Deview 리뷰
주제 - 생활의달인에 나온 꽈배기 맛집 알고싶으세요? : 질의 의미를 파악해 찾아주는 Deep Local Search
https://tv.naver.com/v/23650677
1. What to do?
먼저, 지역검색의 경우 크게 두가지의 결과를 볼 수 있다.
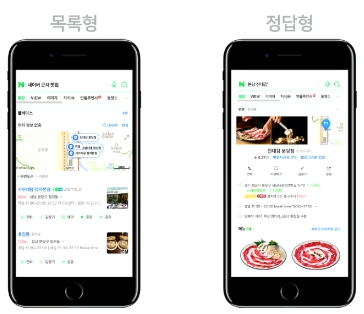
질의가 매우 다양하다.
질의가 목록형을 보여주어야하는 것인지, 정답형을 보여주어야하는 것인지 파악해야한다.
초창기 대응
- 수동으로 3만개 정답형 질의 선정
- 업체 변경 대응의 어려움 (개업, 폐업, 업체 이름 변경 ...)
- 방송출연, 신생 단어 등 trendy 대응의 어려움
현재 대응
- 자동으로 정답형 질의를 추출해야한다.
2가지의 기준으로 추출
- 같은 질의를 했을 때 같은 답을 얻길 원하는가?
- 질의에 대한 답이 적절한가?
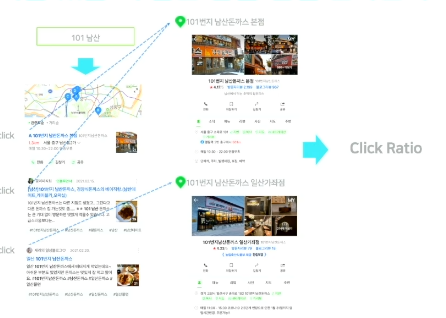
같은 질의를 했을 떄 같은 답을 얻길 원하는가?
- Click Ratio를 통해 판단
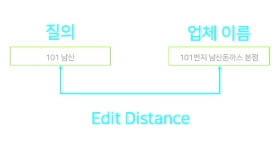
질의에 대한 답이 적절한가?
- edit distance를 통해 판단
최종 process

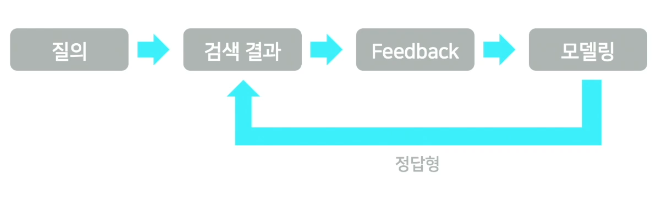
- 여전히 정답형 질의 커버리지가 높지 않았다.
- 그래서 아래 두가지의 방법을 통해 개선했다.
해당 주제 선정 이유
- 검색 개선 인사이트 (불용어, 동의어, tokenize의 문제 해결)
- lexical substitution라는 주제로 연구들이 이루어지고 있다.- 모델 적용 관점
- task당 1개의 tuning model이 아닌 안정성을 높이기 위해 하나의 backbone을 통해 해당 task에 대한 여러 관점의finetuning을 진행
- model의 안정성을 위해 2stage로 process를 구성하여 예측하는 first stage model과 정확한지 판단하는 second stage model을 사용.
2. Matching 개선을 통한 정답형 질의 확장
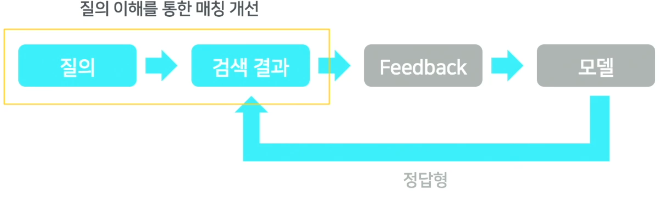
매칭 개선 방법
질의의 의미를 이해해 질의를 변경
- 질의에서 의미적으로 불필요하고 검색에 방해되는 단어를 찾아 제거 -> 불용어
- 댕댕이 병원으로 검색하면 의미적으로 같은 강아지 병원으로도 검색 -> 동의어
질의 변경 (불용어 제거)
질의에서 불용어를 어떻게 판별할까?
-
사용자의 패턴을 통해 알아볼 수 있다.
