
1. 프로세스와 쓰레드 그리고 태스크
태스크
- 자원소유권의 단위
쓰레드
- 수행의 단위
프로세스
- 동작중인 프로그램 ** 프로그램 : 디스크에 저장되어있는 실행 가능한 형태의 파일 ** 실행가능한 형태의 파일 : 컴파일 과정을 거쳐 얻어진 바이너리 기계 명령어와 수행에 필요한 자료들의 집합으로 구성됨
- 파일 형태로 존재하고 있는 프로그램이 수행되기 위해 리눅스 커널로부터 CPU 등의 자원을 할당받는 동적인 객체
- 커널로부터 할당받은 자신만의 자원을 가짐
- CPU가 기계어 명령들을 실행함에 따라 끊임없이 변화하는 동적인 존재
스케줄링
- 커널이 시스템에 존재하는 여러 개의 프로세스 중 CPU라는 자원을 어느 프로세스에게 할당해 줄 것인가 결정하는 작업
2. 사용자 입장에서 프로세스 구조
텍스트 영역
- 사용자 프로그램 중에서 명령, 함수 등으로 구성
- 프로세스의 주소 공간 중 가장 하위 공간 차지
데이터 영역
- 텍스트 영역의 다음 부분 차지
- 전역 변수 등을 담아놓음
스택 영역
- 함수의 지역변수, 인자, 함수의 리턴 주소 등을 담음
- 사용자 공간과 커널 공간의 경계 위치부터 아래 방향으로 공간을 차지
- 프로그램이 수행됨에 따라 동적으로 변함 → 함수를 호출할 때나 인자나 호출된 함수의 지역 변수를 저장하기 위하여 아래 방향으로 크기가 커짐 ⇒ 함수에서 리턴되면 스택의 크기가 줄어듬
힙 영역
- 프로세스 수행 중에 malloc()/free() 등의 함수를 사용하여 동적으로 할당되는 메모리 공간
- 데이터 영역의 다음 부분 차지
- 아래에서 위쪽 방향으로 자라남
프로세스
- 크게 텍스트, 데이터, 스택, 힙이라는 네 영역으로 구분됨
- 각 영역을 세그먼트 또는 가상 메모리 객체라고 부름
3. 프로세스와 쓰레드의 생성과 수행
프로세스 생성
- fork() 또는 vfork()를 통해 프로세스 생성
- 프로세스가 생성되면 주소공간을 포함하여 이 프로세스를 위한 모든 자원들이 새로이 할당됨
- 자식 프로세스의 연산 결과는 자식 프로세스 주소 공간의 변수에만 영향을 줄 뿐 부모 프로세스 주소 공간의 변수에는 영향이 없음 → 지역 변수, 전역 변수 등의 값이 다르게 출력됨
쓰레드 생성
- 시스템 호출 clone() 또는 라이브러리 pthread(POSIX thread)을 통해 쓰레드 생성
- 쓰레드는 자신을 생성한 태스크와 동일한 pid를 가짐
- 함수의 끝을 만나면 종료됨
- 기존에 수행되던 쓰레드는 자신이 생성한 쓰레드가 변수를 수정하면 그 수정된 결과를 그대로 볼 수 있음
- 새롭게 모든 자원을 생성해줘야 하는 프로세스에 비해 생성에 드는 비용이 비교적 적음

fork() vs vfork()
- fork() : 부모 프로세스의 주소 공간을 복사하여 자식 프로세스의 주소 공간을 따로 만듬
- vfork() : 일단은 같은 주소 공간을 가리킴
⇒ fork() 이후 바로 execl()이 되었을 때 자식 프로세스의 주소 공간을 따로 만들어주는 작업이 불필요한 작업이 됨 ⇒ 이를 해결하기 위해 vfork() 제공
4. 리눅스의 태스크 모델
프로세스
- 자신이 사용하는 자원과 그 자원에서 수행되는 수행 흐름으로 구성됨
- 리눅스에서는 이를 관리하기 위해 각 프로세스마다 task_struct라는 자료 구조 생성
** 리눅스에서는 프로세스가 생성되든 쓰레드가 생성되든 task_struct라는 동일한 자료 구조를 생성하여 관리함
리눅스 커널
