그래프 신경망이란 무엇일까? (기본)
변환식 정점 표현 학습과 귀납식 정점 표현 학습
출력으로 임베딩 자체를 얻는 변환식 임베딩 방법의 한계
- 학습이 진행된 이후 정점에 대해서는 임베딩을 얻을 수 없음
- 모든 정점에 대한 임베딩을 미리 계산해서 저장해야 함
- 정점의 속성 정보는 고려하지 않음
→ 출력으로 인코더를 얻는 귀납식 임베딩 방법은 위 문제 모두 해결
그래프 신경망
그래프 신경망의 구조
- 그래프와 정점의 속성 정보를 입력으로 받음
- 정점 u 의 속성 벡터는 라고 하고 이는 속성의 수 m 차원 벡터이다.
- 정점의 속성의 예시
- SNS 에서 사용자의 지역, 성별, 연령 등
- 논문 인용 그래프에서 논문에 사용된 키워드에 대한 원-핫 벡터
- 페이지랭크 등의 정점 중심성, 군집 계수 등
- 그래프 신경망은 이웃 정점들의 정보를 집계하는 과정을 반복하여 임베딩을 얻음
- 대상 정점의 임베딩을 얻기 위해 이웃들 그리고 이웃들의 정보를 집계함
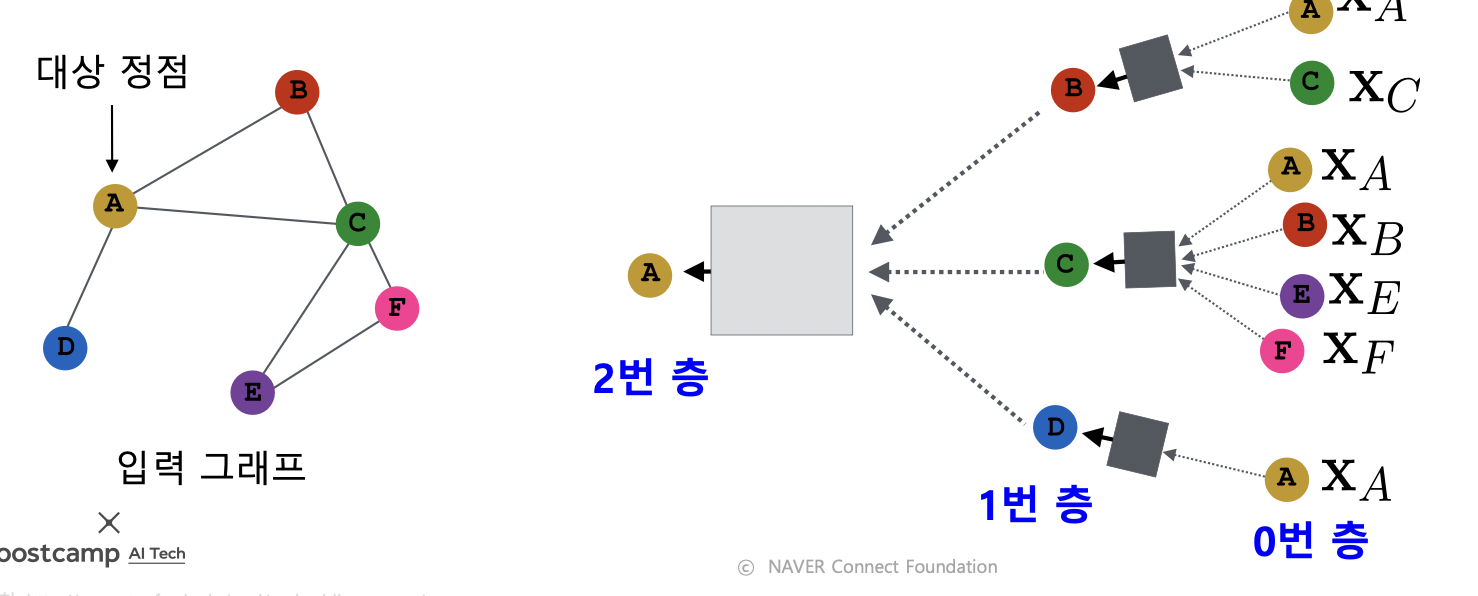
- 각 집계 단계를 층 (Layer) 라고 부르고, 각 층마다 임베딩을 얻음
- 0번 층, 즉 입력 층의 임베딩으로는 정점의 속성 벡터 사용
- 대상 정점마다 집계되는 정보가 상이함
- 대상 정점 별 집계되는 구조를 계산 그래프라고 부름
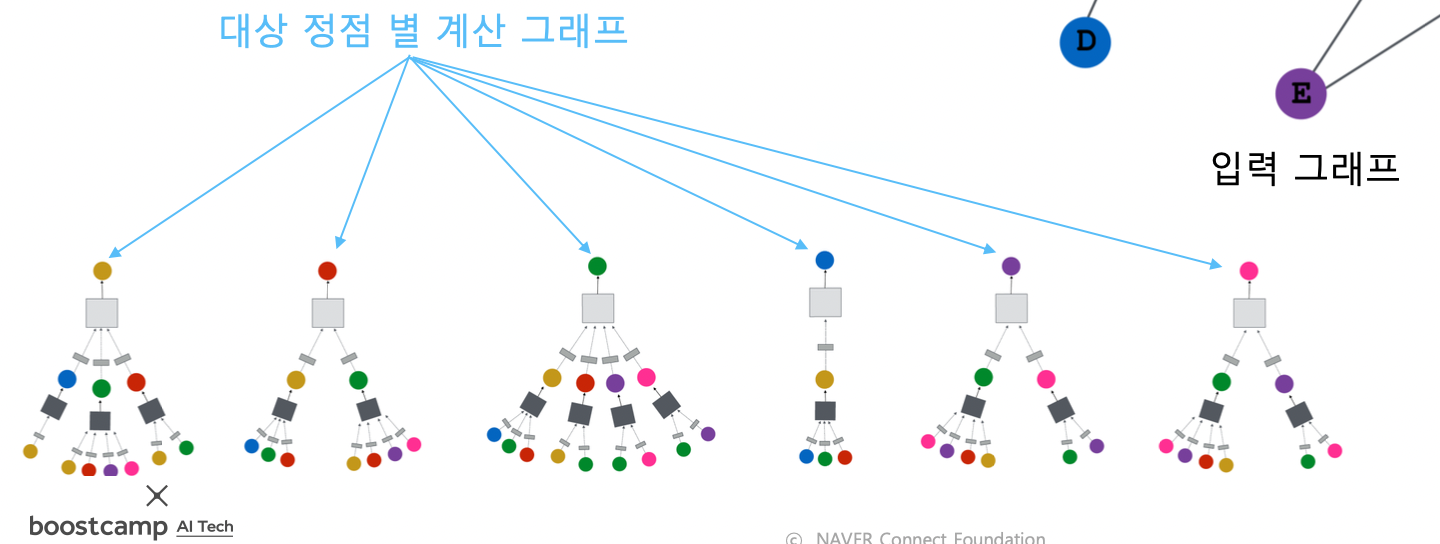
- 서로 다른 대상 정점간에도 층 별 집계 함수 공유
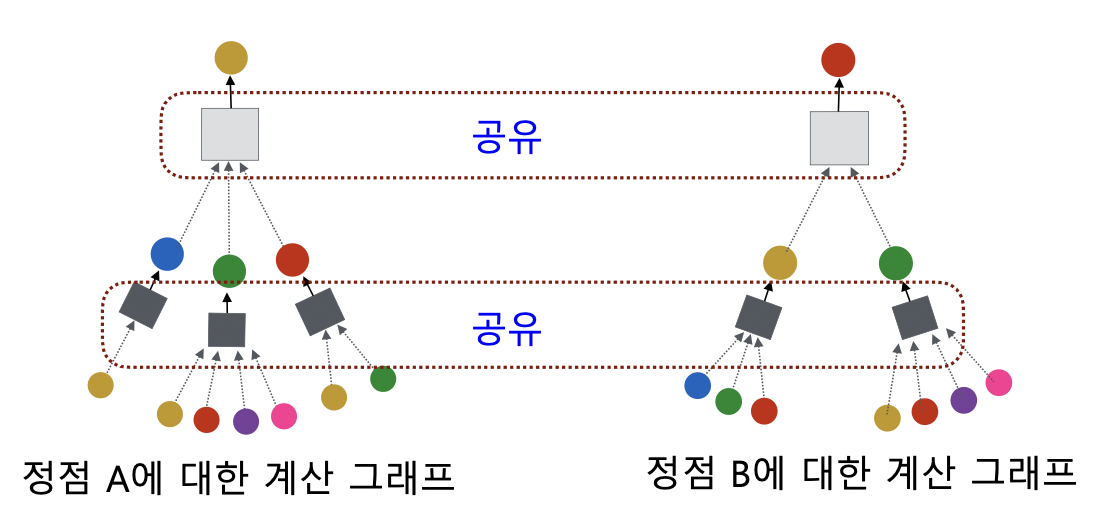
- 집계 함수는 이웃의 정보를 평균 계산하고 신경망에 적용함
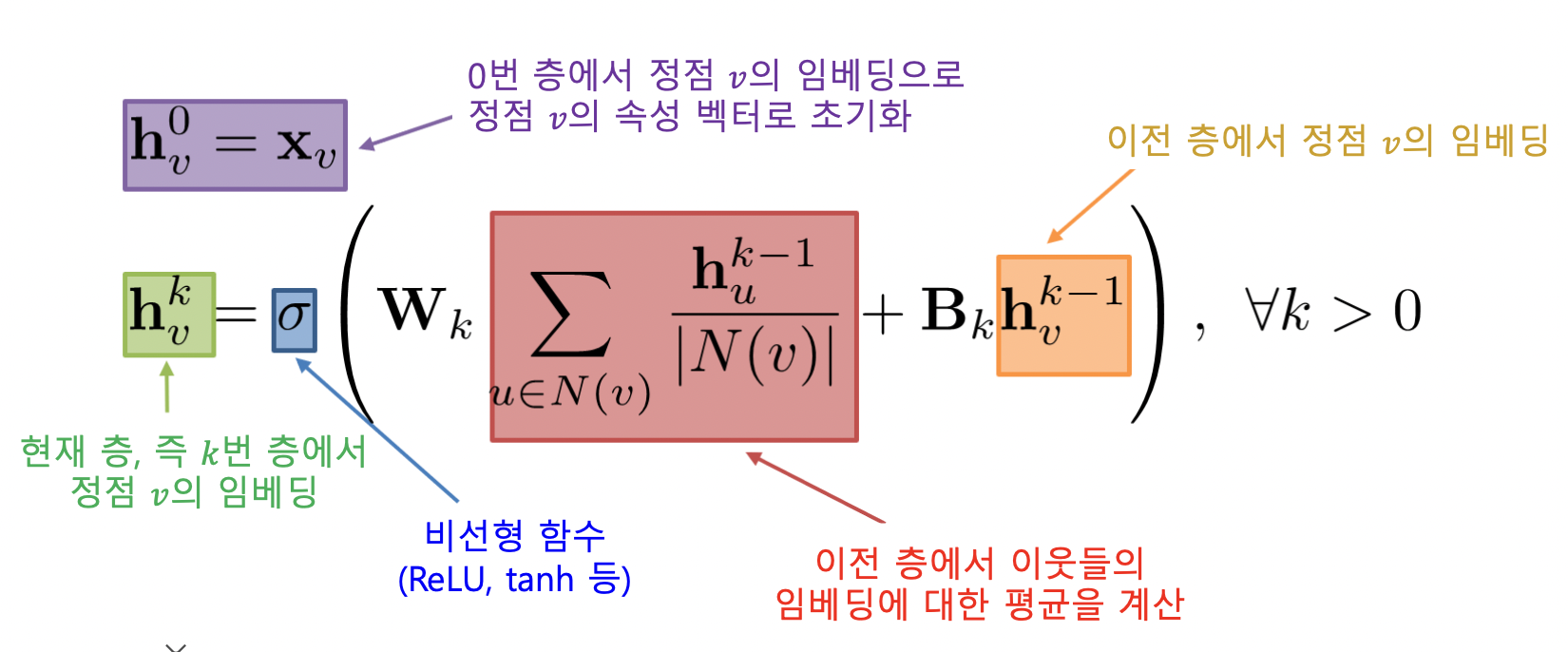
- 마지막 층의 임베딩이 출력 임베딩 이 됨
- 그래프 신경망의 학습 변수는 층 별 신경망의 가중치 (k 는 층)
그래프 신경망의 학습
- 손실함수 결정, 정점간 거리를 보존하는 것이 목표