-
검색질의의 일부 단어 제거 후 검색 & 클릭
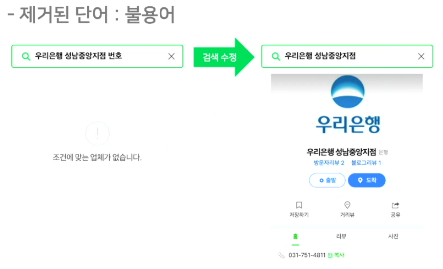
-
검색결과가 나오지 않아 다시 검색 후 클릭을 하게되는 패턴에서 질의에서 제거되는 것들이 불용어
-
이를 확장해 BERT 기반의 질의 불용어 판별 모델 설계
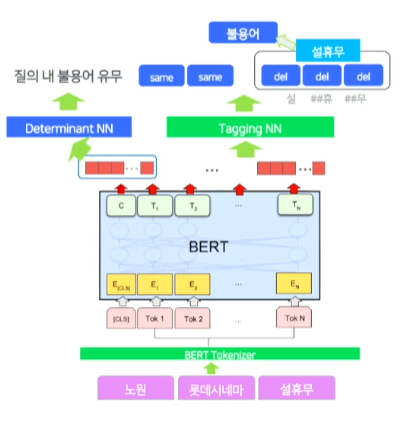
-
질의를 input으로 하고 불용어 유무를 태깅하여 bert token별 output을 통해 판별하는 tagging NN 과정
-
bert sentence output을 통해 질의내에 불용어 유무를 판단하는 Determinant NN 레이어를 따로 두어 학습 안정성을 강화했다.
학습 데이터 구성
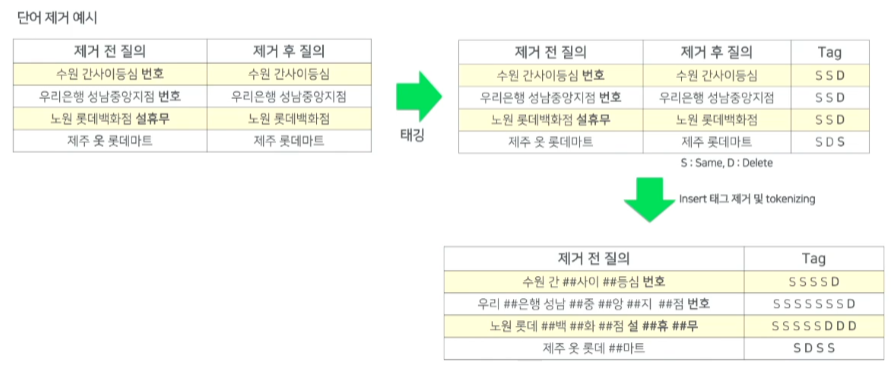
- 위의 사용자들의 패턴을 통해 태그를 추출
- 제거 전 질의에는 검색결과가 없어야 하고, 제거 후 질의에는 검색결과가 적당히 있어야하고 클릭이 되어야 한다.
질의 불용어 판별 모델 실험 결과
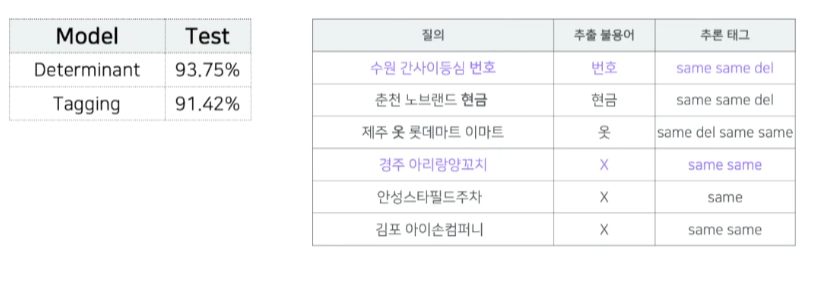
- 수원 간사이등심 번호 같은 경우 번호 라는 불용어가 잘 떨어져 나가는 것을 확인할 수 있다.
- 경주 아리랑양꼬치에서는 불용어가 없다고 판단
질의 변경 (동의어 확대)
두 단어가 동의어인지 어떻게 판단할까?
- 동의질의를 구하는 것은 동의어 사전을 통해
- 동의어를 구하기 위해서는 두 단어가 동의어인지 판단할 수 있어야한다.
BERT-based lexical substitution
- Dropout input encoding
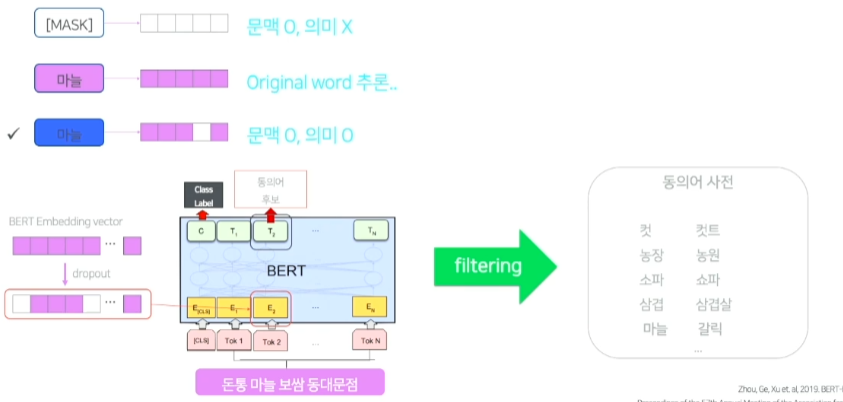
- Bert masking을 사용해, mask된 부분의 단어의 output 이 동의어 후보가 된다.
