가상 컬럼
FROM절에 서브쿼리 사용한 것
예시

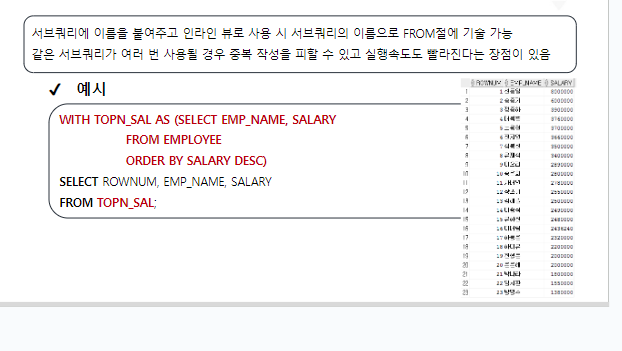
WITH
서브쿼리에 이름을 붙여주고 인라인 뷰로 사용 시 서브쿼리의 이름으로 FROM절에
기술 가능 같은 서브쿼리가 여러 번 사용될 경우 중복 작성을 피할 수 있고
실행속도도 빨라진다는 장점이 있음
예시
RANK()OVER

DENSE_RANK()OVER

코드
/*
* SUBQUERY (서브쿼리)
- 하나의 SQL문 안에 포함된 또다른 SQL(SELECT)문
- 메인쿼리(기존쿼리)를 위해 보조 역할을 하는 쿼리문
-- SELECT, FROM, WHERE, HAVGIN 절에서 사용가능
*/
-- 서브쿼리 예시 1.
-- 부서코드가 노옹철 사원과 같은 소속의 직원의
-- 이름, 부서코드 조회하기
-- 1) 사원명이 노옹철인 사람의 부서코드 조회
SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철';
-- 2) 부서코드가 D9인 직원을 조회
SELECT EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
-- 3) 부서코드가 노옹철사원과 같은 소속의 직원 명단 조회
--> 위의 2개의 단계를 하나의 쿼리로!! -> 서브쿼리
SELECT EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철');
-- 서브쿼리 예시 2.
-- 전 직원의 평균 급여보다 많은 급여를 받고 있는 직원의
-- 사번, 이름, 직급코드, 급여 조회
-- 1) 전 직원의 평균 급여 조회하기
SELECT CEIL (AVG(SALARY)) FROM EMPLOYEE;
-- 2) 직원들중 급여가 3047663원 이상인 사원들의 사번, 이름, 직급코드, 급여 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3047663;
-- 3) 전 직원의 평균 급여보다 많은 급여를 받고 있는 직원 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= (SELECT CEIL (AVG(SALARY)) FROM EMPLOYEE);
/* 서브쿼리 유형
- 단일행 (단일열) 서브쿼리 : 서브쿼리의 조회 결과 값의 개수가 1개일 때
- 다중행 (단일열) 서브쿼리 : 서브쿼리의 조회 결과 값의 개수가 여러개일 때
- 다중열 서브쿼리 : 서브쿼리의 SELECT 절에 자열된 항목수가 여러개 일 때
- 다중행 다중열 서브쿼리 : 조회 결과 행 수와 열 수가 여러개일 때
- 상관 서브쿼리 : 서브쿼리가 만든 결과 값을 메인 쿼리가 비교 연산할 때
메인 쿼리 테이블의 값이 변경되면 서브쿼리의 결과값도 바뀌는 서브쿼리
- 스칼라 서브쿼리 : 상관 쿼리이면서 결과 값이 하나인 서브쿼리- 서브쿼리 유형에 따라 서브쿼리 앞에 붙은 연산자가 다름
*/
-- 1. 단일행 서브쿼리 (SINGLE ROW SUBQUERY)
-- 서브쿼리의 조회 결과 값의 개수가 1개인 서브쿼리
-- 단일행 서브쿼리 앞에는 비교 연산자 사용
-- <, >, <=, >=, =, !=/^=/<>
-- 전 직원의 급여 평균보다 많은(초과) 급여를 받는 직원의
-- 이름, 직급, 부서, 급여를 직급 순으로 정렬하여 조회
SELECT EMP_NAME, JOB_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >SELECT ( AVG(SALARY) FROM EMPLOYEE);
-- SELECT 절에 없는 컬럼이라도
-- FROM, JOIN으로 인해 존재하는 컬럼이면
-- ORDER BY절에 사용 가능
-- 가장 적은 급여를 받는 직원의
-- 사번, 이름, 직급, 부서코드, 급여, 입사일을 조회
-- 노옹철 사원의 급여보다 많이 받는 직원의
-- 사번, 이름, 부서, 직급, 급여를 조회
SELECT EMP_ID EMP_NAME, DEPT_TITLE, JOB_NAME, SALARY
FROM EMPLOYEE
NATURAL JOIN JOB
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE SALARY > (SELECT SALARY FROM EMPLOYEE