- 인접성을 기반으로 유사도를 정의하면 손실함수는 아래와 같음
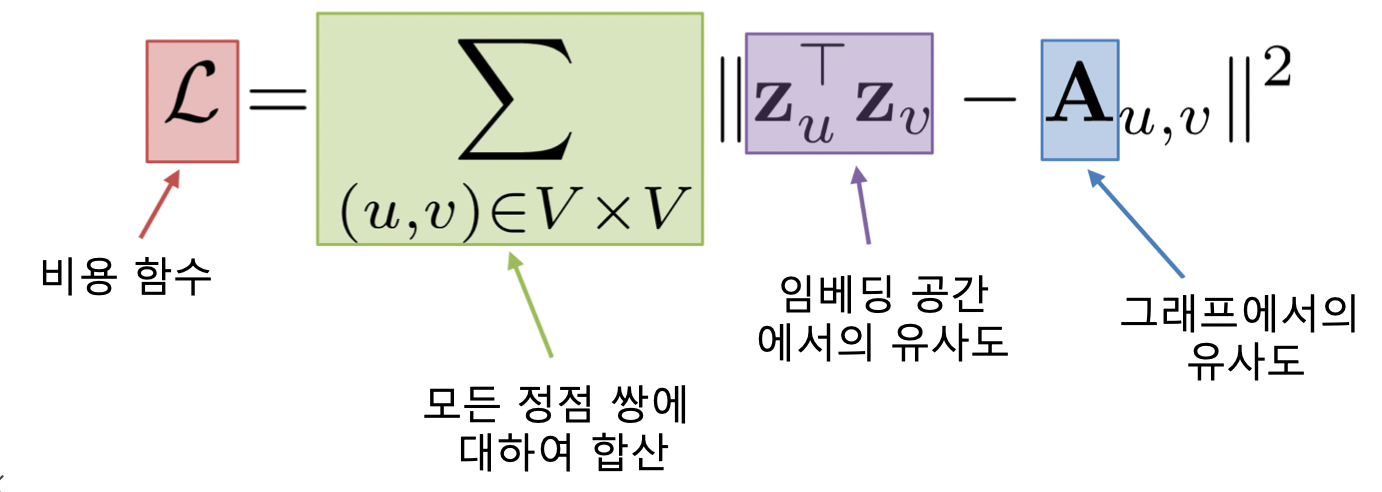
- 후속 과제 (Downstream Task) 의 손실함수로 종단종 (End-to-End) 학습 가능
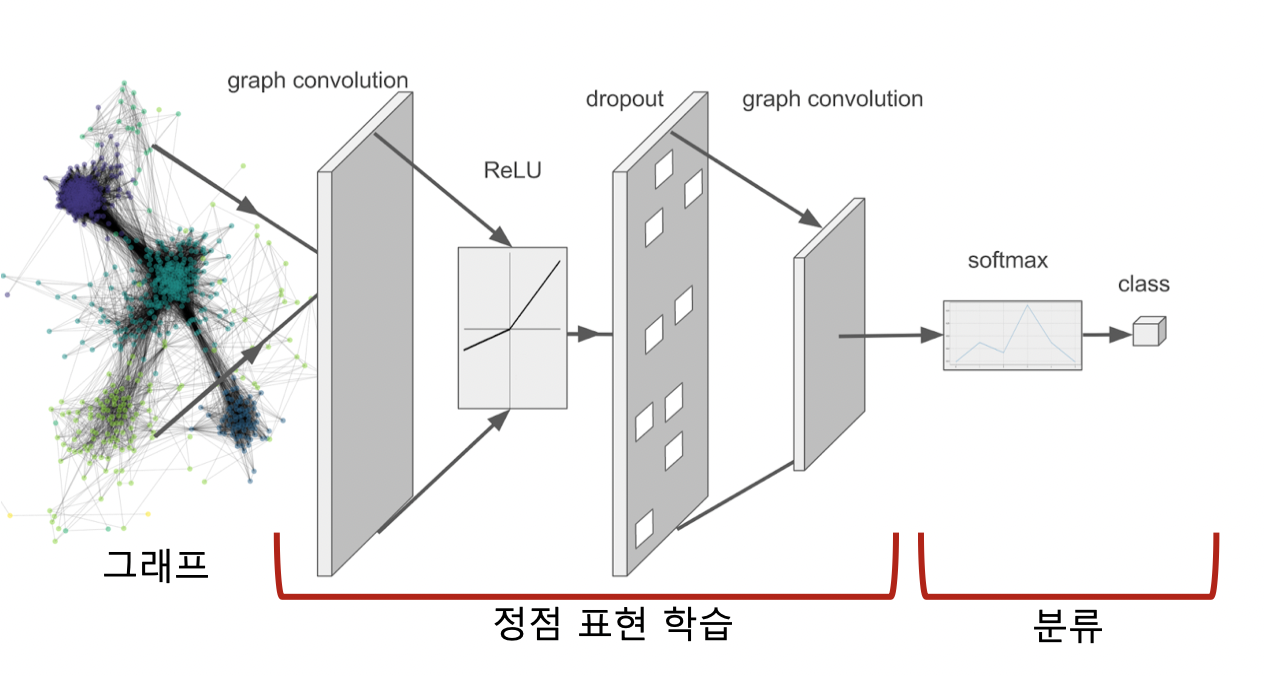
- 정점 분류가 최종 목표
- 그래프 신경망을 통해 정점의 임베딩을 얻음
- 이를 분류기의 입력으로 사용함
- 각 정점의 유형을 분류
- 분류기의 손실함수, 크로스 엔트로피를 전체 프로세스의 손실함수로 사용하여 종단종 학습 가능
- 정점 분류가 최종 목표

- 분류 정확도가 가장 높게끔 그래프 신경망의 학습 변수들을 학습
-
그래프 신경망의 종단종 학습을 통한 분류는 변환적 정점 임베딩 후 별도의 분류기를 학습하는 것보다 성능이 좋음 (정확도가 높음)
-
학습에 모든 정점을 사용할 필요 없음. 일부 선택해서 그래프 신경망 학습하면 됨. 층마다 학습 변수가 있기 때문!