- 하지만 원래 단어를 그냥 마스킹하면 문맥은 살아있지만 원래 단어의 의미를 잃어버리는 경우가 있다.
- 또 원래단어를 그대로 input embedding vector에 넣어주면 원래 단어를 동의어 후보로 뽑기 때문에 문제가 된다.
- 그래서 원래 단어의 의미를 주면서 다른 후보 단어를 찾기 위해 원래 단어의 임베딩 벡터를 dropout하여 input으로 넣어주어 동의어 후보를 구한다.
Lexical substitution
- 문장의 맥락에서 단어의 대체를 식별하는 task, 즉 문장의 의미를 유지한채 단어를 치환해주는 task
- 동의어 찾기와 맥락 의미 유지(ex. 하위 및 상위어 : car(자동차) -> vehicle(탈것)) 두가지로 연구가 이루어짐
- 대부분의 선행연구는 동의어 찾기에 초점이 맞춰짐
- Word Sense Induction(WSI)라는 큰 범위안의 keyword
benchmark
LS07(SemEval2007-task 02 : McCarthy and Navigli, 2007)
LS14(CoInCO: Kremer et al., 2014)

BERT-based Lexical Substitution
2019. beihan Univ, Microsoft.
NLP top tier - ACL 2019
https://aclanthology.org/P19-1328.pdf
- 이전의 w2v을 통한 연구들에 비해 문맥적인 의미를 더 살릴 수 있다.
- Dropout Embedding 개념 도입
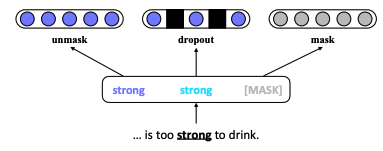
- 기존 단어로 구성된 문장과 치환된 단어로 구성된 문장을 검증.
- 이 때 BERT top four layer의 respresentation을 concat해서 사용한다.
- 대회를 위해 자료를 찾아보면 last n layer representation, top n layer representation을 이용하는 방법은 kaggle에서도 가끔 사용하는 방식.
- 논문에서는 representation을 통해 Candidate Proposal score와 Candidate Validation(contextualized representation simiarity) score를 합하여 최종 score를 계산하여 최종 후보군을 찾는 방법을 제안한다.
네이버에서는 Dropout Embedding과정은 그대로 채택하여 사용한 것 같지만, Tokenize vocab size의 문제점 개선을 위해 validation 과정은 앞서 말한 내용과 같이 w2v을 이용한 새로운 모델을 통해 진행한것 같다.
LexSubCon framework
2021.7.11 https://arxiv.org/pdf/2107.05132v1.pdf
-
검증 과정 변형
-
2개의 score -> 4개의 score
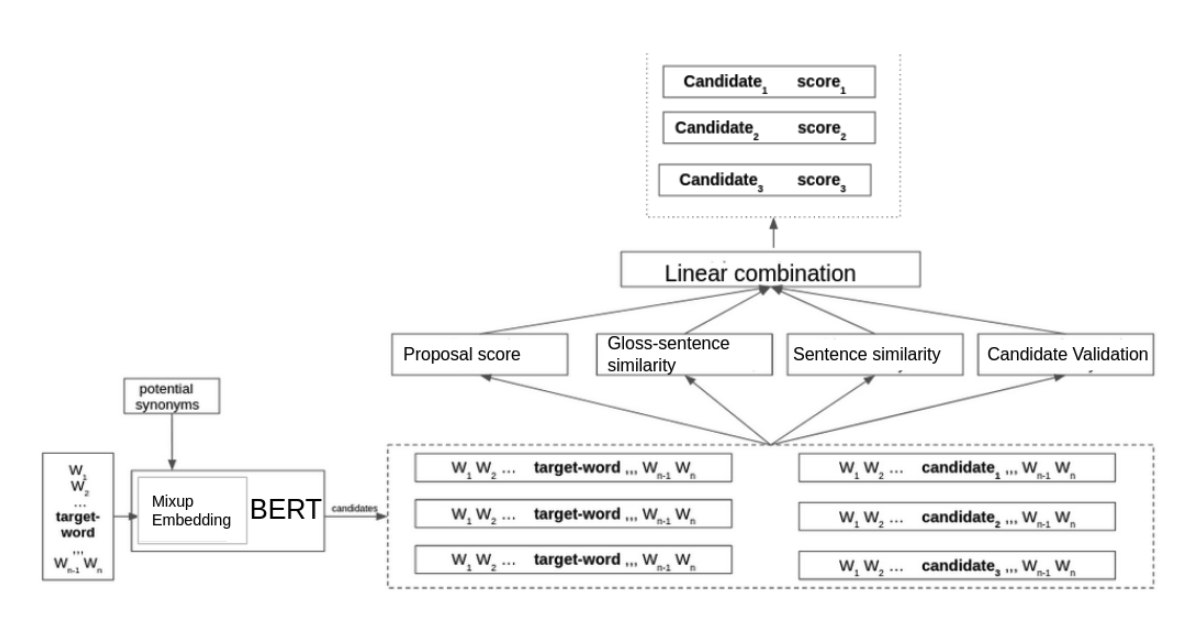
-
총 4개의 validation과정을 사용하여 최종 score를 산정후 최종 후보군 구성.