- 프로세스 또는 쓰레드 중에서 어떤 것이 요청될 지라도, 모두 task_struct 자료 구조로 동일하게 관리함
- task_struct 자료 구조 중에서 수행 이미지를 공유하는가, 같은 쓰레드 그룹에 속해있는가 등의 여부에 따라 사용자가 프로세스 또는 쓰레드로 해석함
- 1대1 모델을 기반으로 함
- 기존 운영체제와 다르게 리눅스는 프로세스던 쓰레드던 커널 내부에서는 대스크라는 객체로 관리됨 → 태스크가 관리하는 자원을 어떻게 공유하고 접근 제어하느냐에 따라 프로세스로 해석될 수도 있고 쓰레드로 해석될 수 있음
- fork()는 비교적 부모 태스크와 덜 공유하는 태스크이고, clone()은 비교적 부모 태스크와 많이 공유되는 태스크임 → do_fork()를 호출할 때 이 함수의 인자로 부모 태스크와 얼마나 공유할지 정함으로써 fork()와 clone() 함수 둘 다 지원 가능 ** do_fork() : 새로 생성되는 태스크를 위해 일종의 이름표 (task_struct 구조체) 생성 후 태스크가 수행되기 위해 필요한 자원을 할당하여 수행 가능한 상태로 만들어줌
프로세스와 쓰레드 분류
- 시스템에 존재하는 모든 태스크는 유일하게 구분 가능해야 함 → tgid(Thread Group ID) 개념 도입
- 태스크가 생성되면 이 태스크를 위핸 유일한 번호를 pid로 할당
- 프로세스를 원하는 경우 :
- 생성된 태스크의 tgid값을 새로 할당된 pid 값과 동일하게 넣음 → tgid 값도 유일한 번호를 갖게 됨
- clone()의 인자로 CLONE_CHILD_CLEARID 또는 CLONE_CHILD_SETTID로 설정
- 생성된 태스크의 tgid값을 새로 할당된 pid 값과 동일하게 넣음 → tgid 값도 유일한 번호를 갖게 됨
- 쓰레드를 원하는 경우 :
- 부모 쓰레드의 tgid값과 동일한 값으로 생성된 태스크의 tgid를 설정 → 부모 태스크와 자식 태스크는 동일한 tgid를 갖게 되며 동일한 프로세스에 속해 있는 것으로 해석됨
- clone() 인자로 CLONE_THREAD 설정
- 부모 쓰레드의 tgid값과 동일한 값으로 생성된 태스크의 tgid를 설정 → 부모 태스크와 자식 태스크는 동일한 tgid를 갖게 되며 동일한 프로세스에 속해 있는 것으로 해석됨
- 프로세스를 원하는 경우 :
5. 태스크 문맥
문맥
- 태스크와 관련된 ‘모든’ 정보
- 우선순위, CPU 사용량 등의 정보 등, 태스크의 가족관계, 태스크에게 전달된 시그널, 태스크가 사용하고 있는 자원 등의 정보 등 …
- 구분
- 시스템 문맥 (System Context)
- 태스크의 정보를 유지하기 위해 커널이 할당한 자료구조들 ex) task_struct, 파일 디스크립터, 파일 테이블, 세그먼트 테이블, 페이지 테이블 등등
- 태스크의 정보를 유지하기 위해 커널이 할당한 자료구조들 ex) task_struct, 파일 디스크립터, 파일 테이블, 세그먼트 테이블, 페이지 테이블 등등
- 메모리 문맥 (Memory Context)
- 텍스트, 데이터, 스택, heap영역, 스왑 공간 등이 포함됨
- 하드웨어 문맥 (Hardware Context)
- 문맥 교환할 댸 태스크의 현재 실행 위치에 대한 정보를 유지
- 쓰레드 구조 또는 하드웨어 레지스터 문맥이라고도 불림
- 실행 중이던 태스크가 대기 상태나 준비 상태로 전이할 때 이 태스크가 어디까지 실행했는지 기억해두는 공간 → 이후 태스크가 다시 실행ㅇ될 떄 기억해 두었던 곳부터 다시 시작
- 시스템 문맥 (System Context)