-
마지막으로 백프로파게이션을 통해 손실 함수 최소화 (학습)
-
학습 완료되면 학습에 사용하지 않은 정점의 임베딩 얻을 수 있음
→ 새로 추가된 정점도 임베딩 가능
→ 심지어 한 그래프로 학습하고, 다른 그래프에도 적용 가능
그래프 신경망 변형
그래프 합성곱 신경망
- 다양한 형태의 집계 함수 사용 가능
- GCN (Graph Convolutional Network) 의 집계 함수
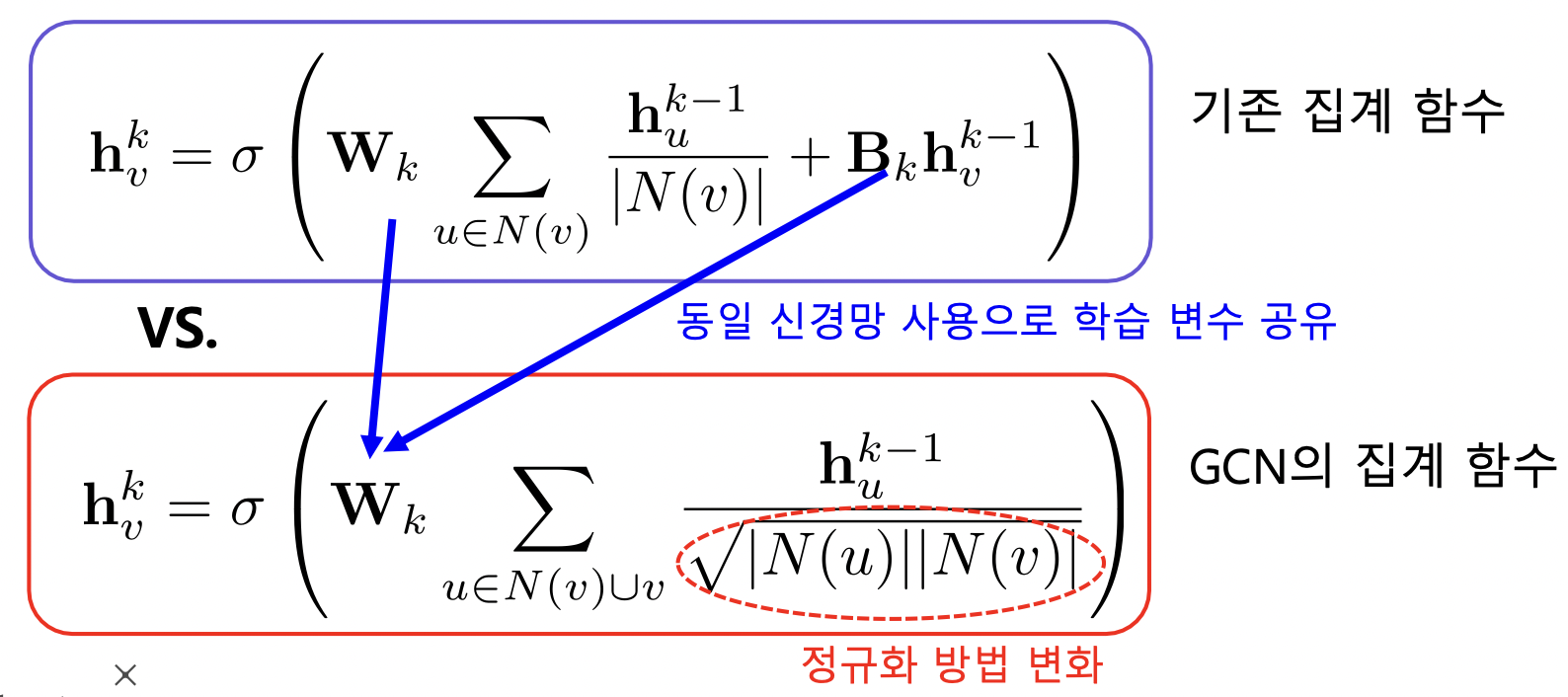
- B 로 이전 신경망 들어오는거 없어짐
- 정규화 방법이 기하 평균으로 변함
GraphSAGE
- 집계 함수
- AGG 함수 (어그리게이션) 를 이용해 이웃의 임베딩을 합친 후 자신의 임베딩과 연결함

- AGG 함수로는 Mean, Pool, LSTM 등 사용 가능
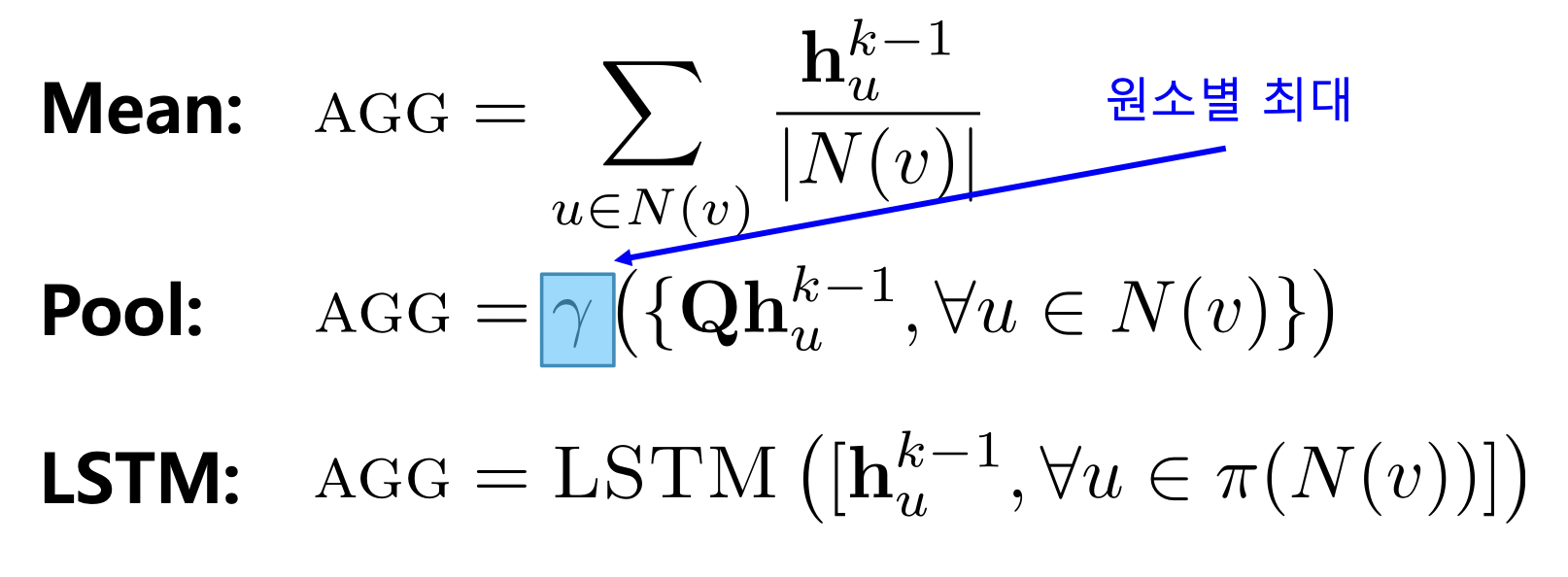
합성곱 신경망 (CNN) 과의 비교
합성곱 신경망과 그래프 신경망의 유사성
- 합성곱 신경망과 그래프 신경망은 모두 이웃의 정보를 집계하는 과정 반복
- 구체적으로 합성곱 신경망은 이웃 픽셀의 정보를 집계하는 과정 반복
합성곱 신경망과 그래프 신경망의 차이
- 합성곱 신경망에서는 이웃의 수가 균일하지만, 그래프 신경망은 아님 (정점 별로 집계하는 이웃의 수가 다름)
- 그래프의 인접 행렬에 합성곱 신경망을 적용하면 효과적일까?