(proposal score, Gloss-sentence similarity, Sentence similarity, Candidate Validation) -
Bert 단어 사전에서 찾는 것 보다 WordNet을 이용해 위 score를 통해 검증된 후보군들에서 최종 후보군을 구성
WordNet
George A. Miller. 1995. Wordnet: A lexical database for english. Commun. ACM, 38 -
결과
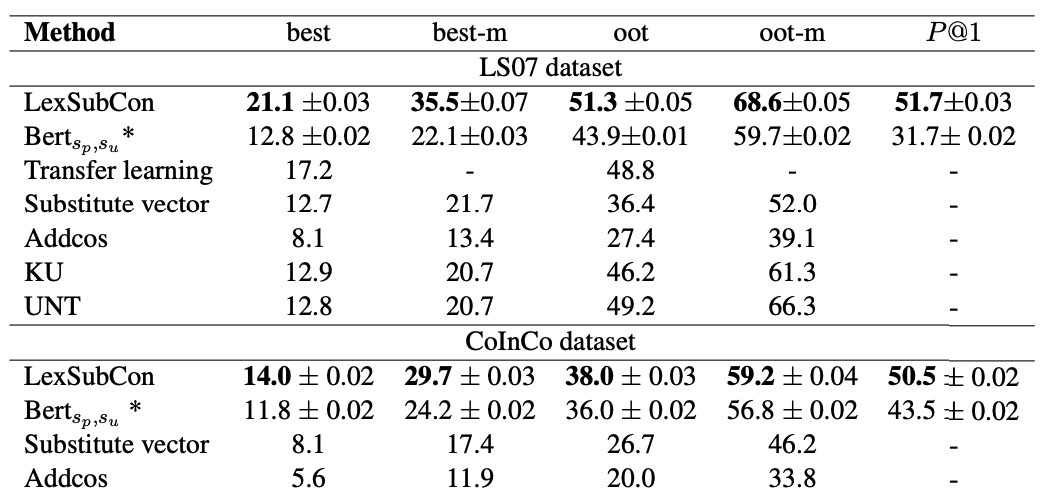
Samsung-LexSubGen
Always Keep your Target in Mind: Studying Semantics and
Improving Performance of Neural Lexical Substitution
NLP top tier COLING2020
paper : https://aclanthology.org/2020.coling-main.107.pdf
github : https://github.com/Samsung/LexSubGen
- 여러 실험에 대한 내용
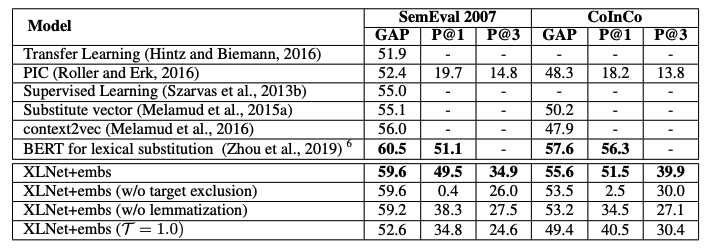
- BERT for lexical substitution이 성능은 제일 좋다.
- 동의어를 단순 유사한 단어라고 정의하기에는 애매하기에 조금더 섬세한 정의를 내리고 비교.