WHERE EMP_NAME = '노옹철');
-- 부서별(부서가 없는 사람 포함) 급여의 합계 중 가장 큰 부서의
-- 부서명, 급여 합계를 조회
-- 1) 부서별 급여 합 중 가장 큰값 조회
SELECT MAX(SUM(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE;
-- 2) 부서별 급여합이 17700000인 부서의 부서명과 급여 합 조회
SELECT DEPT_TITLE, SUM(SALARY)
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
GROUP BY DEPT_TITLE
HAVING SUM(SALARY) = 17700000;
-- 3) >> 위의 두 서브쿼리 합쳐 부서별 급여 합이 큰 부서의 부서명, 급여 합 조회
SELECT DEPT_TITLE, SUM(SALARY)
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
GROUP BY DEPT_TITLE
HAVING SUM(SALARY) = (SELECT MAX(SUM(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE);
-- 2. 다중행 서브쿼리 (MULTI ROW SUBQUERY)
-- 서브쿼리의 조회 결과 값의 개수가 여러행일 때
/*
>> 다중행 서브쿼리 앞에는 일반 비교연산자 사용 x
- IN / NOT IN : 여러 개의 결과값 중에서 한 개라도 일치하는 값이 있다면
혹은 없다면 이라는 의미(가장 많이 사용!)
- > ANY, < ANY : 여러개의 결과값 중에서 한개라도 큰 / 작은 경우
가장 작은 값보다 큰가? / 가장 큰 값 보다 작은가?
- > ALL, < ALL : 여러개의 결과값의 모든 값보다 큰 / 작은 경우
가장 큰 값 보다 큰가? / 가장 작은 값 보다 작은가?
- EXISTS / NOT EXISTS : 값이 존재하는가? / 존재하지 않는가?*/
-- 부서별 최고 급여를 받는 직원의
-- 이름, 직급, 부서, 급여를 부서 순으로 정렬하여 조회
SELECT EMP_NAME, JOB_CODE, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY IN (SELECT MAX(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE);
-- 부서별 최고 급여(SUBQUERY)
SELECT MAX(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE;
-- 사수에 해당하는 직원에 대해 조회
-- 사번, 이름, 부서명, 직급명, 구분(사수 / 직원)
-- * 사수 == MANAGER_ID 컬럼에 작성된 사번
-- 1) 사수에 해당하는 사원 번호 조회
SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL;
-- 2) 직원의 사번, 이름, 부서명, 직급 조회
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID);
-- 3) 사수에 해당하는 직원에 대한 정보 추출 조회 (이때, 구분은 '사수'로)
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME, '사수' 구분
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE EMP_ID IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);
-- 4) 일반 직원에 해당하는 사원들 정보 조회 (이때, 구분은 '사원'으로)
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME, '사원' 구분
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE EMP_ID NOT IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);
-- 5) 3, 4의 조회 결과를 하나로 합침 -> SELECT절 SUBQUERY
-- * SELECT 절에도 서브쿼리 사용할 수 있음
-- 선택함수 사용!