- 그래프에는 합성곱 신경망이 아닌 그래프 신경망을 적용해야함 (흔히 범하는 실수)
- 합성곱 신경망이 주로 쓰이는 이미지에서는 인접 픽셀이 유용한 정보를 담고 있을 가능성이 높음
- 하지만 그래프의 인접 행렬에서 인접 원소는 제한된 정보를 가짐, 특히 인접 행렬의 행과 열의 순서가 임의로 결정되는 경우가 많음
Further Reading
그래프 신경망이란 무엇일까? (심화)
그래프 신경망에서의 어텐션
기본 그래프 신경망의 한계
- 기본 그래프 신경망에서는 이웃들의 정보를 동일한 가중치로 평균냄
- 그래프 합성곱 신경망 역시 단순히 연결성을 고려한 가중치로 평균냄
- 즉, 더 친한 친구 등 관계에 대한 가중치가 고려되지 않음
그래프 어텐션 신경망
- 그래프 어텐션 신경망 (Graph Attention Network, GAT) 에서는 가중치 자체도 학습
- 실제 그래프에서는 이웃 별로 미치는 영향이 다를 수 있기 때문
- 가중치를 학습하기 위해 셀프-어텐션이 사용됨

- 각 층에서 정점 i 로부터 이웃 j 로의 가중치 는 세 단계를 통해 계산됨
- 1) 해당 층의 정점 i 의 임베딩 에 신경망 W 를 곱해 새로운 임베딩을 얻음
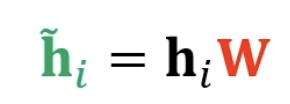