task_struct
- task identification
- 태스크를 인식하기 위한 변수들
- pid, tgid, pid, uid, euid, suid, fsuid, gid, egid, sgid, gsgid 등
- state
- 태스크의 생성에서 소멸까지 관리하는 변수
- task relationship
- 태스크는 생성되면서 가족 관계를 가짐
- real_parent, parent 필드 존재
- scheduling information
- 스케줄링과 관련된 변수
- prio, policy, cpus_allowed, time_slice, rt_priority 등
- signal information
- 태스크에게 비동기적인 사건의 발생을 알리는 매커니즘
- signal, sighand, blocked, pending 등
- memory information
- 태스크는 자신의 명령어와 데이터를 텍스트, 데이터, 스택, 그리고 힙 공간 등에 저장
- 위의 공간에 대한 위치와 크기, 접근 제어 정보 등을 관리하는 변수 존재
- 가상 주소를 물리 주소로 변환하기 위한 페이지 디렉터리와 페이지 테이블 등의 주소 변환 정보 존재
- file information
- 태스크가 오픈한 파일 정보를 files이름의 변수로 접근 가능
- 루트 디렉터리의 inode와 현재 디렉터리의 inode는 fs 변수로 접근 가능
- thread structure
- 문맥 교환을 수행할 떄 태스크가 현재 어디까지 실행되었는지 기억해 놓는 공간
- time information
- 태스크가 시작된 시간을 가리키는 start_time, real_start_time 등이 있음
- 사용한 CPU 시간의 통계를 담는 필드 존재
- format
- 다양한 이진 포맷을 지원하기 위한 필드 존재
- resource limits
- 태스크가 사용할 수 있는 자원의 한계 의미
- 자원의 한계가 배열로 구현되어 있으며 최대 16개의 자원에 대한 한계를 설정할 수 있음
6. 상태 전이와 실행 수준 변화
태스크 상태 전이 과정
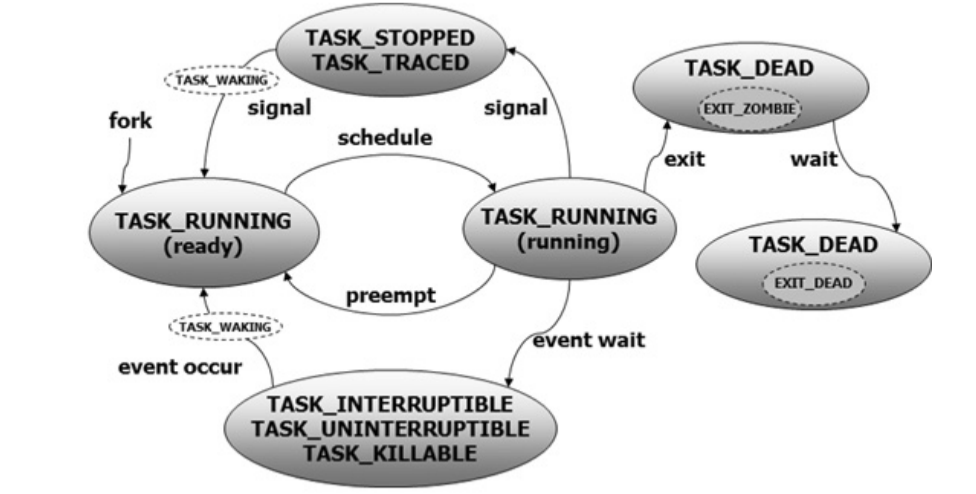
** n개의 CPU를 갖는 시스템에서는 임의의 시점에 최대 n개의 태스크가 실제 실행 상태에 있을 수 있다.
- TASK_RUNNING
- ready : 준비 상태
- running : 실제 CPU를 배정받아 명령어 들을 처리하고 있는 실행 상태
실행 상태 이후
-
TASK_DEAD
- 자신이 해야할 일을 다 끝내고 exit() 호출한 상태
- 보다 구체적으로는 TASK_DEAD(EXIT_ZOMBIE) 상태
- ZOMBIE 상태
- 죽어있는 상태
- 태스크에 할당되어 있던 자원을 대부분 커널에게 반납한 상태
- 자신이 종료된 이후 자신이 사용한 자원의 통계 정보 등을 부모 태스크에게 알려주기 위해 유지되고 있는 상태
- ZOMBIE 상태
- 추후 부모 테스크가 wait()등의 함수를 호출하면 태스크의 상태는 TASK_DEAD(EXIT_DEAD)상태로 바뀌면서 자식의 종료 정보를 넘겨받음
- TASK_DEAD(EXIT_DEAD) 상태의 자식 태스크는 자신이 유지하고 있던 자원을 모두 반환하고 최종 종료
부모 태스크가 자식 태스크에게 wait()등의 함수를 호출하기 전에 먼저 종료된다면?
커널이 코아 태스크의 부모를 init 태스크로 바꿔줌 → init 태스크가 wait()등의 함수를 호출할 때 고아 태스크 최종 소멸 -
