1. Buffering
-
Blocked oriented device (블록 지향 장치)
-
데이터가 고정된 크기의 블록 단위로 저장된다.
-
데이터가 전송될 때 한번에 한 블록씩 전송된다.
-
블록 번호를 통해 데이터를 참조한다.
-
HDD가 이에 해당한다.
-
-
Stream oriented device (스트림 지향 장치)
-
데이터가 블록 구조 없이 바이트 스트림 형태로 저장된다.
-
데이터가 전송될 때 연속적인 바이트 스트림으로 입출력된다.
-
터미널, 프린터, 마우스 등이 이에 해당한다.
-
-
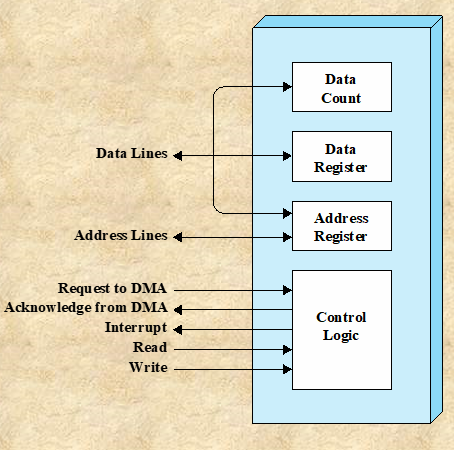
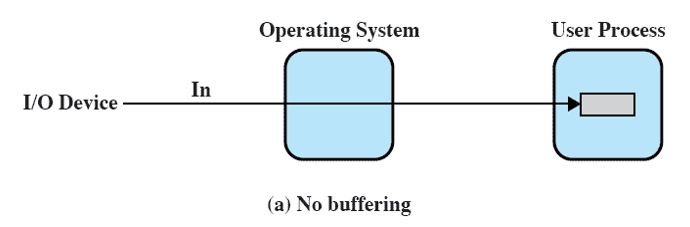
Buffering : I/O Interrupt 기반의 입출력 작업의 처리는 비효율적이므로, 이를 해결하기 위해 Buffering 기법을 도입했다. 버퍼링은 데이터를 처리하는 동안 임시로 저장해두는 메모리 공간(버퍼)을 이용하는 기법이다.
-
입력 버퍼링
- 프로세스가 데이터를 요청하기 전, 데이터를 미리 읽어 버퍼에 저장한다. 이는 나중에 데이터가 필요할 때 버퍼에서 빠르게 읽어오기 위함이다.
-
출력 버퍼링
- 프로세스가 데이터 출력을 요청하면, 버퍼에 데이터를 저장해놓은 뒤 마지막에 한번에 데이터를 출력한다.
-
특징
-
입력 버퍼링은 데이터 요청 전에 수행, 출력 버퍼링은 데이터 요청 후에 수행한다.
-
메모리(버퍼)에서 데이터를 처리하기 때문에, 데이터 입출력 요청 시마다 저장 장치에 접근하는 것보다 오버헤드가 적다.
-
-
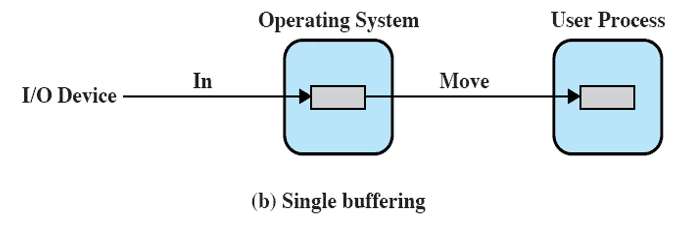
1-1. Single Buffering
-
Single Buffering : 가장 단순한 형태의 버퍼링 방식이다. User 프로세스가 I/O 요청을 할 때, OS가 메인 메모리의 OS 영역에 버퍼를 할당한다.
-
블록 지향 장치에서의 동작 방식
-
입력 버퍼링 : 저장 장치에서 시스템 버퍼로 데이터가 이동한다. 입력 버퍼링이 끝나면, 해당 블록을 사용자 영역으로 이동시키고 즉시 다음 블록을 요청한다.
-
출력 버퍼링 : 데이터가 저장 장치로 이동할 때, 사용자 공간에서 시스템 버퍼로 복사된 후, 시스템 버퍼에서 저장 장치로 최종적으로 이동한다.
-
-
스트림 지향 장치에서 동작 방식 : 한 줄씩 혹은 한 바이트씩 처리된다.
-
한 줄씩 입력 버퍼링 : 버퍼는 한 줄의 데이터를 저장하고, 사용자 프로세스는 전체 줄이 도착할 때까지 대기한다.
-
한 줄씩 출력 버퍼링 : 유저 프로세스는 출력할 한 줄의 데이터를 버퍼에 넣고 계속 작업을 진행한다. 첫 번째 출력 작업이 끝나기 전에 두 번째 줄의 출력을 시도할 경우 중단된다.