- 2) 정점 i 와 정점 j 의 새로운 임베딩을 연결 (컨캣) 한 후, 어텐션 계수 a 를 내적함. 어텐션 계수 a 는 모든 정점이 공유하는 학습 변수

- 3) 2)의 결과에 소프트맥스 적용
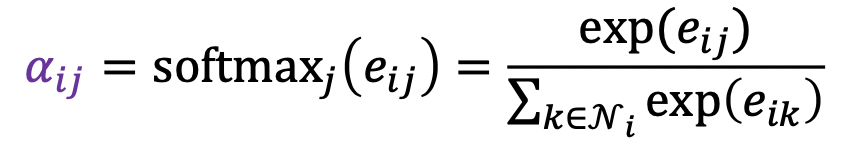
- 여러 개의 어텐션을 동시에 학습한 뒤, 결과를 연결하여 사용 → 멀티헤드 어텐션
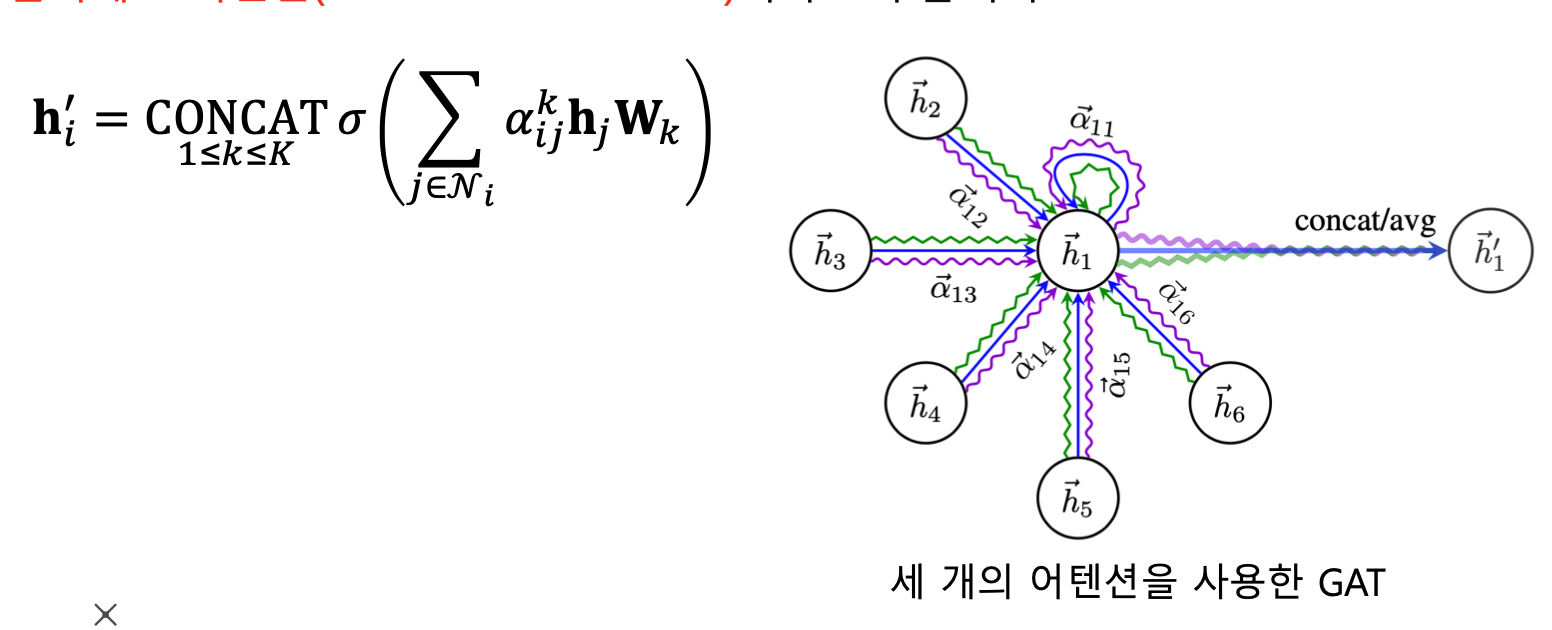
- GAT 가 GCN 보다 정확도가 향상됨
그래프 표현 학습과 그래프 풀링
그래프 표현 학습
- 그래프 표현 학습 or 그래프 임베딩은 그래프 전체를 벡터의 형태로 표현하는 것 (개별 정점으 다루는 정점 표현 학습과 구분됨)
- 그래프 임베딩은 벡터의 형태로 표현된 그래프 자체를 의미하기도 함
- 그래프 임베딩은 그래프 분류 등에 활용
- 그래프로 표현된 화합물의 분자 구조로부터 특성을 예측하는 것이 한가지 예시
그래프 풀링
- 그래프 풀링이란 정점 임베딩들로부터 그래프 임베딩을 얻는 과정
- 평균 등 단순한 방법보다 그래프의 구조를 고려한 방법을 사용할 경우 그래프 분류 등 후속 과제에서 더 높은 성능을 얻음
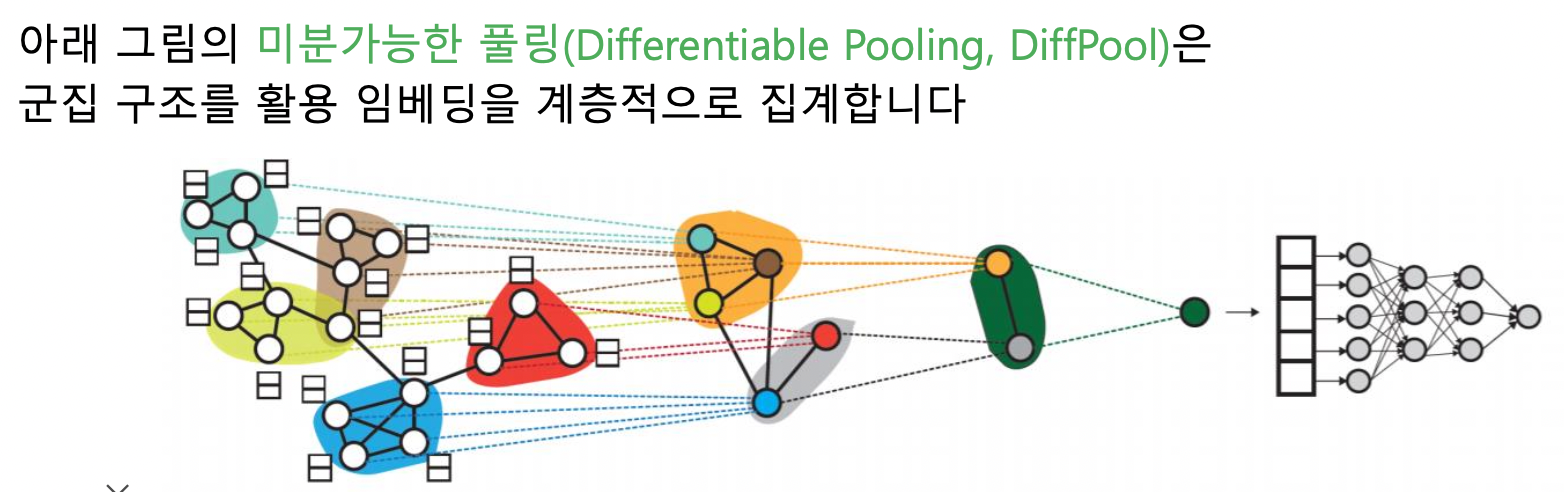
- DiffPool