--> DECODE(컬럼명, 값1, 1인경우, 값2, 2인경우,.... 일치하지 않는경우)
--> CASE WHEN 조건1 THEN 값1
-- WHEN 조건2 THEN 값2
-- ELSE 값
-- END 별칭
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME,
CASE WHEN EMP_ID IN(SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL)
THEN '사수'
ELSE '사원'
END 구분
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID);
-- * 집합 연산자(UNION, 합집합) 사용 방법
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME, '사수' 구분
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE EMP_ID IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL)
UNION
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME, '사원' 구분
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE EMP_ID NOT IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);
-- 대리 직급의 직원들 중에서 과장 직급의 최소 급여보다 많이 받는 직원의
-- 사번, 이름, 직급, 급여를 조회하세요
-- 단, > ANY 혹은 < ANY 연산자를 사용하세요
-- > ANY, < ANY : 여러개의 결과값 중에서 하나라도 큰 / 작은 경우
-- 가장 작은 값보다 큰가? / 가장 큰 값 보다 작은가?
-- 1) 직급이 대리인 직원들의 사번, 이름, 직급명, 급여 조회
SELECT EMP_ID, EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '대리';
-- 2) 직급이 과장인 직원들 급여 조회
SELECT SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '과장';
-- 3) 대리 직급의 직원들 중에서 과장 직급의 최소 급여보다 많이 받는 직원
-- 3-1) MIN을 이용하여 단일행 서브쿼리를 만듦.
SELECT EMP_ID, EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '대리'
AND SALARY > (SELECT MIN(SALARY)
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '과장');
-- 3-2) ANY를 이용하여 과장 중 가장 급여가 적은 직원 초과하는 대리를 조회
SELECT EMP_ID, EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '대리'
AND SALARY > ANY (SELECT SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '과장');
-- 차장 직급의 급여의 가장 큰 값보다 많이 받는 과장 직급의 직원
-- 사번, 이름, 직급, 급여를 조회하세요
-- 단, > ALL 혹은 < ALL 연산자를 사용하세요
-- > ALL, < ALL : 여러개의 결과값의 모든 값보다 큰 / 작은 경우
-- 가장 큰 값 보다 크냐? / 가장 작은 값 보다 작냐?
SELECT EMP_ID , EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '과장'
AND SALARY > ALL (SELECT SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME = '차장');
-- 서브쿼리 중첩 사용(응용편!)
-- LOCATION 테이블에서 NATIONAL_CODE가 KO인 경우의 LOCAL_CODE와
-- DEPARTMENT 테이블의 LOCATION_ID와 동일한 DEPT_ID가
-- EMPLOYEE테이블의 DEPT_CODE와 동일한 사원을 구하시오.