running 상태에서 실제 수행되던 태스크가 자신에게 할당된 CPU 시간을 모두 사용하였거나, 보다 높은 우선순위를 가진 태스크로 인해 ready상태로 전환되는 경우
- 여러 태스크들이 CPU를 ‘공평하게’ 사용할 수 있도록 해주기 위해 CFS 기법을 사용하기 때문
-
TASK_STOPPED
- SIGSTOP, SIGSTP, SIGTTIN, SIGTTOU등의 시그널을 받은 태스크가 전이된 상태
- 추후 SIGCONT 시그널을 받아 다시 TASK_RUNNING(ready)상태로 전환됨
- 디버거의 ptrace()호출에 의해 디버깅 되고 있는 태스크는 시그널을 받는 경우 TASK_TRACED 상태로 전이될 수 있음
-
대기 상태(TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_KILLABLE)
- running 상태에 있던 태스크가 특정한 사건을 기다려야 할 필요가 있을 때
- TASK_UNINTERRUPTIBLE의 경우 시그널에 반응하지 않음 → 시그널에 반응하지 않아 생기는 문제점을 해결하기 위해 중요한 시그널에만 반응하는 TASK_KILLABLE 상태 도입
- 대기 상태로 전이한 태스크는 기다리는 사건에 따라 특정 큐에 매달려 대기
- 실행 중이던 태스크가 대기하게 되면 다시 스케줄러가 호출되어 ready상태에 있는 태스크 중 하나를 선택하여 다시 running상태로 만듬 → CPU 효율을 높임
- 태스크가 기다리던 사건이 발생하면 대기상태에 있던 태스크는 다시 ready 상태로 전이하게 되며 다른 태스크들과 함계 스케줄링 되기 위해 경쟁
TASK_RUNNING(running)상태의 태스크
- 실행 권한에 따라 사용자 수준 실행과 커널 수준 실행 상태로 구분할 수 있음
- user level running
- CPU에서 사용자 수준 프로그램의 제작자가 만든 응용 프로그램이나 라이브러리 코드를 수행하고 있는 상태
- 사용자 수준의 권한으로 동작
- kernel level running
- CPU에서 커널 코드의 일부분을 수행하고 있는 상태
- 사용자 수준 권한보다는 더 강력한 커널 권한으로 동작
- 사용자 수준 실행 상태에서 커널 수준 실행 상태로 전이할 수 있는 방법
- 시스템 호출의 사용
- 인터럽트의 발생
7. 런 큐와 스케줄링
스케줄링
- 여러 개의 태스크들 중에서 다음번 수행시킬 태스크를 선택하여 CPU라는 자원을 할당하는 과정
- 리눅스는 실시간 태스크와 일반 태스크로 태스크를 나우어 각각을 위해 별도의 스케줄링 알고리즘을 구현함
- 실시간 태스크는 항상 일반 태스크 보다 우선하여 실행됨
런 큐
- 스케줄링 작업 수행을 위해 수행가능한 상태의 테스크를 관리하는 자료구조
- 리눅스에서는 각 CPU별로 하나씩의 런큐가 유지됨
- TASK_RUNNING 상태인 태스크는 시스템에 존재하는 런 큐 중 하나에 소속됨
-
새로 소속된 태스크는 부모 태스크가 존재하던 런 큐로 삽입
-
대기 상태에서 깨어난 태스크는 대기 전에 수행되던 CPU의 런 큐로 삽입
⇒ 캐시 친화력을 활용하기 위해
-
- 스케줄러가 수행되면 해당 CPU의 런 큐에서 다음번 수행시킬 태스크를 골라냄
- 어떤 태스크를 선택할 것인가
- 일반 태스크 : CFS 사용
- 실시간 태스크 : FIFO, RR, DEADLINE 정책 사용
- 런 큐간의 부하가 균등하지 않은 경우 어떻게 할 것인가.