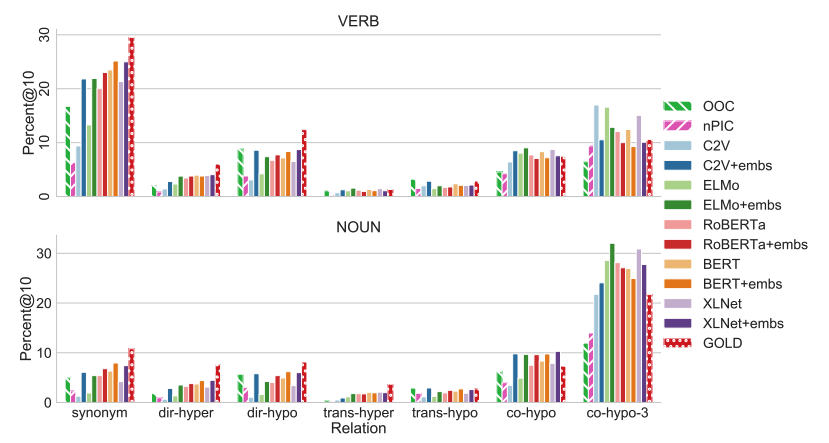
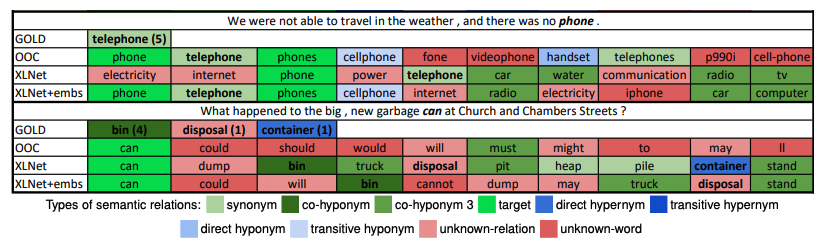
문제점
- 다시 데뷰의 동의어판별 Task로 돌아와서 Tokenizing에서 Token단위로 예측이 이루어지므로 한계가 있다.
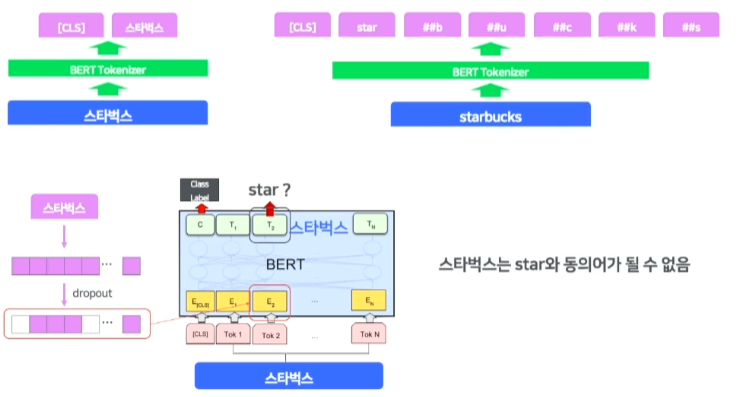
-> Tokenizing 문제가 없는 방법을 찾아야 했다.
동의어 판단 모델 디자인
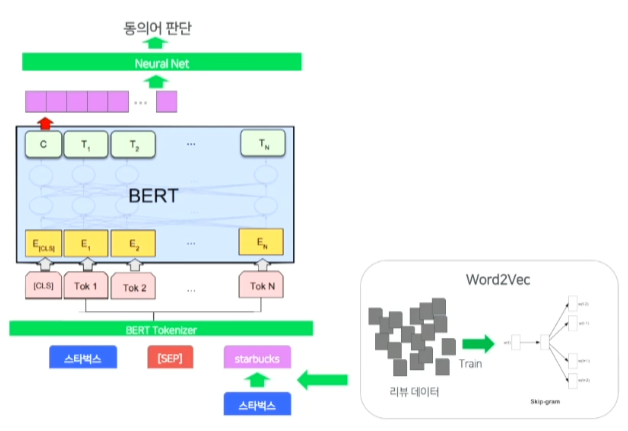
- 더 많은 동의어들을 뽑기 위해
- BERT의 사전이 6만개 정도의 크기로 작기때문에 충분히 많은 단어를 포함할 수 있는 Word2vec을 이용
- 리뷰데이터와 지역 질의를 통해 학습
- 그리고 이 w2v를 이용해 한글 스타벅스와 similarity가 높은 starbucks로 치환하혀 치환된 질의를 만든다.