- 정점별 임베딩 → 군집별 임베딩 → 군집의 군집 임베딩 → 최종 벡터 → 분류 문제 사용
- 그래프 신경망으로 임베딩 얻기, 군집 얻기, 군집 내 합산 총 세 종류의 곳에서 그래프 신경망이 활용
지나친 획일화 문제
개념
- 지나친 획일화 (Over-smoothing) 문제란 그래프 신경망 층의 수가 증가하면서 정점의 임베딩이 서로 유사해지는 현상
- 작은 세상 효과와 관련 있음, 정점 간 거리가 너무 가까워서 문제
- 적은 수의 층으로도 다수의 정점에 의해 영향 받음, 즉 층이 적어도 다수의 정점을 보면 그래프 전반을 보기 때문에 모두 비슷해짐
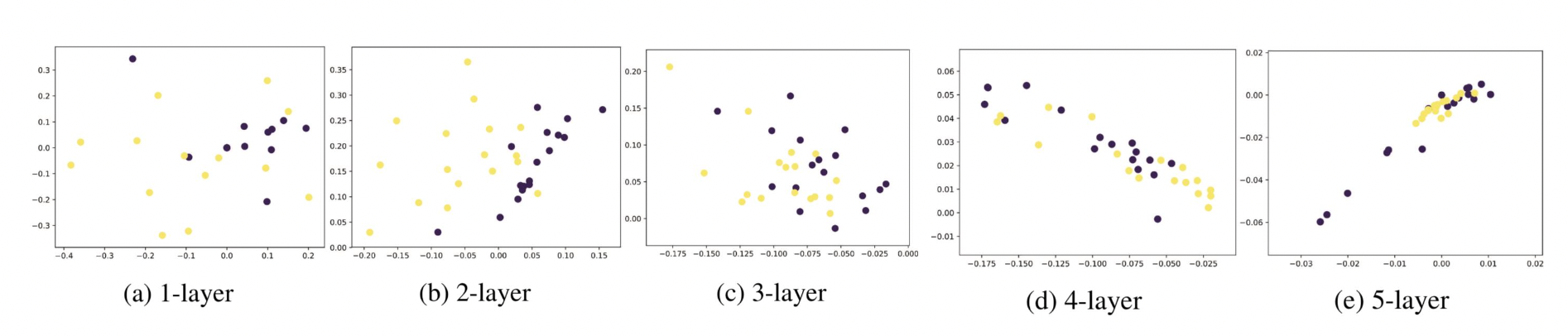
- 결과적으로 그래프 신경망 층의 수를 늘렸을 때, 후속 과제에서 정확도가 감소함
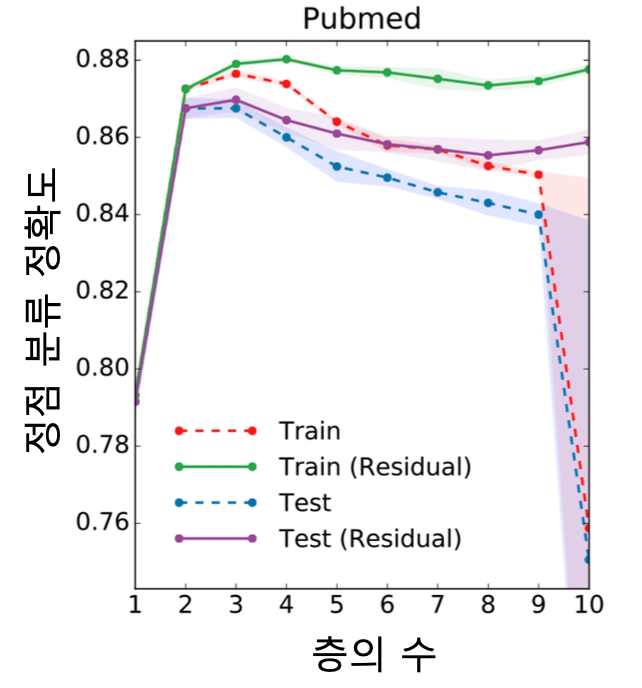
- 그래프 신경망의 층이 2 or 3 개일 때 정확도가 가장 높음
- 문제 해결을 위해 잔차항 (Residual) 을 넣음, 하지만 여전히 문제가 있음
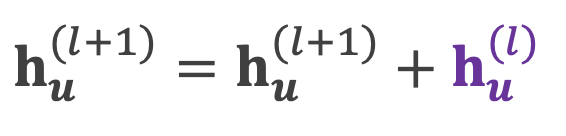
지나친 획일화 문제에 대한 대응
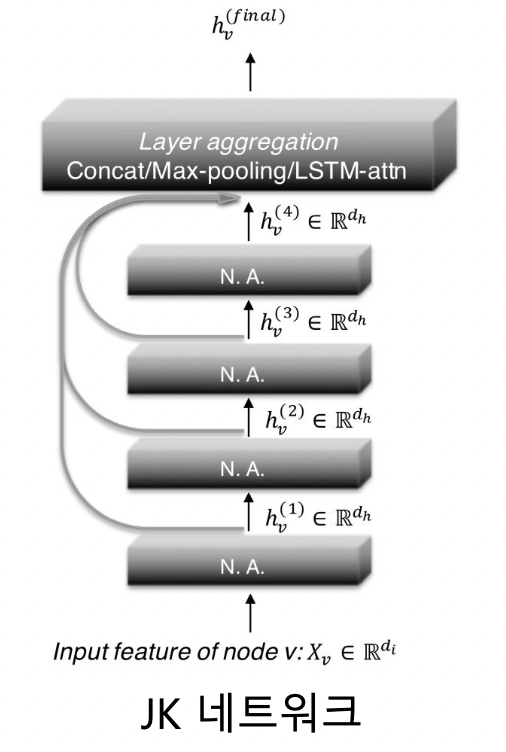