-
한 바이트씩 입력 버퍼링 : 버퍼에 입력된 각 바이트는 즉시 처리된다. (생산자/소비자 모델)
-
한 바이트씩 출력 버퍼링 : 출력 버퍼에 한번에 한 바이트씩 데이터를 넣고 처리한다.
-
-
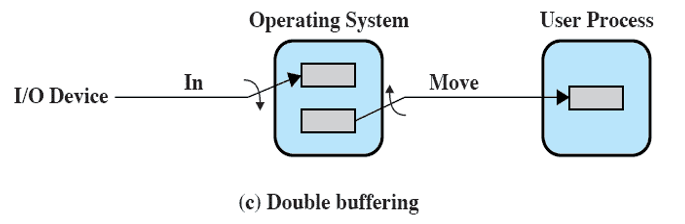
1-2. Double Buffering
-
Double Buffering : 두 개의 시스템 버퍼를 할당하여 데이터를 처리하는 방식이다. 이는 버퍼 교환(Buffer swapping)이라고도 불리운다. 즉, 프로세스가 한 버퍼에서 데이터를 전송(입력 또는 출력)하는 동안, OS는 다른 버퍼를 비우거나 채운다.
-
블록 지향 버퍼링
-
실행 시간은 약 max[C, T]로 추정한다.
-
C는 데이터 전송 시간, T는 버퍼 처리 시간이다.
-
C <= T : 장치가 최대 속도로 동작한다.
-
C > T : 이 경우에도, 프로세스가 I/O 전송을 기다리지 않도록 보장한다.
-
결론적으로 싱글 버퍼링보다 성능이 좋다.
-
-
스트림 지향 버퍼링
-
한 줄씩 처리 : 프로세스는 더블 버퍼가 가득 차기 전까지는 입출력 작업을 중단할 필요가 없다.
-
한 바이트씩 처리 : 생산자/소비자 모델을 따르므로, 싱글 버퍼에 비해 특별한 이점을 제공하지 않는다.
-
-
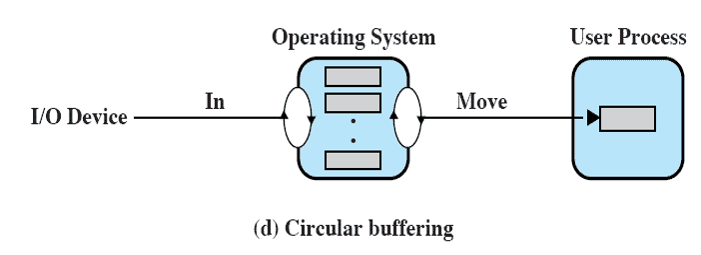
1-3. Circular Buffer
-
Circular Buffer : 순환 버퍼는 두 개 이상의 버퍼를 사용하는 경우, 이 버퍼들이 순환적 구조로 집합을 이룬다. 즉, 집합 속 버퍼들이 순환적으로 사용되며 데이터를 처리한다.
-
특징
-
두 개 이상의 버퍼를 사용하기 때문에 I/O 장치와 프로세스 간의 데이터 흐름이 더욱 원활해진다.
-
더블 버퍼링의 처리 속도 한계를 넘어설 수 있다.
-
생산자/소비자 모델을 따른다.
-
-
2. Disk Scheduling
-
HDD의 구조
-
플래터 : HDD의 표면으로, 플래터가 회전하며 헤드가 데이터에 접근하도록 한다.
-
트랙 : 플래터에 존재하는 작은 원형 홈이다.
-
섹터 : 트랙 안에 존재하는 자체적으로 주소를 갖는 매우 작은 영역이다.
-
헤드 : 회전하는 플래터에서 데이터를 읽어오기 위한 장치이다.
-
-
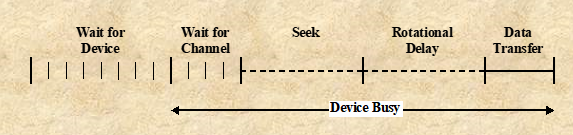
Disk Performance Parameters
-
Seek time (탐색 시간) : HDD에서 특정 섹터(데이터)를 찾는 데 걸리는 시간이다. 이 과정에서 제일 큰 시간이 걸린다. 즉, 헤드를 트랙에 위치시키는 시간이다.
-
Rotational Delay time (회전 지연 시간) : 적절한 섹터와 헤드가 만나기 위해 HDD의 플래터가 회전하는 시간이다. 즉, 섹터가 헤드와 일치할 때 까지 걸리는 시간이다.
-
Access time : 데이터의 읽기 또는 쓰기를 위해 데이터에 접근하는 총 시간이다. 즉, 탐색 시간과 회전 지연 시간의 합이다.
-
Transfer time (전송 시간) : 데이터에 접근한 후, 읽기 또는 쓰기 작업이 수행되는 시간이다. 즉, 데이터 전송에 걸리는 시간이다.
