1. Paging
-
Locality : 대부분의 데이터 참조는 주로 프로그램의 특정 부분(예 : 반복문)에 의해서 발생한다는 경향이 있다. 따라서 프로세스의 일정 부분만이 필요할 수 있다는 가정은 타당하며, 이를 페이징 기법에 활용하면 Thrashing을 방지할 수 있다.'
-
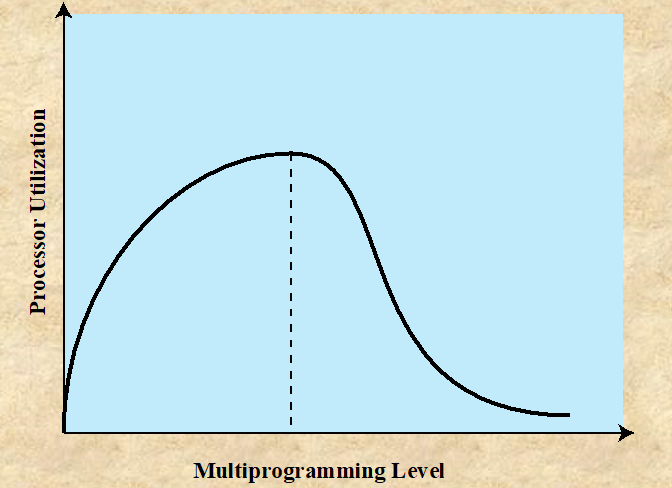
Thrashing : 프로세스가 페이지를 과도하게 많이 교체(페이지 폴트)하여, 실제로 유용한 작업을 수행하는 시간은 얼마 되지 않는 상태이다. 멀티 프로그래밍 레벨이 과도하게 올라갈 경우, 페이지 폴트가 자주 발생할 수 있고, 이로 인해 Thrashing이 발생할 수 있다.
-
Page fault : 프로세스를 실행하는 과정에서 특정 페이지가 필요할 때, 해당 페이지가 현재 메인 메모리에 존재하지 않는 경우, OS에서 Page fault handler가 작동하여 저장 장치에서 해당되는 페이지를 찾아 메모리에 로드한다. 이 일련의 과정을 페이지 폴트라고 한다.
-
Page Size
-
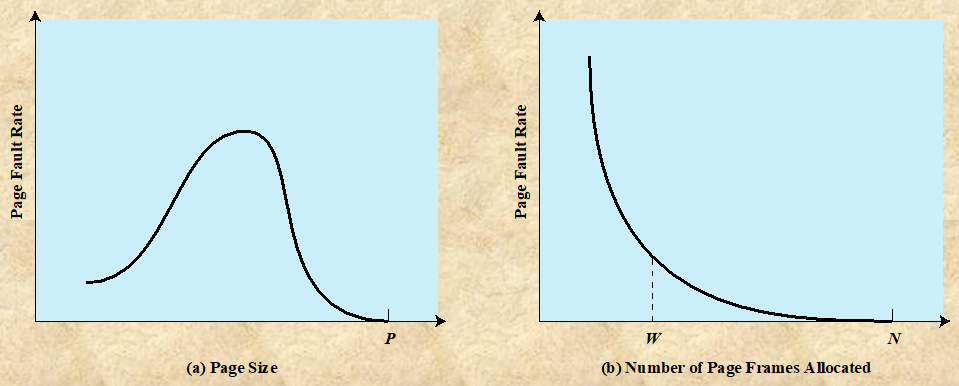
페이지의 크기가 작을수록, 프로세스의 더 많은 조각이 존재한다는 뜻이다. 때문에 Internal fragment Issue를 어느정도 해결할 수 있는 반면, Page Fault의 발생 확률이 높아지고, Page Table의 크기가 커진다.
-
페이지의 크기가 커질수록, Internal fragment Issue가 커진다.