-- 1) LOCATION 테이블을 통해 NATIONAL_CODE가 KO인 LOCAL_CODE 조회
SELECT LOCAL_CODE
FROM LOCATION
WHERE NATIONAL_CODE = 'KO';
-- 2) DEPARTMENT 테이블에서 위의 결과와 동일한 LOCATION_ID를 가지고 있는 DEPT_ID를 조회
SELECT DEPT_ID
FROM DEPARTMENT
WHERE LOCATION_ID = (SELECT LOCAL_CODE
FROM LOCATION
WHERE NATIONAL_CODE = 'KO');
-- 3) 최종적으로 EMPLOYEE 테이블에서 위의 결과들과 동일한 DEPT_CODE를 가지는 사원을 조회
SELECT EMP_NAME
FROM EMPLOYEE
WHERE DEPT_CODE IN (SELECT DEPT_ID
FROM DEPARTMENT
WHERE LOCATION_ID = (SELECT LOCAL_CODE
FROM LOCATION
WHERE NATIONAL_CODE = 'KO'));
-- 3. (단일행) 다중열 서브쿼리 (단일행 = 결과값은 한 행)
-- 서브쿼리 SELECT 절에 나열된 컬럼 수가 여러개 일 때
-- 퇴사한 여직원과 같은 부서, 같은 직급에 해당하는
-- 사원의 이름, 직급, 부서, 입사일을 조회
-- 1) 퇴사한 여직원 조회
SELECT EMP_NAME , DEPT_CODE, JOB_CODE
FROM EMPLOYEE
WHERE ENT_YN = 'Y'
AND SUBSTR(EMP_NO, 8,1) = '2'; -- 이태림, D8, J6
-- 2) 퇴사한 여직원과 같은 부서, 같은 직급 (다중 열 서브쿼리)
-- 단일행 서브쿼리 2개를 사용해서 조회
--> 서브쿼리가 같은 테이블, 같은 조건, 다른 컬럼 조회
SELECT EMP_NAME, JOB_CODE, DEPT_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE ENT_YN = 'Y'
AND SUBSTR(EMP_NO, 8,1) = '2')
AND JOB_CODE = (SELECT JOB_CODE
FROM EMPLOYEE
WHERE ENT_YN = 'Y'
AND SUBSTR(EMP_NO, 8,1) = '2');
-- 다중열 서브쿼리
--> WHERE절에 작성된 컬럼 순서에 맞게
-- 서브쿼리의 조회된 컬럼과 비교하여 일치하는 행만 조회
-- (컬럼 순서가 중요!)
SELECT EMP_NAME, JOB_CODE, DEPT_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE (DEPT_CODE , JOB_CODE) = (SELECT DEPT_CODE,JOB_CODE
FROM EMPLOYEE
WHERE ENT_YN = 'Y'
AND SUBSTR(EMP_NO, 8,1) = '2');
-------------------------- 연습문제 -------------------------------
-- 1. 노옹철 사원과 같은 부서, 같은 직급인 사원을 조회하시오. (단, 노옹철 사원은 제외)
-- 사번, 이름, 부서코드, 직급코드, 부서명, 직급명
SELECT EMP_ID, EMP_NAME, DEPT_CODE, JOB_CODE, DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT (DEPT_CODE = DEPT_ID)
WHERE (DEPT_CODE,JOB_CODE) = (SELECT DEPT_CODE , JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철')
AND EMP_NAME != '노옹철';
-- 2. 2000년도에 입사한 사원의 부서와 직급이 같은 사원을 조회하시오
-- 사번, 이름, 부서코드, 직급코드, 고용일
SELECT EMP_ID,EMP_NAME, DEPT_CODE, JOB_CODE,HIRE_DATE
FROM EMPLOYEE
WHERE (DEPT_CODE, JOB_CODE) = (SELECT DEPT_CODE , JOB_CODE
FROM EMPLOYEE
WHERE EXTRACT (YEAR FROM HIRE_DATE) = 2000);
-- 3. 77년생 여자 사원과 동일한 부서이면서 동일한 사수를 가지고 있는 사원을 조회하시오
-- 사번, 이름, 부서코드, 사수번호, 주민번호, 고용일
SELECT EMP_ID, EMP_NAME,DEPT_CODE,MANAGER_ID,EMP_NO,HIRE_DATE
FROM EMPLOYEE
WHERE (DEPT_CODE , MANAGER_ID) = (SELECT DEPT_CODE, MANAGER_ID
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 1, 2) = '77'
AND SUBSTR(EMP_NO, 8, 1) = '2');
-- 4. 다중행 다중열 서브쿼리
-- 서브쿼리 조회 결과 행 수와 열 수가 여러개 일 때