-
-
Seek time : 헤드를 원하는 트랙까지 이동시키는 데 걸리는 시간으로, 데이터 처리 시간의 대부분을 차지한다. 따라서 Disk Scheduling의 주요 대상이 된다.
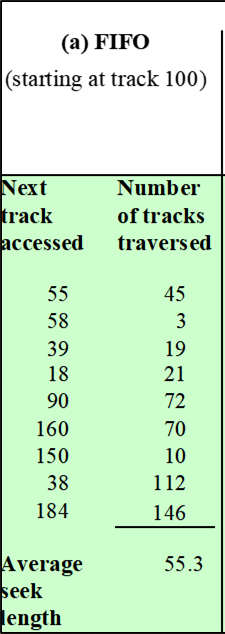
2-1. First In First Out (FIFO)
-
First In First Out (FIFO) : 큐에 존재하는 순차적 항목 그대로 디스크에 접근하여 처리하는 가장 단순한 스케줄링 형태이다.
-
특징
-
모든 요청은 요청 받은 순서대로 처리되므로 가장 공정한 알고리즘이다.
-
트랙과 헤드의 거리가 먼 데이터에 접근해야되는 경우, 성능이 떨어진다.
-
많은 프로세스가 데이터 접근을 요청하는 경우, 사실상 랜덤 스케줄링과 동일하다.
-
-
2-2. Shortest Service Time First (SSTF)
-
Shortest Service Time First (SSTF) : 가장 Optimal한 솔루션으로, 헤드의 현재 위치에서 가장 적은 이동이 필요한 데이터에 대한 I/O 요청을 선택하는 방식이다. 항상 최소 탐색 시간을 보장하지만, Overhead가 매우 크다(계산 시간이 오래 걸림).
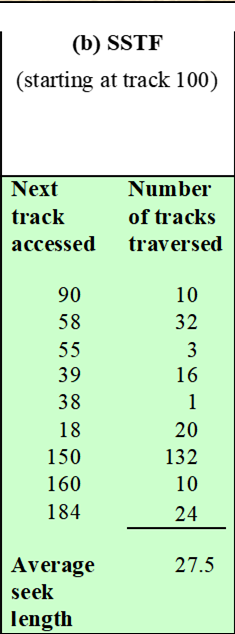
-
특징
-
모든 요청 중 현재 헤드의 위치에서 제일 가까운 데이터에 대한 요청을 선택한다.
-
항상 최소 Seek time을 보장한다.
-
구현이 매우 복잡하므로, 계산에 대한 Overhead가 크다.
-
-
2-3. SCAN
-
SCAN (엘리베이터 알고리즘) : 헤드가 한 방향으로 이동하며, 그 방향에 있는 모든 I/O 요청을 처리한다. 만약 한쪽 끝(마지막 트랙)에 도달했지만 처리할 데이터가 남았다면, 반대쪽 끝(가장 안쪽 트랙)을 향하여 이동하며 같은 방식으로 동작한다.
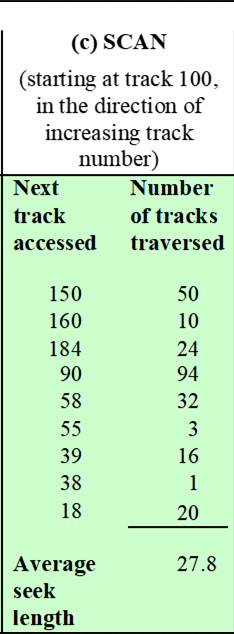
-
특징
-
특정 요청이 과하게 기다리는 Starvation 현상을 방지하며, 오버헤드 또한 적다.
-
오버헤드가 적으며 성능또한 우수하기 때문에, 가장 최적화 된 스케줄링 방식이라고 볼 수 있다.
-
-
2-4. C-SCAN (Circular Scan)
-
C-SCAN : 헤드가 항상 한 방향으로만 스캔하고, 마지막 트랙에 도달하면 헤드를 반대쪽 끝으로 돌아가게 한 뒤, 다시 첫 트랙부터 마지막 트랙까지 스캔을 시작한다.
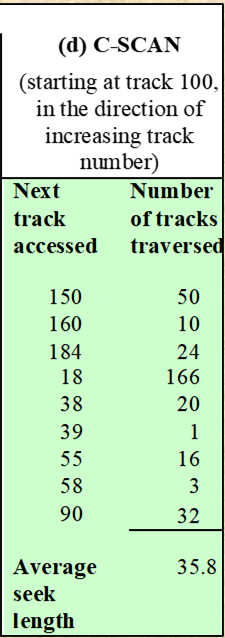
-
특징
-
SCAN은 양방향으로 스캔하지만, C-SCAN은 무조건 한 방향으로만 스캔한다.
-
장점은 SCAN 방식과 동일하지만, 양방향 스캔보단 Seek time이 길어질 수 있다.
-
-
