수식 인식이란?
-
수식이 있는 image를 입력으로 받아 latex 포맷의 텍스트로 변환하는 task
-
글자를 읽는다 = 글자 찾기 + 글자 인식 = OCR
글자의 위치를 찾는 방법 - Text Localization
- object detection 활용
- Instance Segmentation 활용
- Hybrid
- Detection, Segmentation 알고리즘을 모두 활용
글자를 인식하는 방법 -Text Recognition
- cnn을 활용하여 Image Feature를 뽑고,
- 인식은
- 전체 단어를 한번에 인식- Character의 Sequence로 인식
OCR에서는
- text가 1줄
- 읽는 순서는 좌 -> 우
수식 인식에서는
- 2줄 이상인 경우
- 읽는 순서도 좌 -> 우, 상-> 하, 하->상 다양함
이번 대회에서는
- Localization 되어 있는 data를 이용하여
- Recognition을 얼마나 잘하는지를 평가
생각 정리
- binary classification 으로 손글씨, 프린팅글씨를 분류하고 진행하면 어떨까?
- GAN과 같은 이미지 생성기술로 글자만 뽑아낼수 있을까?
- labeled image가 없기에 self-supervised learning으로 하거나,
- 이 방법으로 할 경우 정확도에대한 신뢰성이 떨어질 것 같다. - 외부데이터를 찾아보아야 할 것 같다.
- labeled image가 없기에 self-supervised learning으로 하거나,
Data cleaning
EDA를 진행하며 data에 대해 너무 많은 방해요소들이 섞여있었고, 이를 보완해줄 방법을 찾던 중, OCR에서는 Data cleaning의 과정 또한 중요하다는 것을 알게 되었다.
이미지를 읽고 cv2.copyMakeBorder로 이미지의 weight, height의 10%를 추가로 [0,0,0] color를 주고 padding을 시켰다.
- padding을 안줬을 떄,

- padding을 0,흰색으로 주었을 때,

- padding을 255, 검은색으로 주었을 때,

음영, 흐린부분 등 이 많기에 명암대비를 주기 위해 여러가지 시도를 진행.
- hist normalize
- 전체적으로 이미지가 명암대비를 주었다기보다는 화사해지는 방향으로 밝아진 느낌이 들었고, 추출시에도 데이터가 이상하게 추출되었다.
- CLAHE
- 성공!!!