- JK 네트워크 (Jumping Knowledge Network) 는 마지막 층의 임베딩 뿐 아니라, 모든 층의 임베딩을 함께 사용함
- APPNP 라는 그래프 신경망에서는 0번째 층에만 신경망을 사용함 (W 곱하기)
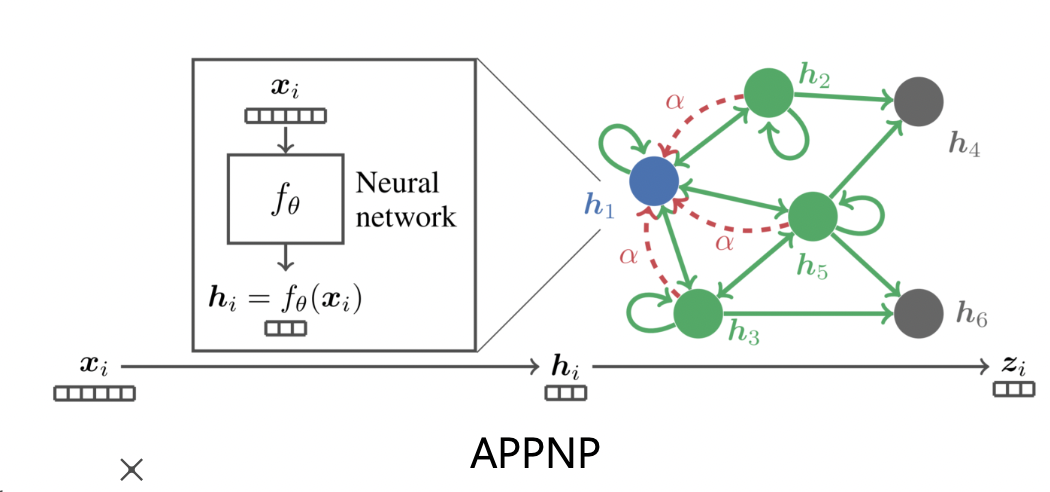
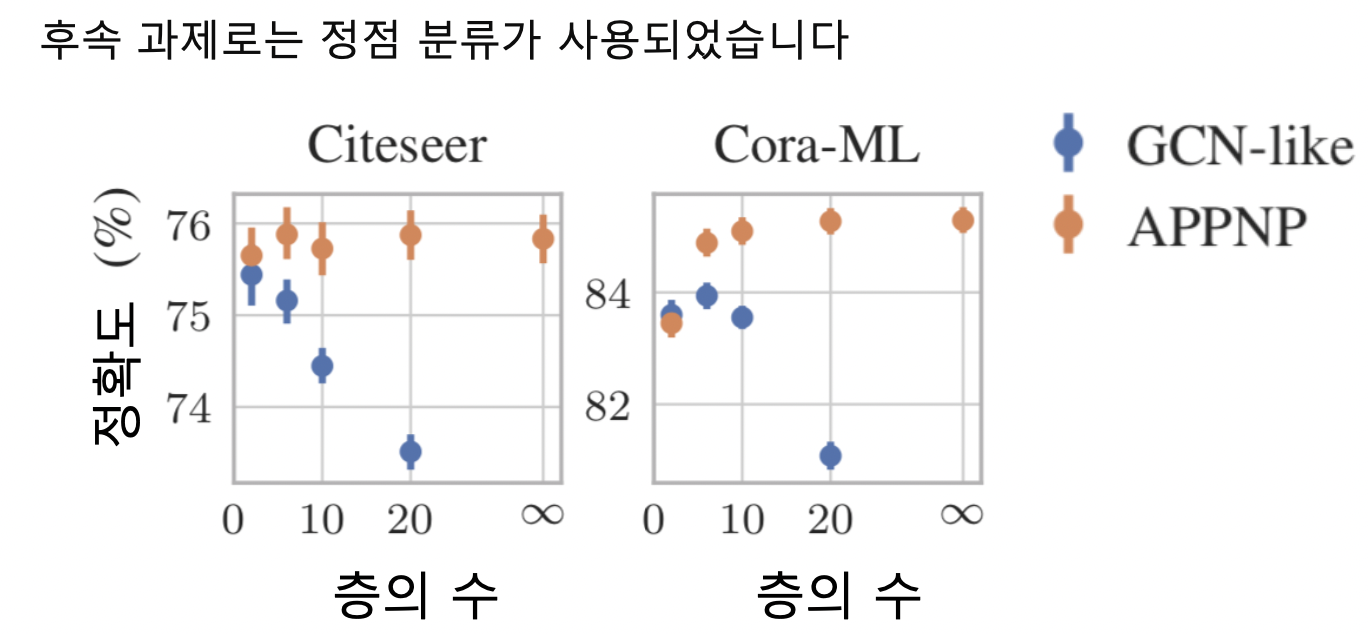
- 두 방법 모두 효과 있음
- 특히 APPNP 의 경우, 층의 수 증가에 따른 정확도 감소 효과가 없음을 확인
그래프 데이터의 증강
그래프 데이터 증강
- CNN 에서는 이미지 augmentation 을 통해 데이터를 증강했음
- Data Augmentation, 데이터 증강은 다양한 기계학습 분야에서 효과적
- 그래프에서도 누락되거나 부정확한 간선이 있을 수 있고, 데이터 증강을 통해 보완 가능
- 임의 보행을 통해 정점간 유사도를 계산하고, 유사도가 높은 정점 간의 간선을 추가하는 방법 제안됨
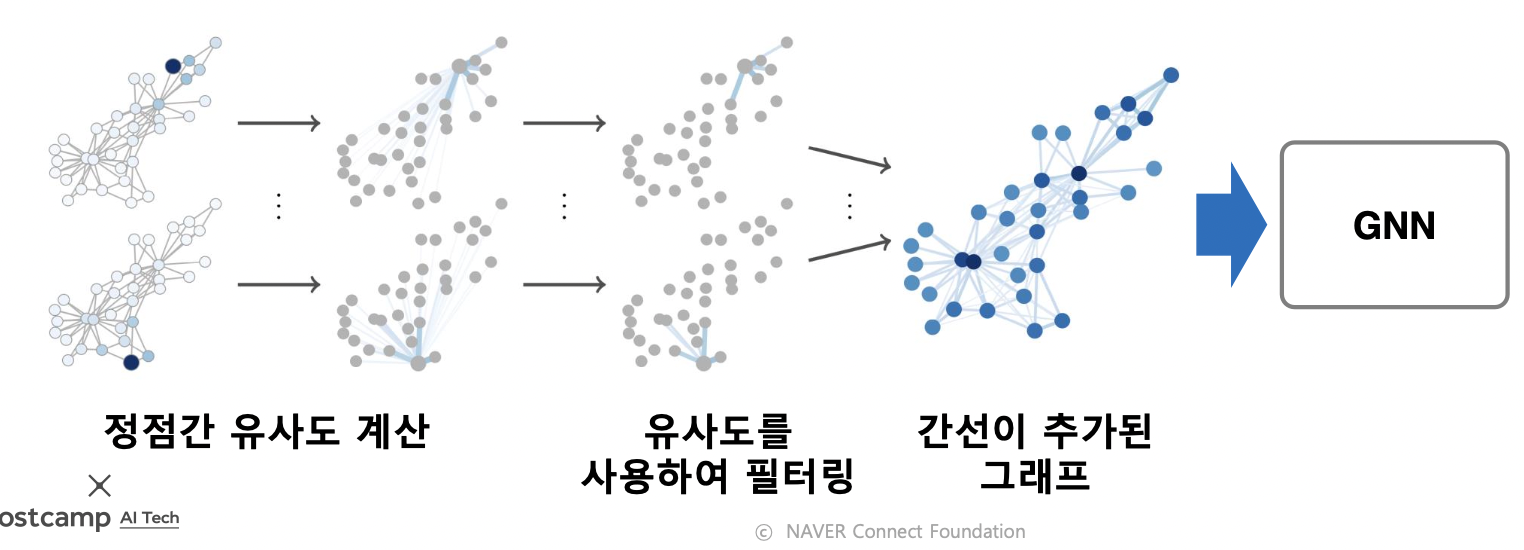
그래프 데이터 증강에 따른 효과
- 정점 분류의 정확도가 개선됨
Further Reading
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.