- 함께 인풋으로 넣어주어 동의어인지 아닌지 판단하는 모델을 설계
- 버트 토크나이징의 제한된 사전크기의 문제를 w2v으로 해결하며 BERT의 sentence이해의 강점을 함께 이용한 모델
학습 데이터 구성
- 지역 검색 질의의 단어 하나를 w2v에서 유사도 높은 단어로 치환하여 치환 질의를 만들어 원래 질의 치환질의 쌍을 구축
- 동의어 사전을 이용해 원래 질의 치환 질의에 대해 동의어 labeling을 진행
(동의어가 있으면 1 없으면 0 -> 이진분류) - 동의어 사전 : 수동으로 구축한 것, 한영 사전, 이전의 토크나이징문제가 있었던 모델로 부터 얻었던 동의어 사전
동의어 추출 모델 실험 결과

- 마지막으로 사람이 직접 판단하여 동의어 사전 구축
서비스 예시
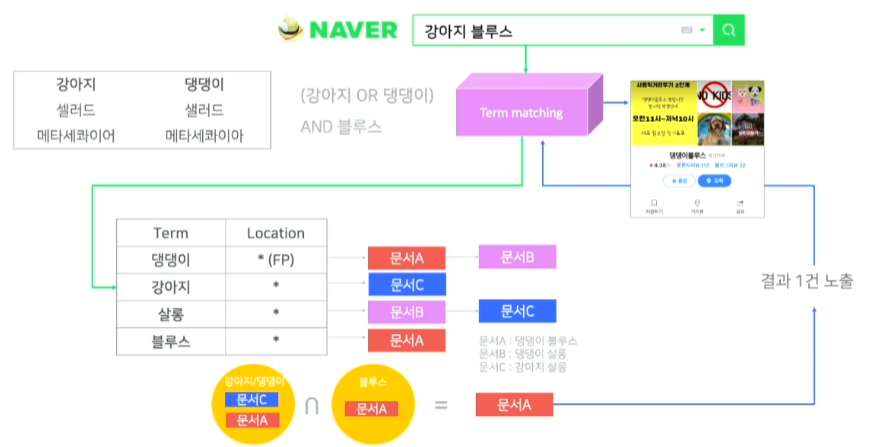
- 동의어 사전을 확장하게 되면 동의어에 대해서도 인덱싱을 하게 되기 때문에 강아지의 경우 댕댕이에 대한 단어에 대해서도 인덱싱을 하게된다.
- 강아지나 댕댕이가 있는 문서는 문서 A와 문서 C이다.
- 블루스 까지 있는 경우는 문서 A이다.
- 따라서 문서 A가 검색결과로 나타난다.
3. Modeling 개선을 통한 정답형 질의 확장
정답형 추출 모델 문제점 / 개선 방안
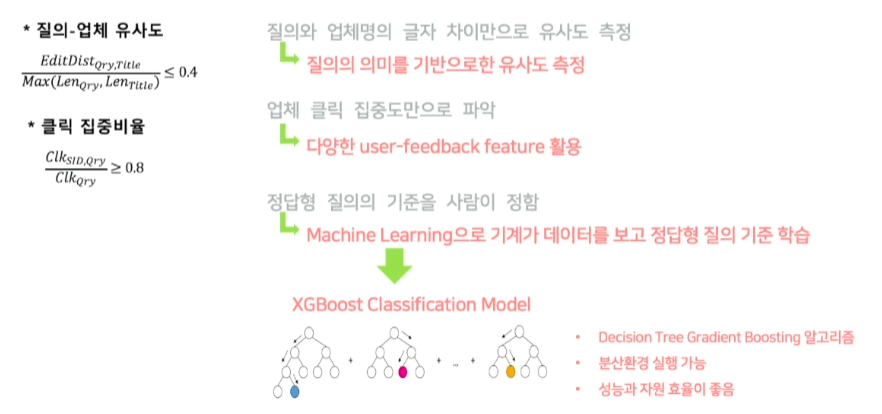
- 기존에는 질의와 업체명을 이용해서만 유사도를 계산했지만 BERT모델을 통해 구할 수 있다.
- 클릭 집중도만으로 파악했다는 것이 문제점 인데 클릭만해도 지역성과 중요성의 다양한 feature를 파악 가능
- 정답형 질의의 기준을 사람이 threshold를 정해서 판단하는 것이 아니라 machine learning으로 해결 -> XGBoost
학습 데이터 구성
- 클릭과 같은 user feedback이 통계적으로 의미를 갖기 위해 월 클릭수가 특정 횟수 이상인 질의로 한정해 구성
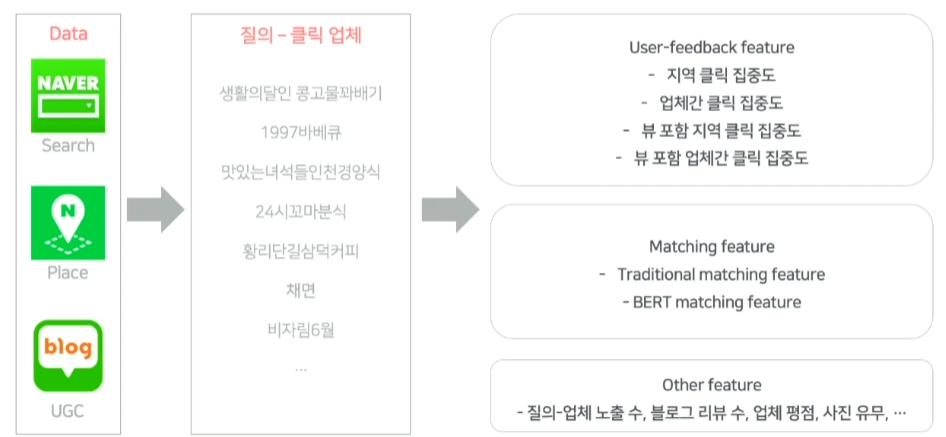