- 처음에는 tileGridSize를 default인 8x8로 진행하였고, 이를 늘려가며 16x16, 32x32, 64x64 등등으로 바꾸어가며 진행하였지만, 일정 수준이상의 효과를 뽑아내기에는 무리가 있었다.
- 이를 분석해보고, data의 size가 가로, 세로가 크게 차이가 나는 것과 minmax의 차이가 수천이상의 차이가 나는 것을 알게되었다.
- 가로, 세로의 비율에 따라서, tileGridSize를 주었더니 효과가 급격히 좋아졌다.
Thresholding
- CLAHE를 적용한 image를 grayscale로 변환 후, binary, OTSU thresholding을 적용해서 이미지내에서의 Text part를 뽑아낼수 있었다.
- 최종적으로 첫날의 결과는 아래와 같았다.
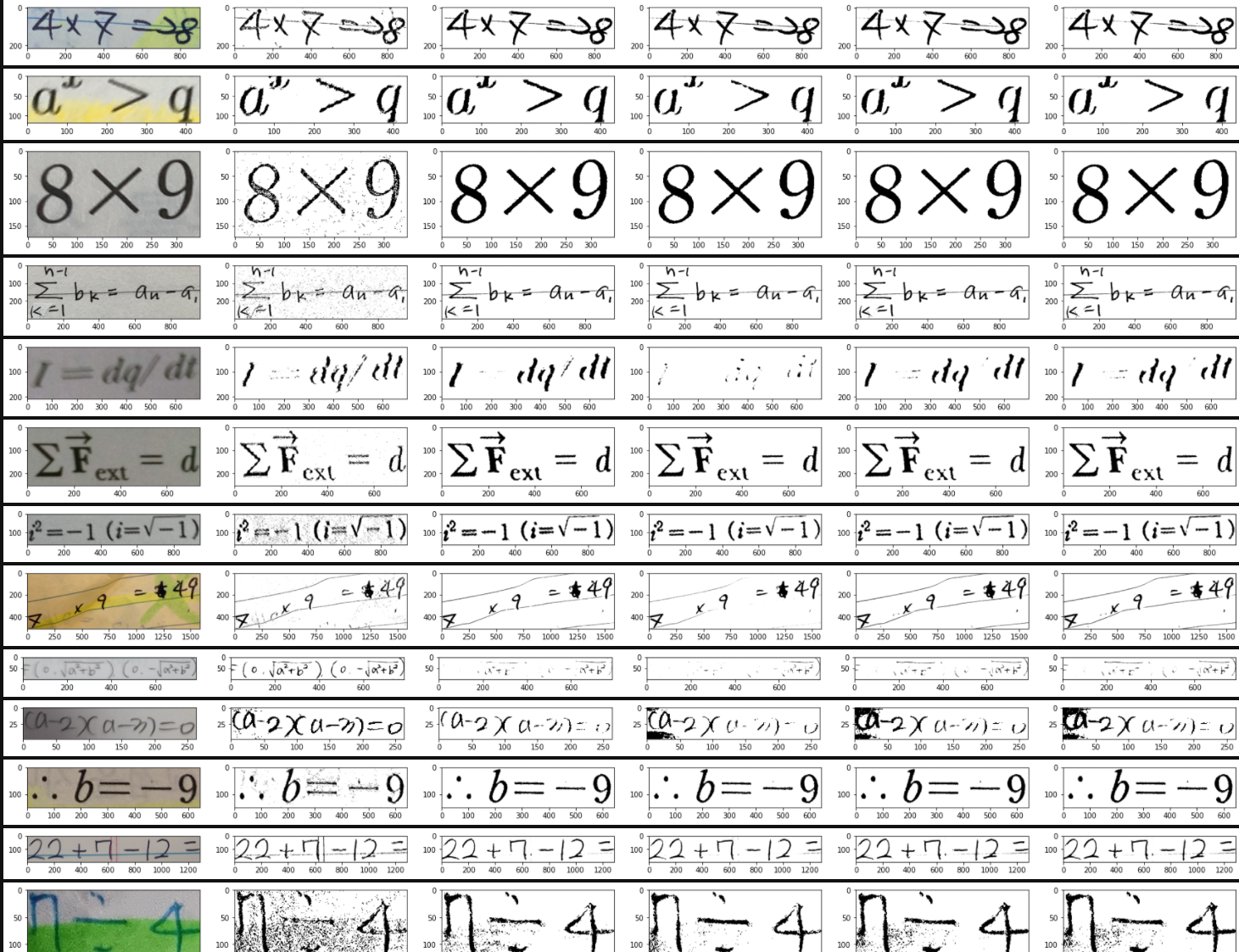
추가 내용
-
위 사진에서 보다시피 size에 관련하여 어느정도 해결을 하였지만, 아직 모든 data에 대해 적용할 수 있는 size에 대한 비율을 찾지는 못했다. 이를 위해 조금 더 연구가 필요할 것 같다.
-
이미지 전체의 약간의 noise들과, Text에 대한 윤곽을 조금 더 뚜렷하게 줄 수있는 filtering을 연구해 보아야 겠다.
-
대학 시절 강의때 들었던 erosion, dilatation, opening, closing, gradient, top hat, black hat의 조합을 잘 구성해서 이를 해결할 수 있을 것 같다.
-
이에 관련하여 자세하게 설명된 link
- 위 첫번째 추가 내용을 해결하면서, filtering과정에 대한 hard filtering과정을 위 cleaning result data를 ground truth로 GAN을 통해 해결하는 방법도 좋을 것 같다는 생각이 들었다.
- GAN을 통해 encoding을 진행하게 되면 Natural flow model을 만들 수 있을 것 같다.
- histogram분포를 통해 흐린이미지를 파악해서 흐린이미지에는 조금더 강하게 gird를 나누어주어 사용하는 것도 좋은 것 같다.
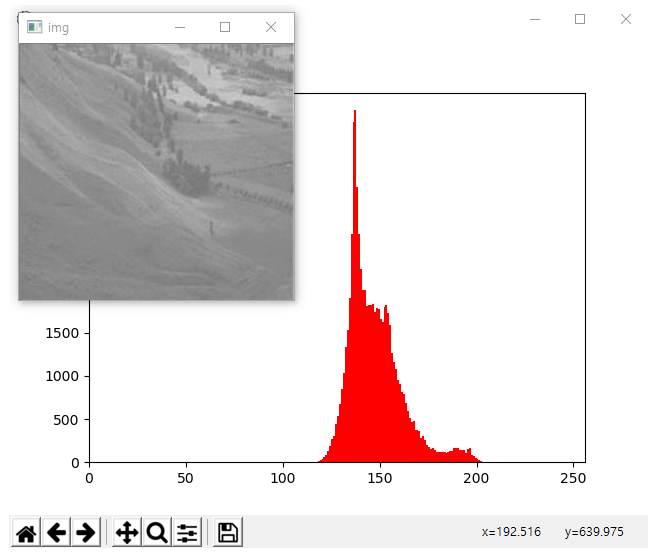
- bitwiseand연산을 통해서 5개정도의 grid를 통해 나온 이미지들을 and연산을 시켜 중복적으로 글씨가 나오는 부분들만을 합치는 것도 좋을 것 같다.

Preparation student who dreams of becoming an AI engineer.