-
-
Address Translation in Paing
-
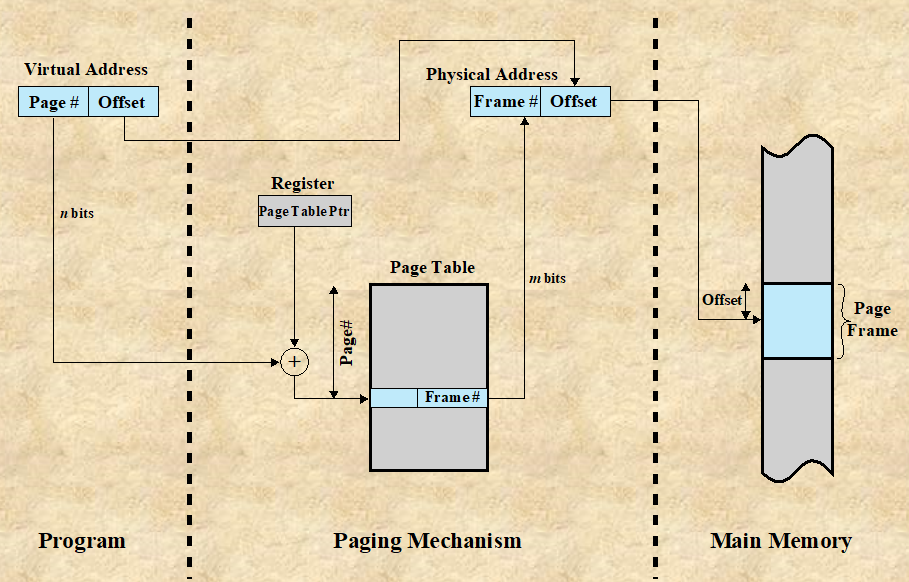
메모리에서 프로세스가 실행될 때 코드를 읽는 기본 메커니즘은 논리 주소를 물리 주소로 변환하는 것이다.
-
OS는 주소 변환이 필요할 때 PCB 안에 존재하는 Page Table을 참조한다.
-
-
Multi Level Page Table : Page Table로 인한 메모리 낭비가 심한 경우, 이를 해결하기 위한 방법이다.
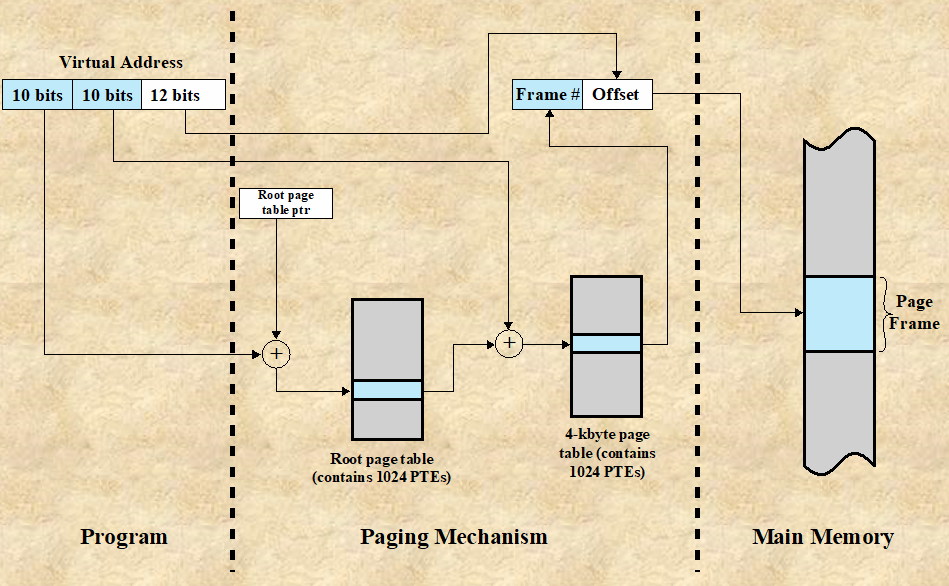
-
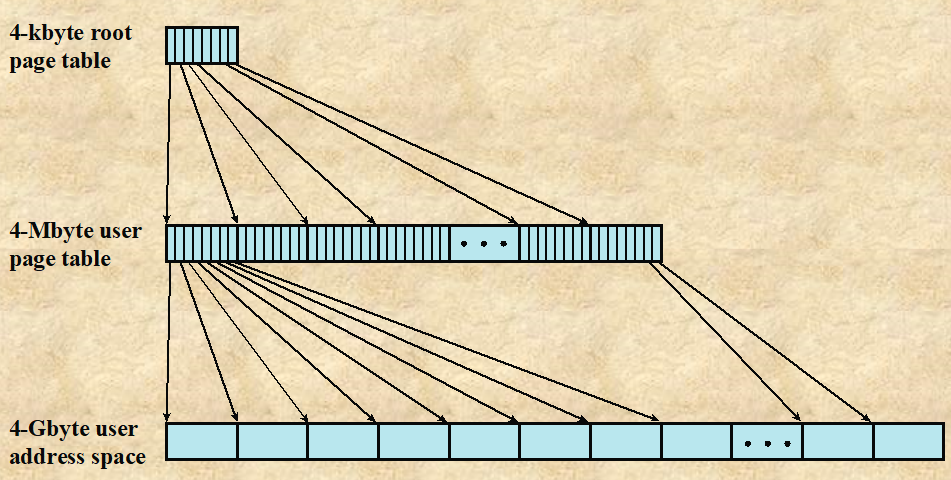
논리 주소의 Page number의 사이즈가 20bit인 경우
-
Single Page Table : 해당 테이블에 존재하는 페이지가 몇 없더라도 페이지 테이블의 크기가 만큼 필요하다.
-