- 지역 클릭 집중도 : 질의와 클릭한 업체를 바탕으로 지역성 질의인지 확인
- tf-idf, bm25와 같은 전통적인 매칭 feature들과 bert를 이용한 의미론적 매칭 feature를 추출
- 또한, 정답형을 내보낼때 최소한의 업체 정보들도 필요하기에 추출
BERT 기반 질의-업체 유사도 feature
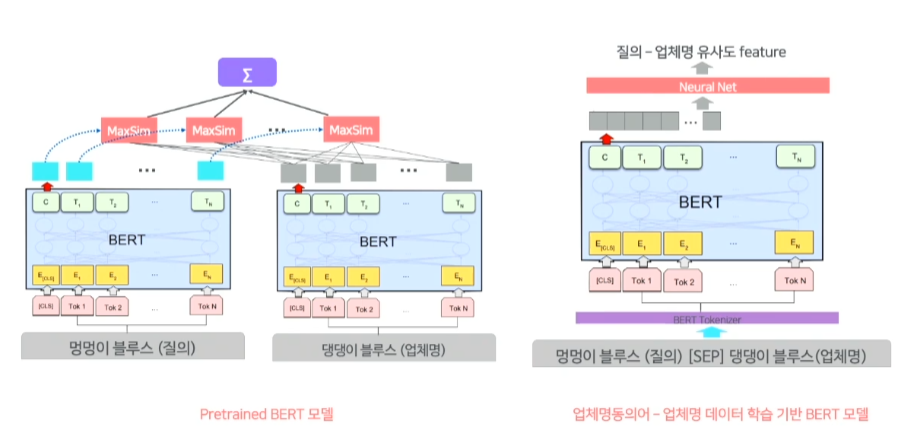
- bert모델을 활용한 의미적인 매칭은 두가지 모델을 활용
-
왼쪽에 보이는 모델은 질의 단어와 업체 문서 단어의 의미유사도 feature를 구하는 과정
-
질의에 있는 멍멍 과 업체명에 있는 블루스와는 의미적으로 유사하지 않다.
-
하지만 업체명에 있는 댕댕과는 가장 유사하다.
-
멍멍 댕댕 두 단어의 output의 cosine similarity가 멍멍 token의 max similarity가 된다.
-
이 과정을 질의의 모든 단어에 반복하여 합을 구하게 되고, normalize하여서 질의-업체 유사도 값을 구하게 된다.
-
오른쪽의 모델은 질의 전체와 업체명 전체의 의미유사도 feature를 구하는 model
-
업체명 동의어와 업체명을 가지고 bert model을 fine-tuning하는 모델
-
업체명 유의어인 멍멍이 블루스와 댕댕이 블루스가 같은 의미인가 모델에 학습하는 과정
-
이 두가지 모델을 통해 질의-업체 유사도를 구한다.
모델 학습 및 정답형 질의 추출 과정
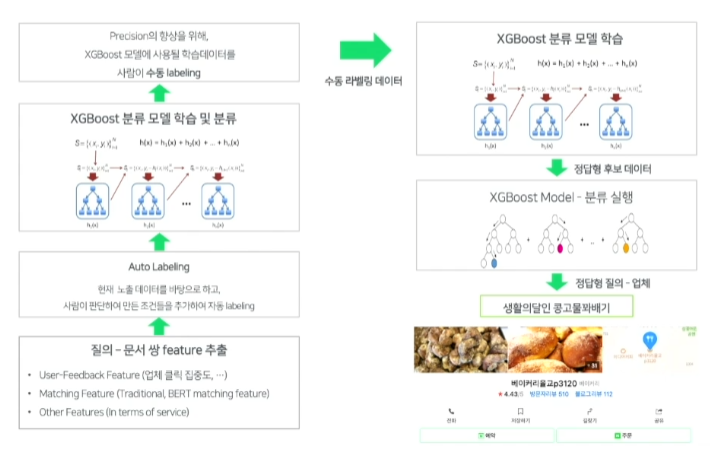
- 이렇게 나온 feature를 바탕으로 학습 데이터를 구성
- 학습 데이터를 만들때, 정답형인지 아닌지 labeling을 해야하는데
- 이미 정답형으로 노출되고 있던 data는 positive로 labeling하고, 클릭이 분산되는 경우 negative로 labeling을 했다.
- 이 데이터를 바탕으로 학습 및 분류했지만 이 모델만으로는 precision이 높지 않았다.