-- 본인 직급의 평균 급여를 받고 있는 직원의
-- 사번, 이름, 직급, 급여를 조회하세요
-- 단, 급여와 급여 평균은 만원단위로 계산하세요 TRUNC(컬럼명, -4)
-- 1) 급여를 200, 600만 받는 직원 (200만, 600만이 평균급여라 생각 할 경우)
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY IN (2000000,6000000);
-- 2) 직급별 평균 급여
SELECT JOB_CODE, TRUNC(AVG(SALARY), -4)
FROM EMPLOYEE
GROUP BY JOB_CODE;
-- 3) 본인 직급의 평균 급여를 받고 있는 직원
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE (JOB_CODE, SALARY) IN(SELECT JOB_CODE, TRUNC(AVG(SALARY), -4)
FROM EMPLOYEE
GROUP BY JOB_CODE);
-- 5. 상[호연]관 서브쿼리
-- 상관 쿼리는 메인쿼리가 사용하는 테이블값을 서브쿼리가 이용해서 결과를 만듦
-- 메인쿼리의 테이블값이 변경되면 서브쿼리의 결과값도 바뀌게 되는 구조임
-- 상관쿼리는 먼저 메인쿼리 한 행을 조회하고
-- 해당 행이 서브쿼리의 조건을 충족하는지 확인하여 SELECT를 진행함
-- 해석 순서가 기존 서브쿼리와 다르게
-- 메인쿼리 1행 -> 1행에 대한 서브쿼리
-- 메인쿼리 2행 -> 2행에 대한 서브쿼리
-- ...
-- ** 메인쿼리의 행의 수 만큼 서브쿼리가 생성되어 진행됨
-- 직급별 급여 평균보다 급여를 많이 받는 직원의
-- 이름, 직급코드, 급여 조회
SELECT EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE MAIN -- MAIN 쿼리
WHERE SALARY > (SELECT AVG(SALARY) -- SUB 쿼리
FROM EMPLOYEE SUB
WHERE SUB.JOB_CODE = MAIN.JOB_CODE);
/*
- SELECT JOB_CODE, AVG(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE;
J1 8000000
J2 4850000
J4 2330000
J3 3600000
J7 2017500
J5 2820000
J6 2624373
*/
-- 부서별 입사일이 가장 빠른 사원의
-- 사번, 이름, 부서명(NULL이면 '소속없음'), 직급명, 입사일을 조회하고
-- 입사일이 빠른 순으로 조회하세요
-- 단, 퇴사한 직원은 제외하고 조회하세요
SELECT EMP_ID, EMP_NAME, DEPT_CODE, NVL(DEPT_TITLE, '소속없음'), JOB_NAME, HIRE_DATE
FROM EMPLOYEE MAIN
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
WHERE ENT_YN = 'N' -- MAIN 쿼리
AND HIRE_DATE = (SELECT MIN(HIRE_DATE) /2/ -- SUB 쿼리
FROM EMPLOYEE SUB
WHERE SUB.DEPT_CODE = MAIN.DEPT_CODE)
/1/
ORDER BY HIRE_DATE;
-- 1) MAIN의 1행의 DEPT_CODE를 SUB에 대입
-- 2) SUB를 수행
-- 3) SUB의 결과를 이용해서 MAIN의 조건절을 수행
-- 6. 스칼라 서브쿼리
-- SELECT절에 사용되는 서브쿼리 결과로 1행만 반환
-- SQL에서 단일 값을 가르켜 '스칼라'라고 함
--> SELECT절에 작성되는 단일행 서브쿼리
-- 모든 직원의 이름, 직급, 급여, 전체 사원 중 가장 높은 급여와의 차
SELECT EMP_NAME, JOB_CODE, SALARY, (SELECT MAX(SALARY) FROM EMPLOYEE) - SALARY
FROM EMPLOYEE;
-- 각 직원들이 속한 직급의 급여 평균 조회
-- (스칼라 + 상관 쿼리)
SELECT EMP_NAME, JOB_CODE, SALARY,
(SELECT CEIL(AVG(SALARY))
FROM EMPLOYEE SUB
WHERE SUB.JOB_CODE = MAIN.JOB_CODE
)
FROM EMPLOYEE MAIN;
-- 모든 사원의 사번, 이름, 관리자사번, 관리자명을 조회
-- 단 관리자가 없는 경우 '없음'으로 표시
-- (스칼라 + 상관 쿼리)
SELECT EMP_ID, EMP_NAME, MANAGER_ID,
NVL ((SELECT EMP_NAME FROM EMPLOYEE SUB
WHERE SUB.EMP_ID = MAIN.MANAGER_ID
), '없음') 관리자명
FROM EMPLOYEE MAIN;
-- 7. 인라인 뷰(INLINE-VIEW)
-- FROM 절에서 서브쿼리를 사용하는 경우로
-- 서브쿼리가 만든 결과의 집합(RESULT SET)을 테이블 대신에 사용한다.
