2021 부스트캠프 Day9
[Day 9] Pandas II / 확률론
Pandas II
Groupby I
- SQL groupby 명령어와 같음
- split -> apply -> combine
df.groupby("Team")["Points"].sum()
# Team : 묶음의 기준이 되는 컬럼
# Points : 적용받는 컬럼
# sum : 적용받는 연산
# 결과 : Team을 기준으로 Points들을 Sum- 한개 이상의 column을 묶을 수 있음
df.groupby(["Team", "Year"])["Points"].sum()Hierarchical index
- Groupby명령의 결과물도 결국 dataframe
- 두 개의 column으로 groupby를 할 경우, index가 두개 생성
unstack(): Group으로 묶여진 데이터를 matrix 형태로 전환해줌rest_index(): 묶여진 데이터를 분리해준다.
h_index.unstack()swaplevel: index level을 변경할 수 있음
h_index.swaplevel()
h_index.swaplevel().sortlevel(0)operations: index level을 기준으로 기본 연산 수행 가능
h_index.sum(level=0)
h_index.sum(level=1)Groupby II
- grouped : Groupby에 의해 Split된 상태를 추출 가능함
grouped = df.groupby("Team")
for name, groupt in grouped:
print(name)
print(group)get_group(): 특정 key값을 가진 그룹의 정보만 추출 가능
grouped.get_group("Devils")- 추출된 group 정보에는 세 가지 유형의 apply가 가능함
- Aggregation: 요약된 통계정보를 추출해 줌
grouped.agg(sum)
grouped['Points'].agg([np.sum, np.mean, np.std])- Transformation: 해당 정보를 변환해줌
score = lambda x: (x.max())
grouped.transform(score)- Filtration: 특정 정보를 제거 하여 보여주는 필터링 기능
df.groupby('Team').filter(lambda x: len(x) >= 3)Pivot Table
- 우리가 excel에서 보던 것
- Index 축은 groupby와 동일
- column에 추가로 labeling 값을 추가하여, value에 numeric type값을 aggregation 하는 형태
df_phone.pivot_table(["duration"], index=[df_phone.month, df_phone.item], columns=df_phone.network, aggfunc="sum", fill_value=0)Crosstab
- 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용
- Pivot table의 특수한 형태
- User-Item Rating Matrix 등을 만들 때 사용가능
pd.crosstab(index=df_movie.critic, columns=df_movie.title, values=df.movie.rating, aggfunc="first").fillna(0)Merge
- SQL에서 많이 사용하는 Merge와 같은 기능
- 두 개의 데이터를 하나로 합침
pd.merge(df_a, df_b, on='subject_id')
# subject_id를 기준으로 merge
pd.merge(df_a, df_b, left_on='subject_id', right_on='subject_id')
# 두 dataframe이 column이 다를 때
pd.merge(df_a, df_b, on='subject_id', how='left')
# left join
pd.merge(df_a, df_b, on='subject_id', how='right')
# right join
pd.merge(df_a, df_b, on='subject_id', how='outer')
# full(outer) join
pd.merge(df_a, df_b, on='subject_id', how='inner')
# inner join
pd.merge(df_a, df_b, right_index=True, left_index=True)
# index based joinconcat
- 같은 형태의 데이터를 붙이는 연산작업
df_new = pd.condat([df_a, df_b])Mathematics for Artificial Intelligence : 확률론 맛보기
확률론과 딥러닝
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있다.
- 기계학습에서 사용되는 손실함수(loss function)들의 작동원리는 데이터 공간을 통계적으로 해석
- 회귀분석에서 손실함수로 사용되는 L2-노름은 예측오차의 분산을 가장 최소화하는 방향으로 학습
- 분류 문제에서 사용되는 교차 엔트로피(cross-entropy)는 모델예측의 불확실성을 최소화하는 방향으로 학습
- 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야 한다.
확률분포
- 확률변수를 확률분호 D에 따라 이산형(discrete)와 연속형(continuous) 확률변수로 구분
이산확률변수 vs 연속확률변수
- 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
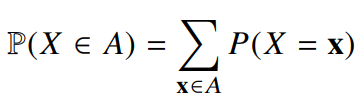
- 연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도(densitiy)위에서의 적분을 통해 모델링
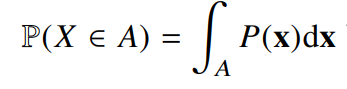
조건부확률과 기계학습
- 조건부 확률 P(y|x)는 입력변수 x에 대해 정답이 y일 확률을 의미
- 로지스틱 회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용
- 분류 문제에서 softmax(W∮+b)는 데이터 x로부터 추출된 특징패턴 ∮(x)과 가중치행렬 W을 통해 조건부확률 P(y|x)을 계산
- 회귀 문제의 경우 조건부기대값 E[y|x]를 추정
- 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴∮을 추출
기대값
- 확률 분포가 주어지면 데이터를 분석하는데 사용 가능한 여러 종류의 통계적 범함수(statistical functional)을 계산
- 기대값(expectation)은 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용
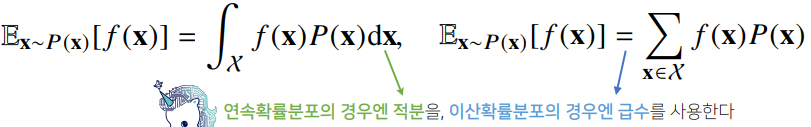
- 기대값을 이용해 분산, 첨도, 공분산 등 여러 통계량을 계산할수 있다.
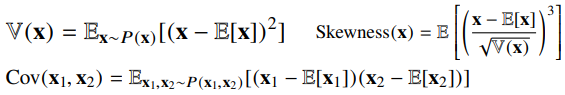
몬테카를로(Monte Carlo) 샘플링
- 기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분
- 확률분포를 모를 때 데이터를 이용하여 기대값을 계산하려면 몬테카를로(Monte Carlo) 샘플링 방법을 사용
- 몬테카를로는 이산형이든 연속형이든 상관없이 성립
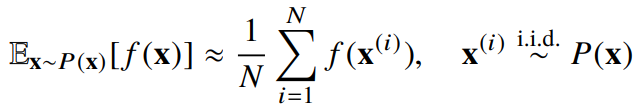
- 몬테카를로 샘플링은 독립추출만 보장한다면 대수의 법칙(law of large number)에 의해 수렴성을 보장

Preparation student who dreams of becoming an AI engineer.