- 리눅스에서 부하 균등 기법 제공
- 특정 CPU가 많은 작업을 수행하고 있고 다른 CPU가 한가하면 다른 CPU로 태스크를 이주시켜 시스템의 전반적인 성능 향상을 시도
- 어떤 태스크를 선택할 것인가
리눅스 태스크 정책
- 실시간 태스크
- SCHED_FIFO, SCHED_RR, SCHED_DEADLINE
- 일반 태스크
- SCHED_NORMAL, SCHED_IDLE, SCHED_BATCH
실시간 태스크
- SCHED_FIFO, SCHED_RR, SCHED_DEADLINE 정책을 사용하는 태스크 → 실시간 태스크를 생성하는 별도의 함수가 존재하는 것이 아니라 태스크의 스케줄링 정책을 위 세가지 중 하나로 바꾸게 되면 실시간 태스크가 됨
- 실시간 정책을 사용하는 태스크는 고정 우선순위를 가짐 → 우선 순위가 높은 태스크가 낮은 태스크보다 먼저 수행된다는 것을 보장
- 실시간 태스크 중 가장 높은 우선순위의 태스크를 찾기 위해 비트맵 사용
- RR
- 동일 우선순위를 가지는 태스크가 복수개인 경우 타임 슬라이스 기반으로 스케줄링
- 동일 우선 순위를 가지는 태스크가 없는 경우 FIFO와 동일하게 동작
- DEADLINE 정책
- EDF 알고리즘을 구현한 것
- deadline이 가장 가까운 테스크를 스케줄링 대상으로 선정
- 우선순위는 의미가 없음 → 기존 우선순위 기반 스케줄링 정책 대비 기아현상 등의 문제에 효율적임 → 주기성을 가지는 수많은 응용들에 효과적으로 적용 가능
- 현재시간 + runtime < deadline 조건을 만족해야 함
- DEADLINE 정책을 사용하는 태스크들의 runtime 합은 CPU의 최대 처리량을 넘으면 안됨 → 새로운 태스크가 DEADLINE 정책을 사용하려 할 떄 기존 태스크들의 runtime과 period를 이용하여 해당 태스크의 성공적인 완료 여부를 확정적으로 결정할 수 있음 ⇒ 실시간 스케줄링 기법의 가장 중요한 요소
일반 태스크 스케줄링 (CFS)
- 시스템에 존재하는 태스크들에게 공평한 CPU 시간을 할당하는 것을 목표로 함 ** 시간 단위가 길면 태스크의 반응성이 떨어지고, 짧으면 문맥교환으로 인한 오버헤드가 높아지기 떄문에 적절한 값을 설정하는 것이 중요함
- vruntime
- 각 태스그가 가지는 값
- 스케줄링되어 CPU를 사용하는 경우 사용시간과 우선순위를 고려하여 증가됨
- 별도의 지정이 없다면 우선순위는 부모 태스크의 우선순위와 같음
- 항상 실시간 태스크의 우선순위보다 낮은 것이 보장됨
- 우선순위가 높은 태스크의 경우 시간이 느리게 흘러가는 것처럼 관리하고, 우선순위가 낮은 태스크의 경우 시간이 빠르게 흘러가는 것처럼 관리함
- 가장 낮은 vruntime을 가지는 태스크를 빠르게 찾아내기 위해 RBtree 사용
- vruntime 값을 키로 함
- 가장 좌측에 존재하는 태스크가 다음번 스케줄링의 대상이 됨
- 스케줄링된 태스크는 수행 될수록 키값이 증가하여 좌측에서 우측으로 이동되고, 스케줄링 되지 않은 태스크는 대기하는 동안 점점 키값이 상대적으로 감소되어 트리의 좌측으로 이동하게 됨