SELECT *
FROM(
SELECT EMP_NAME 이름 , DEPT_TITLE 부서
FROM EMPLOYEE
JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
)
WHERE 부서 = '기술지원부';
-- 인라인뷰를 활용한 TOP-N분석
-- 전 직원 중 급여가 높은 상위 5명의
-- 순위, 이름, 급여 조회
SELECT ROWNUM,EMP_NAME, SALARY
FROM EMPLOYEE
--WHERE ROWNUM <= 5
ORDER BY SALARY DESC;
-- ROWNUM 컬럼: 행번호를 나타내는 가상 컬럼
-- SELECT, WHERE, ORDER BY 사용 가능
--> 인라인뷰를 이용해서 해결 가능하다
-- 1) 이름,급여를 급여 내림차순으로 조회한 결과를 인라인뷰로 사용
--> FROM 절에 작성되기 때문에 해석순위 1순위
-- 2) 메인쿼리 조회 시 ROWNUM을 5 이하까지만 조회
SELECT ROWNUM, EMP_NAME , SALARY
FROM(SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC)
WHERE ROWNUM <= 5;
-- 급여 평균이 3위 안에 드는 부서의 부서코드와 부서명, 평균급여를 조회
SELECT DEPT_CODE,DEPT_TITLE, 평균급여
FROM(
SELECT DEPT_CODE , DEPT_TITLE, CEIL(AVG(SALARY)) 평균급여
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON(DEPT_CODE = DEPT_ID)
GROUP BY DEPT_CODE, DEPT_TITLE
ORDER BY 평균급여 DESC)
WHERE ROWNUM <= 3;
-- 8. WITH
-- 서브쿼리에 이름을 붙여주고 사용시 이름을 사용하게 함
-- 인라인뷰로 사용될 서브쿼리에 주로 사용됨
-- 실행 속도도 빨라진다는 장점이 있다.
--
-- 전 직원의 급여 순위
-- 순위, 이름, 급여 조회
WITH TOP_SAL AS (SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC)
SELECT ROWNUM, EMP_NAME, SALARY
FROM TOP_SAL
WHERE ROWNUM <= 10;
-- 9. RANK() OVER / DENSE_RANK() OVER
-- RANK() OVER : 동일한 순위 이후의 등수를 동일한 인원 수 만큼 건너뛰고 순위 계산
-- EX) 공동 1위가 2명이면 다음 순위는 2위가 아니라 3위
-- 사원별 급여 순위
-- 1) ROWNUM
SELECT ROWNUM, EMP_NAME, SALARY
FROM(SELECT EMP_NAME,SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC);
-- 2) RANK() OVER(정렬순서)
SELECT RANK() OVER(ORDER BY SALARY DESC) 순위,
EMP_NAME,SALARY
FROM EMPLOYEE;
-- DENSE_RANK() OVER : 동일한 순위 이후의 등수를 이후의 순위로 계산
-- EX) 공동 1위가 2명이어도 다음 순위는 2위
SELECT DENSE_RANK() OVER(ORDER BY SALARY DESC) 순위,
EMP_NAME,SALARY
FROM EMPLOYEE;