- precision향상을 위해 첫번째 모델에서 정답으로 분류되어진 데이터들 중 일부 소량, 애매한 데이터들을 negative가 많도록 사람이 직접 labeling하여 학습
- 다시 학습했고, recall이 20% 감소했지만 precision이 85%->99.7%까지 향상
서비스 적용 결과
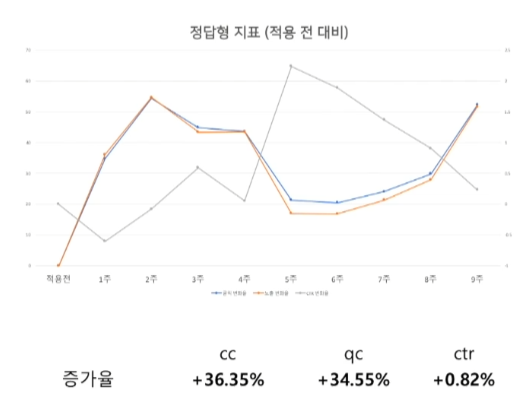
개선해야할 점
- 클릭수가 적은 Long-tail 질의들에 대한 정답형 추출 불가
Long-tail 정답형 확장을 위한 모델링
학습데이터 구성
-
학습데이터는 질의와 문서만으로 정답형을 예측하도록 구성
-
input으로는 질의, 문서
-
output으로는 정답형인지 판단하는 5가지 특성으로 정의
-
이 5가지 특성은 크게 2가지로 정의
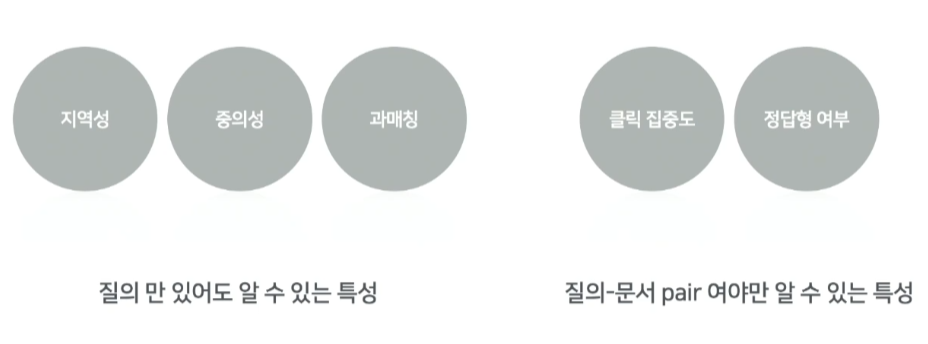
-
지역성 : 질의만으로 이 질의가 지역적인 특성을 지닌 질의인지 여부를 판별
ex. 강남맛집 -> 누가봐도 지역질의- 업체가 노출된 적이 있는지
-
중의성 : 정답형이라는 것은 통범입장에서도 Q&A가 되어야 한다.
ex. 강남맛집은 지역영역이 가장 상위에 위치해야 한다. -> 중의성이 없다 -> 누가봐도 지역질의 but 오아시스 -> 업체가 있어도 밴드가 더 유명하니 지역입장에서는 중의적인 질의- 통합검색에서 지역 영역이 가장 상단에 있는지 여부
-
과매칭 : 질의가 카테고리성이거나 리뷰성이거나 상세정보를 얻는 질의인지 여부를 판단
ex. ---후기 -> 리뷰성- 지역성 질의의 패턴분석을 통해 과매칭 판단

- 지역성 질의의 패턴분석을 통해 과매칭 판단
-
클릭집중도
- 업체 클릭 / 전체업체 클릭 이 특정 비율 이상인지 여부
-
정답형 여부
- 서비스 기준으로 질의-업체 정답형으로 노출되고있는지 여부
정답형 예측 모델
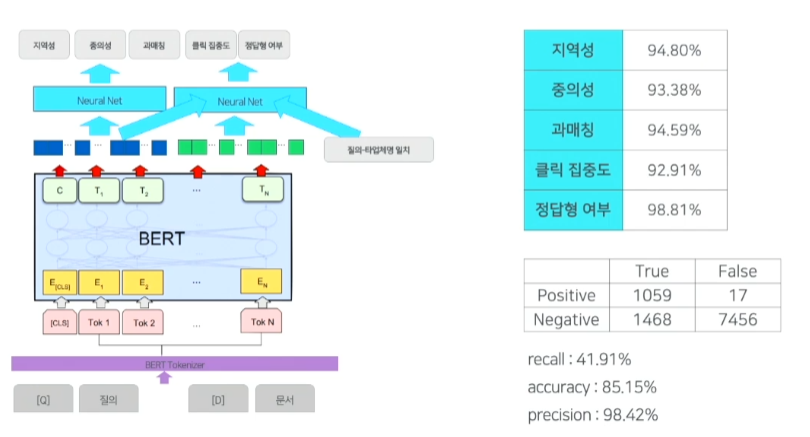
- 정답형 여부만 판단하면되는데 나머지 4개에 대해서도 예측하는 이유는 모델의 안정성 때문이다.
- 다섯가지를 모두 만족하는 경우에만 정답형으로 선정
- 아직 더 개선진행중