Multi Level Page Table : 만약 페이지 넘버를 2^10, 2^10의 2 Level로 쪼갠다면, 의 루트 페이지 테이블이 존재하고, 각 엔터티에 대해서 크기의 테이블이 존재한다. 따라서 페이지 개수가 적은 프로세스의 경우, Multi Level Page Table로 구성할 경우 의 메모리만 필요하므로, 오버헤드를 줄일 수 있다.
-
-
-
Inverted Page Table : Page Number의 PID를 확인하고, 해당하는 프레임 넘버를 찾아 필요한 페이지를 참조한다. OS가 하나의 Inverted Page Table을 통해 전체 페이지를 관리하므로, 프로세스 당 1개의 Page Table가 존재하여 프로세스 관점에서 페이지를 관리하는 것보다 오버헤드가 적다.
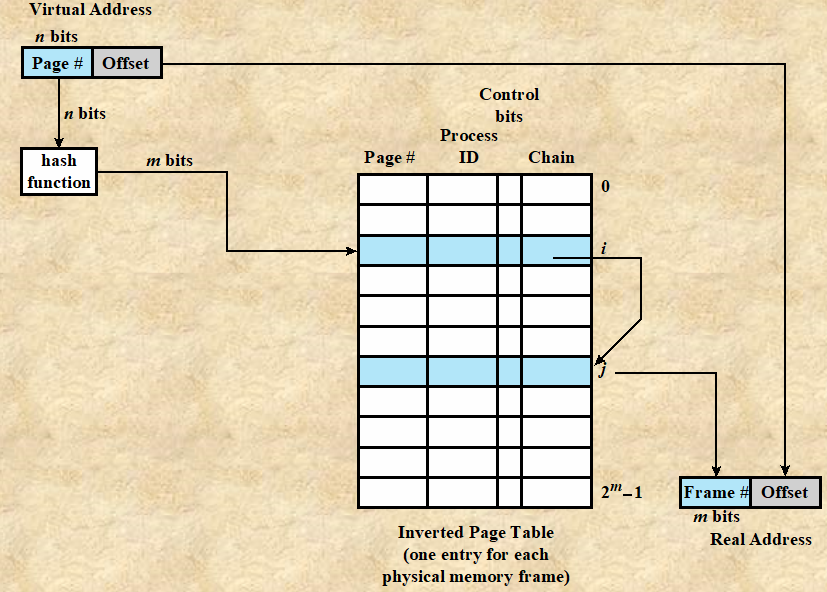
-
Demand Paging (수요 페이징) : 페이지에 대한 참조가 발생할 때만 메인 메모리로 페이지를 가져오는 방식이다.
-
보조 메모리에 존재하는 페이지에 대한 참조는 프로세스가 처음 시작될 때 자주 발생한다.
-
즉, Page fault가 많이 발생한다.