- 현재 수행중인 태스크의 키값이 다른 태스크보다 커지더라도, 해당 태스크의 타임 슬라이스 혹은 스케줄링간 최소 지연 시간 내에서는 계속 수행 보장
- 리눅스는 각 태스크 별로 선점되지 않고 CPU를 사용할 수 있는 타임 슬라이스가 미리 지정되어 있으며, 타임 슬라이스가 작은 태스크 간의 빈번한 스케줄링을 막기 위해 스케줄링 간 최소 지연 시간도 정의되어 있음
스케줄러 호출
- 어떻게
- schedule()함수 호출
- 현재 수행되고 있는 태스크의 need_resched 필드 설정
- 언제
- 주기적으로 타이머 인터럽트가 발생하는데 이 인터럽트 서비스 루틴이 종료되는 시점에 현재 수행되고 있는 태스크의 need_resched 필드를 보고 스케줄링 할 필요가 있을 때
- 현재 수행되고 있는 태스크가 자신의 타임슬라이스를 모두 사용했거나, 이벤트를 대기하는 경우
- 새로 태스가 생성되거나, 대기 상태의 태스크가 깨어나는 경우
- 현재 태스크가 sched_setscheduler()같은 스케줄링 관련 시스템 콜을 호출할 때
8. 문맥 교환
- 수행 중이던 태스크의 동작을 멈추고 다른 태스크로 전환하는 과정
- 문맥 저장 : 문맥 교환 시점에 어디까지 수행했는지, 현재 CPU의 레지스터 값은 얼마인지 등을 저장 → task_struct thread 필드에 저장
💡 스케줄링이 일어나면 문맥 교환이 발생하고, 문맥 교환 시엔 현재 수행 중이던 태스크의 문맥을 저장해 두어야 한다.
** 문맥 : H/W context를 의미
thread_struct
- 태스크가 실행하다 중단되어야 할 때 태스크가 현재 어디까지 실행했는지 기억하는 공간
- 유지하는 정보
- 어떤 명령어까지 수행하였으며, 다음 수행해야할 명령어가 어디인지
- CPU의 pc 레지스터를 통해 알 수 있음
- 현재 스택의 사용 위치가 어디인지
- CPU의 sp 레지스터를 통해 알 수 있음
- 태스크 실행 중에 이용한 CPU의 범용 레지스터 값들
- CPU 상태, 세그먼트를 관리하는 레지스터 내용 등등
- 어떤 명령어까지 수행하였으며, 다음 수행해야할 명령어가 어디인지
두 태스크 간의 문맥 교환
- 실행 수준 변화에 따른 CPU 레지스터 정보 저장/복원 및 태스크 간의 문맥 교환에 따른 CPU 레지스터 정보 저장/복원이 필요하므로 총 4번의 CPU 레지스터 정보 저장/복원 발생
9. 태스크와 시그널
시그널
- 태스크에게 비동기적인 사건의 발생을 알리는 메커니즘
- 태스크가 시그널을 원활이 처리하기 위해 지원하는 기능
- 다른 태스크에게 시그널을 보낼 수 있어야 함
- 자신에게 시그널이 오면 그 시그널을 수신할 수 있어야 함
- 자신에게 시그널이 오면 그 시그널을 처리할 수 있는 함수를 지정할 수 있어야 함
- 수신한 시그널 처리는 태스크가 커널 수준에서 사용자 수준 실행 상태로 전이할 때 이루어짐
인터럽트 vs 트랩 vs 시그널
- 인터럽트 & 트랩
- 사건의 발생을 커널에게 알리는 방법
- 시그널
- 사건의 발생을 태스크에게 알리는 방법
이 글은 아래의 책을 공부 및 정리한 내용입니다.
리눅스 커널 내부구조 - 예스24

탐험하는 개발자