-
지역성의 원리에 따라, 점점 더 많은 페이지가 메모리로 가져와지면, 대부분의 미래 참조는 최근에 가져온 페이지들 중에 이루어질 것이다.
-
따라서 점차 페이지 폴트의 수는 줄어들 것이다.
-
-
PrePaging : 페이지 폴트가 발생했을 때 요구된 페이지 외의 다른 페이지들도 같이 메모리에 가져오는 방식이다. 프로세스의 페이지가 저장 장치에 연속적으로 저장되어 있다면, 페이지를 하나씩 참조하는 것보다 여러개를 한번에 가져오는 것이 더 효율적이다. 즉, 프리페이징은 페이지 폴트가 발생하였을 때 추가 페이지를 미리 가져오는 방식이라고 볼 수 있다.
2. Page Replacement Algorithm
- Page Replacement Algorithm : 가상 메모리 시스템에서 사용되는 알고리즘으로, 메인 메모리가 가득 찼을 때 어떤 페이지를 교체 할지를 결정하는 방법이다. 이 알고리즘은 프로그램 실행의 효율성을 최대한 유지하면서, 필요한 페이지 교체를 하기 위해 필요하다. 대표적인 방식은 FIFO, LRU등이 존재한다.
2-1. FIFO
-
FIFO (First In First Out) : 프로세스의 페이지 프레임을 순환 버퍼로 취급하여, 메모리에 가장 오래 있었던 페이지를 교체하는 방식이다. 즉, 가장 오래 된 페이지일수록 이제 사용하지 않을 가능성이 높다고 간주하는 것이다.
-
동작 방식

-
초기화 : 메모리에 할당된 페이지의 수만큼 공간을 확보하고, 이 공간을 순환 버퍼로 취급한다. 현재 위치를 가리키는 포인터를 초기화한다.
-
페이지 요청 : 프로세스가 페이지를 요청할 때, 해당 페이지가 이미 메모리에 있는지 확인한다.
-
Page Hit : 요청한 페이지가 이미 메모리에 있는 경우, 아무 작업도 하지 않는다.
-
Page Fault : 요청한 페이지가 메모리에 없는 경우, 페이지 폴트가 발생한다. 메모리에 가장 오래 존재했던 페이지(포인터가 가리키는 위치의 페이지)를 제거하고 요청한 페이지를 로드한다. 포인터는 다음 위치로 이동한다.
-
-
문제점
-
Belady's Anomaly : 메모리 프레임 수의 증가가 페이지 폴트 발생 횟수의 감소를 항상 보장하지 못한다.
-
자주 사용되는 페이지는 고려하지 않는 알고리즘이므로, 페이지 폴트가 자주 발생하여 성능 저하가 발생할 수 있다.
-
-
2-2. LRU
-
LRU (Least Recently Used) : 메모리에서 가장 오랫동안 참조되지 않은 페이지를 교체하는 방식이다. 지역성 원리에 따르면, 이는 가까운 미래에 참조될 가능성이 가장 낮은 페이지라고 유추할 수 있으므로, 유효한 접근 방법이다. 다만 이를 구현하는 것은 매우 어려운 문제이다. LRU 알고리즘의 구현에 대한 접근은 다음과 같다.
-
타임스탬프 사용 : 각 페이지에 마지막 참조 시간을 기록하여, 페이지 교체가 필요할 때 가장 오래된 타임 스탬프를 가진 페이지를 찾아 교체한다. 이 방법은 LRU 방식을 완벽하게 구현하지만, 오버헤드가 상당하다.
-
연결 리스트 사용 : 모든 페이지를 참조 순서에 따라 연결 리스트에 유지한다. 페이지가 참조될 때마다, 해당 페이지를 리스트의 맨 앞으로 이동한다. 즉, 리스트의 맨 뒤에 위치한 페이지가 가장 오랫동안 참조되지 않은 페이지가 된다. 이는 타임스탬프 방식보다 오버헤드가 적다.
-
3. Working Set Model
-
Working Set Model : 운영 체제에서 프로세스의 메모리 요구 사항을 추정하고 관리하기 위해 사용되는 개념. 즉, 프로세스에 할당할 Frame 개수를 Dynamic하게 조절하여 시스템의 메모리 관리를 최적화하는 방법을 제시한다.
-
Working Set : 특정 시간 간격 동안 프로세스에 의해 참조된 페이지의 집합이다. 즉, 프로세스가 실행을 위해 필요로 하는 페이지의 집합으로 이해할 수 있다.
-
Window : 워킹 셋을 측정하기 위해 고려하는 시간의 범위이다. 이 간격이 너무 짧거나 길면 워킹 셋이 제대로 계산되지 않을 수 있다.
-
지역성 (Locality) : 프로세스가 시간 간격동안 특정 페이지를 집중적으로 사용하는 현상이다.
-
-
Working Set Model의 장점
-
프로세스가 필요로 하는 메모리(페이지)를 예측함으로써 OS는 프로세스에 필요한 메모리를 할당하고, 메모리가 부족할 때 어떤 페이지를 교체할지 결정할 수 있다. 때문에 스레싱을 예방할 수 있다.
-
시스템의 메모리 사용률을 최적화할 수 있다.
-
4. Translation Lookaside Buffer (TLB)
-
Address translation : CPU가 페이지를 참조하기 위해선 논리 주소를 물리 주소로 변환하는 과정이 필수적이다. 이때, 다음과 같은 두 단계의 과정을 거치게 된다.
-
페이지 테이블 조회 : 페이지를 참조하기 위해 물리적 메모리에 위치한 페이지 테이블을 조회한다.
-
데이터 참조 : 페이지 테이블을 통해 알아낸 페이지 항목을 실제 메모리 주소에서 찾아 데이터를 참조한다.
-
위와 같이 가상 메모리 참조가 필요할 때마다 두 번의 물리적 메모리 접근이 필요하므로, 오버헤드가 발생한다.
-
-
Translation Lookaside Buffer (TLB, 변환 색인 버퍼) : TLB라는 CPU 레지스터상에 위치한 고속 캐시를 사용하여 위와 같은 문제를 해결할 수 있다. TLB는 최근에 사용된 페이지에 대한 정보를 저장하여, 메모리 접근 시간을 줄이려고 시도한다.
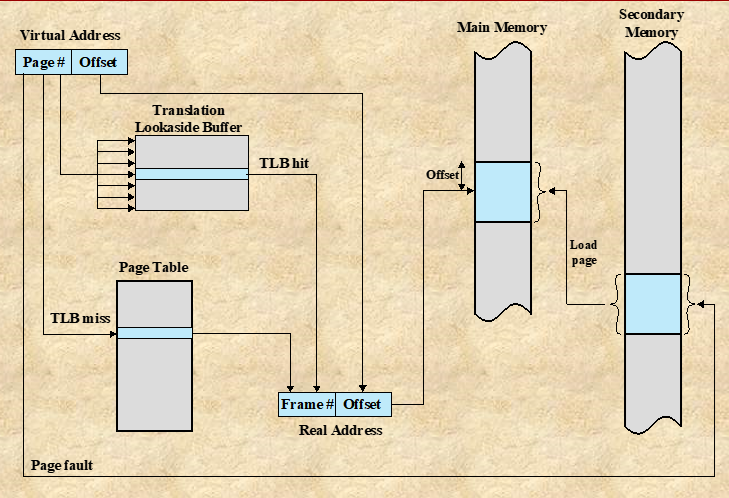
-
동작 방식
1). 특정 페이지를 찾기 위해, 바로 페이지 테이블을 참조하지 않고 TLB에서 찾으려고 먼저 시도한다.
2). TLB hit : 만약 TLB에 해당 페이지가 존재한다면, 페이지 테이블에 접근 없이 필요한 페이지를 바로 참조할 수 있다.
3). TLB unhit(miss) : TLB에 해당 페이지가 없다면, 페이지 테이블에 접근해 필요한 페이지를 참조한다.
-
특징
- TLB는 크기가 매우 작은 캐시 메모리이므로, Locality에 근거하여 사용될 확률이 높은 페이지를 올려놓는다. 즉, 오래된 페이지는 새로운 페이지로 교체한다.
-
